网贷信用风险预警
2020-05-06郝仁杰
□文/郝仁杰
(南京邮电大学 江苏·南京)
[提要] 随着大数据时代的到来,传统的征信体系不再满足互联网金融对征信精度的要求。本文基于Logistic回归、随机森林算法的模型来预测P2P网贷中客户的信用风险。通过爬虫技术抓取某网贷平台的交易数据,然后利用SMOTE重采样技术对数据采样,实证研究结果表明:相较于Logistic回归模型,基于随机森林模型的预测能显著降低错误比例,提高预测正确率、召回率和特异性。本研究对P2P网贷平台的信用风险预警具有参考意义。
一、引言
随着“互联网+”概念兴起,传统的金融模式已经不再满足时代的新要求,纷纷提出多式多样的业务模式。随之而来的是各种包括政策风险、监管风险、操作风险、网络风险与信用风险在内的种种风险。因此,当前对于平台而言最重要的是如何利用各自的数据,通过大数据模型精准判断借贷人的违约风险,这对保障投资人的利益、平台的安全和行业的稳健发展都具有很重要的现实意义。
二、研究现状
在国外,早期的网贷信用风险评估中,借贷平台是通过投资人而非借贷平台来筛选确定借款人是否值得信赖,这就造成虚假陈述现象比较普遍。后来引入数学建模的形式去评估信贷风险,比较常用的包括判别分析、聚类分析、Logistic回归等。此后对模型进行进一步探索之后,引入了ZE-TA信用风险评估模型、高斯混合模型和随机森林等模型。在国内,近几年内的网贷平台良莠不齐,发展模式并没有行业规范,带来更严重的信用风险。有学者利用现代大数据中借贷人的个人特征、历史表现、借款信息等三个方面的数据建立模型发现其对网贷信用风险存在显著影响。缪莲英等学者通过Logistic回归研究发现社会资本的存在能够降低平台借款人的违约风险。
目前,对传统商业银行贷款的信用风险研究比较成熟,但随着大数据时代的到来,互联网金融的兴起,传统的征信体系已经不能满足现阶段对征信的要求。而且传统的数学模型对于多变量之间共线性有严格的要求,并不能全面考虑各种特征,并且使用机器学习模型进行信用风险研究还处于初步阶段。
三、研究方法
Logistic回归模型是典型的广义线性模型,响应变量与自变量之间通过Logit函数连接,在0-1分类问题中得到广泛应用。假设因变量Y取值为0或1,事件未发生定义为Y=0,事件发生的概率为P,事件未发生的概率为1-P,把P看成x的线性函数,Logistic回归的公式可以表示为:
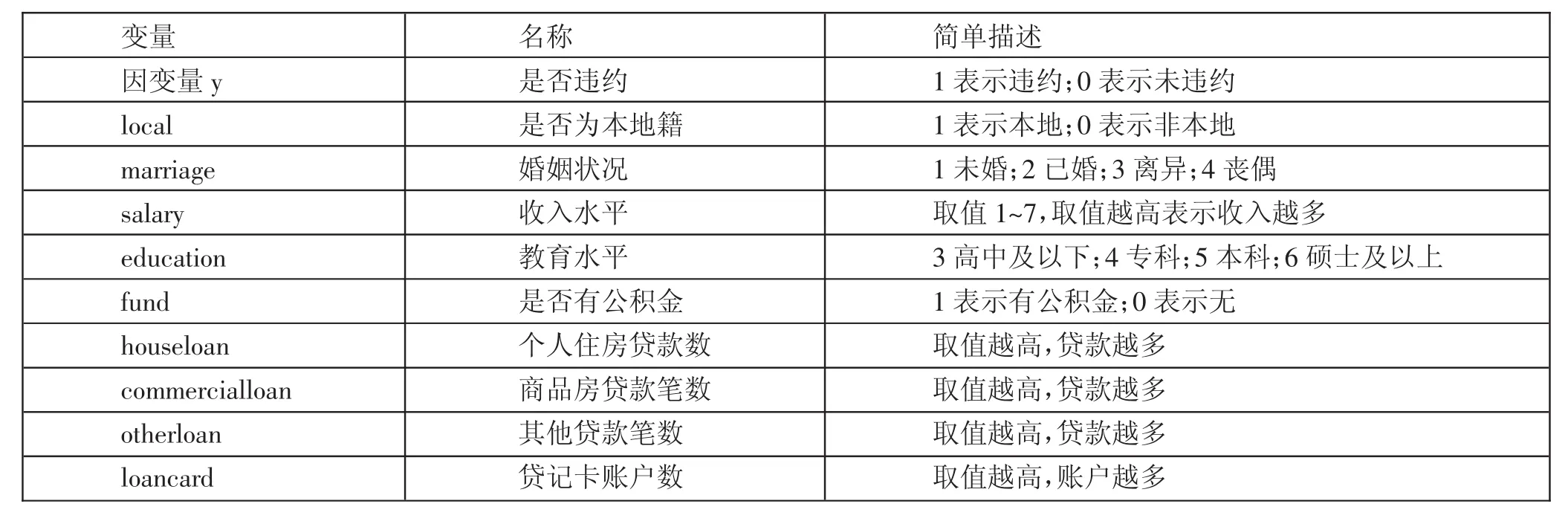
表1 变量说明一览表

随机森林是常见的集成学习模型,它是基于在基学习器为Bagging模型的基础上,引入了随机的概念。一方面是数据的随机:在训练模型的时候每棵树会随机又放回的利用训练集数据进行训练,大约有1/3的数据不会被选取到;另一方面在树模型分叶的节点上,会随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
最后两个模型的评价指标,本文从训练集、测试集、未重采样测试集根据混淆举证计算得来的正确率、召回率、特异性、错判率四个指标来评价模型,其中前三个指标越接近1表示模型越好,错判率越接近0越好。

四、实证研究
(一)数据来源与变量说明。本文选取了国内一个比较出名的网贷平台作为研究目标。利用网络爬虫技术获取平台从一段时间爬取的借贷数据,共计8,864条样本。样本所含指标如表1所示,包括客户是否为违约客户、是否为本地籍、教育水平、婚姻状况、收入水平、是否有公积金、个人住房贷款笔数、商品房贷款笔数、其他贷款笔数和贷记卡账户数。(表1)
(二)数据预处理。因为本数据集近90%的样本是属于非违约的,如果分类器将所有的样本都分类为该类,尽管最后的分类精度超过90%,其实并无实际意义。所以,在数据不均衡时,评价指标的参考意义不大。针对样本数据不平衡的情况,本文用R软件中的SMOTE函数进行重采样的处理方式,对大类的数据样本进行欠采样来减少大类的数据样本个数,即采样的个数少于该类样本的个数。得到的样本集两个类别各近占50%。将重采样剩余的原始数据作为整个数据集的测试集,用重采样后的数据集的70%训练模型,然后先用剩下的30%测试模型,最后再用整个数据集的测试集再次验证模型的预测效果。
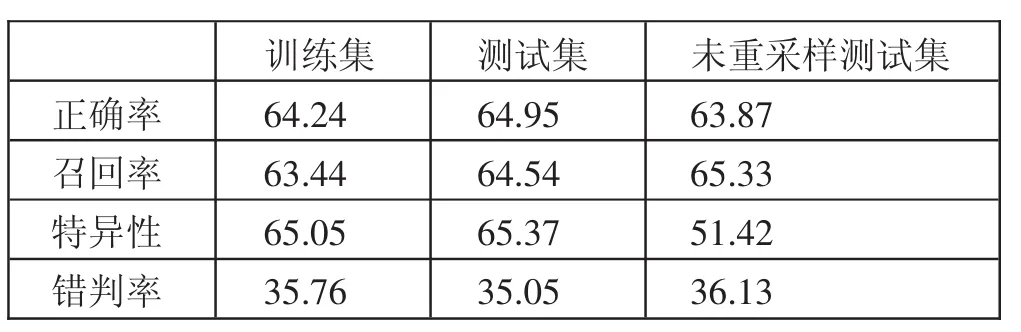
表2 Logistic回归模型评价指标一览表(单位:%)
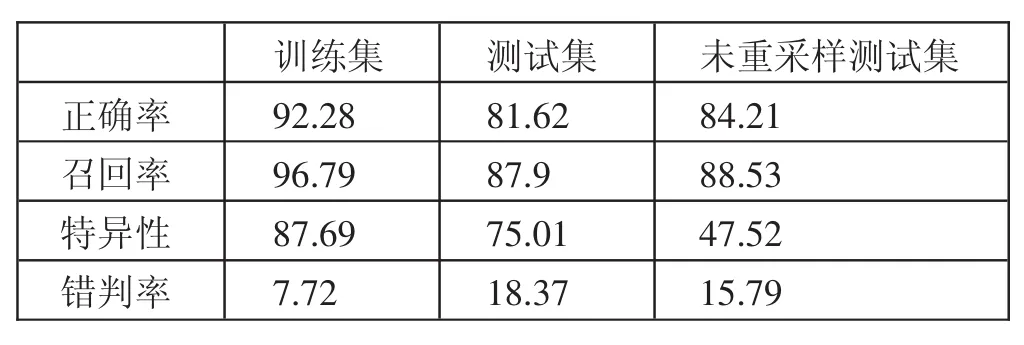
表3 随机森林模型评估指标一览表(单位:%)
(三)实证分析
1、Logistic回归模型建立与预测。将经过9个指标作为特征变量,是否违约作为目标变量来建立Logistic回归模型。首先,考察特征变量间的多重共线性。从相关系数矩阵中发现,特征变量之间的共线性比较普遍且复杂,采用“逐步回归”对变量进行筛选。将建立的模型分别用重采样的训练集与测试集以及未经重采样数据集的测试集进行了模型的预测,通过正确率、召回率、特异性以及错判率四种指标来检验模型预测效果,结果如表2所示。(表2)
由表2中的结果可知,训练集和测试集以及未重采样的测试集所计算得到的4个指标差异不大。平均来看,模型的预测正确率大概为64%、召回率为64%、特异性为60%以及错判率在35%。
2、随机森林模型建立与预测。本文采用集成学习中随机森林的算法,此算法是目前机器学习方法中比较流行且预测效果较优的集成算法。它避免了过拟合的误差,能够有效地提高模型的预测能力。
图1表示的训练集分类的误判率,可以看到随着树的数量增多,误判率渐渐趋于平稳。到100棵树时误判率已有平稳趋势,但之后还是有些许波动,最后在进行随机森林建模时,树的参数选为300。(图1)
由表3中的结果可知,训练集和测试集以及未重采样的测试集所计算得到的四个指标有差异。训练集的整体预测效果优于其他两个训练集,这是由于本身的模型是基于训练集所建立。模型的预测正确率大概为85%、召回率为90%、特异性为70%以及错判率在13%左右。这个验证结果明显比Logistic回归预测结果的精确度有提升。(表3)
五、结论
借款人违约,对出借人和P2P平台都会造成巨大损失,更会制约行业的发展。预警借款人违约风险的有效手段是构建全国性的征信体系,同时平台进一步完善审查监督制度,但这些都需要多个参与主体长期的共同努力才能实现。就目前来看,最有效的方法是平台基于自身积累的大数据,构建预测准确、性能稳定的违约风险预警模型。
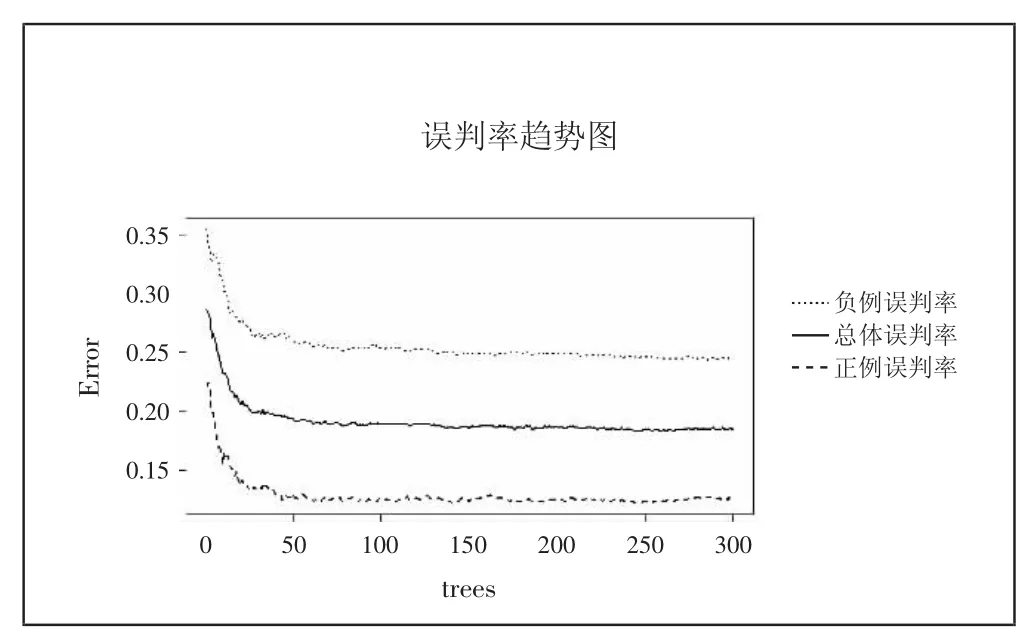
图1 误判率趋势图
本文基于Logistic回归和随机森林信用风险预警模型进行分析比较,研究结果表明:基于三个样本集的模型评价指标,随机森林所建立的模型计算得到的准确率、召回率和特异性比Logistic回归的高,并且错误率要低。所以,在对P2P网贷信用风险预警时,选用随机森林所构建的模型预测效果会比较好。而传统的Logistic回归,由于必须满足严格的统计学假设,在评估客户信用风险时可能受到较大限制,具有自身的局限性。但是,Logistic回归模型还是有借鉴之处,比如每个特征变量对客户违约的影响程度以及正负向关系是可以通过模型的系数可以直观的看到,这是集成学习具有局限的地方。所以,可以将这两种模型从不同角度去看待,但总的预测效果还是由随机森林建立的模型更为准确,并且符合大数据时代的要求。
本文研究基于Logistic回归与集成学习的P2P网贷违约风险预警,对P2P网贷平台的违约风险预警具有启示意义,有助于平台更好地预测借款人信用风险,完善自身风控体系。另外,由于数据有限,本研究还有需进一步深入探讨的地方,比如如何提升模型的泛化能力、对违约客户的细化分类以及从更多维度的用户特征去训练模型。
