一种基于SVDD的WLAN室内被动入侵检测方法
2020-05-01高罗莹田增山李玲霞张小娅
高罗莹,田增山,李玲霞,张小娅
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 前 言
被动入侵检测是指被检测目标在不携带任何信号收发设备的条件下,通过检测入侵目标对无线电波的扰动实现环境的异常检测,在智能家居、老人监护和警务安保等领域具有潜在的应用价值[1-3]。目前为止已经发展了多种被动入侵检测系统,比如,超宽带雷达系统[4],计算机视觉系统[5],无线电层析成像系统[6]以及无线传感器[7]被动检测系统。这些系统在特定条件下能够提供较高的检测率,但仍有各自的缺点。超宽带雷达检测系统,需要安装特殊的硬件设备;计算机视觉系统受到直射视距的影响,并且无法在黑暗环境或者烟雾环境中工作;无线电层析成像系统和无线传感器系统,需要部署高密度的节点来实现监测区域的全覆盖,且设备昂贵,不适宜大规模商用。相比于这些系统,基于无线局域网(wireless local area network,WLAN)的被动入侵检测系统利用室内环境中广泛部署的无线网络,具有易部署、成本较低、覆盖面积广等特点,从而得到了广泛的关注。
现有的基于WLAN的被动入侵检测技术,主要有基于时间序列分析的检测技术,如移动均值(moving average,MA)和移动方差(moving variance,MV)检测技术[8];基于统计异常的检测技术,如Ichnaea系统[9];以及基于模式识别的检测技术,如基于最大似然估计(maximum likelihood estimation, MLE)[10]和支持向量机(support vector machine, SVM)[11]的检测技术。然而,基于时间序列分析的检测技术,虽然能在短时间内获得较高的检测性能,但是对环境变化的稳健性较差,随着时间和环境的变化检测性能逐渐下降;基于统计异常的检测技术,其单链路的检测性能取决于置信度水平的取值,因此在多链路联合检测中,为了实现较好的检测性能需要调整每条链路的置信度水平,其应用场景有限;基于模式识别的检测技术,需要在训练阶段采集大量的正常数据和异常数据作为训练样本,才能获得较好的分类准确率,因此训练阶段时间开销较大,不适合在大范围场景下应用。
为了避免以上技术的不足,本文提出一种基于支持向量域描述(support vector domain description,SVDD)[12-13]的WLAN室内被动入侵检测算法。首先,利用A-distance值分布差异性度量方法[14]与交叉验证法计算出各种信号特征对于正确区分静默状态与有人运动状态的平均贡献度,选择平均贡献度较高的特征来刻画环境中不同的状态。然后,根据特征选取的结果,提取出静默状态下每条链路相应的信号特征,并构造出特征矩阵。最后,利用特征矩阵训练SVDD异常检测模型,SVDD以SVM为基础,通过非线性变换将特征矩阵从低维输入空间变换到高维特征空间,并在高维空间中得到一个超球体异常检测边界,并且利用L1正则化有效地抑制离群点的影响,具有较好的抗噪性。本文最后在复杂的家居环境和大范围的走廊环境下采集WLAN数据用以验证本文算法的有效性。验证结果表明,本文算法在这2种环境中的F1-measure值分别达到0.960和0.945,优于现有的基于WLAN的被动入侵检测技术。
1 系统模型
本文的室内入侵检测系统包括3个阶段,分别为特征分析阶段,离线训练阶段,在线监测阶段。系统框架如图1。
特征分析阶段。在入侵检测系统中,不同的特征组合其检测性能存在差异。因此,在特征分析阶段需要挑选出最优的特征组合,作为之后系统构建的特征数据基础。在该阶段,本文分析随机场景中多种特征在正常和异常状态下的分布差异,评估这些特征在不同传播路径下的重要性,并根据特征重要性排序选择最优的特征组合用于被动入侵检测。
离线训练阶段。采集静默数据来构建入侵检测模型,用于检测环境中是否存在异常。在该阶段,感知区域中有无人活动,接收设备采集每条链路的接收信号强度值。然后,根据特征分析阶段的结果提取每条链路相应的特征值,结合多链路信号特征构建特征矩阵。最后,利用特征矩阵训练出SVDD入侵检测模型。
在线检测阶段。利用离线阶段训练出的模型来判断当前环境是否异常。在该阶段,提取实时信号的相应特征构建特征向量,通过判断特征向量是否在超球体内部来判断感知区域内是否存在入侵,实现实时检测。
2 基于SVDD的WLAN室内被动入侵检测系统
2.1 特征分析阶段
特征分析阶段主要是通过分析各种特征在静默和入侵2种状态下的分布差异,来寻找最优的特征组合,用于构建被动入侵检测系统。
2.1.1 信号特征分布差异性分析
在2.4~5 GHz频段的无线环境中,信号在无变化的环境中其接收信号强度(received signal strength,RSS)值相对稳定,但是一旦环境中存在干扰,信号在传播过程中会受到反射,折射和散射的影响,会造成RSS值的变化,如图2,静默和有人走动时,链路的信号具有明显的差异。因此,接收端RSS信号的变化情况,能很好地反映无线环境是否有入侵者。
为了更好地捕捉接收端信号功率水平的变化,本文使用滑动窗函数提取信号特征,通过学习信号特征的变化来研究接收信号变化的规律。本文主要考虑7种信号特征,分别是最大值、最小值、均值、中值、极差值、方差以及平均FFT[15](mean of fast fourier transformation,Mean FFT)。其中,平均FFT是信号的频域特征,用于捕获人员入侵的周期模式,能有效地反映信号的波动变化情况。假设t时刻的滑动窗数组为Wt=[xt-L+1xt-L+2…xt],t≥L,滑动窗长度为L。根据特征提取函数提取t时刻滑动窗数组的特征,平均频率提取公式为
(1)

图3为4条链路的7种特征在静默和走动状态下的分布情况。可以看出,不同特征在2种状态下的分布差异性是不同的。因此,为了在不同环境下均能获得较高的检测率,需要对特征进行筛选,选取分布差异较大的特征组合实现异常检测。
2.1.2 特征选取方法与步骤
为了实现有效的特征选取,本文使用A-distance值评估每个特征在静默和走动2种状态下的分布差异,选取分布差异程度较大的特征构建检测模型。其中,A-distance值通常用于度量构建2分类器的2组数据(Ds和Dt)的分布差异程度[13],A-distance值越大,说明2组数据的分布差异性越大,构建出的分类器分类误差就越低。本文中选择决策树作为线性分类器h,使用E(h)表示分类器的损失,则A-distance值定义为
dA(Ds,Dt)=2(1-2E(h))
(2)
利用A-distance值和交叉验证法计算每个特征的平均贡献度Cj的具体步骤如下。
步骤1 提取M条链路静默数据和走动数据的7种信号特征,并构建特征矩阵Dnor,i和Dabnor,i,其中,i=1,…,M。
步骤2 将链路i(i=1,…,M)中第j(j=1,…,7)个特征向量Djnor,i和Djabnor,i分别划分为G个大小相似的互斥子集
Djnor,i=Dj,1nor,i∪Dj,2nor,i∪…∪Dj,Gnor,i
Djabnor,i=Dj,1abnor,i∪Dj,2abnor,i∪…∪Dj,Gabnor,i
步骤3 构造训练集Trgi,j,g=1,…,G和测试集Tegi,j,g=1,…,G,具体为
其中,静默数据的标记为1,走动数据的标记为-1。
步骤4 利用训练集Trgi,j,g=1,…,G构造决策树分类器hgi,j,g=1,…,G。
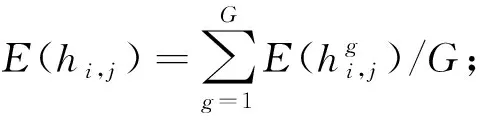
步骤6 根据(3)式求出链路i中第j个特征对应的A-distance值,具体为
dAi,j=2(1-2E(hi,j))
(3)
若dAi,j<0,表明特征j不能有效地区分链路i中的静默状态和走动状态,因此令dAi,j=0。然后,依次计算出链路i中7个特征的A-distance值{dAi,1,dAi,2,…,dAi,7},并进行归一化,得到特征j对于链路i的贡献度ci,j
(4)
步骤7 计算M条链路中第j个特征的贡献度ci,j,i=1,…,M,并求出第j个特征的平均贡献度。最后,依次求出7个特征的平均贡献度Cj为
(5)
步骤8 根据平均贡献度Cj的大小对特征重要性进行从高到低排序,Cj越大,特征重要性排序越靠前。最后,根据特征重要性排序结果选取前p(p≤7)个特征构建被动入侵检测系统。
在实际部署中,特征数p的取值,根据目标场景中静默数据的虚警率来确定,当特征数p从1开始逐渐增加时,虚警率会逐渐降低,当特征数p达到一定值popt时,虚警率降低到较低水平,并随着特征数的继续增加,虚警率趋于稳定或出现上升的趋势,此时特征数的取值应为popt。
2.2 离线训练阶段
离线训练阶段通过采集静默状态下多条链路信号数据,结合特征分析阶段结果,提取相应的特征数据,构建特征矩阵,然后利用特征矩阵训练SVDD入侵检测模型,用于在线检测阶段对环境的实时监测。
2.2.1 特征矩阵构建
用k表示在系统中无线链路的数量,该值等于信号发射设备即接入点(access point,AP)的数量乘以信号接收设备即监测点(monitor point,MP)的数量,其中,接收机的接收频率为1 Hz。
根据特征选取的结果,本文选择贡献度较高的p(p≤7)个特征用于运动检测,利用滑动窗函数(滑动窗长为L,与特征分析阶段相同)提取出每条链路j在时刻t相应的p个信号特征st,j,即st,j=[s1t,j,…,spt,j],其中,s1t,j和spt,j表示链路j在t时刻提取出的第1个特征和第p个特征。将t时刻k条链路的特征构成特征向量St,即St=[st,1,…,st,j,…,st,k]。采集T个时刻的信号后,得到T-L+1个特征向量,利用这T-L+1个特征向量构造特征矩阵S,如(6)式,令N=T-L+1。
(6)
2.2.2SVDD被动入侵检测模型构建
在该部分中,利用特征矩阵S训练得到SVDD入侵检测模型。SVDD的目标是在高维空间中找到一个体积最小的超球体,能够包含所有或者大部分的训练样本。为了避免离群点的影响,对每个训练样本点引入一个松弛变量ξi≥0,允许一些点在超球体外部。并且对每一个松弛变量ξi,乘以惩罚参数C,这使得系统具有一定的抗噪性能。目标函数为
s.t. ‖Si-a‖2≤R2+ξi,ξi≥0,i=1,…,N
(7)
根据(7)式可以构建拉格朗日函数为
(8)
(8)式中,拉格朗日乘子αi≥0,γi≥0。将拉格朗日函数L分别对R,a,ξi求偏导,并令其等于0,可得

(9)
由αi≥0,γi≥0,可得0≤αi≤C。
根据拉格朗日对偶性,求(7)式的极小值问题可变为其对偶问题的极大值问题。并引入核函数K(Si,Sj),实现由低维输入空间到高维特征空间的非线性映射。可得以下优化问题
(10)
利用序列最小最优化算法(sequential minimal optimization,SMO)可以求得αi的最优解[16]。当αi=0时,表示对应的样本点位于超球体内部;当αi=C时,表示对应的样本点在超球体之外,即为受限支持向量;当0<αi R2=‖Vq-a‖2= (11) 在大多数情况下,高斯核函数训练出的超球体边界对样本的描述效果较好[12],因此本文选用高斯核函数KG(Si,Sj)=exp(-‖Si-Sj‖2/σ2),(10)式和(11)式就变为 (12) (13) 2.2.3SVDD模型参数调节 在SVDD入侵检测模型中,有2个重要的参数,一个是惩罚参数C,另一个是高斯核宽度因子σ,它们的取值在一定程度上会影响SVDD检测的准确性,下面讨论参数取值对超球体异常检测边界的影响。 1)惩罚参数C。 “供给侧结构性改革”由中央财经领导小组于2015年11月提出,其含义为“用改革的办法推进结构调整,减少无效和低端供给,扩大有效和中高端供给,增强供给结构对需求变化的适应性和灵活性,提高全要素生产率,使供给体系更好适应需求结构变化。”① 2)高斯核宽度因子σ。 当σ2→0时,KG(Si,Sj)→0,i≠j,(12)式变为L=1-∑iα2i。当αi=1/N时,L的值最大。这时所有的特征样本都是支持向量,导致该检测系统的灵敏度较高,使虚警率升高,造成过拟合现象。过拟合是指某检测模型能在训练集上比其他模型有较好的检测性能,但是在训练集之外的数据集上检测性能较差的情形。 当σ2→时,KG(Si,Sj)=1,(12)式为当仅有一个αi=1而其他所有的αi=0时L的值最大,其值为0。这时只有一个特征样本是支持向量,会造成欠拟合现象,同样导致虚警率提升,系统检测性能下降。欠拟合表示某一检测模型在训练集上的性能较差,并且在训练集之外的数据集上检测性能也较差的情形。 然而,在过拟合和欠拟合之间必有一段σ的取值使得SVDD模型拟合效果较好,此时的虚警率较低,可利用一段静默数据作为测试集来找到这段σ,设为[σmin,σmax]。为了防止边缘取值使得SVDD模型仍出现一定过拟合或欠拟合,取最优σopt为这段取值的中间值,即σopt=(σmin+σmax)/2。 本文以一条链路的方差和均值为例,展示核惩罚参数C和宽度因子σ对边界的影响,如图4。图4的检测边界为高维空间超球体边界在2维平面上的投影,当惩罚因子C增大时,被排除在边界外的样本点减少,相应地判决边界也有所变化。但当惩罚因子C大于一定值时,惩罚因子对超球体边界的影响较小,图4中,当C=0.4时与C=0.8时超球体边界几乎相同。而当核宽度因子σ增大时,支持向量个数减少,判决边界也有所增大。 在该阶段,首先实时采集每条链路的接收信号强度读数,并进行与离线训练阶段相同的特征提取步骤,构建出ton时刻的特征向量Ston=[ston,1,…,ston,j,…,ston,k]。然后,利用训练出的SVDD模型判断Ston到球中心的距离a=∑iαiSi不小于R,进而感知确定ton时刻环境中是否有人入侵,表示为 mton=‖Ston-a‖2/R2 (14) (14)式中,mton表示在ton时刻环境的异常程度,当mton小于1时,则认为当前感知区域内没有人员活动。否则,则说明当前感知环境中有人活动。 场景1中布置有4个AP和一个MP,具体布置位置如图5a;场景2中布置有3个AP和2个MP,如图5b。首先,进行25 min静默数据的采集,利用滑动窗函数提取相应的信号特征,滑动窗长度值L=20;然后,利用2.2节的方法训练出SVDD入侵检测模型;最后,测试人员在感知区域内任意位置运动或走出感知区域,进行室内入侵检测。 为了验证本文提出的被动检测算法的可靠性和有效性,通常使用虚警率(false positive, FP)、漏检率(false negative, FN)和F1-measure值作为评价指标[1]。虚警率表示感知区域内无人员活动,但是系统却发出告警的概率。漏检率表示感知区域内有人员活动,但是系统却没有检测出来的概率,而正检率(true positive,TP)则与FN相反,其表示感知区域内有人员活动,系统正确检测的概率。F1-measure值则是一种综合评价指标,用来衡量检测算法的有效性,其值为查准率(precision, P)和查全率(recall, R)的调和平均,即F1-measure=2PR/(P+R),其中,查准率P=TP/(P+FP),查全率R=TP/(TP+FN)。 本文选取随机场景下30条传播路径不同的链路,采集静默数据和有人员活动数据,计算每个特征的平均贡献度,结果如图6。根据平均贡献度值的大小对特征重要性进行排序,得到:极差值>方差>平均FFT>均值>最小值>最大值>中值。下面讨论特征数p对检测性能的影响。 从图7可以看出,随着特征数p的增加,虚警率FP和漏检率FN逐渐降低,F1-measure逐渐上升;而当特征数p≥5时,虚警率FP和漏检率FN达到最低并趋于稳定,同时F1-measure达到最大并逐渐稳定。根据2.1.2节所述方法,利用虚警率FP可选择popt=5,此时F1-measure也能达到最高值。 为确定惩罚因子C与高斯核宽度因子σ对入侵检测系统检测性能的影响,本文计算当C=2x,x∈{-10,-9.95,…,0} ,σ=2y,y∈{-2,-1.95,…,8}时,2种实验场景中的虚警率FP,漏警率FN,以及F1-measure值。计算结果分别如图8和图9。 从图8和图9可知,当惩罚因子C较小时(<2-9),L1正则化项对离群点的抑制程度较低,过多的离群点在超球体外部,使得超球体半径R过小,从而导致虚警率较高,但随着C逐渐增加,虚警率逐渐降低,F1-measure值也逐渐升高。可以看出C>2-7后,对系统的检测率影响较小,但为了防止在实际部署时,训练数据中出现过多的异常点从而导致超球体半径过大,漏检率过高的问题,C值不宜较大,故取C=2-4。当高斯核宽度因子σ较小时(<1),系统会因为SVDD模型过拟合而导致虚警率很高,随着σ增大,虚警率逐渐降低,而当σ很大时(>26),系统会因为SVDD模型严重的欠拟合而导致虚警率较高。综合评估指标F1-measure作为综合的评估指标整体呈现出先升后降的趋势,与2.2.3节的结论相符。根据2.2.3节所述方法,只需用一组静默数据作为测试集来计算虚警率,然后可得到最优σ。例如,在场景1中,当σ处于[20.3,25.05]时,虚警率较平稳且小于0.1,取该段的中值也就是σopt=(20.3+25.05)/2≈17.18作为场景1环境下σ的最优取值。 在本节中,将本文中所提出的方法与其他主要基于RSSI的被动入侵检测技术,如MA,MV以及Ichnaea进行性能对比。 首先,分析不同场景下滑动窗长度对不同检测技术F1-measure值的影响,结果如图10。经分析可得F1-measure值随着滑动窗长度的增加呈现出先上升后下降的趋势,这是由于当滑动窗较小时,每个窗内数据量较少,不能有效地表征信号波动特性,因此检测灵敏度较低。而当窗较大时,信号抖动特性在一定程度上被忽略,导致检测性下降,并且检测时延也较长,因此滑动窗长度不宜过大,在本文中滑动窗长度L=20。与其他检测技术相比,本文所提出的方法在不同滑动窗长度下均有较优的检测性能,这是由于使用的最优特征组合,能有效地刻画环境中不同的状态,增强系统的稳定性缘故,因此滑动窗长度对其检测性能的影响较小。 其次,对比不同检测技术的检测性能,表1为性能对比结果。分析表1可知,与现有的基于统计特性的算法相比,本文所提算法在虚警率和漏检率上均有一定程度的降低,而且本文算法F1-measure值在2种场景下分别达到了0.960和0.945,优于经典的Ichnaea系统。 表1 与现有技术的检测性能对比Tab.1 Comparison of detection performance with existing technologies 为了在真实无线环境中实现准确的人员活动检测,本文提出一种基于SVDD的WLAN室内被动入侵检测算法,该算法利用A-distance值评估7种特征对于正确区分正常状态和异常状态的平均贡献度,并根据平均贡献度进行特征重要性排序,选择多个特征有效地区分不同感知环境中的正常状态和异常状态,显著提高检测的准确率。此外,本文算法只需采集正常状态的数据构建SVDD被动入侵检测模型,就能有效降低训练阶段的开销,利用L1正则化抑制离群点的影响,具有较好的抗噪性。实验结果表明,本文提出的方法在2种不同的室内场景下虚警率和漏检率分别低于5%和9%,同时F1-measure值高于94%,检测性能比基于统计特性的算法更优。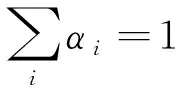
2.3 在线监测阶段
3 实验结果
3.1 测试环境
3.2 评价指标
3.3 随机场景下特征的平均贡献度
3.4 惩罚因子C与高斯核宽度因子σ对检测性能的影响
3.5 性能对比

4 结束语
