OCR文字识别技术的研究
2020-04-30张婷婷马明栋王得玉
张婷婷,马明栋,王得玉
(南京邮电大学,江苏 南京 210003)
0 引 言
OCR的概念于1929年由德国科学家Tausheck最先提出。最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy[1]。在20世纪的60、70年代,世界各个国家对OCR的研究主要集中在对文字的识别方法上,并且仅是对0到9的数字进行识别。而国内在OCR技术的研究相对较晚。在20世纪70年代,国内学者起初研究的是数字、英文字母及符号的识别,70年代末开始研究汉字的识别。
OCR[2]技术在目前互联网及人工智能迅速发展的趋势下,也有了飞速的发展。到目前为止,结合其他方向的技术,特别是人工智能方向,OCR技术已经发展到可以识别带有地理位置信息的图纸,可以对文字进行高精度的识别,包括生僻字在内的情况[3]。
OCR技术也普遍应用在日常生活,最为熟悉的是百度网页可以拍照识别图纸上的题目文字,另外还有百度AI输入法中的一系列文字识别功能,包括:身份证识别、名片识别、表格识别等等[4]。
1 图像输入预处理
图像输入,对其进行预处理操作。对于不同格式的图像,有着不同的存储格式和压缩方式[5]。文中的图像输入,上传图片方法是实现客户端上传一张本地图片或者使用抓包工具postman向百度服务器发送url请求[6]时设置参数添加一张本地带汉字的图片。
预处理过程,是使用阈值分割法把图片上每个像素二值化[7]。以下是用Java语言实现的预处理函数,函数是根据图片高度和宽度遍历图片上的每个像素点,通过ISWHITE来判断当前像素值。
Int width=img.getWidth();
Int height=img.getHeight();
For(int x=0;x For(int y=0;y If(ISWHITE(img.getRGB(x, y))==1) { Img.setRGB(x,y,color.WHITE.getRGB()); //像素红绿蓝在一定范围置成白色 } else { Img.setRGB(x,y,color.WHITE.getRGB()); //反之置成黑色 } } } 灰度化处理,在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值。灰度图每个像素只需一个字节存放灰度值[8],其范围是0~255。将彩色图像中的三分量的亮度作为三个灰度图像的灰度值[9]。其中fk(i,j)(k=1,2,3)为转换后的灰度图像在(i,j)处的灰度值。采用分量方法[10]: f1(i,j)=R(i,j) (1) f2(i,j)=G(i,j) (2) f3(i,j)=B(i,j) (3) 二值化过程[11],根据灰度图像中像素的灰度级值的取值范围为c0[12],希望能够更加显现出图像中的文字部分,一般图像中的文字为黑色,在灰度图像中灰度值较小。二值化过程使用Otsu算法实现,Otsu算法又称为最大类间方差法[13]。 设一幅图像大小为(M*N),f(x,y)是该图像中点(x,y)处像素的灰度值,灰度级为L,则f(x,y)∈[0,L-1]。若灰度级i的所有像素个数为fi,则第i级灰度出现的概率为: (4) (5) 将图像中的像素按灰度级用阈值t划分为两类,即背景c0和目标c1[14]。背景c0的灰度级为0~t-1,目标的灰度级为t~L-1。背景c0和目标c1对应的像素分别为f(i,j)。背景c0部分出现的概率和目标c1部分出现的概率分别为: (6) (7) 其中,w0+w1=1。 背景c0部分和目标c1部分的平均灰度值分别为: (8) (9) 图像的总平均灰度值为: (10) 图像中背景和目标的类间方差为: δ2(k)=w0(u-u0)2+w1(u-u1)2 (11) 令k的取值从0~L-1变化,计算不同k值下的类间方差δ2(k),使得类间方差δ2(k)最大时的那个值就是所要的最佳阈值。 图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。图像分割方法近年来又有新型神经网络图像分割法,文中使用阈值分割法进行图像分割。 阈值分割方法实际上是输入图像f到输出图像g的变换[15],公式如下: (12) 其中,T为阈值,对于物体的图像元素g(i,j)=1,对于背景的图像元素g(i,j)=0。 如果能确定一个合适的阈值就可准确地将图像分割开来。阈值确定后,将阈值与像素点的灰度值逐个进行比较,而且像素分割可对各像素并行地进行,分割的结果直接给出图像区域[16]。 前边的图像处理都是为此步骤做铺垫。二值化和图像分割已经将字符提取出来,但是以单个汉字为基础的识别要将每个字从图像中提取出来[17]。文中的汉字识别,主要借助百度的OCR识别技术,识别出通用字。 此测试环境需要的配置如下: (1)百度官方的Java SDK压缩包; (2)Jdk需要1.7以上; (3)IDE使用Eclipse新建工程,导入下载的工具包; (4)配置通用文字识别的客服端,以及服务器代理设置,代码如下: Public class test { Public static void main(string[] args) { AipOcr Client=new AipOcr(app_id,api_key,secret_key); //网络设置 Client.setConnectionTimeoutInMillis(2000); Client.setSocketTimeoutInMillis(60000); //代理设置,http代理 Client.setHttpProxy(“proxy_host”,proxy_port); //接口调用 String path=“test.jpg”; JSONObject res=client.basicGeneral(path,new HashMap System.out.println(res.toString(2)); } } 上述代码中接口说明如表1所示。 表1 测试代码接口说明 向服务器请求识别某张图片中的所有文字。Java语言的配置代码如下: public void sample(AipOcr client) { //传入可选参数调用接口 HashMap options.put(“language_type”,“CHN_ENG”); options.put(“detect_direction”,“true”); options.put(“detect_language”,“true”); options.put(“probability”,“true”); //参数为本地路径 String image=“test.jpg”; JSONObject res=client.basicGeneral(image,options); System.out.println(res.toString(2)); //参数为二进制数组 byte[] file=readFile(“test.jpg”); res=client.basicGeneral(file,options); System.out.println(res.toString(2)); //通用文字识别, 图片参数为远程url图片 JSONObject res = client.basicGeneralUrl(url, options); System.out.println(res.toString(2)); } Postman使用post方法请求识别图片文字,请求参数设置如表2所示。 表2 url请求参数设置 请求返回结果参数说明如表3所示。 表3 请求结果参数说明 介绍了OCR识别的过程和相应模块的代码实现,理论公式推导。国内在OCR方向上的发展是很迅速的,尤其是国内公司在其上的应用,这种技术已经渗透到日常手机打字的软件百度输入法中。文中的二值化方法只是平常方法中的一个,还有其他很多方法未涉及,图像分割也是如此。 OCR大体可以分为两类:手写体识别和印刷体识别。文中使用Java语言基于百度OCR的API实现OCR扫描识别印刷体图片上文字的一个客户端(普通文字识别),操作可以借助百度公司OCR的API利用抓包工具postman向其服务器发送post请求,在请求参数中带上一张带有文字的图片或者使用实现的客户端进行图片上传识别。还介绍了图像文字识别刚开始的图像处理,其中图像分割步骤至关重要,是识别率高的关键点。文中默认识别通用文字中文,高精度的识别或者带位置信息的识别,生僻字的识别,此处不做研究。Post请求提交时,请求头Header设置为x-wwww-form-urlencoded形式。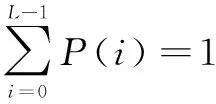

2 图像分割

3 汉字识别



4 结束语
