大数据下的基于主题模型的社交网络链接预测
2020-04-30骆梅柳裴可锋
骆梅柳,裴可锋
(1.南京航空航天大学,江苏 南京 211106;2.江苏财会职业学院 信息系,江苏 连云港 222061)
0 引 言
时至今日,随着计算机技术和网络的高速发展,大数据成为当下研究的热点。大数据时代巨大的数据量,繁杂的异构信息不仅影响着人们的生活,而且对一些研究领域提出了新的挑战,这其中就包括社交网络链接预测研究。
20世纪90年代以来,社交网络不断地融入人们的生活,web2.0技术的发展包括微博、微信、Twitter等社交媒体,更是大大加快了这一进程。通过这些社交媒体构成的社交网络,人们分享自己喜欢的事物,交流想法,结交朋友。社交网络已经与人们的生活息息相关,因此社交网络分析俨然已成为当前社会科学以及计算机学科研究的热点话题。
作为复杂网络分析的分支研究任务,社会网络链接预测是根据已知的社交网络中的用户,社交网络结构等信息,预测尚未“结交”的用户建立链接成为朋友的可能性[1]。通过计算推荐可以快速查找到社交网络中的好友、社区发现等,更有利于丰富网络演化模型的理论研究。其虽然也是数据挖掘中地一个子领域,但是不同于其他挖掘领域关注于数据内容信息本身,链接预测一般关注的是网络的结构信息。例如,Common Neighber,Salton,RA等算法都是针对节点间的关联关系来进行预测的。但是随着大数据时代的到来,仅仅获取用户节点间的结构信息已不足以进行准确有效的社交网络预测。
卢文羊等人[2]提出基于LDA主题模型的协作演化链接预测算法,虽然提高了预测效果,但并没有很好地结合结构相似度信息。吴梦蝶等人[3]基于主题模型分析节点语义信息,综合节点属性特征和网络结构特征进行链接预测,但是在节点属性特征中没有考虑到命名实体和联系特征在用户区分中的重要作用。
基于传统社交网络链接预测在大数据时代下的不足,文中以微博用户链接预测为例,提出挖掘社交网络中的文本信息与节点间的结构信息相结合的方法对社交网络链接进行预测。
1 主题模型
主题模型[4]是一种能够对大规模文档集中的文字所隐含的主题进行有效分析并进行数学建模的方法,将每一篇文档看作一个关于主题的概率分布,而每一个主题又看作是一个关于单词的概率分布。现有存在的主题模型有很多种,包括PLSA、LDA等。由于LDA模型采用无监督的方法,适用于大规模文本语料,计算高效,因此文中采用LDA模型对文本进行主题建模。
LDA模型是一种基于分层的贝叶斯模型[5],由Blei等人在2003年提出,LDA的分层主要是分为文档、主题及词三个层次。LDA模型地核心思想是应用词袋模型的方法,将语料库的每一个文档都视为若干潜在主题的混合分布,每个主题的确定由词汇库中所有单词的概率分布决定[6]。通过将库的文档看作是一个词频向量,可将文本有用信息构建成易于建模的数字信息[7]。LDA模型的文本生成过程如图1所示。
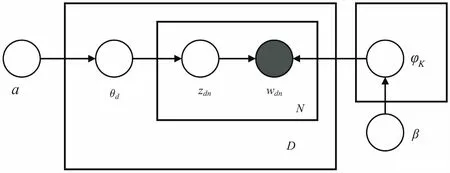
图1 隐Dirichlet分配主题模型
(1)根据Poission分布,抽取文本长度,N~Poission(φ);
(2)根据狄里克雷分布系数α,得到该文档主题概率分布,θ~Dir(α);
(3)根据狄里克雷分布系数β,生成k个主题的主题-词的概率分布φ,φ~Dir(β);
(4)对长度为N的文档中的每一字Wn:
·从已知的主题分布θ中通过多项式分布得到这个字的主题Zn,Zn~Multinomial(θ)。
·根据Zn,选择该主题对应的词概率分布φzn,通过多项式分布选择出该字Wn~Multinomial(φzn)。
其中θ和φ是两个需要估计的参数。由于难以直接求出这两个参数,因此可以采用Gibbs抽样迭代法进行求解。
2 社交网络链接预测模型
2.1 总体框架
文中对社交网络链接进行预测是通过判断节点的相似度来预测两个节点间是否会链接。对节点相似度的判断主要针对如下几个方面:
(1)基于节点属性的用户兴趣特征;(2)基于网络拓扑结构的特征。
其中,基于节点属性的用户兴趣特征相似度度量主要包含三个部分:首先,利用LDA模型对用户发表的微博信息进行主题建模得到该用户的主题信息,并利用KL距离进行相似度度量;其次,对用户微博信息中的命名实体进行识别,根据不同用户相同命名实体数量计算用户间的相似度;最后根据用户微博特征如转发或者@,找出用户共同转发的微博数或者@同一个人次数,从而进行用户相似度的度量。而基于网络拓扑结构的相似性分析则可以通过目前预测效果比较好的RA指数进行度量。
最后,综合上述的各个部分可以得出每个节点代表的用户相似性,从而进行预测。预测结果可以通过链接预测的常用评价指标AUC进行计算。总体框架如图2所示。
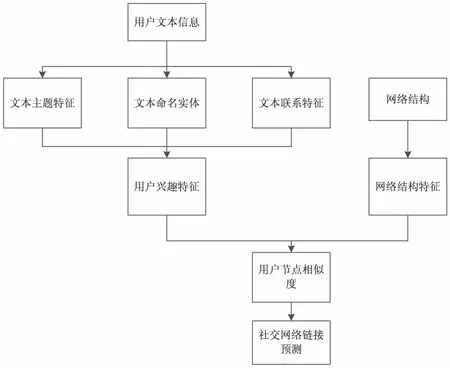
图2 社交网络链接预测模型总体框架
2.2 用户兴趣特征相似度度量
文中将用户兴趣相似度分为三个方面:文本主题特征度量、文本命名实体度量、文本联系特征度量。
2.2.1 文本主题特征度量
这部分是用户兴趣特征度量的重点。主题模型出现之前,一般采用用户词汇矩阵来对不同的用户进行标注,即通过统计用户使用词汇概率的不同来进行用户识别,但是由于词汇的数量很多,而且不同单词之间出现频率相差很大,造成稀疏性和度量的不准确性。而采用LDA主题模型将用户与词汇间的维度转化为两个维度,一是用户与主题,二是主题与词汇,这样可以解决稀疏性和度量的不准确性的问题,如图3所示。
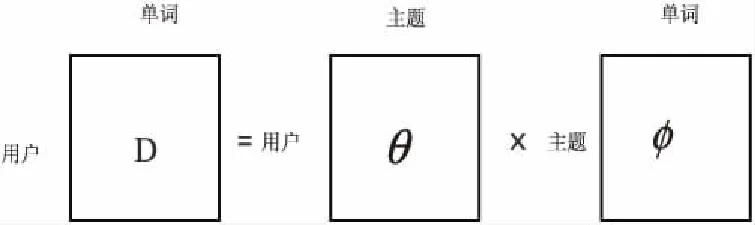
图3 文本主题特征度量
通过LDA过程可以得到两个矩阵:用户主题矩阵、主题单词矩阵。应用用户主题矩阵得到各个用户的主题向量表示θi={pi1,pi2,…,pik},i表示第i个用户,Pij表示第i个用户在第j个主题下的概率。不同的用户概率主题向量必然不同。可以通过度量用户概率主题向量的相似度来度量用户兴趣的相似度。可以利用KL散度(相对熵)来计算两个概率分布的相关度[8]:
(1)
其中,pi和pj分别表示第i个用户和第j个用户的主题向量,KL散度越大表示两个用户之间的相关度越大。
2.2.2 文本命名实体度量
命名实体是以名称为标识的实体,比如人名、机构名等,还包括数字、日期等[5]。在用户微博文本表示中,命名实体如人名、地名等在用户所要表达的思想中具有重要的意义,通过这些命名实体可以看出用户关注的人或地点等甚至可以标注出用户在现实中所处的环境。但是对用户具有标识作用的人名和地名在表达中并不是经常出现的,因此常常被归类到低频词中。通过LDA将用户映射到主题空间的过程中,命名实体这类特殊低频词往往会被忽略掉,从而不能发挥任何作用。所以利用LDA模型将用户文本主题化之后,进行文本命名实体分析是有意义的。
命名实体识别目前是一个比较热的研究领域,已有工具可以较准确地识别出文本中的命名实体[9]。通过判断不同用户微博中出现的命名实体相同数量可以反映用户之间的相似性。令Nx为用户x的命名实体集,Ny是用户y的命名实体集。不同于主题向量的比较,用户之间基于命名实体的相似性还与共同命名实体占各自总命名实体比例有关系。如果用户x与用户y的共同命名实体数量占其自身很小的比率,用户的相似性就应该较小,反之比率越大则相似性越大。另一方面,可能共同部分占x总比重相对较小,占y总比重相对较大,则x接受y产生链接概率就小,y的概率就相对较大。因此是不对称的。用户x链接到用户y的概率可以表示为:
(2)
数值越大,表示用户x会链接到用户y的可能性越大。
2.2.3 文本联系特征度量
微博是目前主流的网络社交媒体,其具有实时性强、短小精炼等特征。微博的一大特点是可以转发别人的微博以及可以@某人与其进行互动。显然,用户的转发和@构成了用户的重要标识特征。与上一小节类似,进行语义分析主题建模并不能充分有效地把这部分重要的信息利用起来,所以在进行用户兴趣相似度度量时可以把这部分内容加进去。
统计用户转发的微博及@的用户名,比较两个用户在这方面的相似性能在一定程度上反映用户之间的相似性。类似命名实体的度量,根据两个用户共同部分的数量比各自的总数量来衡量用户链接到另一用户的可能性大小。数值越大,可能性越大。用户x链接到用户y的概率计算公式[10]如下:
(3)
其中,Ax表示用户x转发微博数量地集合,Bx表示用户x@用户名的集合,Ax∩y表示用户x与用户y共同转发的微博数量,Bx∩y同理。
将上述文本主题特征、命名实体、联系特征三个方面得到的用户间相似度度量进行整合,可以得到用户节点的兴趣相似度量。因为三个方面都是与用户兴趣相似度正相关,所以可以通过这几个指标的简单累加得出用户兴趣相似度量的值。计算公式如下:
g(x,y)=KL(px||py)+p1(x,y)+p2(x,y)
(4)
2.3 网络结构相似度度量
社交网络结构是存在网络结构中各个用户节点之间链接状态,在网络中有效提高链接预测的准确度,需要准确掌握社交网络各个节点网络结构[11]。目前在基于节点相似度的链接预测中应用较多的预测方法有CN(common neighbor)、RA(recourses allocation)、AA(Adamic-Adar)等,其中应用较多、预测效果较好的方法是RA[12]。
RA是指网络中两个节点之间不存在直接相连,但它们之间传递资源是通过两个节点之间的邻居来完成。公式定义为:
(5)
2.4 节点相似度计算
将网络结构相似度和用户兴趣相似度进行结合,计算出所要求的节点相似度,计算公式如下:
Sxy=g(x,y)+u*RAxy
(6)
其中,u用于调节两类特征值在节点相似度计算中的权重,可以通过实验进行确定。
3 实 验
3.1 实验数据集
以微博社交网络为数据源,使用了微博堂中分享的63 641个微博用户的新浪微博数据集,其中包括用户uid、用户昵称、用户姓名、用户所在地、微博数等用户信息以及84 168条在2018-05-03至2018-05-11采集的关于12个主题的微博信息,1 391 718条用户好友关系,27 759条微博转发关系,以满足实验需要。分析微博用户之间的用户关系,利用好友关系构建社交网络
3.2 实验方法
在训练集上采用文中提出的方法进行链接预测。首先采用RA指数计算网络中各个节点的结构相似性,以此作为拓扑结构相似性度量。然后是主题模型的求取。由于微博文本短小的特点,合并同一个用户所有的微博内容,利用LDA模型对其进行分析处理。根据数据集,网络主题数设置为12,得到各个用户对12个主题的概率分布,并利用KL距离得到用户间主题相似度,利用各个节点得到的命名实体集和转发关系,@特征集从而得到上一小节的命名实体相似度和特征实体相似度,得到用户间兴趣相似度并利用最后的合成公式得到最终的节点相似度对微博网络链接进行预测,其中取参数u为0.8。作为对比,采用仅考虑节点属性的方法以及仅计算RA指数的方法对测试集进行链接预测。
3.3 实验结果评价指标
文中应用链接预测最常用的评价体系AUC来评价链接预测方法的效果。AUC[13]通常是指从整体上评价链接预测方法的精确度。AUC的具体作法是分别从测试集和不存在的边中随机抽取n次,对两者的分数进行比较,边的分数即是链接存在的可能性。文中用两个顶点的相似度表示,AUC用公式表示为:
(7)
其中,n'表示测试集中边的分数大于不存在的边的次数,n''表示两者相等的次数。若所有的评分值都来自于独立同分布的情况,则AUC的值在0.5到1之间,AUC的值大0.5的程度越大、越靠近1,表示该算法的执行效果比随机的执行效果越好,链接预测准确度越高[14]。
3.4 实验结果
使用AUC方法分别对三种方法的预测结果进行评价,随机从测试集和不存在的边中抽取n次进行比较,n分别取500,1 000和3 000三种情况,结果见表1。
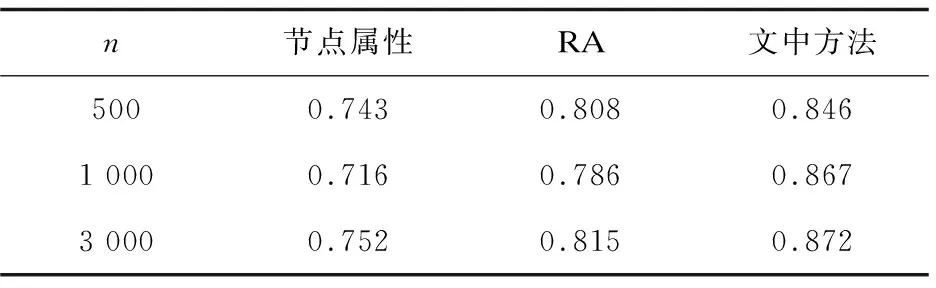
表1 链接预测AUC
其中节点属性一列表示单考虑用户兴趣相似度得到的AUC值,RA表示采用仅考虑网络结构相似度得到的AUC值,最后一列表示采用文中方法得到的AUC值。明显可以看出,文中方法的预测精度更高。
4 结束语
面对大数据时代带来的挑战,提出了一种基于主题模型的社会网络链接预测算法。在传统的基于网络结构相似性计算节点相似性的基础上,利用LDA为代表的主题模型挖掘用户的兴趣相似度,同时结合用户的命名实体集和联系特征集对用户兴趣相似度的计算进行补充完善,最后得出用户节点相似度从而进行社交网络进行预测。在微博的数据集上,将文中方法与使用节点属性、RA指数的方法进行比较,结果表明该方法预测效果更优。
