一种轻量级的多尺度特征人脸检测方法
2020-04-30程宾洋
朱 鹏,陈 虎*,李 科,程宾洋
(1.四川大学 计算机学院,四川 成都 610065;2.四川大学 视觉合成图形图像技术国防重点学科实验室,四川 成都 610065;3.四川川大智胜软件股份有限公司,四川 成都 610045)
1 概 述
早期人脸检测算法大多使用的是模板匹配技术。其中具有代表性的是Rowley等人提出的基于神经网络的正面人脸检测系统[1],通过滑动窗口检测图像,并确定每个窗口是否包含面部,用20×20的人脸和非人脸图像训练了一个多层感知器模型,该系统在多个网络之间进行判断,从而提高单个网络的性能,主要解决近似正面的人脸检测问题。在后续Rowley对算法的更新中,加入了角度估计器[2],可对待检测区域进行旋转从而再进行正面人脸检测。不过由于复杂的分类器设计和密集的滑动窗口采样需要大量的运算,使得检测速度差强人意。
2001年Viola和Jones设计了一种基于AdaBoost分类器的人脸检测算法[3],使用简单的Haar-like特征和级联的AdaBoost分类器对滑动窗口中的候选框进行判定,同时为了提高效率,引用了积分图(integral image)机制。在深度学习出现之前,工程中使用的人脸检测大多都是基于该算法的延伸。但是由于Haar-like是相对简单的一种特征,所以其稳定性较低;同时AdaBoost弱分类器采用简单的决策树,对正面人脸的检测效果较好,但是对于各种人脸姿态、表情和遮挡等特殊复杂情况检测效果并不理想;并且在该算法的分类器设计中,对一个样本的评价不会基于该样本在之前阶段中的表现,所以分类器的鲁棒性差。基于该方法的后续研究中,使用了其他特征,比如局部的二进制模式(LBP)[4]和颜色特征[5],使得检测效果得到了很大的改进,并且在此基础上用于人脸追踪[6]。
2008年Felzenszwalb提出基于DMP(deformable part model)模型的人脸检测算法[7],采用FHOG(对HOG的改动)进行特征的提取,该算法在多姿态、多角度和遮挡等场景下的检测效果要优于Viola和Jones提出的算法效果,但是由于该模型的计算量过大,达不到实时性的要求,所以在实际工程中很少采用。
自2012年AlexNet在ILSVRC(imagenet large scale visual recognition challenge)的图像分类比赛中取得突破性成绩后,卷积神经网络很快运用到图像处理和目标检测中,并同样取得重大进展[8]。通过卷积神经网络能够让网络更好地获取到目标各个层级的特征,从而增强了网络对外界环境的鲁棒性。
Cascade CNN是传统检测向深度网络过渡的代表[9],由Li Haoxiang等人提出,和Viola-Jones的人脸检测器相似,采用级联的方式组织多个分类器,不同的是每一级的分类器由卷积神经网络组成,并且构建图像金字塔,通过滑动窗口将待检测区域送入三个网络中进行回归校正,通常第一个网络就可以剔除绝大多数负样本,同时每个网络间采用NMS(non-maximum suppression)算法去除高度重叠的区域。之后的MTCNN网络[10]也是借鉴了Cascade CNN模型的思想。随后的研究[11]中,使用L2损失与三元组损失相结合的总损失函数,减少漏检;在文献[12]中还使用了两层级联网络;在文献[13]中,级联网络之间加入了图像金字塔;这些改进都取得了较好的检测效果。
文中提出的模型是基于SSH(single stage headless)[14]的人脸检测模型,SSH最大的特点就是尺度不相关性(scale-invariant),MTCNN是对待检测图像的不同尺度分别进行预测,如此一来计算量会大大增加,而SSH只需要一个尺度的图像就可以预测,实现了one stage的人脸检测。其原理是利用3个检测模块(M1,M2,M3)分别对主干VGG网络的3个不同特征图进行预测,每个检测模块都包含检测和分类,通过对不同尺度的特征图进行预测,实现了多尺度的人脸检测,但是传统VGG网络的计算量相对较大,网络参数也相对较多。文中的主干网络参考了当前先进Mobile-Net[15]结构的思想,设计出了一种轻量级网络结构,该网络主要由多个3×3,1×1卷积核和传统卷积核构成,将一个标准卷积分解为一个深度卷积和一个点卷积(1×1卷积核),在保证卷积效果的同时大大缩减了计算复杂度,从而提高了检测效率。此外,模型的检测模块融合多个卷积特征,可以获得更多的上下文信息以及更大的感受野,从而提升检测性能。
2 设计方法
2.1 整体框架
该方法是在caffe深度学习框架下设计和训练的,该框架具有简洁快速的特点。网络模型由1个主干网络和3个检测模块构成。主干网络未使用标准卷积,而是将一个标准卷积分解为一个深度卷积和点卷积(1×1卷积核),从而减少运算量和参数,提高运算效率,降低内存消耗;同时主干网络在每一层卷积后都会加入批量归一化(batch normal),加快模型收敛速度,避免网络的梯度消失或爆炸问题,并减少网络对初始参数的依赖;3个检测模块(M1,M2,M3)分别检测主干网络中3个不同尺度的特征图,以检测不同大小的目标,其中检测模块包含目标分类和框体回归操作,由一个普通的3×3卷积,一个context Module和两个1×1卷积组成。context Module为了获得更多的上下文信息和更大的感受野,使用了5×5和7×7的卷积核分别进行卷积操作,然后使用concat融合特征;另外网络去除了全连接层,使用1×1卷积核代替全连接层,使得网络的输入可以像Faster RCNN[16]一样输入不同尺寸的图片,同时减少模型参数。总体来说,文中提出的模型考虑了效率和准确度,既能保证检测精度,又能达到人脸的实时检测,可应用于实际的工程中。
网络模型的总体结构如图1所示。
其中M1、M2和M3分别表示检测模块1、检测模块2和检测模块3,分别用于检测小目标、中目标和大目标。
2.2 主干网络设计
文中提出的主干网络参考了深度可分离卷积[17]的方法,该方法的核心是将一个传统卷积分离为深度卷积(depthwise convolution)和一个1×1的卷积(pointwise convolution),在尽量提取特征的同时,减少网络参数和网络计算量。结合多尺度特征提取的思想和人脸检测的实际场景应用,设计出了一种传统卷积和深度可分离卷积相结合的,轻量级的,具备实时性的主干网络。现有一个输入为W×W×C×1的特征,如图2所示将传统卷积分解成深度可分离卷积。
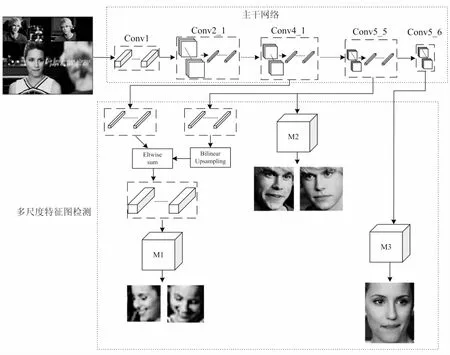
图1 模型总体结构

图2 深度可分离卷积
其中k、S、C和N分别为卷积核的标识、卷积核的尺寸、输入特征图的深度和输出特征图的深度。深度卷积中每个卷积核的通道数为1,并且分别与输入特征图的单个相应通道做卷积运算,即对每个输入特征的通道应用一个深度卷积核,如第一个深度卷积核和输入特征的第一个通道做卷积;现假设有一个Dinput×Dinput×C的输入特征图(Dinput为输入特征图的尺寸),经过stride为1,卷积核为Sk×Sk×C×N的卷积操作输出Doutput×Doutput×N的特征图(Doutput为输出特征图的尺寸),令Doutput=Dinput,则传统卷积操作的计算量Amount(g)为:
Amount(g)=Sk×Sk×C×N×Dinput×Dinput
(1)
深度可分离卷积的计算量Amount(ds)为:
Amount(ds)=Sk×Sk×Dinput×Dinput+C×N×Dinput×Dinput
(2)
那么深度可分离卷积和传统卷积的计算量之比为:
(3)
综上,若输入224×224×64的特征图,经过3×3的卷积核输出224×224×128的特征图,那么两者的计算量之比约为0.118 9,也就是说使用深度可分离卷积操作,计算量可缩减为传统卷积的1/9左右,运算速度大幅提升。
主干网络中的一组深度可分离卷积的结构如图3所示。

图3 一组深度可分离卷积
主干网络输入为224×224×3×1的图像数据,在网络中的参数变化如表1所示:主干网络总共26个卷积层,没有池化层。网络最终输出特征图的尺寸为7×7×512×1。

表1 主干网络参数
2.3 检测模块设计
检测模块也是一个全卷积网络,分为三个检测模型M1、M2和M3分别抽取主干网络中Conv4_1、Conv5_5和Conv5_6层的3个不同尺度特征图,对应的stride为8、16和32,再分别对这三个尺度的特征图进行预测,包括人脸分类和人脸框体回归。
2.3.1 多尺度特征图
主干网络中Conv4_1、Conv5_5和Conv5_6层生成的特征图尺寸分别为28×28×256、14×14×512和7×7×512,其中低层的感受野较小用于检测小目标,高层的感受野较大用于检测大目标,不同尺寸的特征图可以获取多尺度的特征映射。
M2和M3检测模块都是直接从主干网络中获取特征图,而M1检测模块融合了Conv4_1和Conv5_5层的特征图,首先对Conv4_1和Conv5_5层的输出采用1×1卷积核,降维得到28×28×128和14×14×128尺寸的特征图,并对Conv5_5采取双线性上采样输出尺寸为28×28×128的特征图,再将两个特征图采用对应元素相加的方式进行特征融合,融合后得到28×28×128的特征图,经过一个3×3×128×128的卷积再送入M1检测模块。这样做的主要目的是为了增加M1检测模块的语义信息。
综上,通过检测不同尺度的特征,可以检测到不同大小的目标。如图4所示,浅层的M1检测模块可以更好地获取到小目标人脸特征,而更深层的M2检测模块则无法获取到小目标人脸特征。

图4 多尺度特征检测热力图
2.3.2 检测模块
M1、M2和M3检测模块的结构相似,区别在于输入的特征图大小不同,对应的stride分别为8、16和32,同时M1的输入特征通道数为128,而M2和M3都是512。检测模块结构如图5所示,每个检测模块都包含人脸分类和框体回归,进行框体回归的时候,定义一系列边界框(anchor),通过回归的方式逐渐使其靠近真实的人脸框。类似Faster-RCNN中的RPN思想使用密集的滑动窗去定义一系列的anchor,在每个检测模块特征图的任一被滑动窗口覆盖的区域,定义具有和当前滑动窗口相同中心位置但尺度不同的K个anchor,每个anchor对应一个尺度,原始的RPN中K个anchor具有不同的长宽比,文中所有的anchor长宽比都设为1,因为人脸的长和宽差距不大;假设一个特征图的大小为W×H,那么最终就会得到W×H×K个长宽比为1,尺度不同的anchor。
如图5所示,首先检测模块对输入特征分别进行两种卷积,一种是普通的3×3卷积,另一种是Context Model;接着将普通的3×3卷积和Context Model进行channel维度上的拼接,最后两个1×1的卷积层用于框体回归和人脸分类,分类器决定当前卷积核覆盖的中心位置的各个尺度的图像是否为人脸。最终输出W/S×H/S×2K个分类得分和W/S×H/S×4K个回归坐标。

图5 检测模块结构
图5中Context Model的具体结构如图6所示。在two-stage检测中,通常会通过扩大候选区域的窗口来合并上下文信息,文中的Context Model通过简单的卷积层来模仿这种策略来合并上下文信息,由于anchor是以卷积方式进行分类和回归的,所以通过使用更大的卷积核就可以实现类似two-stage检测中的扩大候选框的方式。Context Model采用5×5和7×7的卷积核,这样可以增加对应层的感受野,同时也增加了每个检测模块中的目标尺度;为了减少模型的参数量,并提高网络的非线性表达能力,采用两个3×3的滤波器和三个3×3的滤波器替代5×5和7×7的滤波器,该方法和文献[18]中提到的类似。Context Model输出通道的个数为C1,M1、M2和M3的C1分别为128、256和256。

图6 Context Model
3 训 练
使用动量梯度下降和权值衰减的方式训练网络。因为该网络通过3个检测模块来实现多尺度的人脸检测,所以训练过程中需要使用3个相互独立的loss。为了使得3个检测模块针对相应的尺度进行检测,在训练的时候为每个模块分配特定尺度范围的anchor,将最小尺度的anchor分配给M1模块,中等尺度的分配给M2模块,最大尺度的分配给M3模块,同时只将属于该检测模块尺寸的人脸的分类和回归损失值进行反向传播。另外当且仅当一个anchor与真实人脸之间的IOU(预测框和真实框的重叠指标)大于0.5时,才将该anchor与真实人脸区域进行对比,所以反向传播不会迭代与真实人脸区域不匹配的anchor。
3.1 损失函数
损失函数J如式(4)所示,其中lc为人脸分类loss,使用标准的多项log的loss。k为检测模块的索引Mk,并且Ak表示定义在Mk中的anchor集合。在Mk中第i个anchor和对应真实人脸区域的标签分别表示为pi和gi。anchor中的正样本与真实人脸区域的IOU超过0.5,负样本与真实人脸区域的IOU小于0.5。Nrk为模块Mk中的anchor个数,会参与到分类loss的计算。
(4)

3.2 困难样例挖掘(OHEM)
由于实际情况中正负样本不均衡,因此对每个检测模块进行OHEM[19],即使用负样本中与真实人脸区域的IOU最大的样本与正样本中与真实人脸区域的IOU最小(大于0.5)的样本组成一个小批量进行训练,不过由于负样本通常会很多,所以这里选取25%的小批量作为正样本。
4 结果分析
文中提出的算法在FDDB(face data set and benchmark)数据集上进行评测,FDDB数据集是评估人脸检测算法性能最常用的大型数据集之一,这个数据集拥有2 845张有人脸的互联网新闻图像,总共标记了5 171张人脸。数据集在人脸姿态、表情、光照、清晰度、分辨率、遮挡程度等方面具有很大的多样性,贴近真实应用场景,因此成为最受欢迎、最权威的数据集之一。FDDB提出两种类型的图像检测评分,分别是离散分数和连续分数。在第一种评分下,关注的是检测框和标注框之间的IOU是否超过0.5,而第二种评分下关注的则是检测框和标注框之间的IOU越大越好。文中提出的算法采用离散分数的方法进行评测。图7为此算法与当下表现较好的DP2MFD[20]、FaceNess[21]、CCF、CascadeCNN[9]、Acf[22]、VJ算法的对比结果,其中CCF为级联分类器,使用的是Haar-like矩形特征。其中横坐标表示假正类的个数,纵坐标表示真正类率。可以看出,文中提出的算法优于其他算法,最终的真正类率可达到93.52%。

图7 FDDB数据集ROC曲线
另外运用该算法分别对AFW(annotated faces in the wile)、FDDB和WiderFace数据集的部分数据做检测,检测效果如图8所示。可以看到,测试数据中的人脸包括不同尺度,不同姿态,不同装扮和不同光照的情况,但是算法鲁棒性强,检测的准确度很高。

图8 算法检测效果
最后,对算法的运算速度进行实验,选用包含8张不同尺度人脸的640×480的图像,在Intel(R) Core(TM) i5-7500 CPU @3.40 GHz×2的CPU处理上的检测速度达到2 FPS,虽然在CPU上的表现较为平庸,但是在普通的NVIDA GeForce GTX 1050Ti 4g显卡上面的检测速度达到40 FPS。这得益于深度可分离卷积的思想,通过将普通卷积分解为一个深度卷积和1×1卷积,减少运算量,并且使用不同尺度的特征图,没有使用图像金字塔。实验表明该算法在普通GPU可以达到实时的人脸检测,可应用于实际场景。
5 结束语
为了提高检测速度,采用深度可分离卷积代替普通卷积,减少计算量,同时减少模型参数和内存,最终模型参数内存为25.4 M;同时将主干网络中的不同尺度特征图输出到不同的检测模块,实现不同尺度人脸的检测;此外,网络去除全连接层,使用1×1卷积代替,从而进一步减少模型参数,并且网络可以输入不同大小的图像。另外该人脸检测算法实现Single-Stage检测,便于训练和测试的部署;模型基于caffe深度学习框架,具体良好的可移植性。最后,该算法在公开人脸数据库上的检测表现优异,且在GPU上的检测速度满足实时性要求。不足之处在于该算法在CPU上的运算速度并不理想,后续会考虑融入更加轻量型算法的思想,提升CPU检测速度,从而运用到配置更低的设备中。
