MeGAN:基于多任务增强生成对抗网络的图像合成
2020-04-29彭进业曹煜章勇勤彭先霖李展王珺张群喜杨蕊
彭进业 曹煜 章勇勤 彭先霖 李展 王珺 张群喜 杨蕊


【主持人语】随着科学技术的快速发展,人工智能技术已被广泛应用于人类生活的各个方面。为了让人工智能更好地服务于人类,首要需求是“理解人类”:理解人的情感和行为,进而模仿人类与人交流。因此,我们认为以理解人类为中心的人工智能技术将是一个重要的研究方向。与理解人类的语音信号分析和自然语言处理问题不同,计算机视觉任务更加宽泛。在当前的计算机视觉领域,面向理解人类的研究主要集中在人脸分析和行为分析。针对这一新兴的研究热点,本栏目将探讨基于计算机视觉的人脸表情识别、表情合成和行为分析等相关问题,提出解决办法,为以理解人类为中心的人工智能技术应用抛砖引玉。
【主持人】彭进业,教授,博士生导师,西北大学信息科学与技术学院院长,教育部创新团队负责人。
摘要:在计算机视觉领域,现有图像合成方法通常采用一对一的映射网络生成人脸表情,存在很大的建模局限性,难以表达丰富多样、复杂多变的人脸表情。为此,该文提出一种基于多任务增强生成对抗网络的图像合成方法。该方法构建多任务学习框架,改善人脸表情生成的多样性;通过设计双域卷积模块,利用具有补偿的频域信息改善空域特征映射;引入多尺度自适应激活函数,对不同特征进行自适应修正,进一步提升网络性能和特征映射效果。实验结果表明,该文方法能够同时生成多种逼真的人脸表情图像,与现有先进的图像合成方法相比,具有更好的定性和定量评估结果。
关键词:深度学习;生成对抗网络;图像合成;人脸表情;多任务学习
中图分类号:TP391.41
DOI:10.16152/j.cnki.xdxbzr.2020-03-001
MeGAN: Multi-task enhanced generative adversarialnetwork for image synthesis
PENG JinyeCAO YuZHANG YongqinPENG Xianlin LI Zhan WANG JunZHANG Qunxi3, YANG Rui4
Abstract: In computer vision fields, existing image synthesis methods usually feature a one-to-one mapping network to generate facial expressions. But they have the inherent limitations, which hinder the accurate representation of diverse facial expressions. For this reason, a novel multi-task enhanced generative adversarial network (MeGAN) for facial image synthesis is proposed. This network adopts a multi-task learning framework to improve the diversity of facial expression generation. The dual-domain convolution module is designed to use frequency-domain features as complementary information for improving the learning of spatial feature mapping. A multi-scale adaptive activation function is introduced to modify the feature maps adaptively for further improvement of network performance. Experimental results show that the proposed method can generate a variety of realistic facial expression images simultaneously and usually achieve better qualitative and quantitative results than the state-of-the-art methods.
Key words:deep learning; generative adversarial network; image synthesis; facial expression;multi-task learning
目前以深度學习为代表的人工智能技术已广泛应用于图像合成领域[1-8]。现有图像合成方法绝大多数假设输入和输出是一对一的映射关系[9-15],只能在两个域之间进行跨域转换,其模型存在很大局限性,难以满足多样化人脸表情生成等方面的应用需求[16-17]。人脸表情复杂多样,人们感兴趣的可能不止一种,例如人脸数据集RaFD[18]将表情分为8种,若使用基于一对一映射的图像合成方法进行跨域生成,需要训练56个网络模型,存在效率低下且效果不佳的问题。
为了生成多样化的合成图像,本文提出一种多任务增强生成对抗网络(multi-task enhanced generative adversarial network,MeGAN)。该网络通过共享图像信息,可减少模型参数,改善合成图像的逼真度。本文的主要贡献为:①提出多任务增强生成对抗网络模型,实现多样化图像合成;②设计双域卷积模块,利用具有补偿性的频域特征改善空域特征映射;③引入多尺度自适应激活函数,对不同特征进行自适应修正,改善网络建模的效率和性能;④ 利用实验验证本文方法的性能,通过与基准方法[11,15,19]比较,分析评估本文方法的有效性。
1 相关工作
1.1 生成对抗网络
Goodfellow等人[20]最先提出生成对抗网络(generative adversarial network, GAN)并将其用于数据生成。作为一种无监督学习模型,GAN通过生成器和判别器两个模块的互相博弈学习产生好的输出结果。在GAN模型训练中,生成器产生尽可能逼真的样本去欺骗判别器,判别器尽可能准确地辨别生成的样本和真实的样本。近年,出现了GAN的多种改进方法,例如多样化图像生成[10]和多域图像合成[19]。
1.2 图像合成
自从GAN出现以后,许多关于GAN的改进方法被文献报道,广泛应用于图像合成的各个方面,并且取得突破性进展。由于传统GAN难以准确表达图像合成的映射关系,Isola等人[9]利用对抗损失和L1损失构建总体目标函数,提出基于cGAN模型[21]的图像合成网络pix2pix[9]。随后,Zhu等人和Kim等人分别提出CycleGAN[11]和DiscoGAN[22],通过建立周期一致性损失函数,先将源图像前向合成到目标域,再反向合成到源图像域,解决了数据集中图像配对的问题。Huang等人[15]假设图像分为内容空间和风格空间,利用空间重组实现合成图像的多样性。然而,这些方法只考虑两个域建模,且不具备扩展性。为了解决这个问题,Choi等人提出针对人脸属性和表情转换的多域图像合成网络StarGAN[19],仅使用单一生成器即可完成多个数据域之间的图像合成。StarGAN将域标签作为生成器的附加输入,利用训练学习将输入图像转换到相应的数据域。
1.3 人脸表情
图像合成广泛用于人脸分析[17,19,23-25],例如表情合成[21]。Choi等人提出一种多域人脸表情图像合成方法[19];Shen等人提出一种基于残差网络的人脸属性操作方法[17];Zhang等人利用cGAN模型[21]将表情分类器内嵌于数据增强模块,通过综合利用不同姿态和表情,实现人脸图像合成和位置不变的人脸表情识别[25]。然而,现有方法绝大多数是一对一映射模型,不能对多个表情同时操作。
2 方 法
本文提出一种基于多任务增强生成对抗网络的图像合成方法(MeGAN),本节详细讲述双域卷积、多尺度自适应激活函数、网络架构和目标函数。
2.1 双域卷积
传统深度学习方法通常只对空域特征进行建模,忽略了頻域特征对空域特征的补偿性[26-28]。为此,本文提出双域卷积(DDConv)模块,其网络结构如图1所示。对给定的输入图像xin∈s,先定义空域s和频域f,为简便起见,将输入图像xin记作空域图像xs,而将通过前向离散余弦变换(FDCT)对输入图像xin变换的频域图像记作xf;然后,对xs和xf分别进行卷积处理,从而得到xs1和xf1;接着,利用逆向离散余弦变换(IDCT)将频域特征xf1转换为空域特征xs2,再将两个互补的空域特征xs1和xs2拼接(Concat);最后,利用1×1卷积进行融合重建输出图像xout。与传统空域卷积相比,双域卷积能够综合利用图像的空频特征,改善神经网络的表征能力。
2.2 多尺度自适应激活函数
与传统固定阈值的激活函数(例如,ReLU)和单一尺度可学习的激活函数(例如,xUnit[29])不同,本文提出一种多尺度自适应激活函数,记作MsAA,其网络结构如图2所示。激活函数MsAA先利用线性修正单元(ReLU)、由传统卷积(Conv)和空洞卷积(dConv)[30]构成的多尺度卷积、拼接(Concat)、卷积(Conv)、批量归一化(BN)和高斯函数(Gauss)模块生成权重系数,再将其与前级卷积层输出的特征映射进行点乘(Mult),实现对不同特征进行自适应修正,改善网络性能。
2.3 网络框架
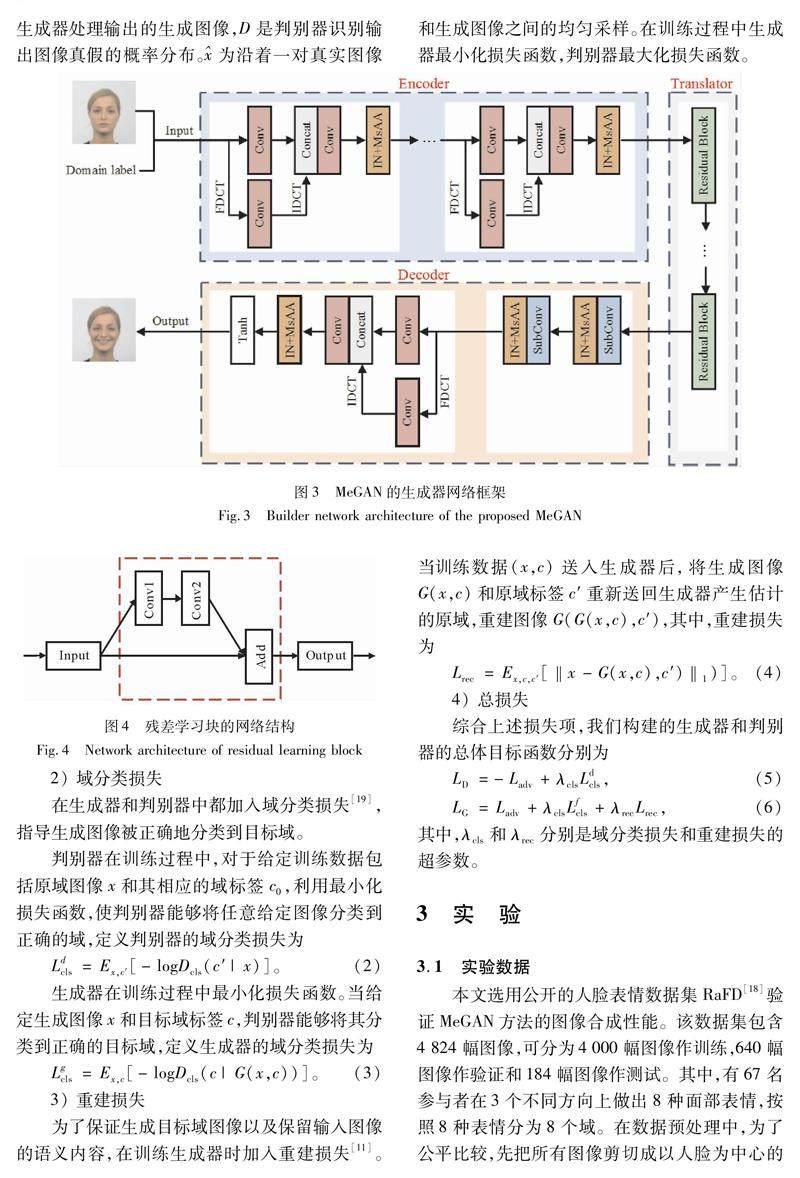
MeGAN模型由生成器和判别器组成,生成器的网络架构如图3所示。假设X和Y分别表示图像集合的源域和目标域,对给定输入图像x∈X,生成器接受输入图像x和目标域标签c,产生与x对应的属于目标域Y的图像G(x,c),其中,目标域标签c是在模型训练过程中随机生成,用于保证训练的充分性和遍历性。
生成器由编码器(Encoder)、转换器(Translator)和解码器(Decoder)3部分组成。编码器是由双域卷积组成,从每个卷积层输出特征映射被送入实例归一化(IN)[31]和MsAA进行修正,提高图像特征表达的有效性和准确性。
转换器(Translator)由6个残差学习块(ResBlock)[32]组成,其网络结构如图4所示。利用残差学习设计转换器,通过对不同层次的图像特征进行组合,提高网络的信息传播能力和跨域转换能力。
解码器利用亚像素卷积[33](SubConv)替代转置卷积实现上采样, 使用激活函数tanh将亚像素卷积特征融合生成目标域估计的高分辨率图像G(x,c)。
判别器是建立在采用PatchGANs[9,11]方法而不是传统卷积网络基础上,利用辅助分类器[33]允许单个判别器控制多个域,区分生成图像的真假和对应域标签。
2.4 目标函数
对于给定训练数据(x,c)和目标域Y,类似于StarGAN[20],我们利用对抗损失、域分类损失和重建损失构造总体损失函数。
1) 对抗性损失
为了提高生成对抗网络训练的稳定性和收敛性,采用WGAN[34-35]的梯度惩罚对抗损失:
其中,G(x,c)为输入图像x和目标域标签c经过生成器处理输出的生成图像,D是判别器识别输出图像真假的概率分布。为沿着一对真实图像和生成图像之间的均匀采样。在训练过程中生成器最小化损失函数,判别器最大化损失函数。
2) 域分类损失
在生成器和判别器中都加入域分类损失[19],指导生成图像被正确地分类到目标域。
判别器在训练过程中,对于给定训练数据包括原域图像x和其相应的域标签c0,利用最小化损失函数,使判别器能够将任意给定图像分类到正确的域,定义判别器的域分类损失为
其中,λcls和λrec分别是域分类损失和重建损失的超参数。
3 实 验
3.1 实验数据
本文选用公开的人脸表情数据集RaFD[18]验证MeGAN方法的图像合成性能。该数据集包含4 824幅图像,可分为4 000幅图像作训练,640幅图像作验证和184幅图像作测试。其中,有67名参与者在3个不同方向上做出8种面部表情,按照8种表情分为8个域。在数据预处理中,为了公平比较,先把所有图像剪切成以人脸为中心的尺寸为256×256的图像,然后,将其缩放至尺寸为128×128。
3.2 实验设置
本实验中,设置λgp=10,λcls=1和λrec=10,选用Adam优化器[36],并设置参数β1=0.5,β2=0.999来训练网络模型,同时,每执行5次更新判别器,执行1次更新生成器。对于数据集RaFD[18],在前100个轮次以0.000 1的学习速率训练网络模型,而后每隔100次迭代学习速率减小10-9,直至模型训练收敛。
3.3 方法评估
选用Inception v3图像分类模型[37]计算客观定量评价指标FID[38-39]来分析评估本文方法的实验结果,其中,较低的FID得分表示较高的图像质量。此外,还将本文方法与MUNIT[15],CycleGAN[11]和StarGAN[19]进行比较,给出定量和定性评估结果,这些对比方法的实验结果是由公开的源代码或作者提供。
MUNIT假设图像可分解为与域无关的内容空间和依赖域特定属性的风格空间,在图像合成时,将输入图像的内容空间和目标域的风格空间重新组合。CycleGAN由两个转换网络组成,对每两个不同的域,需要两个生成器和判别器,在训练过程中,利用对抗性损失和循环一致损失对训练过程进行约束。StarGAN利用一个模型实现单个网络同时训练不同域的多个数据集,在人脸表情合成等任务中有明显优势。
针对公开数据集RaFD,为了便于评估,我们将输入图像域设为“Neutral”表情,其余7种表情轮流作为目标域。由于MUNIT和CycleGAN是一对一映射模型,對不同的配对表情图像分别进行模型训练和测试,从而实现多种表情合成。因为StarGAN和本文方法都是多域转换模型,直接利用数据集RaFD对它们分别进行训练和测试。图5给出不同方法的表情图像合成结果的视觉对比。从图5可知,与MUNIT和CycleGAN相比,本文的MeGAN方法能够生成畸变更少、细节更丰富的面部特征,其原因在于多任务学习框架更能充分利用多模图像特征,并且多尺度自适应激活函数更能有效地修正图像特征。与StarGAN相比,我们的MeGAN方法利用高效的多层次残差学习和频域特征补偿,能够生成表情细节更丰富逼真的合成图像。
图6展示了不同方法对任选取的 “Disgusted”表情合成结果的视觉对比。从图6可知,MUNIT很难保留输入图像的个人身份和面部特征,CycleGAN和StarGAN在嘴巴等部位存在比较严重的模糊现象,而MeGAN方法生成细节清晰表情丰富的合成图像。
选用FID作为客观评价指标,分析评估本文方法和基准方法的图像合成性能。表1给出不同方法对所有测试图像合成结果的FID平均值对比,其中,FID越低表明合成图像质量越好。
4 结 语
本文提出了一种基于多任务增强生成对抗网络的多域图像合成方法MeGAN。通过设计双域卷积,利用具有补偿的频域特征辅助空域特征映射建模;提出多尺度自适应激活函数对空频双域特征进行修正,提高图像合成网络的性能。实验结果表明,与现有先进的图像合成方法相比,本文方法能够生成细节更逼真、表情更多样、质量更高的合成图像。
参考文献:
[1]WANG T C, LIU M Y, ZHU J Y, et al. High-resolution image synthesis and semantic manipulation with conditional GANs[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8798-8807.
[2]ZHANG Y Q, XIAO J S, PENG J Y, et al. Kernel Wiener filtering model with low-rank approximation for image denoising[J]. Information Sciences, 2018, 462:402-416.
[3]ZHANG Y Q, KANG R W, PENG X L, et al. Image denoising via structure-constrained low-rank approximation[J]. Neural Computing and Applications, 2020(5): 1-16.
[4]ZHANG Y Q, YAP P W, CHEN G, et al. Super-resolution reconstruction of neonatal brain magnetic resonance images via residual structured sparse representation[J]. Medical Image Analysis, 2019, 55:76-87.
[5]ZHANG Y Q, SHI F, CHENG J, et al. Longitudinally guided super-resolution of neonatal brain magnetic resonance images[J]. IEEE Transactions on Cybernetics, 2019, 49(2): 662-674.
[6]PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE, 2016: 2536-2544.
[7]ZHANG R, ISOLA P, EFROS A A. Colorful image colorization[M]∥Computer Vision — ECCV 2016. Cham: Springer International Publishing, 2016: 649-666.
[8]GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 2414-2423.
[9]ISOLA P, ZHU J Y, ZHOU T H, et al. Image-to-image translation with conditional adversarial networks[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE, 2017: 5967-5976.
[10]YI Z L, ZHANG H, TAN P, et al. DualGAN: Unsupervised dual learning for image-to-image translation[C]∥2017 IEEE International Conference on Computer Vision (ICCV).Venice: IEEE, 2017: 2868-2876.
[11]ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]∥2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 2242-2251.
[12]ZHU J Y, ZHANG R, PATHAK D, et al. Toward multimodal image-to-image translation[C]∥Advances in Neural Information Processing Systems, 2017: 465-476.
[13]CHEN Q F, KOLTUN V. Photographic image synthesis with cascaded refinement networks[C]∥2017 IEEE International Conference on Computer Vision (ICCV).Venice: IEEE, 2017: 1520-1529.
[14]LIU M Y, BREUEL T, KAUTZ J. Unsupervised image-to-image translation networks[C]∥Advances in Neural Information Processing Systems. NIPS, 2017: 701-709.
[15]HUANG X, LIU M Y, BELONGIE S, et al. Multimodal unsupervised image-to-image translation[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR). IEEE, 2019: 1458-1466.
[16]包仁達, 庾涵, 朱德发, 等. 基于区域敏感生成对抗网络的自动上妆算法[J].软件学报, 2019, 30(4):36-53.
BAO R D, YU H, ZHU D F, et al, Automatic makeup with region sensitive generative adversarial networks[J].Journal of Software, 2019, 30(4):36-53.
[17]SHEN W, LIU R J. Learning residual images for face attribute manipulation[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE, 2017: 1225-1233.
[18]LANGNER O, DOTSCH R, BIJLSTRA G, et al. Presentation and validation of the radboud faces database[J].Cognition and Emotion, 2010, 24(8): 1377-1388.
[19]CHOI Y, CHOI M, KIM M, et al. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation[C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE, 2018: 8789-8797.
[20]GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]∥Advances in Neural Information Processing Systems,2014:2672-2680.
[21]MIRZA M, OSINDERO S. Conditional generative adversarial nets[EB/OL].2014:arXiv:1411.1784[cs.LG].https://arxiv.org/abs/1411.1784.
[22]KIM T, CHA M, KIM H, et al.Learning to discover cross-domain relations with generative adversarial networks[C]∥The 34th International Conference on Machine Learning(ICML), 2017: 2941-2949.
[23]高巖, 许建中, 王长波,等. 约束条件下的人脸五官替换算法[J].中国图象图形学报, 2019, 15(3):503-506.
GAO Y, XU J Z, WANG C B, et al. Algorithm for human face fusion under constraints[J].Journal of Image and Graphics, 2019, 15(3):503-506.
[24]EHRLICH M, SHIELDS T J, ALMAEV T, et al. Facial attributes classification using multi-task representation learning[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).LasVegas:IEEE, 2016: 752-760.
[25]彭先霖, 张海曦, 胡琦瑶. 基于多任务深度卷积神经网络的人脸/面瘫表情识别方法[J].西北大学学报(自然科学版),2019,49(2):187-192.
PENG X L, ZHANG H X, HU Q Y. Facial /paralysis expression recognition based on multitask learning of deep convolution neural network[J].Journal of Northwest University(Natural Science Edition), 2019, 49(2):187-192.
[26]ZHANG Y Q, CHENG J Z, XIANG L, et al. Dual-domain cascaded regression for synthesizing 7T from 3T MRI[M]∥Medical Image Computing and Computer Assisted Intervention — MICCAI 2018. Cham: Springer International Publishing, 2018: 410-417.
[27]ZHANG Y Q, YAP P T, QU L Q, et al. Dual-domain convolutional neural networks for improving structural information in 3 T MRI[J].Magnetic Resonance Imaging, 2019, 64: 90-100.
[28]QU L Q, ZHANG Y Q, WANG S, et al. Synthesized 7T MRI from 3T MRI via deep learning in spatial and wavelet domains[J]. Medical Image Analysis, 2020, 62: 101663.
[29]KLIGVASSER I, SHAHAM T R, MICHAELI T. xUnit: Learning a spatial activation function for efficient image restoration[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2433-2442.
[30]YU F, KOLTUN V, FUNKHOUSER T. Dilated residual networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE,2017: 472-480.
[31]ULYANOV D, VEDALDI A, LEMPITSKY V. Instance normalization: The missing ingredient for fast stylization[EB/OL].2016:arXiv:1607.08022[cs.CV]. https://arxiv.org/abs/1607.08022.
[32]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Las Vegas:IEEE, 2016: 770-778.
[33]SHI W Z, CABALLERO J, HUSZR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas:IEEE, 2016: 1874-1883.
[34]ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier gans[C]∥Proceedings of the 34th International Conference on Machine Learning, 2017: 2642-2651.
[35]ARJOVSKY M, CHINTALA S, BOTTOU L, Wasserstein generative adversarial networks[C]∥In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017: 214-223.
[36]GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wassersteinGANs[C]∥Advances in Neural Information Processing Systems,2017: 5767-5777.
[37]KINGMA D P, BA J. Adam: A method for stochastic optimization[EB/OL]. 2014: arXiv:1412.6980[cs.LG]. https:∥arxiv.org/abs/1412.6980.
[38]SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas:IEEE, 2016: 2818-2826.
[39]HAN Z, IAN G, DIMITRIS M, et al. Self-Attention Generative Adversarial Networks[C]∥In Proceedings of the 36th International Conference on Machine Learning,2019: 7354-7363.
(編 辑 李 静)
作者简介:
彭进业,男,湖南涟源人,二级教授,博士生导师。主要从事图像处理与模式识别、多媒体信息检索、量子信息处理等方面的研究与教学工作。现任西北大学信息科学与技术学院院长、软件学院院长,兼任陕西省图像图形学学会副理事长、陕西省生物医学工程学会副理事长、中国图像图形学学会理事、陕西省计算机学会媒体计算专委会主任、陕西省电子学会常务理事、陕西省大数据与云计算产业技术创新战略联盟常务理事。2002年获得西北工业大学博士学位,2003年破格晋升教授,2007年入选教育部新世纪优秀人才支持计划。担任文化遗产数字化保护与传播教育部创新团队负责人及信号处理系列课程陕西省教学团队负责人。多次担任国际学术会议大会主席、程序委员会主席和程序委员会委员。先后主持国家重点研发课题、国家自然科学基金面上项目等20多项国家级和省部级科研项目。在IEEE TIP,TMM,TCSVT,TKDE,《中国科学》《电子学报》《物理学报》等国内外重要学术期刊及CVPR,IJCAI,WWW等重要国际学术会议上发表学术论文多篇,获国家教学成果二等奖、陕西省科学技术二等奖等教学科技奖励。
收稿日期:2020-04-02
基金项目:国家重点研发计划资助项目(2017YFB1402103);陕西省科技计划重点项目(2018ZDXM-GY-186);西安市智能感知与文化传承重点实验室(2019219614SYS011CG033);陕西高校青年杰出人才支持计划(360050001)
作者简介:彭进业,男,湖南涟源人,二级教授,博士生导师,从事图像处理与模式识别、多媒体信息检索、量子信息处理等研究。
