一种试题智能提取与批量导入方法
2020-04-28王东,林宏
王 东,林 宏
(贵州师范学院 数学与大数据学院,贵州 贵阳 550018)
试题录入技术是试题库系统研究的关键内容,试题库建设质量和效率很大程序上依赖于试题录入方式和采用的技术。试题库系统通过提供专门的试题录入互交界面,输入或设置试题属性及内容,再提交保存到服务器端数据库中。这是一种单题录入的方式,每次录入一道试题,逐题保存在试题库中。采用这种录入方式建设题库的速度较慢、效率较低。一些研究者关注到这一点,致力于研究一种高效、便捷的试题批量导入方法,通过程序自动识别、抽取、录入各类试题信息,将人力从枯燥、乏味的手工录入试题信息的工作中解放出来。
已有的典型研究主要包括以下几个方面:(1)借鉴词法、语法分析技术解析试题内容实现试题导入,如文献[1]基于词法、语法分析的试题导入系统的研究;(2)通过构建有严格控制要求的试题导入文档模版实现试题自动识别,如文献[2]基于PB与VBA的试题导入方法研究、文献[3]基于VFP实现批量导入Word文档试题到数据库的方法,文献[4]基于ASP.NET将Word试题逐题导入数据库的实现方法,文献[5]通过解析试题模型得到 HTML 格式,再根据 HTML 的标签信息分解出题目与答案;(3)利用解析引擎从试题文档结构进行试题内容分析的方法,如文献[6]的基于PANTLR的试卷识别和导入系统的研究。上述试题导入方法取得一定的效果,同时也存在一些问题,如有些方法对试题文档格式限制过严,影响易用性;有的方法丢失了部分试题信息,如格式信息;有些方法识别准确率较低、使用要求高等。本文以广泛使用的word文档为导入数据源,提出一种简单、高效、稳定的批量导入方法。
1 相关研究
1.1 试题存储策略
一个试题库系统包含多个题库,每个题库对应一门学科或一门课程,负责管理若干试题。在存储试题数据时,采用怎样的存储方式与试题录入、编辑方式密切相关,同时对后续试题应用如组卷、导出等产生直接影响。通常,存储试题信息时,一道试题信息由多维属性来表征,如试题编码、题干、答案、所属题型、难度系数、所属知识点等,对题干和答案的存储策略最为重要。最常采用的存储方式是将试题题干和答案的html代码以字符串形式存储到数据库表的相应字段中,该方式存在的问题是描述包含图文、表格、公式等复杂对象混排效果的试题较为困难,需要将试题组卷生成word文档时会丢失原有排版效果,难以生成一份理想的word文档。第二种存储方式是将试题以word格式的文档形式存放到服务器上,或者直接将试题以二进制流形式存储到数据库中。若试题以word文档存放在服务器上,数据库中需要记录试题路径信息;若以二进制流存储到数据库中,使用时需要将二进制流解析成word文档。该存储方式有利于保持试题格式在试题录入、组卷等环节中的一致性,但在web页面上呈现试题信息时要额外进行word到html的格式转换处理。
1.2 试题编辑方法
基于C/S体系结构的试题库管理系统,利用RichTextBox控件能较好显示编辑图文并茂的试题[7-9],基于B/S体系结构的试题库管理系统,试题录入的常规方法是使用web富文本编辑器,如:eWebEditor,KindEditor,CKEditor,ueditor等,富文本编辑器提供所见即所得的功能,操作人员可以在直观、易用的界面创建和编辑试题内容,试题内容最终是以html字符串形式存储。使用富文本编辑器对纯文本试题编辑比较方便,然而对于包含图片、表格和公式的试题编辑,操作上则比较繁琐,图片需要单独上传到服务器上,实现图文混合排版很耗时,仅部分富文本编辑器有限支持word内容的直接复制和粘贴,大多数富文本编辑器不能将上传的word文档直接解析成html格式,也未提供将html格式内容导出为word文档的功能。若试题库系统需要生成word格式的试卷,或者试题要以word文档形式存放在服务器上,则可以使用Office的ActiveX控件作为编辑器,如微软的dsoframer开源控件[10-11],将ActiveX控件嵌入到网页中,通过组件模型提供的API实现对word文档的操纵,该方式存在的主要问题是多用户并发操作时,服务器端容易出错。相对而言,由第三方提供的Office组件,如Pageoffice,则比较完美的提供了在线编辑和处理的功能。
2 试题批量导入方法
2.1 批量导入流程
试题批量导入方法与试题存储策略和试题编辑方法有紧密联系。在试题编辑方法选择上,要确保批量导入的试题能够再次通过单题录入编辑器进行编辑,并且不会产生任何信息丢失和格式错乱。对于试题存储策略,以独立文档形式将试题存放在服务器上,每道试题由题干和答案两个word文档构成,这种存储方式完整保留了试题的排版和格式信息,便于后续的试题使用。除了存储题干和答案信息外,完整的试题信息还需要其它属性加以描述,如试题所属章节、试题难度系数、试题所属题型、题干路径、答案路径、空数等,这些属性值也需要存储到数据库中。当采用批量导入时,如果单纯追求自动化程度,则需要将每道试题的所有属性都附加到导入文档中,在导入时通过程序自动识别出来,但这样不仅增大待导入文档的预处理难度,而且试题自动识别的复杂度也很高,必然降低了批量导入功能的易用性和实用性。因此,批量导入时需要在人工干预和程序自动处理之间做折中,将部分属性通过导入界面进行预设置,如:试题所属章节、难度系数。当批量导入时,增加一个工人确认环节,在最终导入系统前可以对属性进行个别调整和确认。试题批量导入流程如图1所示:

图1 批量导入流程
首先,通过客户端将试题文档上传到服务器上,对试题进行自动解析与识别,将试题与答案分割成独立的word格式文档,其次,将试题信息存储到临时数据库,用户再对导入试题进行确认,最后,存入题库数据库。下面对试题导入过程进行详细讨论。
2.2 试题导入模板设计
要对完全自由格式的文档进行自动识别是极其困难的。因此,对待导入的文档制作了模板,设置适当规则。试卷导入模板要力求简单、规则明了,使用者在已有试卷基础上稍做整理即可。制定了三条规则,规则1,使用“##试题类型名称”的单行文本作为不同题型区域的分割标记,这条规则可以确保一次能导入多种题型的试题;规则2,每道试题包括试题题干区域与答案区域两部分,两部分区域按序相邻,题干区域与答案区域用“@@”分隔,“@@”独立成行,试题与试题之间也用独立成行的“@@”分隔;规则3,填空题中的“空”用带下划线的连续空格表示,这条规则确保能自动识别出填空题中的空数。试卷导入的模板格式如图2所示。

图2 试题导入模板
2.3 试题类型区识别
对导入文档进行自动处理的第一步是根据规则1获取文档中的所有题型分隔标识“##”,取得与标识符“##”在同一段落的文本(该文本为题型类型名称),同时获得各题型的区域范围。对word导入文档的访问与操纵技术,采用微软提供的组件对象模型(COM组件),通过在开发环境中引用Office类型库,就可以访问Office编程接口和各种对象。要对文档中特定模式进行搜索,可以使用word对象模型中Range对象的Find.Execute方法,该方法能搜索特定模式串在文档中的所有出现位置。通过使用该方法迭代搜索题型分隔标识在文档中出现的位置,精准分割出每种题型所属的试题区域范围,并使用一个ArrayList对象存储试题类型信息,ArrayList对象中的每个结点记录了每种题型的名称、区域起始位置及区域终点位置。试题类型区域识别的详细步骤如下:
输入:试题文档Range对象myrange
输出:题型列表qtypelist
定义:struct {qtype, start ,end},/* qtype:题型名称, start:起始位置,end:结束位置 */
1.初始化:qtypelist←new ArrayList
/*获取数据库已有试题类型*/
2.dv←db.RunSelectSQL(SQLstr)
3.end1←myrange.end /*文档尾部位置*/
/*执行myrange.Find.Execute方法,迭代搜索题型标识符,直到该方法返回值为零*/
4.while flag=true do
5.flag ←myrange.Find.Execute("##",…)
6.if flag=true then
/*获取从文档起始位置到当前搜索点范围内所有段落数*/
7.x←G_wa.ActiveDocument.Range(0, myrange.end).Paragraphs.Count
/*获取搜索点所在段落的文本内容,即题型类型名称*/
8.newrange←G_wa.ActiveDocument.Range(0, myrange.End).Paragraphs(x).Range
/*遍历数据库内已设置的题型类别,若获取到的题型类型是合法题型,将该题型类型名称、该题型起始位置及区域终点位置信息追加到题型列表中。*/
9.fori=0 in dv.Count-1
10.ifnewrange.text=dv.Item(i) then
11.node.qtype←dv.Item(i);node.start←myrange.Start; node.end1←end1
12.ifqtypelist.Count!=0 then
13.qtypelist.Item(qtypelist.Count-1).end←myrange.Start
14.endif
15.qtypelist.Add(node)
16.endif
17.endfor
18.endif
19.endwhile
2.4 试题自动识别
使用Find.Execute方法对全文进行一次搜索后,获得题型列表。识别各题型内的试题时需要再对全文进行第二次搜索,根据规则2以“@@”为模式进行搜索,在搜索中逐题分割出试题与答案区域,并为识别出的试题与答案区域设置书签,生成试题答案列表,列表中每个结点包含4个信息:试题类型名称、书签名称、区域起点位置、区域终点位置。具体算法描述如下:
输入:试题文档Range对象myrange,题型列表qtypelist
输出:试题列表questionlist
定义:struct {qtype,bookmarks,start,end },/*试题类型名称、书签名称、区域起点位置、区域终点位置*/
1.初始化:questionlist←new ArrayList
2.while flag=true do
3.flag=myrange.Find.Execute("@@",…)
4.if flag=false then break;
/*遍历题型列表,判断试题位置区域与试题类型区域的位置关系*/
5.fori=0 in qtypelist.Count-1
6.node1←qtypelist.Item(i)
/*若试题分割标记位于当前题型位置范围内*/
7.ifmyrange.Start>=node1.start and myrange.Start<=node1.end1 then
/*若当前标记与前一标记属同一题型, 试题起始位置为前一标记结束位置,试题结束位置为当前标记开始位置,否则,新题型开始的第一题,试题起始位置为题型起始位置,试题结束位置为当前标记开始位置*/
8.ifquestiontype=node1.qtype then
9.start←prestart,end1←myrange.Start
10.else
11.start←node1.start+1
12.end1←myrange.Start
13.end if
/*设置试题范围*/
14.newrange←G_wa.ActiveDocument.Range(start,end1)
/*设置书签*/
15.G_wa.ActiveDocument.Bookmarks.Add("PO_" & k,newrange)
/*新增试题结点*/
16.questionnode.qtype←node1.qtype
17.questionnode.bookmarks← "PO_" & k
18.questionnode.start←start
19.questionnode.end1←end1
20.questionlist.Add(questionnode)
21.k←k+1
22.prestart←myrange.End+1
23.questiontype←node1.qtype
24.endif
25.endfor
26.endwhile
2.5 填空题空数识别
填空题与其它题型不同,填空题需要存储试题的空数信息。批量导入方法应具备填空题“空”的自动检测能力。为实现该功能,首先需要对试题文档中的填空题按规则3做规范化处理,填空题中的每空均用带下划线的连续空格串表示,批量导入时再由处理程序对填空题的“空”进行自动识别。具体算法描述如下:
输入:题干Range对象oRng
输出:空数
变量:字符下划线状态列表oDic,空数列表arrItems,空格blank
1.获取试题题干文本字符长度,sLen←oRng.Characters.Count
/*遍历所有字符,存储所有字符的下划线状态*/
2.for j=1 in sLen
3.oDic←oRng.Characters(j).Font.Underline
/*遍历下划线状态列表,存储所有的带下划线连续空格串的开始位置*/
4.for j=0 in oDic.Count-2
ifoDic.Item(j)=wdUnderlineNone and oDic.Item(j+1)=wdUnderlineSingle and oRng.Characters(j+1)=blank then
arrItems←(j+2)
endif
endfor
5.返回空格数:arrItems.count
2.6 文档分割
批量导入的最后处理是将包含特殊书签的文档分割生成一个个独立的子文档。该过程分两步处理,第一,根据试题识别环节标记的特殊书签,将每一个书签代表的区域内容生成一个独立的word文档,首先将书签内容复制到剪贴板,再将剪贴板内容存储为word文件,并返回文件的路径信息;第二,将每道题的属性信息存入数据库试题临时表中,并触发确认页面供用户干预,用户可对试题所属章节、试题难度系数等属性做进一步修改,再将试题最终提交到数据库中。考虑到多用户并发处理的情形,存储到临时表时为每个用户生成一个时间戳,从临时表读取数据时根据相应的时间戳,就能避免产生干扰和冲突。文档分割具体算法描述如下:
输入:书签列表arrlist, 题型列表qtypelist
输出:试题列表questionlist
1.fori=0 in arrlist.Count-1 step 2
2.bookmark ←arrlist.Item(i)
3.bookmark.Range.Select() /*选择段落*/
4.bookmark.Range.Copy() /*将段落放入剪切板*/
5.question ←questionlist.Item(i+1)
6.spnum←CreateA() /*生成题干文件*/
7.bookmarkB←arrlist.Item(i+1)
8.bookmarkB.Range.Select()
9.bookmarkB.Range.Copy()
10.CreateB() /*生成答案文件*/
/*保存到临时数据库*/
11.SaveFile(bookmark.Range.Text,bookmarkB.Range.Text,spnum,timestap)
12.endfor
3 试题相似度检测

4 实验与分析
为了验证本文所提方法的效率,对比了人工单题录入与该方法的时间效率。实验数据从《数据库原理与应用》、《数据结构》等5门课程中挑选,每门课程由三种不同题型的试题组成一套试卷,试卷详细构成见表1。
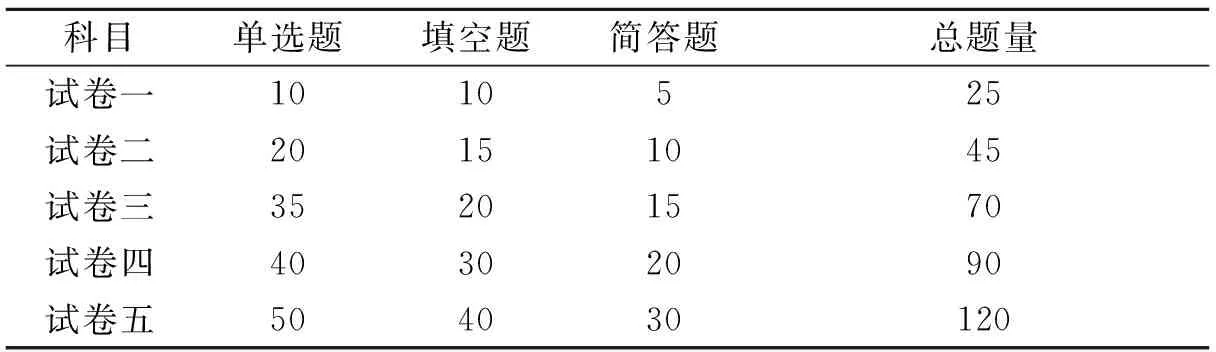
表1 试卷试题构成统计表
实验过程由10人分别使用单题录入和批量导入方法对所有试题集执行试题录入操作,并记录单题录入或批量导入的所用时间,最后计算每组试题的平均录入和批量导入时间。实验结果如图3所示。
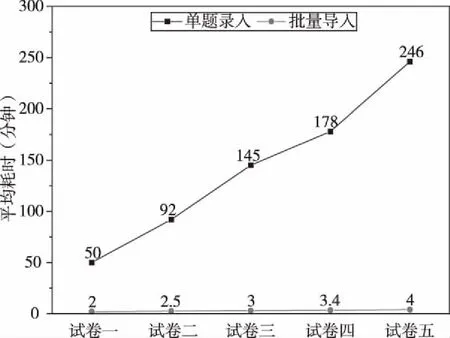
图3 耗时统计
从图3可以看出,批量导入方法与单题录入法相比,相同题量的试题,批量导入方法的时间效率明显好于单题录入方法。并且,随着试题量的增加,单题录入的时间消耗大致随试题量成比例增加,而批量导入方法消耗的时间变化并不大。可见,对于大批量的试题录入,批量导入方法的优势更加显著。
5 结语
试题库管理系统是否有具有高效实用的试题录入方式是影响试题库建设的关键因素。本文阐述了使用服务器端自动化技术的试题智能提取与批量导入方法,在导入文档模板设计上,制定了简单明了的标识规则,只需对原有试卷稍做整理即可满足导入要求,具有操作简单的优点。在对文档中的试题进行自动识别时分两步完成,首先识别出各题型区域,再识别各题型区域内的试题及答案,并为试题及答案标注书签,通过标注的书签自动分割出试题及答案,最后将获取的试题信息存入数据库,该方法确保导入后的试题不会丢失任何信息。为了最大化减少人工干预,提高试题质量,在批量导入过程中还实现了填空题空数自动识别和试题重复检测。进一步的实验表明,与人工单题录入方式相比,本文提出的方法更加高效、便捷。目前该方法已集成到试题库管理系统中,在实际应用过程中成为用户首选的试题录入方法,具有良好的应用效果。
