伴随式教育档案管理数据及其评价功能
2020-04-28马红梅肖雨桐张汶军
马红梅 肖雨桐 张汶军
(华中师范大学 教育学院/湖北省基础教育研究中心, 湖北 武汉 430079)
引言
“善于运用互联网技术和信息化手段开展工作”是十九大报告对公共事业管理提出的时代要求。在数字化平台建设和信息化管理服务全面辐射学校等企事业单位的背景下,将日常教育管理工作中自动生成的伴随式管理过程数据(administrative data)用于评估学生发展状态、教师教学绩效及其所在学校组织效能或教育政策效果等是教育治理与改进工作的重要内容。实际上,这种数据建设和应用分析的工作思路在工业界和企业界也受到了高度重视①,信息技术领域的研究者也关注了类似的数据采集与分析技术对教学诊断、学习心理与行为干预等方面的价值②。
近年来,各部委的若干政策文本中均体现了充分利用信息化手段改善公共事务治理水平的要求③。具体到教育领域,《中小学学生学籍信息化管理基本信息规范》(教基厅[2007]10号)提出了与公安部人口信息管理系统和国家人口基础信息库整合、根据学生身份信息建立全国统一联网的中小学生电子学籍系统的设想,该系统于2014年1月10日联网试运行成功,预期可“拓展应用于事业规划、经费使用、招生就学、控辍保学、教材管理、考勤评价、社会实践等校内外相关管理”,为教育评价与治理提供数据基础。2015年8月31日,国务院《关于印发促进大数据发展行动纲要的通知》(国发[2015]50号)肯定了电子学籍系统的重要价值。2016年6月7日,教育部颁布的《教育信息化“十三五”规划》(教技[2016]2号)将基础数据伴随式收集和全国互通共享的国家教育管理信息化战略工作规划进行了细化。
全员全过程管理数据的伴随式收集为教育评价和政策评估奠定了基础,但如何整合并利用这种全样本大规模数据仍是一个需要理论与技术指导的问题。本研究将教育信息化、管理精细化、技术精准化等工作的工具价值统合到评价与治理中,从理论层面分析整合多部门宽时段追踪型档案数据对改进我国教育评价实践的重要价值,也从技术层面讨论处理这类特殊数据的操作步骤。
本文的研究意义主要体现在以下两个方面:第一,将国家关于利用信息手段促进教育评价与治理的精神落实到可操作的层面;第二,展望电子学籍档案系统产生的大规模伴随式数据对改进教育教学评价或公共政策评估的潜在贡献。文章回应了《关于推进中小学教育质量综合评价改革的意见》(教基二[2013]2号)提出的“充分利用现代信息技术,建立和完善教育质量综合评价数字化管理平台,开发评价工具,为开展评价、改进工作提供技术支撑”的要求。下面将对伴随式数据的集成与分析及其应用价值进行详细论述。
伴随式数据的集成与分析
用可靠的高质量数据说正确的话是当前经济和社会各领域评估工作的诉求。如前所述,在“信息化”和“大数据”时代,教育日常管理工作中自然产生的数据富含各类信息,它“大”而“厚”的数据结构所享有的分析技术优势能大幅度地缩减评价或评估中的误差方差比例,从而更真实地反映学生的学习曲线、教师的教学水平、学校的培养质量、政策的实际效果。本部分重点介绍伴随式档案管理的数据集成和分析技术。
(一)数据集成
根据《国家教育管理信息系统建设总体方案》中关于“两级建设、五级应用”数据库建设要求,学籍档案覆盖了学生和教职工基本信息等微观个体数据、学校资产及办学条件等中观数据、县级或地市级以及省级的经费收支等宏观数据。理论上,学籍管理系统所采集的动态多期信息可包罗教育生产过程内外的任何事件。例如,学生个人和家庭基本信息、学校及其所在社区的基本情况、各科任课教师的背景信息和履历及其所教学生每次考试成绩等所有档案。此外,学者还可通过有意识地设定识别码的方式将自行收集的调查数据、社会实验数据等与学籍档案库进行合并。在公共数据库建设制度成熟的挪威、瑞典、法国、意大利、美国等国家,教育系统的伴随式档案管理数据还可以与劳动和社会保障、医疗卫生、财政与税收、保险、军役服务等终生各项社会记录跨库合并④。而且,这些数据对评估个人和组织的长期发展、公共政策执行效果等方面都起到了重要作用。
由于个人身份代码或若干个体共享的组织机构代码以及地区行政编码等识别码的唯一性,所有数据表均可以通过它得以集成归档。识别码虽然不用于实质性的统计分析,但它对数据整合工作尤其重要,而锚定一个终身不变且便于识计的识别码却成为现实中数据管理与规划工作的难点之一。如果数据表中缺乏具有唯一性和关联性的识别码,即使大量信息都被存储下来,学生与他所在的学校、教他的任课教师及这些教师开设的课程也无法对应起来,这样无法匹配的凌乱数据仍然无助于推进评价工作。
通过个人、组织和地区等各层面的固定匹配代码,分散在任课教师、教务处、学校财务处、人事处、招生和就业或升学处、区县教育局等多个部门的数据可以横向合并。而且,由于识别码不随时间而变,不同时点上的观测值又可以纵向合并。因此,这符合国务院《关于印发促进大数据发展行动纲要的通知》(国发[2015]50号)工作部署的要求:“完善教育管理公共服务平台,推动教育基础数据的伴随式收集和全国互通共享。建立各阶段适龄入学人口基础数据库、学生基础数据库和终身电子学籍档案,实现学生学籍档案在不同教育阶段的纵向贯通。”
数据管理和分析中心工作人员只需将这些零散的后台数据直接导出,再以识别码为数据网络节点(node)做合并和转置处理就可以形成基于同一个体或组织的广统计口径宽时间窗口的面板数据。此外,即使只有单期截面数据,这种分科目同时采集学生和教师等相关主体信息的数据也可通过重新编码和纵向转置技术转换成同一学生在同一时点上的多次观测数据,这就是经济学文献中常用的伪面板数据(pseudo-panel)⑤。
实际上,我国人文社会科学文献中常见的县级、地市级或省级面板数据也是利用这种思路集成的伴随式管理数据,只是其分析单位和加总级别较高而已。在这种同时记录了时间差异和截面差异的面板数据中,某些基本信息不随时间变化(例如,性别、出生时间或地点等)或在同等间隔的时间区间内所有个体发生等量变化(例如,年龄、工作年限等);而另外一些信息随着记录时间的不同而发生不同变化。这种数据结构方面的优势为后文所涉的分析技术提供了统计学基础。
伴随式档案管理数据至少具有以下几个方面的突出优势。第一,在不同时点上频繁观测各项指标所形成的(伪)面板数据具有统计上的优良属性,可适用于固定效应(fixed effect,FE)等高级计量方法获得更加精准的估计,便于更科学地评估学生发展、教师绩效、学校效能以及政策效果等。第二,可以根据归属关系或业务关系将若干个源数据主体进行精确匹配,形成信息量丰富的“厚数据”,以备更加充分地控制协变量的混淆效应、减少遗漏变量偏误。第三,各源数据主体间存在交叉匹配的可能,可应用更加精致的方法获得最优无偏一致估计。例如,师生业务关系配对记录中可能存在同一学生选修不同教师的若干门课程的情况或同一学生同时选修同一位教师多门课程的情况,在这种情况下,可以进一步引入“教师-课程”、“教师-学生”、“学生-课程”等高维固定效应,可更加彻底地消除影响学业表现水平的个人能力、人格个性、教师评分标准或教务及课程政策变迁等各主体间的相互选择效应。
(二)分析技术
如上所述,具有追踪性质的学籍档案资料是一个很强大的面板数据,时空双重差异所赋予的结构特质决定了它可以适用FE估计等方法以更加准确地识别变量间的数量关系。为了论述的便利,笔者先设定一个如公式1所示的“线性累积模型”(linear cumulative model)。在这个模型中,教育是一个特殊生产过程,且后一阶段的成就水平高度依赖于前一阶段的发展结果,即增值评估模型。来自家庭(F)、学校或同伴(S)和教师(T)的各方面资源联合作用于具有一定特质(X)且具有一定学力(A0)和前期基础(At-t*)的学生,在t时点产生阶段性成绩或最终教育成就(At)。
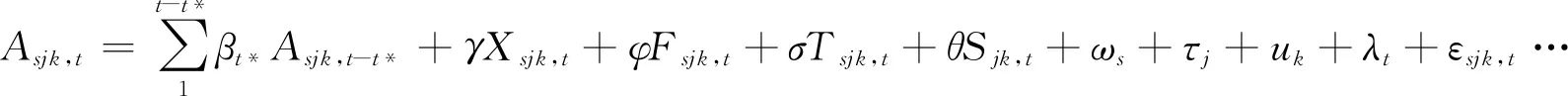
简化分析起见,先假设A是学生在某科目考试中的分数。对教师而言,A即为学生在教师所教课程上的班级或年级平均成绩,此时公式1右边与学生有关的变量均需加总到相应的层面;对学校而言,A是将这门课程上的标准化成绩加总到学校层面的均值,而此时方程右边的学生个体变量和教师变量需要加总到学校级别。以此类推,研究者可以灵活地选择分析单位,在各个层次上评估产出水平。
t表示当期观测,而t-t*为此前t*期的观测时间。如果将数据表从按时间依次横向排列变量的宽型格式转置成同一个变量t次纵向堆栈的长型格式,则t*期上A的前期观察值与第t期的A合并到同一列,相当于动态面板数据中的若干阶滞后项。t*的值域取决于可获得的数据观测期数,最少为1期;而当t*为0时,就退化为不考虑前期学业基础的截面数据;当t=t*时,A0=At-t*⑥。在FE估计中,A0因其不随时间而变被消项,部分学者也将A0移项到方程左边后计算“净增值”(net gain)。
公式1中,下标k,j和s表示第k所学校由第j位教师负责教授的第s名学生,学校、教师、学生等都具有不随时间而变的个体特征,记为uk、τj、ωs。例如,学生人格个性、教师职业精神、学校组织氛围等个人或组织的不可观测特征也影响t时点上的被解释变量(A),而且,这些不随时间而变的特征较难度量且具有跨期稳定性,因此,遗漏变量和序列相关等对模型设定的影响较大。利用追踪数据的结构优势、调用FE估计技术可以解决这些问题。FE估计的主要思路是对误差项进行分解处理,其技术要点是通过组内去均值的对中处理过程消除不随时间而变或在同样的时间窗口内所有发生等量变化的个体特征。时间趋势项(λt)进一步消除了同时影响所有学生、教师、学校和社区等的随时间而变的共同趋势之干扰。
尽管双向固定效应能缓解部分遗漏变量引起的估计偏误,但仍无法消除双向因果的可能性。研究者可根据数据的可得性,联合使用工具变量、断点回归等其他因果推断技术改进估计结果的精准性。除了以上常见的方法外,结构方程以及贝叶斯估计、蒙特卡洛模拟等非参数(或半参数)估计也在这个领域的研究逐渐流行。因此,在具体的研究中,研究者可根据研究的目的和数据的信息容量选择最恰当的方法。
公式1对教育评价工作的重要意义在于,At-t*项控制了学生的前期学习基础,为评价工作提供了更加完整的图景。将t*次前期表现对当期成绩影响的程度βt*投射到图像上即可根据成长曲线的斜率变化刻画各阶段的发展趋势⑦。增值评估中可能出现正增值、负增值和零增值三种情况。而且,在这种动态的评估过程中,即使整体发展趋势既定,评价对象也可以在部分观测点上出现反方向波动,例如,图1描绘的发展型成长曲线中也可以容纳间歇性的负增值,而退化型成长曲线在第四期也出现了正增值。

图1 基于跟踪数据的学生成长曲线与发展轨迹
此外,公式1中隐含了一个很强的假设,即前期投入(At-t*)在所有个人或组织中的当期回报率都完全相同。通过在成长模型中引入衰减系数而允许βt*在不同时点上或在不同群体中的取值不同,上述问题就可以得到解决。这就是文献中常涉及的“几何衰减效应”(geometric decay),技术上对应着若干个交互项。
综上,学籍档案管理系统对今后教育评价与测量工作、教育政策评估具有重要的工具性价值。通过对学生、教师、学校、区县等信息主体多期追踪观测,研究者或数据管理中心的分析师可以将这些信息合成纵横贯通的面板数据,进而采用高级计量分析技术以克服当前我国主流评价方式的诸多问题。下文将对当前我国教育评价实践中存在的主要问题以及伴随式数据彰显其应用价值之处进行说明。
伴随式数据的应用价值
在数据开放度较高的欧美地区,包括教育在内的社会公共事务评估研究中广泛地启用了行政管理过程中产生的伴随式数据⑧。例如,美国北卡罗纳州几十年的教育管理档案数据存放在杜克大学;佛罗里达、华盛顿、德克萨斯、纽约、芝加哥、丹佛等地的数据频繁地出现在美国教育评估文献中。普林斯顿大学还成立了“国家教育追踪数据分析中心”(National Center for Analysis of Longitudinal Data in Education Research, CALDER)。
截至目前,出于信息安全等方面的考虑,国内伴随式管理过程数据总体上尚未用于教育评价,只有少数学者在部分地区或个别学校开展了个案研究⑨。我国行政管理过程数据的垄断与封闭现象不仅限于教育领域,经济学家也表达了类似的呼吁⑩。然而,从意识到行政管理数据在评价方面的优越性到普遍投入使用需要经历一个认识过程,即使在数据开放度较高的美国,部分地区早期也受到类似问题的困扰,学者掀起的“数据质量运动”(data quality campaign)缓慢而艰难地改变了美国数据封存和浪费状况。
(一)评价个体或组织
在数据不充分或信息缺乏有效整合的情况下,我国教育评价方式也相对粗糙,至少存在以下两个方面的问题。
第一,数据所有者缺乏共建共享与集成优化意识。即使很多学校或地区很早就启动了无纸化自动办公系统的建设并通过这个信息平台采集了充足的信息,但这些数据散落在科任教师、教务处、招生办和就业指导处、区县教育行政管理部门等。这可能反映了数据处理技术和能力、信息保密的多重限制。笔者认为,即使在短期内无法实现行政管理数据大范围地联网使用,各学校或地区也可以先行先试,做好数据收集规划方案并使这些伴随式数据服务于教育评价与治理工作。
第二,数据的利用水平不足,分析技术简单粗糙。很多评价还停留在报告频数(或优秀率、及格率)和均值等描述统计量的初级阶段,增值评估没反映到对学生、教师和培养单位的考核中。用达标率和均值等指标评价教师绩效或学校效能的做法是“一次性”终结性评价,斩断了过去与现在的内在联系,遗漏了公式1中的At-t*等重要内容。这种做法有失公允,引起了很多教师和校长等一线教育工作者的不满,甚至挫伤了一些生源较差的学校的办学积极性或教师的工作积极性。
在班级或学校甚至地区等更高层级的分析单元上做横向比较时,更有必要诉诸增值评价理念与技术。在实验示范班级或生源占绝对优势的学校,学生可轻易达到更高的绝对水平,但这些学生最终表现并不一定是学校和教师的作用。从增值的角度看,优生群体甚至还可能存在负增值的退化过程;相反,在生源较差的班级或薄弱学校,尽管学生的绝对表现水平较低,但他们可能已远超出预期可达到的水平。后一种情况所描述的教育过程有效地促进了学生成长,符合“投入-产出”的逻辑,但得不到现行评价制度的认可。这正是很多生源较差但效能较高学校面临的困惑。
中小学校长和区县教育行政管理部门工作人员也意识到了上述问题,他们很想知道如何做好学生学业评价和教师绩效激励等问题的顶层设计和技术改进。本文中关于数据采集方式的变更及这种信息的合成处理与分析可以从技术上解决他们的忧虑,因此,充分利用教育管理信息化过程中自动生成的伴随式管理过程数据是推动我国教育评价与治理工作的一个立足点。与此同时,较好地落实本研究的研究设想对负责评价的相关工作人员提出了新的专业要求,他们需要加强数统知识修炼或积极寻求与同时谙熟评价理论与计量分析的学者的合作。
(二)评估公共政策
政策分析和项目评估常用面板数据进行研究。除了用于评估个人和组织外,学籍档案管理系统生成的伴随式过程性数据还能用于构造前后测“准实验”,并用于评估教育政策效果或其他事件的干预效应(treatment effect)。与社会调查数据相比,伴随式管理过程数据“先知先觉”地自动记录了政策生效前的“前测”情况,不必采取要求被访者“回溯”的方式获取干预前的信息,利用双重差分估计等类型的研究设计优势更突出。
当前我国很多公共政策评估的文献均是以县或地市以及省为分析单位展开的分析,这些加总到更高行政单元的数据为了解公共政策的执行效果之概貌提供了重要信息,但政策成效及其作用的微观机制还有待更加细致地分析,而档案管理工作能在更基础的观测单元获取数据,对详尽了解公共政策的作用方式、分布效应等问题都具有重要价值。
结语
持续性地跟踪人在教育教学常态情境中留下的历时痕迹,有意识地规划数据生成、归档、建模、分析与应用,这项工作能服务于学生成长与发展、教师教学与考核、学校治理与改进、公共政策运行与调整。本研究探讨了电子学籍档案系统生成的伴随式数据对日常教育评价和教育政策评估等方面的潜在价值。
在管理电子化和办公自动化的今天,档案资料管理过程中伴随式生成的数据具有完整、追踪等诸多优势。以学生和教师的个人身份代码、学校组织代码、地区行政编码等为识别变量将跨期信息合并成宽厚的数据后,研究者能采用更灵活的模型设定和更精准的分析技术,动态评估学生、教师、学校或公共政策等;在信息量充足的情况下,研究者还可以结合财务数据进行“成本-收益”分析,监测公共教育资源的使用效率等。
综上,文中所涉的数据构造与应用技术对改进信息收集、资料分析和呈现方式以及提高教育评价精度等方面具有重要价值。而且,评价过程和结果均数有先后、进退有据,经得起反复检验,预期能提高教育治理的精细化水平。受篇幅限制,本研究仅从理论层面讨论了伴随式管理数据的应用价值,而没有提供基于数据的实证分析。
注释
①C. Zhu, “Big Data as a Governance Mechanism,”ReviewofFinancialStudies, vol. 32, no. 5, 2019, pp. 2021-2061;刘强、秦泗钊:《过程工业大数据建模研究展望》,《自动化学报》2016第2期;汪寿阳、洪永淼、霍红、方颖、陈海强:《大数据时代下计量经济学若干重要发展方向》,《中国科学基金》2019年第4期。
②卢国庆、谢魁、张文超、刘清堂、张妮、梅镭:《面向即时数据采集的经验取样法:应用、价值与展望》,《电化教育研究》2019年第6期;余胜泉、徐刘杰:《大数据时代的教育计算实验研究》,《电化教育研究》2019年第1期;罗玮、罗教讲:《新计算社会学:大数据时代的社会学研究》,《社会学研究》2015年第3期。
③刘亚亚、曲婉、冯海红:《中国大数据政策体系演化研究》,《科研管理》2019年第5期。
④实际上,即使在没实现教育管理过程电子化的时代,研究者也可以通过问卷调查等方式建构这样的集成式数据,但这项工作的核心是在问卷中设置可以将不同主体与各种外围信息库进行精确匹配的识别码。例如,美国的学校和人员配备调查(Schools & Staffing Survey)及与此配套的教师专项调查(Teacher Follow-up Survey)均采集了个人社保号码(security number)这个唯一身份识别码信息,通过它既可以实现各调查主体的内部合并,又可以与劳动力市场调查National Longitudinal Survey of Youth、Panel Study of Income等综合社会调查进行外部合并以分析学校教育对个人终身发展的长期效应或代际传递问题等。
⑤自从Deaton(1985)分享了这种伪面板数据构造技巧后,经济学文献中开始大量使用这种技术。国内教育研究领域还没有充分开发伪面板数据处理技术,笔者曾对其具体操作步骤进行了详细论述。
⑥C. Koedel, K. Mihaly and J. E. Rockoff, “Value-Added Modeling: A Review,”EconomicsofEducationReview, vol. 47, no. 4, 2015, pp. 180-195.
⑦T. Andrabi, J. Das, A. I. Khwaja and T. Zajonc, “Do Value-Added Estimates Add Value? Accounting for Learning Dynamics,”AmericanEconomicJournal:AppliedEconomics, vol. 3, no. 3, 2011, pp. 29-54.
⑧M. Almunia, J. Harju, K. Kotakorpi, J. Tukiainen and J. Verho, “Expanding Access to Administrative Data: The Case of Tax Authorities in Finland and the U.K.,”InternationalTax&PublicFinance, vol. 26, no. 3, 2019, pp. 661-676; D. Card, R. Chetty, M. S. Feldstein and E. Saez, “Expanding Access to Administrative Data for Research in the United States,” Nashville: American Economic Association,2010.
⑨梁晨、董浩:《必要与如何? 基于历史资料的量化数据库构建与分析: 以大学生学籍卡片资料为中心的讨论》,《社会》2015年第2期;梁晨、李中清:《大数据、新史实与理论演进:以学籍卡材料的史料价值与研究方法为中心的讨论》,《清华大学学报(哲学社会科学版)》2014年第5期;辛涛、姜宇、刘文玲:《中高考数据链接对学校进行增值性评价:以某市40所高中2132名学生中高考数据的实证分析为例》,《中小学管理》2012年第6期。此外,岳昌君教授及其研究团队关于大学生就业的一系列优秀研究作品也是基于全国高校档案管理数据撰写而成的;辛涛教授、孙志军教授、兰小欢教授等基于中高考数据的研究也是与地方教育局合作的经典案例。
⑩甘犁、冯帅章:《以微观数据库建设助推中国经济学发展:第二届微观经济数据与经济学理论创新论坛综述》,《经济研究》2019年第4期。此外,2019年8月9-10日,中国国家自然科学基金委召开了“大数据时代计量经济学前沿理论、方法与应用”会议,并决定重点资助五大与数据有关的研究主题,其中之一即为“大数据政策评估计量分析的理论、方法与应用”。教育领域的研究也开始关注这个趋势,参见杜育红、臧林:《学科分类与教育量化研究质量的提升》,《华东师范大学学报(教育科学版)》2019年第4期;范涌峰、宋乃庆:《大数据时代的教育测评模型及其范式构建》,《中国社会科学》2019年第12期。
