基于改进YOLO v3模型的挤奶奶牛个体识别方法
2020-04-27何东健刘建敏熊虹婷芦忠忠
何东健 刘建敏 熊虹婷 芦忠忠
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100;2.农业农村部农业物联网重点实验室, 陕西杨凌 712100;3.陕西省农业信息感知与智能服务重点实验室, 陕西杨凌 712100)
0 引言
以信息与智能技术为支撑的绿色、高效、精准养殖成为现代畜牧业发展的必然趋势[1-3]。奶牛养殖业作为中国畜牧业的重要组成部分,其信息化、自动化、智能化应用不断深化[4-7]。精准养殖体系中个体档案建立、信息采集、执行方案制定以及产品溯源等,都需要对奶牛进行快速准确的识别[2]。个体身份识别是对奶牛个体进行管理及自动分析奶牛行为的前提和应用基础[8],对奶业发展具有至关重要的作用。对于现代化的规模化奶牛养殖场,挤奶厅不仅完成挤奶作业,更是养殖场数据采集的重要场所,在这里可以监测每头牛的产奶量、挤奶时间、日挤奶次数、产奶品质等数据。对进入挤奶厅的每头奶牛进行准确识别,可以在未来与不同牛只个体的产奶情况准确匹配,这对企业掌握每头奶牛的产奶量情况、提高并改进对奶牛的喂养管理、判断奶牛健康状况、增加养殖场经济效益等具有重要意义。传统的奶牛个体识别主要采用人工耳标、信息登记、佩戴颈链等方法[9],依靠人工观察方式不能适应现代化规模养殖自动识别的应用需求。无线射频识别技术(Radio frequency identification,RFID)在实时更新资料、存储信息量、使用寿命、工作效率、安全性等方面都具有优势,近年来在畜牧业中被用于动物识别[10-11]。典型的电子识别装置必须通过穿刺固定在颈部或耳朵上,这会对奶牛造成损害并影响动物福利,且RFID电子标签价格较高,在规模化养殖中需要多台RFID读取设备识别奶牛,大大增加了生产成本。
随着计算机技术的发展,结合荷斯坦奶牛特有的黑白花纹信息,采用计算机视觉实现奶牛个体识别逐步引起国内外学者的关注[12-17]。LI等[18]提出自动识别奶牛尾部图像作为感兴趣区域(Region of interest,ROI),以Zernike矩描述区域内白色图案的形状特征,采用支持向量机(Support vector machine,SVM)对23头奶牛分类的最高精度达到99.7%,但对ROI为纯黑色的奶牛并不适用。CAI等[19]将牛脸图像分割为互不重叠的独立小块,使用局部二值模式方法提取纹理特征,并设计了特征描述子,建立的面部描述模型能准确高效地进行牛脸识别,但实际场景下牛的头部不断移动,难以自动采集其脸部图像。张满囤等[20]提出一种基于小波变换和改进核主成分分析法的奶牛个体识别方法,但该方法实时性较差。赵凯旋等[21]提出一种基于卷积神经网络的奶牛个体识别方法,该方法对30头奶牛的识别正确率为93.33%,但训练样本数较少,不能满足中等规模养殖场的需求。ANDREW等[22]研究采用区域卷积神经网络(RCNN)对荷斯坦黑白花牛个体识别的方法,在89头奶牛中准确率达到86.1%,对无人机拍摄的23头室外放牧奶牛的识别准确率达98.1%,但该研究针对室外放牧环境,不适合挤奶厅奶牛的识别。YOLO(You only look once)算法[23-25]是一种端到端的卷积神经网络,检测速度快,在农业目标实时检测与识别中具有良好应用前景[26]。深度学习在农业对象的识别中表现出良好的性能和抗干扰能力,具有复杂场景下奶牛个体识别的潜力。
为提供一种可在实际奶牛养殖环境下应用、非接触、低成本的挤奶奶牛个体识别方法,本文在设计奶牛进出挤奶厅背部视频采集方案的基础上,提出基于视频分析和改进YOLO v3深度卷积神经网络的挤奶奶牛个体识别方法。
1 供试图像采集与预处理
1.1 图像采集
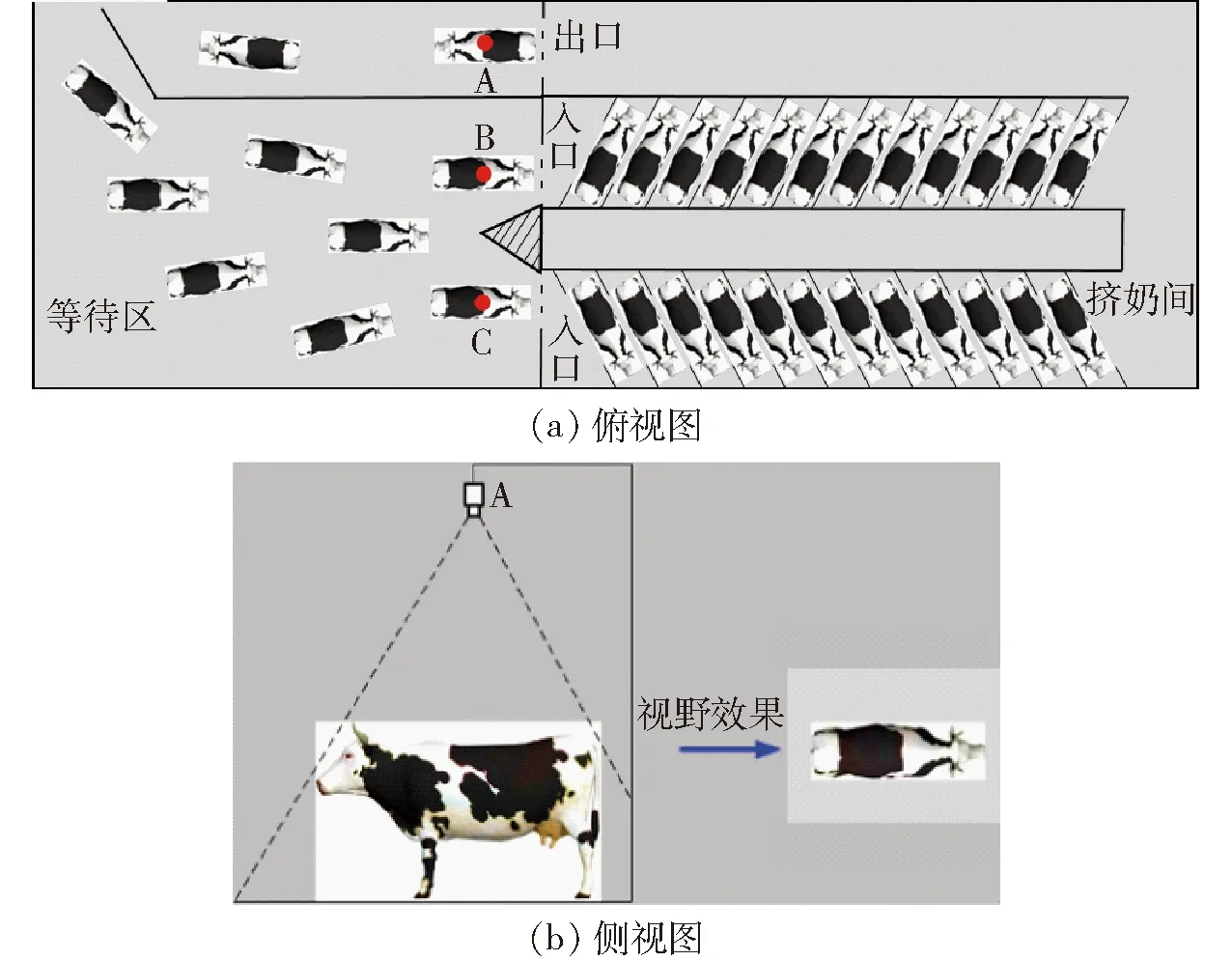
图1 摄像机安装位置示意图Fig.1 Installation location of video camera
本研究供试视频拍摄于陕西省杨凌科元克隆股份有限公司,拍摄对象为89头泌乳期间健康的美国荷斯坦奶牛。每天早、中、晚进行3次挤奶,在挤奶时间段内,奶牛从等待区的2个入口进入挤奶厅,每个挤奶厅有12台挤奶设备,完成挤奶的奶牛从唯一出口离开。如图1所示,用A、B、C表示的3台DS-2CD3325-I型高清网络摄像机(海康威视,杭州)分别安装在出入口的正上方,距离地面高度为2.7 m,调整摄像机视轴竖直向下,并使其视场水平方向与牛只行走方向基本平行,视野宽度大于1.5个牛身长度。
每个摄像机有一个独立的IP地址,通过摄像机配套的萤石云客户端,可远程实时访问摄像机,以浏览对应位置的奶牛背部视频。同时,摄像机采集的视频通过网络传输至25 m外挤奶厅监控室的硬盘录像机内,录像机接入养殖场内部有线网络接口。视频采集系统如图2所示。

图2 视频采集系统Fig.2 Video acquisition system
于2019年3月17—21日拍摄供试视频,根据养殖场的固定挤奶时间设置摄像机拍摄时间段,每天05:00—07:00、13:00—15:00、19:00—21:00时段自动获取奶牛进出挤奶厅时的背部视频片段。89头奶牛按12头1组随机从不同入口进入挤奶间(最后一组为5头)。当每组第1头奶牛全部出现在视野左侧时开始采集,到最后一头奶牛行走至视野右侧边缘结束,以此作为一个视频段。
对不同时段进出挤奶厅的每组奶牛背部视频,剔除包含奶牛停顿和异常行为的视频后,共采集到48段视频,每段视频时长在20~80 s之间,视频帧率为25 f/s,分辨率为1 920像素(水平)×1 080像素(垂直)。由于夜间挤奶厅和等待区有灯光照明,故夜间拍摄的视频段也被选用。利用视频帧分解技术,每3帧取1帧,得到无异常的奶牛背部图像10 800幅。
用于图像数据处理及模型训练的计算机处理器为Inter Core i5-8700,主频为3.20 GHz,显卡为NVIDIA GeForce GTX 1070 Ti,16 GB内存,500 GB硬盘。所有程序均在Windows 10系统下用Python语言编写,图像显示处理调用OpenCV库、数据计算调用CUDA、CuDNN等。
1.2 视频图像预处理
由于奶牛养殖场环境复杂、光照不均等,导致视频帧图像中包含噪声及边缘模糊等,需要去除视频帧图像中的噪声,并做图像增强等预处理,以提高有效信息占比,为后续目标检测、特征提取和个体识别等奠定良好的基础。
1.2.1双边滤波去噪
实际拍摄的视频地面颜色与奶牛背部黑色斑点颜色相近,若采用高斯滤波或中值滤波,在边缘处易出现模糊现象,考虑到双边滤波算法[27]结合图像的空间邻近度和像素值相似度进行折中处理,能在保持强边缘的同时有效地对图像的细小变化进行平滑,故用双边滤波算法去除噪声。
为验证双边滤波算法对本文图像去噪的有效性,用双边滤波算法、高斯滤波、中值滤波、均值滤波、方框滤波5种方法对同一幅图像进行去噪效果对比试验,不同滤波器处理后图像的峰值信噪比(PSNR)和结构相似性值(SSIM)如表1所示。

表1 不同滤波器下图像的峰值信噪比和结构相似性值Tab.1 PSNR and SSIM of image under different filters
由表1可知,原始图像经过双边滤波算法处理后,峰值信噪比为36.23 dB,与原始图像结构相似性值达到0.999 98,在5种滤波器中均取得最高值,图像质量相对较好。故本文选择双边滤波算法去除噪声。
1.2.2图像增强
由于挤奶厅地面为深灰色,与奶牛身体颜色相近,使得图像偏暗,且奶牛躯干边缘轮廓和地面难以明显区分,故需对图像像素进行亮度、对比度增强,增强公式为
h(x)=αf(x)+β
(1)
式中h(x)——输出图像f(x)——输入图像
α——增益,影响图像对比度,预备试验确定α为1.1
β——偏置,影响图像亮度,预备试验确定β为30
图像增强后,通过自定义的卷积核kernel进行锐化处理,即
(2)
通过强化奶牛躯干边缘轮廓与背部花斑分界线,达到增强边缘的效果。
1.3 摄像机标定
DS-2CD3325-I型半球形摄像机为广角摄像机(焦距为2.8 mm,水平视场角为103°),图像呈现严重的桶形失真[28],如图3a所示。
为了消除图像畸变,本文采用张正友标定方法进行标定。采用边长为0.5 m×0.35 m、印制有间隔0.05 m黑白网格的棋盘格标定板,获取视场中与奶牛同一高度的不同位置、不同角度下的25幅图像,利用Matlab中CameraCalibrator标定工具箱对每一幅图像提取角点信息,依次连接各个内角点,自动获取摄像机畸变系数和内参数矩阵。相机坐标系(x,y,z)与世界坐标系(X,Y,Z)的对应关系可表示为
(3)
式中fx——x轴焦距fy——y轴焦距
cx——x轴光学中心
cy——y轴光学中心
可在Python中查看标定结果,实现图像畸变校正。
校正后根据有效区域进行剪裁,最终得到的奶牛背部图像尺寸为1 444像素(水平)×756像素(垂直)。矩形网格畸变校正结果如图3b所示。
1.4 供试数据
为避免样本量差异对识别结果的影响,需要保证不同模式中参与训练的样本数量基本一致,在经过预处理的10 800幅图像中,选择7 358幅包含独立完整目标的奶牛背部图像。结合奶牛进入挤奶厅时躯干与视野水平线有一定倾斜角度、视频图像中光照强度随时间变化的特点,对原始数据集采用旋转10°、旋转-10°、亮度线性增强10、亮度线性降低10的方法进行数据扩充,最终得到36 790幅图像。随机选取其中22 074幅作为训练集,7 358幅为验证集,7 358幅为测试集,数据之间无重叠。
为了提供训练模型的数据类别,采用开源工具LabelImg对训练和测试图像集进行人工标注。由于奶牛行走中头部会产生起伏,有抬头和低头行为,使得奶牛头部形状变化较大,且头部占奶牛身体的比例较小,故标注时忽略奶牛的头部,仅框选奶牛背部区域,将其标记为对应奶牛的身份ID(耳标),并自动生成相应的配置文件。
2 YOLO v3识别模型的构建与改进
深度学习具有强大的数据表征能力,通过组合低层特征形成更抽象的高层表示属性类别或特征,在样本量足够大时可以达到较好的识别精度[29],适合用于本文奶牛个体的识别。当前以R-CNN系列[30-31]为代表的基于区域分析的模型和以SSD[32]、YOLO系列为代表的基于回归分析的模型应用较为广泛。其中,YOLO v3识别模型具有轻量高速的特点,在快速检测的同时识别准确率高,非常适合作为奶牛实时识别模型。
2.1 边界框的分类和预测
YOLO v3将输入图像首先缩放至416像素×416像素,然后划分为S×S个网格,输入深度神经网络进行训练。每个网格单元负责检查其内的边界框和其置信度,网格单元具体信息可用T(x,y,w,h,C)表示,x、y是当前网格单元预测检测对象的置信度中心位置的横、纵坐标,w、h是外接矩形的宽度和高度,置信度C则反映当前网格单元是否包含奶牛目标及其预测准确性,通过阈值对预测结果进行取舍。假设图像的左上角为坐标原点,则预测的边界框可表示为
(4)
式中bx、by——预测边界框中心点的横、纵坐标值
σ(x)、σ(y)——预测边界框中心点与最近网格边缘在x、y向的距离
dx、dy——网格的横、纵坐标偏移量
bw、bh——预测边界框的宽度和高度
pw、ph——锚点框的宽度和高度
位置边框采用logistic预测目标对象的置信度。如果预测边界框与真实边界框重叠,并且预测结果优于所有其他边界,则该框的值为1,否则为0。
2.2 YOLO v3模型的改进
本文识别的荷斯坦奶牛身形较大,且不同个体之间体长、体宽相近,YOLO v3模型的先验锚点框和结构并不适于奶牛识别。故本文使用K-means算法对数据集中的奶牛目标聚类分析,针对奶牛识别修改模型的层级结构,并参考Gaussian YOLO v3[33]构建改进YOLO v3模型。
2.2.1锚点框的聚类与优化
YOLO v3借鉴了Faster R-CNN和SSD中锚点框作为初始候选框的方法,其大小为人工设定的固定值,在不同尺度上对目标进行预测,初始锚点框的选择影响网络的速度和精度。为加快网络收敛速度,本文用K-means算法对数据集中标注的边界框进行聚类,得到适合奶牛数据集的锚点框。为了减少锚点框尺寸对误差的影响,用平均交并比(Averange intersection over union, AIoU)代替欧氏距离作为K-means聚类分析的评判标准,平均交并比越大表示聚类效果越好,距离表示为
(5)
式中A——真实的边界框区域
T——聚类得到的矩形框区域
DA,R——真实框中心与聚类中心之间的距离
K——聚类中心(即锚点框)数量
Ni——第i个聚类中心的样本数量
IoU——真实框和聚类框的交并比
令K=1,2,…,12分别对数据集样本进行聚类分析,得到平均交并比与K之间的关系如图4所示。
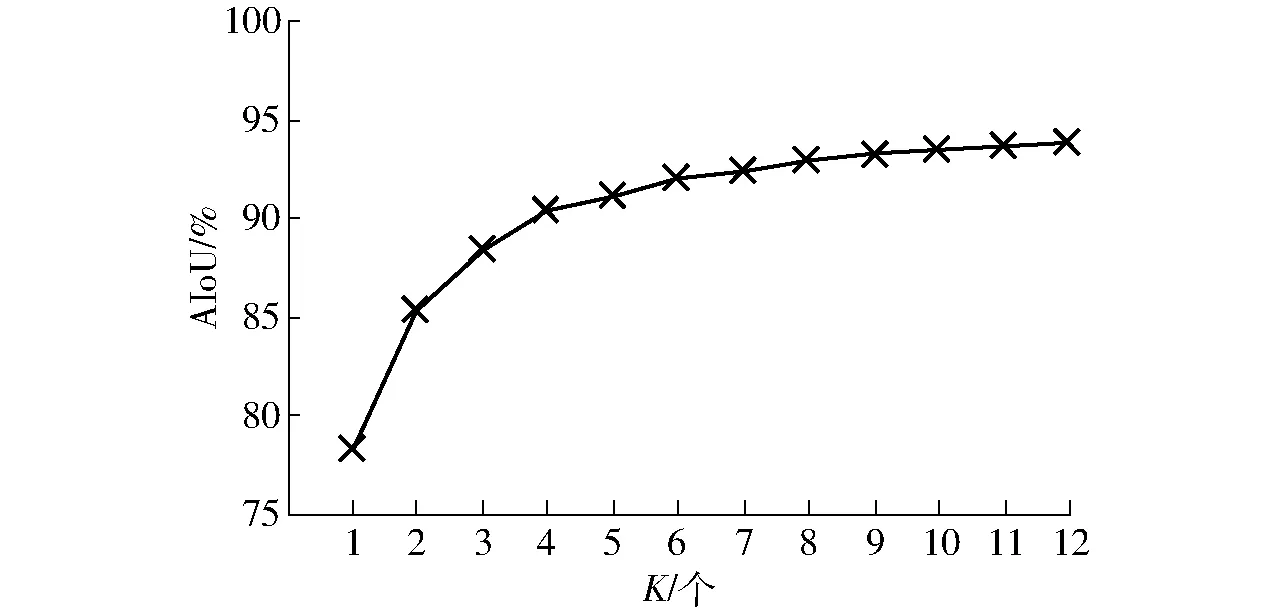
图4 平均交并比与K之间的关系Fig.4 Relationship between AIoU and K
由图4可知,当锚点框数量为9时,平均交并比达到93.5%,且此后变化平稳。为平衡交并比与网络复杂度,将K=9的聚类结果作为网络中的锚点框尺寸,即(199,165)、(208,190)、(229,177)、(233,201)、(222,222)、(260,196)、(272,208)、(255,234)、(235,274)。
2.2.2网络结构的改进
YOLO v3采用Darknet-53网络结构,在前向传播过程中,通过改变卷积核步长实现张量的尺寸变化。Darknet-53借鉴了残差神经网络[34]的构造,每个残差模块由多个残差单元(res unit)组成,每个残差单元有2个卷积层和1个快捷链路,使网络结构加深的同时避免梯度消失,加强对图像特征的学习。输入通过2个DBL(Darknetconv2d-BN-Leaky)单元进行残差操作,其中,DBL单元包含卷积层、批归一化层(BN)和Leaky ReLU激活函数层,残差单元的基本结构如图5所示。

图5 残差单元的基本结构Fig.5 Structure of res unit
YOLO v3模型(不含图6中虚线框包围部分)中有5次下采样,输出3个不同尺寸的特征图。将更深层网络的特征进行步长为2的上采样,与前一步下采样得到的特征进行张量拼接,使网络既可以包含高层特征的高级语义信息又可以保留低层特征的物体位置信息。网络在13×13(尺度1)、26×26(尺度2)、52×52(尺度3)3种尺度上对不同大小的目标进行边界框预测,在COCO数据集中对应的锚点框是(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90)、(156,198)、(373,326),而奶牛数据集锚点框最小值(199,165)大于前8个锚点框,因此训练时只能在1个尺度上提取特征,特征提取效率低。为提高网络收敛速度,增强特征提取能力,故将本文经K-means聚类得到的锚点框按从大到小的顺序分配给尺度1、尺度2和尺度3,每个尺度预测3个锚点框,以提高多尺度目标预测准确率。
本文识别奶牛数量为89个,样本数量和计算量较大,因此在残差模块和降采样层间增加1个1×1卷积层,在不损失分辨率的前提下进一步降低输入通道数、减少计算量。改进后的网络层数更深,为防止随着网络层数的增加可能造成的梯度消失,提升网络训练效果,将YOLO v3输出模块中的前4个卷积层替换为2个残差单元,通过跳跃连接的方式将信息传递到更深层。改进内容用虚线框标出,则改进后的网络结构如图6所示。

图6 改进后的YOLO v3网络结构Fig.6 Structure of improved YOLO v3
2.2.3改进YOLO v3模型的构建
YOLO v3模型输出预测框的位置参数bx、by、bw、bh和目标置信度,边界框和置信度均单独回归。输出的预测框只有确定性坐标值而无概率值,无法表示当前预测框的准确性。为进一步提高检测精度,本文借鉴Gaussian YOLO v3[33],采用高斯模型对预测框的可靠性进行建模。给定输入xg、输出yg的单个高斯模型如下
G(yg|xg)=Ng(yg|μ(xg),Σ(xg))
(6)
式中μ(xg)——均值,表示预测边框的位置
Σ(xg)——方差,表示预测框位置的不确定性
G、Ng——高斯分布参数
将预测特征图中每个预测框的坐标用均值和方差建模,预测框的输出更改为μ(bx)、Σ(bx)、μ(by)、Σ(by)、μ(bw)、Σ(bw)、μ(bh)、Σ(bh),通过sigmoid函数将输出值限定在0~1之间。
2.2.4损失函数
YOLO v3使用方差相加与二值交叉熵的损失计算方法,损失函数由坐标误差、交并比(Intersection over union,IoU)误差和分类误差3部分组成[23-25]。在训练时通过反向传播不断更新模型,使得损失值不断减小。通过高斯建模将预测框坐标输出为高斯参数,因此预测框的损失函数更改为负对数似然损失[33],即
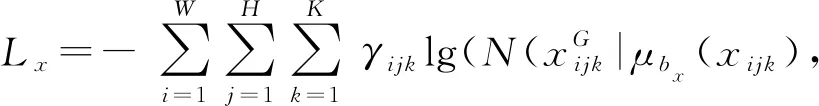
(7)
式中Lx——坐标bx的负对数似然损失,与Ly、Lw、Lh的计算方法相同
W、H——高度和宽度的网格数
γijk——对数似然损失参数

xijk——网格(i,j)中的第k个锚点
μbx(xijk)——bx的均值坐标
Σbx(xijk)——bx的不确定性
ε——对数函数的数值稳定性参数
2.3 基于改进YOLO v3的奶牛个体识别模型训练
用22 074幅训练集图像进行训练,用其余图像进行验证和测试。将经畸变矫正后尺寸为1 444像素×756像素的图像转换为416像素×416像素,以适于YOLO v3的输入。然后再分成13像素×13像素的网格单元,以便于输入网络进行训练。训练时,以64幅图像为一个批次,每训练一批图像,更新一次权值参数。根据预备试验结果,权值的衰减速率(decay)设为0.000 5,动量因子(momentum)设为0.9,最大训练次数设置为80 000,初始学习率(learning rate)设为0.000 5。在迭代次数为60 000和70 000时,学习率降低为初值的10%和1%,使模型在训练后期振荡减小,从而更加接近最优解。
本文对改进YOLO v3模型进行80 000次迭代,其损失(Loss)函数的变化如图7所示。由图7可知,在前2 000次的迭代中损失值迅速下降,表明模型快速拟合;在2 000~30 000次迭代中损失值缓慢减小,而30 000次迭代后损失值稳定在0.1~0.2之间,只有轻微振荡,表明此时的训练结果较好。
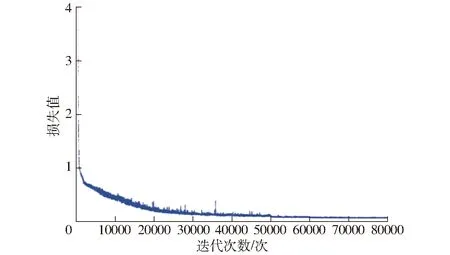
图7 损失函数的输出结果Fig.7 Output result of loss function
为了防止因迭代次数过多而产生过拟合,在30 000次迭代后,每隔2 000次迭代输出一次权值模型,得到25个模型。为了选取合适的模型,采用准确率(P)、召回率(R)、平均精度(mAP)、交并比(IoU)和平均帧率(fps)来评估模型性能,计算公式如下
(8)
式中TP——真实正样本数量
FP——虚假正样本数量
FN——虚假负样本数量
Ncow——所识别奶牛个体类别数量
n——类别序号
P(n)——第n类的准确率
R(n)——第n类的召回率
A′——检测出的边界框区域
本文需要识别89头奶牛个体,因此Ncow为89。在性能评估参数中,IoU用于测量真实值和预测值之间的相关度,相关度越高,该值越高,IoU的阈值选择直接影响准确率和召回率。本文的目的是识别出相似背景下不同牛只个体编号,对交并比要求并不高,故以IoU是否大于50%判断奶牛目标是否被正确识别。
同时引入衡量分类模型精确度的F1指标,F1同时兼顾了分类模型的准确率和召回率,计算公式为
(9)
式中F1——指标F1
为了对模型的性能进行恰当的排序,需要明确性能参数的优先级。在奶牛个体识别系统中,试验采用的性能参数优先级由大到小依次为mAP、F1、P、R、fps、IoU。
3 结果与讨论
mAP是评价模型性能的主要指标,故选择mAP最高的模型作为最优模型。通过最优模型对测试集中的奶牛个体进行识别,得到P、R、F1、IoU、fps,并与YOLO v3、Faster R-CNN进行比较。
3.1 最优模型的确定
改进YOLO v3模型迭代30 000次后输出的mAP变化曲线如图8所示。由图8可知,当迭代次数为70 000次时,mAP达到最大值95.16%,故选择迭代70 000次的权重参数作为最优模型参数。
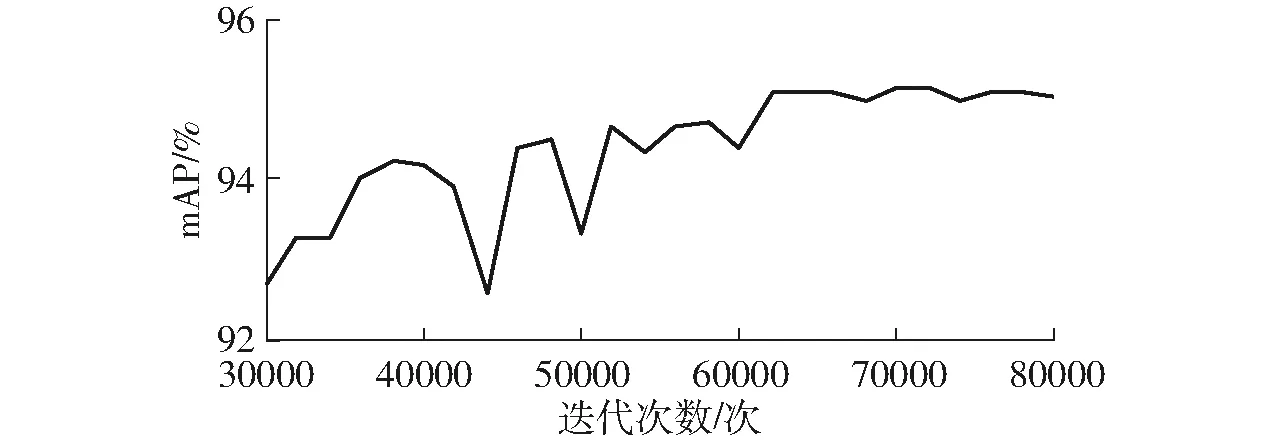
图8 mAP随迭代次数的变化曲线Fig.8 Change curve of mAP with iterations
置信度反映当前模型检测预测框内存在目标的可能性和目标位置的正确性,预先设定置信度阈值,预测框的置信度大于该值时被检测到。因此,同一模型在不同置信度阈值下预测的F1、P、R、IoU会产生不同变化,为找出最优置信度阈值,图9给出不同阈值下的参数值。
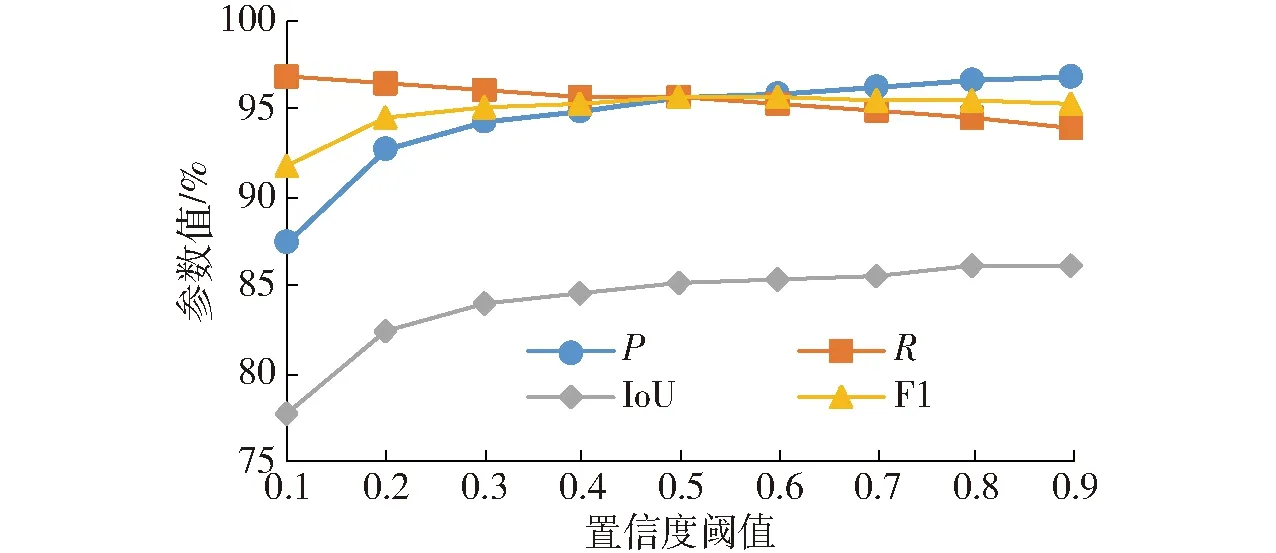
图9 不同置信度阈值下的性能参数值的变化Fig.9 Changes of different parameters with different thresholds
由图9可知,当置信度阈值取0.6时,F1达到最大值95.61%,其他参数处于较高值,模型预测结果最优。
3.2 模型识别结果
为了验证本文方法的可靠性和稳定性,用测试集图像进行分类识别试验,并与YOLO v3、Faster R-CNN识别结果进行对比。奶牛识别结果示例如表2所示。由表2可知,3种模型均能正确识别出不同奶牛个体编号,当视野中有多头奶牛时也能被很好地识别出来,表明构建的网络能可靠地识别奶牛,对牛只个体的形变具有较强的泛化能力。
3种模型在测试集上的F1、准确率、召回率、mAP、IoU和平均帧率如表3所示。由表3可知,本文模型测试集识别准确率为95.91%,略高于YOLO v3的94.97%和Faster R-CNN的94.01%;召回率为95.32%,较YOLO v3提高了4.98个百分点,较Faster R-CNN提高了6.03个百分点;平均精度为95.16%,比YOLO v3和Faster R-CNN分别提高了2.36个百分点和2.41个百分点。IoU为85.28%,比Faster R-CNN低2.1个百分点,但本文目的是识别奶牛个体,对奶牛位置精确度无要求,故IoU不影响对奶牛的识别。
从处理速度上看,本文模型平均帧率达32 f/s,是Faster R-CNN的8倍,能够满足奶牛养殖场对进出挤奶厅的奶牛个体编号的实时识别要求。
表2 奶牛识别结果示例
Tab.2 Examples of identification results for dairy cows

表3 3种模型对奶牛个体的识别结果
Tab.3 Recognition results of three models for dairy cows

模型F1/%准确率/%召回率/%mAP/%IoU/%平均帧率/(f·s-1)本文模型95.6195.9195.3295.1685.2832YOLO v392.6094.9790.3492.8082.5138Faster R-CNN91.5994.0189.2992.7587.384
3.3 不同体斑颜色奶牛的对比试验
由于荷斯坦奶牛的身体斑点仅包含黑白两种颜色,因此,奶牛背部体斑的颜色是特征提取和识别的主要因素。当奶牛体斑颜色接近纯黑色时,识别难度大。供试89头泌乳期荷斯坦奶牛中,背部为纯黑色的奶牛约占10%。
为了验证本文模型对不同体斑颜色的识别精度,构建体斑颜色测试集,共300幅图像,其中背部为纯黑色的单头奶牛图像128幅,背部为黑白双色的单头奶牛图像172幅。本文模型与YOLO v3、Faster R-CNN模型对不同体斑颜色奶牛检测的F1如表4所示。
由表4可知,本文模型对不同体斑颜色奶牛识别的F1值均高于YOLO v3和Faster R-CNN模型2个百分点左右。3种模型对黑白双色奶牛识别的F1值高于对纯黑色奶牛的检测结果,这是因为黑色奶牛本身特征参数较少,其特征提取更为困难。
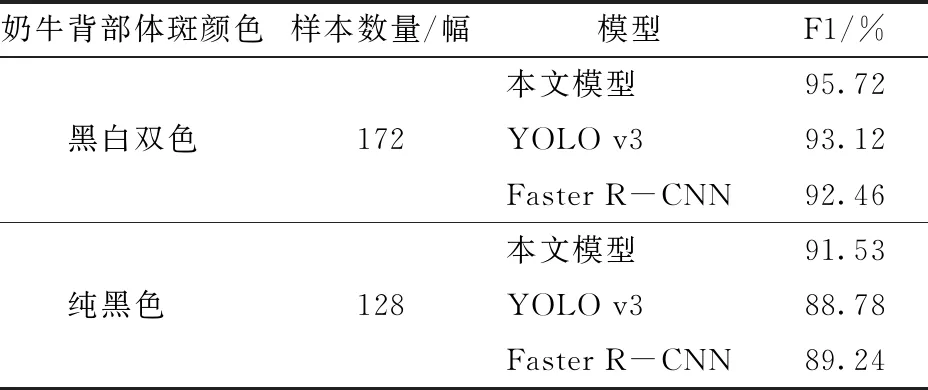
表4 3种模型对不同体斑颜色奶牛的识别结果Tab.4 Recognition results of three models under different body spot characteristics of dairy cows
3.4 不同模型的对比试验
为了验证本文模型的有效性,进行与其他模型的对比试验,结果如表5所示。
由表5可知,在识别对象和样本数量相当的情况下,本文模型的准确率比文献[15]模型提高了11.71个百分点,比文献[16]模型提高了0.61个百分点,单帧识别时间减少了1.910 s,比文献[22]模型准确率提高了9.81个百分点。
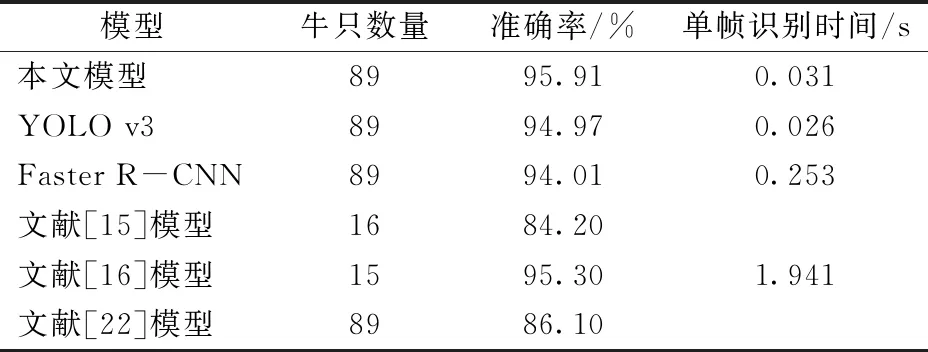
表5 不同模型识别结果Tab.5 Recognition results of different models
上述结果表明,本文模型提高了奶牛个体识别准确率,实际检测平均帧率达32 f/s,为后续实时检测奶牛挤奶时间和产奶量提供了技术支持。
3.5 讨论
本文构建的识别模型准确率为95.91%,有部分奶牛未能正确识别。其中一头黑色奶牛错误识别的情况如图10所示,16054号奶牛被误识别为16079号奶牛。

图10 具有相似颜色的奶牛错误识别示例Fig.10 Example of wrong identification of dairy cows with similar color
导致误识别的原因是16054号和16079号奶牛身体区域均接近纯黑色,背部花斑颜色相似,缺少用于识别的特征,即使肉眼观察也很难正确区分,故模型出现错误识别。且当奶牛个体快速通过视野时易产生运动模糊,导致奶牛骨架和轮廓等关键信息缺失,特征提取更为困难。
图11为YOLO v3和改进YOLO v3模型对视场中黑白双色的13223号和16099号奶牛的识别结果。YOLO v3模型只识别出13223号奶牛,未识别出位于左下角的16099号奶牛。图11a中16099号奶牛运动中背部有较大程度的弯曲变形,因此被漏识别。此外,该视频帧图像拍摄于中午,从挤奶厅侧方有强烈的太阳光照射,使很大白色区域的奶牛背部出现了高光与阴影,产生色差,交界区域边缘出现大量未经训练的特征,导致模型漏识别。而改进YOLO v3模型正确识别出视场中的2头奶牛,如图11b所示,表明改进YOLO v3模型具有良好的抗形变能力。

图11 2种模型对13223号和16099号奶牛的识别结果Fig.11 Identification results of cow 13223 and cow 16099 with two models
未来可在不损失精度的情况下进一步优化网络模型,提高模型对奶牛的特征提取能力。也可在纯黑色、纯白色奶牛背部人为做不同标记,提高其识别特征信息的能力,进一步提高识别准确率。
4 结论
(1)在YOLO v3模型的基础上,借鉴Gaussian YOLO v3算法增加网络的输出参数,并用K-means算法优化奶牛图像聚类锚点框,增加残差模块以改进网络结构,提出了基于改进YOLO v3深度卷积神经网络的挤奶奶牛个体识别方法。
(2)在实际环境中,对89头奶牛的识别结果表明,改进YOLO v3模型对奶牛个体识别准确率为95.91%,召回率为95.32%,mAP为95.16%,平均帧率为32 f/s,具有较高的识别准确率和适应奶牛形变的能力。
(3)本文方法识别准确率比YOLO v3和Faster R-CNN分别高0.94个百分点和1.90个百分点,检测速度是Faster R-CNN的8倍,单帧耗时仅为0.031 s,能够满足养殖场对挤奶奶牛进行实时识别的要求。
