杉木施肥引发基因表达响应机制的转录组分析
2020-04-26何贵平王海蓉邱勇斌程亚平徐肇友
齐 明,何贵平,王海蓉,邱勇斌,程亚平,徐肇友
(1.中国林业科学研究院 亚热带林业研究所,浙江 富阳 311400;2.浙江省遂昌县林业技术推广总站,浙江 遂昌 323300;3.浙江省开化县林场,浙江 开化 324300;4.浙江省庆元县庆元林场,浙江 庆元 323805;5.浙江省龙泉市林科院,浙江 龙泉 323700 )
林木施肥是人们有意识地将有机或无机的营养物质施入土壤中或喷施在植物体上,改变植物生长的外部营养环境,以改善林木营养状况,促进林木生长。Beautils[33]提出了配方施肥和平衡施肥的理论,已在林业生产中广泛应用,目前国内外主要用材树种的人工林普遍进行了施肥技术研究[1-2]。各国对不同肥料类型、不同养分配比、不同立地条件、不同培育阶段的林地施肥措施进行了深入研究[1,3-6],取得了许多成果,并广泛应用于林业生产。杉木Cunninghamia lanceolata对地力要求较高,目前我国杉木存在连栽和杉木造林地肥力不高等问题,采用营养遗传理论选育氮磷高效利用的无性系是解决问题的一个办法,但既对磷高效利用又对氮高效利用的杉木少而又少,所以施肥必需的。林业上有关杉木施肥进行了广泛的试验研究,但是施肥引发的基因响应分子机制却了解很少。本研究的目的是运用转录组技术研究杉木施肥的基因响应机制,可为杉木的施肥诊断和施肥方案的制定提供科学依据,为杉木营养遗传育种展开MAS 选择提供重要参考。
随着分子生物学的不断发展,利用转录组技术,对植物营养胁迫条件下磷的运转已有研究:如Li 等[7]采用水培法,进行磷胁迫处理,研究了PHT基因在杉木根茎叶中的转运规律;Lu 等[8]运用基因芯片技术研究了小麦Triticum aestivum施用有机肥和无机肥后,差异基因表达的规律;桑健[9]采用水培胁迫法,然后进行转录组测序,挖掘出与超积累型东南景天Sedum alfredii,HE的重金属耐受性及超积累性相关的胁迫应答基因:6个潜在的重金属的应答基因;陈双双[10]以超积累型东南景天为研究材料,采用水培胁迫的方法,研究了SaHsf家族基因对热、冷、干旱、盐、外源激素ABA和重金属Cd 处理的应答机制,发现与0 h 处理相比,12 h的胁迫处理就可以诱导抗逆显著的上调表达基因,和表达显著受抑制的下调基因。同时揭示了在Cd的胁迫下,SaHsf基因在根、茎、叶中均存在3种类似的表达模式;张运兴[11]以旱柳的栽培变型馒头柳Salix matsudanaf.umbraculifera为研究对象,旱柳Salix matsudana.为对照,探索二者在镉胁迫后的形态、生理生化和分子方面的差异,随后通过转录组测序技术从分子层面挖掘镉吸收、转运、解毒等相关基因,进而解析分子调控机制;Geng 等[12]运用水培进行磷胁迫的方法,研究了水稻Oryza sativa中磷的吸收与运转;Loth-perereda 等[13]运用水培进行磷胁迫的方法,研究了PHT1基因家簇在杨树Populus tremula中,结构与表达谱的变化。在杉木中借助RNA-seq 技术,研究杉木纤维性状发育的形成机制和木材形层成活动的规律,也有些研究[14-18]。但杉木施肥响应基因研究,目前尚未被涉及,施肥造成杉木高生产力的分子机制也未知,这是本研究要解决的关键问题。
本研究以基因差异表达分析为切入点,以杉木无性系开6为研究材料,4个施肥处理,两两间的比较分析,来探讨杉木施肥刺激引起的分子响应机制,揭示杉木施肥高生产力的原因。开展本项研究,以期了解施肥引发的基因响应机制,为研究与印证差异表达基因的功能提供科学基础。
1 研究材料与研究方法
1.1 研究材料
研究材料为速生的杉木无性系开6,2017年春进行扦插,年底抽取苗高基本一致,约25 cm 高的开6 共计12株,参与试验。
1.2 试验设计
移植苗放在试验大棚内,采用容器杯培苗,容器规格为直径14 cm、高13 cm。培苗基质为杭州市三桥育苗基地的缺氮少磷红壤土,其中缺氮少磷红壤土含有机质20.28 g.kg-1,全氮、全钾和全磷含量分别为0.427 g·kg-1、11.20 g·kg-1和0.269 g·kg-1,水解氮、有效钾和有效磷含量分别为39.3 mg·kg-1、131.60 mg·kg-1和2.44 mg·kg-1,pH 值4.55。
培苗基质的配制[19]如下:缺素红壤土∶河沙,按3:2的比例,混均匀后装杯,每杯土重2 kg,种一株杉木无性系开6,然后移到育苗大棚中缓苗6个月,其间不施肥,仅正常水分管理。到了2018年6月初,开始施肥试验,施肥量参照杉木育苗的施肥标准,试验设计如下表1。

表1 杉木施肥试验设计(硝酸铵和磷酸二氢钾溶于水的浓度为7‰)†Table1 Test design of fertilization for Chinese fir
杉木施肥试验设计的宗旨是检验施肥引发的基因响应,整个试验以缺磷少氮的贫瘠土为基质,施肥处理为:不施肥的贫瘠土地,对贫瘠林地单施氮肥或磷肥,以同时施加N、P 肥为参比对象。试验植株的编号是:group1 缺素组,三个重复分株编号码:C1-1,C1-2,C1-3;group2 施氮肥组,三个重复分株编号:N1-1,N1-2,N1-3;group3施磷肥组,三个重复分株编号:P1-1,P1-2,P1-3;group4 同施氮磷肥,为试验对照组WT,三个重复分株编号:WT1-1,WT1-2,WT1-3。选择连续几天天晴的天气,开始施肥试验,水肥150 ml 分三次浇肥,每隔12 h 浇50 ml的水肥,最后一次施肥后80 h后(12:00)进行取样:用自来水将杉木的根系洗尽,又用纯净水冲洗一遍,用剪刀将当年生的新根剪下,用铝箔纸包好,迅速浸泡在液氮中,第二天转移至-80℃的冰箱中,直至提取RNA时才放到冰块上。
1.3 研究方法
1.3.1 cDNA 文库准备及RNA-seq 测序
文库构建、无参转录组测序、及随后的unigene 功能注释、基因表达分析等项目的分析见有关文献[20-24]。
1.3.2 序列比对及差异表达基因分析
通过Illumina Hiseq4000 测序获得的转录组测序数据,需要经过以下几个步骤的生物信息学处理与分析[18,20-24],方能获得有意义的结果:1)原始数据处理;2)序列组装;3)unigene 序列的功能注释;4)unigene的GO 分类;5)unigene 代谢通路分析;6)预测unigene的编码序列(CDS);7)unigene的表达差异分析;8)差异表达的unigene的GO和Pathway 富集分析。所有这些分析项目均由软件完成,除了杉木新根样本的准备和研究方案的制定外,整个项目中的测序和初步分析委托杭州联川生物技术股份有限公司完成。
unigene 归一化采用FPKM(Fragments per kb per Million fragments)方式,其计算公式:

式(1)中:FPKM是某个基因(A)的表达量,C是唯一比对到基因A的片段数,N是唯一比对到所有unigene的总片段数,L为unigene A的碱基数。
测序数据进一步在Excel 平台和MatLab7.0 平台上处理,以获得有用的信息[25]。
2 结果与分析
2.1 测序数据质量和基因表达概况
不施肥处理、氮肥处理、磷肥处理和对照(氮磷混施)处理,共12个样本,测序测得的原始序列(Raw Reads)介于5.1E+07到7.2E+07 nt;12个样本的Clean reads 分别介于5.0E+07到7.1E+ 07 nt。总的拼接长度724,341,090 nt。Clean reads有效数据占原始Raw Reads的比例在98%以上。12个样本的Phred 数值大于Q20和Q30的碱基占总体碱基的百分比,分别介于98.20%~98.84%和95.07%~96.4%。原始测序序列中,碱基G和C的数量总和占总碱基数的百分比介于44.20%~45.08%之间。
12株样本,测得的基因表达量在不同区间的分布接近正态分布。综合以上几个测序质量评价指标,说明12 份样本的测序质量较高,能保证后续研究和满足后续数据分析的要求。
2.2 测序数据的拼接结果
测序数据的拼接结果列于表2。
从表2可见,平均GC%达42.47%;当读长数达50%时,该读长的长度为1 463 nt。综合其它项的结果,可以得出测序数据的组装拼接的结果很成功。杉木新根测序获得的unigene为74 288,这一结果与杉木针叶测序获得的结果[26](80 171个unigenes)十分接近,测序结果正常。
2.3 基因注释结果
对clean reads 在6个数据库进行BLASTX 分析,比对结果列于表3。

表2 拼接结果的统计Table2 Statistics of splicing results

表3 不同数据库BLASTX 注释结果统计Table3 Statistics of BLAST annotation of different database
将获得的unigene 序列分别与Swiss-prot,Nr,Pfam,KEGG,eggNOG和GO数据库序列进行比对,获得注释,组装unigene 数为74288个注释基因。由于针叶树已进行全基因组测序的树种太少,因而与农作物相比,针叶树种中挖掘出的基因也少。为了获得良好的测序分析结果,今后要加快针叶树的全基因组的测序研究。
2.4 不同的试验处理组间的基因差异表达模式分析
基于转录组测序结果,绘制基因差异表达韦恩图(图1)。
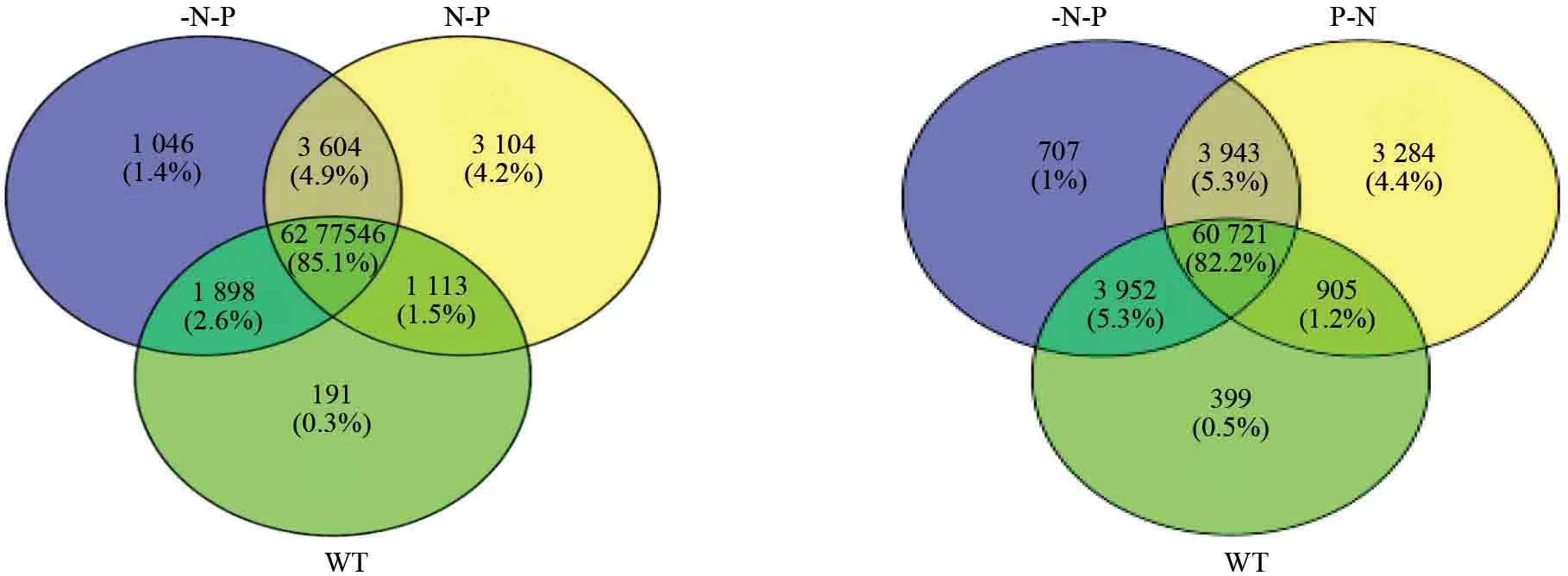
图1 杉木不同施肥处理引起基因响应之韦恩图Fig.1 A Venn diagram of different fertilizer treatments induced gene response
由韦恩图可以发现基因差异表达模式:不同的调控因子和转录网络(Transcriptional networks)在无性系中会重新结合,并导致基因表达方式的改变。
从图1(左)可见,在-P-N1-VS-WT 比较组中,它们有64 673个共同基因,相对于WT 比较组,未施肥组,有4 650个特异表达基因,其中包含了若干耐性基因;在N-P-VS-WT 比较组中,有63 888个共同基因,有6 708个特异表达基因,其中包含了若干磷素的敏感基因;从图1(右)可见,在P-N-VS-WT 比较组中,它们有61 626个共同基因,施P 肥后,样株受P 肥刺激,引起了7 227个特异表达基因,其中包含了若干氮素的敏感基因表达;N-P_VS_P-N 比较组的韦恩图未列出,N-P 处理与P-N 处理有共同基因65 768个,N-P 处理引发了4 828个特异表达基因的表达,P-N 处理引发了3 085个特异表达基因的表达。这些差异表达的基因参与了杉木氮磷的吸收、转运和利用。
2.5 4个不同施肥处理6个处理比较组的差异基因表达分析
4个不同施肥处理6个处理比较组的差异基因表达分析结果列于表4。

表4 杉木转录组组内差异基因表达分析结果Table4 Differentially expressed genes in different groups
由表4可知,不同的比较组间,差异表达显著和不显著的基因数目是不同的,施肥可以引起一些基因上调表达,或下调表达;也能引起一些基因默;同一比较组内,显著表达基因中,上调基因数与下调基因不等,表达不显著中,上调基因数与下调基因数也不等;各施肥处理组引起沉默的基因数在3 694~21 291 间变动。
2.6 杉木基因表达量的热聚类分析与施肥的分子响应
从测序组装、比对注释和基因表达量计算到基因的富集分析,最终从各样本组获得的差异表达基因中,分别抽取表达量极其显著25 左右个基因,进行热聚类图分析。热聚类图一共做了六组,这六组的热聚类结果是一致的:比较组内有一组是对照组,如表达显著的差异基因在对照组中高表达,则在试验组就低表达,它们是互补关系。在此仅列出一个比较组(施氮肥与不施肥组)的热聚类分析结果图,来说明这一结果。在图2中,不同颜色的区域代表不同的基因表达信息,同一处理内三个生物学重复间基因表达基本上是一致,而同一比较组中不同处理间,基因表达基本上是互补的:基因甲在处理组高表达,则在对照组就低表达,反之亦然。例DN56564_c1_g4 在未施肥处理组是低表达,则在施氮组中是高表达。如果在杉木林中检测到DN56564_c1_g4、DN56906_C1_g1、DN54750_c1_g2_、DN55368_c2_g1、DN54759_c1_g6、DN61447_c0_g4、DN62531_c0_g9、DN62712_c0_g1、DN32638_C0_g2 这9个基因下调表达的话,那么意味着该林分该施氮肥了。通过对这9个基因的功能进行了追踪发现:这9个基因多与氨基酸、蛋白质的合成、转运等功能有关。
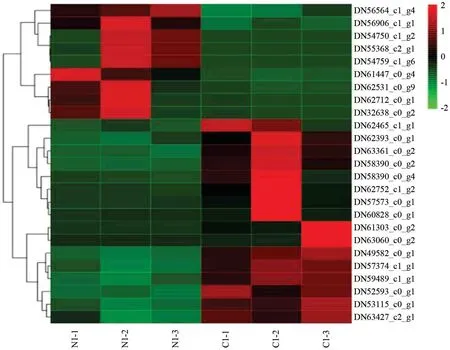
图2 N1_VS_C1 比较组间热聚类Fig.2 group2_VS_group1_heatmap
图2不同区域的基因表达模式相近,同一处理内基因分为上调表达和下调低表达,同一比较组内不同处理间,相同基因的表达是上调表达与下调表达互补,其它比较组的结果与图2一致,只是上调、下调的基因变了。这一结果说明,在缺素(缺N、P)造林地上,进行杉木施肥时,应该多肥种进行混合施肥;而且从施肥诱导的表达基因数量上看,磷肥的施肥量可以与氮肥可以不等量,这一结果与林业生产实践中得到了印证:在杉木经营中,施钙镁磷肥的施用量通常是尿素的三倍左右[27-30],这是由于钙镁磷肥易被固定,其利用率仅为10%~20%的缘故。林业施肥中,不同类肥料的吸收有相互促进的现象。但从所有的热聚类图还不能肯定或否定不同的肥种间对氮肥或磷肥的吸收利用,有相互促进作用的结果。
2.7 差异表达基因的GO 富集和分类分析
GO(gene ontology)是基因本体联合会(Gene Onotology Consortium)所建立的数据库,用于描述基因产物的功能。为全面了解施肥对基因差异表达的影响,以对照的基因为参照物,对六个比较组间的差异基因做了成对分析,获得了六个比较图表。差异表达基因的入选标准:1)Abs[ log2fold_change]>1;2)经FDR的校正过的P value <0.05。本研究选取C1-VS-WT 比较组,对所有的DEGs 进行GO 功能富集分析作图,进行示范:GO 富集和分类分析作图时,GO 功能分类体系中,有参与生物过程biological process、细胞组分Cell components 以及分子功能Molecular function 三个大类,50个小类别。不施肥与对照比较组的基因富集与分类结果见图3。
由图3可见,以对照组WT为参照物,在不施肥处理C1 中,不同的GO terms 中,参与新陈代谢的基因数目不同;针对大多数GO terms,上调基因的稍稍超过了下调基因的趋势;下调极显著的三个GO terms,按基因数目多少的排序(下同)是:等离子体的膜>细胞核>膜的有机组成。上调极显著的三个GO terms是细胞核>细胞质>分子功能;所有GO terms 上,存在显著的上调、下调基因,且上调基因略占优势。按照以上思路,其它比较组GO 富集与分类分析的一般结果列于表5。

图3 C1_VS_WT 比较组差异表达基因的GO 富集与分类(up:上调基因;down:下调基因)Fig.3 GO classification of differentially expressed genes in group1-vs-group4
由表5可见,不施肥处理、施肥处理六个比较组,对杉木GO terms 影响最大的,定位在叶绿体、细胞骨架、细胞膜、细胞核、细胞质上;其次是分子功能、蛋白质结合和生物过程等。从GO的富集与分类结果可以得出结论:施氮肥可以促进磷的吸收和代谢,同时施磷肥也可以促进氮的吸收和运转,因为氮和磷是生命元素,细胞分裂、伸长和发育都需要氮和磷,细胞活动是杉木生长发育的基础。缺乏氮素磷素山地上的杉木,表达较多的基因是对贫瘠的耐性基因。施肥后杉木林地的土壤环境发生了变化,对杉木根系产生刺激,诱导新的基因表达或上调一些差异基因表达,耐性基因可能下调或沉默了,新的基因又影响杉木体内的生理生化代谢途径的改变,这些正调控和负调控相互影响,从而推动了杉木整体的生长发育。
以前通常认为:上调基因的表达对植物生长发育具有正向效应;显著下调的差异基因可能对植物产生负向效应。但这里的研究表明,杉木施肥试验中,并不能肯定所有的基因表达增强就是有利的,并不能肯定所有的基因下调就是不利,如果不是这样的话,下调基因数超过上调基因数(表5中P1-VS-C1;P1-VS-N1)时,杉木样株怎么能生存?所以某些基因受到抑制也是有利的,这与姜涛等[31]的研究结果一致。
2.8 施肥对杉木的生理生化过程影响进一步分析
氮磷是生命元素。由上述分析可见,施氮肥或磷肥可以促进杉木的生长发育。但杉木的生长发育是由一系列的生理生化过程来完成。其中蛋白质在细胞分裂、生长伸长等生理过程发挥重要作用,但是蛋白质的合成过程是细胞核中的DNA模板上的mRNA,扩散到核外,在核蛋白体上形成一个合成蛋白质的模板。这时,较小的tRNA 复合体向mRNA模板靠拢,找到一个正确的“位点”。mRNA 能辨认tRNA 上与之相符的反密码子。这样tRNA 正确地将不同的氨基酸一个一个地带到mRNA的相应位置上,最后靠肽键将氨基酸连接起来,形成多肽链,并释放出tRNA。多肽折叠就是蛋白质,在这一过程中氨基酸—tRNA 大分子化合物的合成,成为合成蛋白质的重要一环。
由于蛋白质合成的重要性,我们选择施磷肥处理与对照组来分析施肥对杉木的生理生化过程的影响。根据KEGG 富集,得到tRNA 大分子化合物的合成途径:氨酰基—tRNA 生物合途径,见图4。其中,天门冬氨酰—tRNA合成酶[EC:6.1.1.12]显著上调,而其它的合成酶或转移酶不显著表达。在图4中,tRNA 在一系列的酶基因的催化作用下,分别与L-谷氨酸、L-谷氨酰胺、L-丙氨酸、L-天门冬氨酸,形成氨基酸-tRNA 大分子化合物,为下一步蛋白质的合成,提供前体(多肽)。这些催化酶基因见图4,其中天门冬氨酰—tRNA 合成酶[EC:6.1.1.12]显著上调,催化L-天门冬氨酸与tRNA,形成L-天门冬氨酰-tRNA,并使得这一反应过程在7 条通道中占主导地位。施磷肥促进了天门冬氨酰—tRNA 合成酶[EC:6.1.1.12]上调表达,从而促进L-天门冬氨酰-tRNA 大分子化合体的形成,也促进了蛋白质的合成。另外值得说明的是丙氨酸,天冬氨酸和谷氨酸代谢在施磷组中得到显著富集,这为氨酰基—tRNA 生物合成,提供了充足的前体。
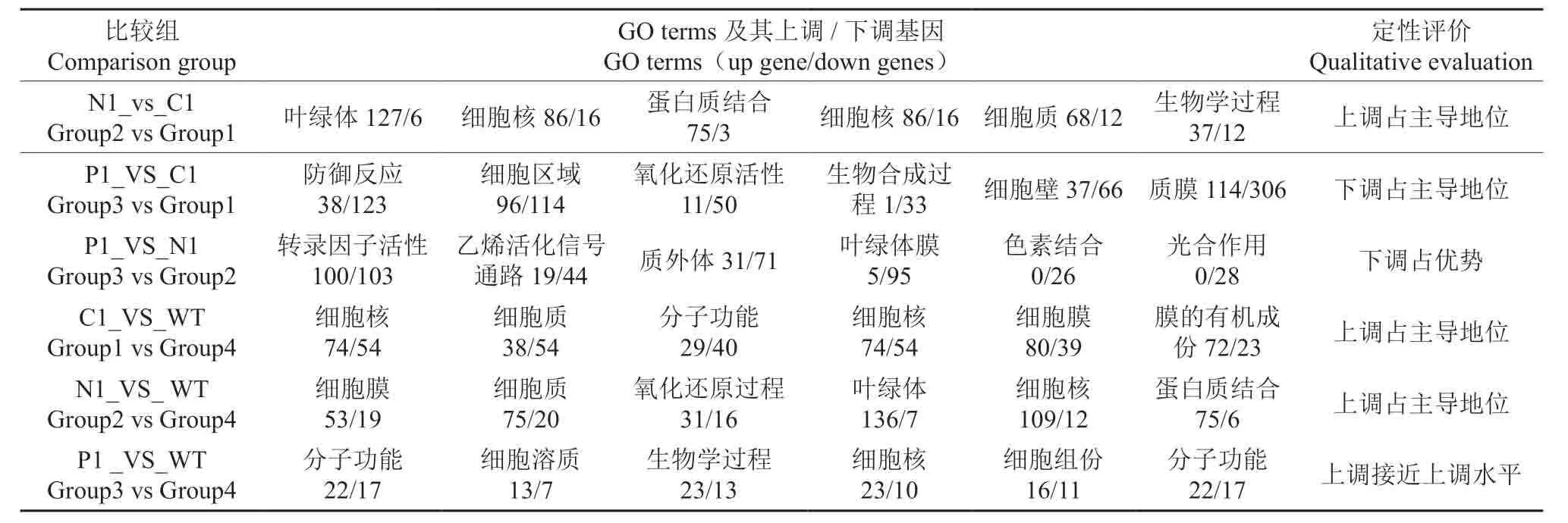
表5 显著差异表达基因GO 富集与分类前三名分析结果 Table5 Significant differences in expression gene GO enrichment and classification of the first three results
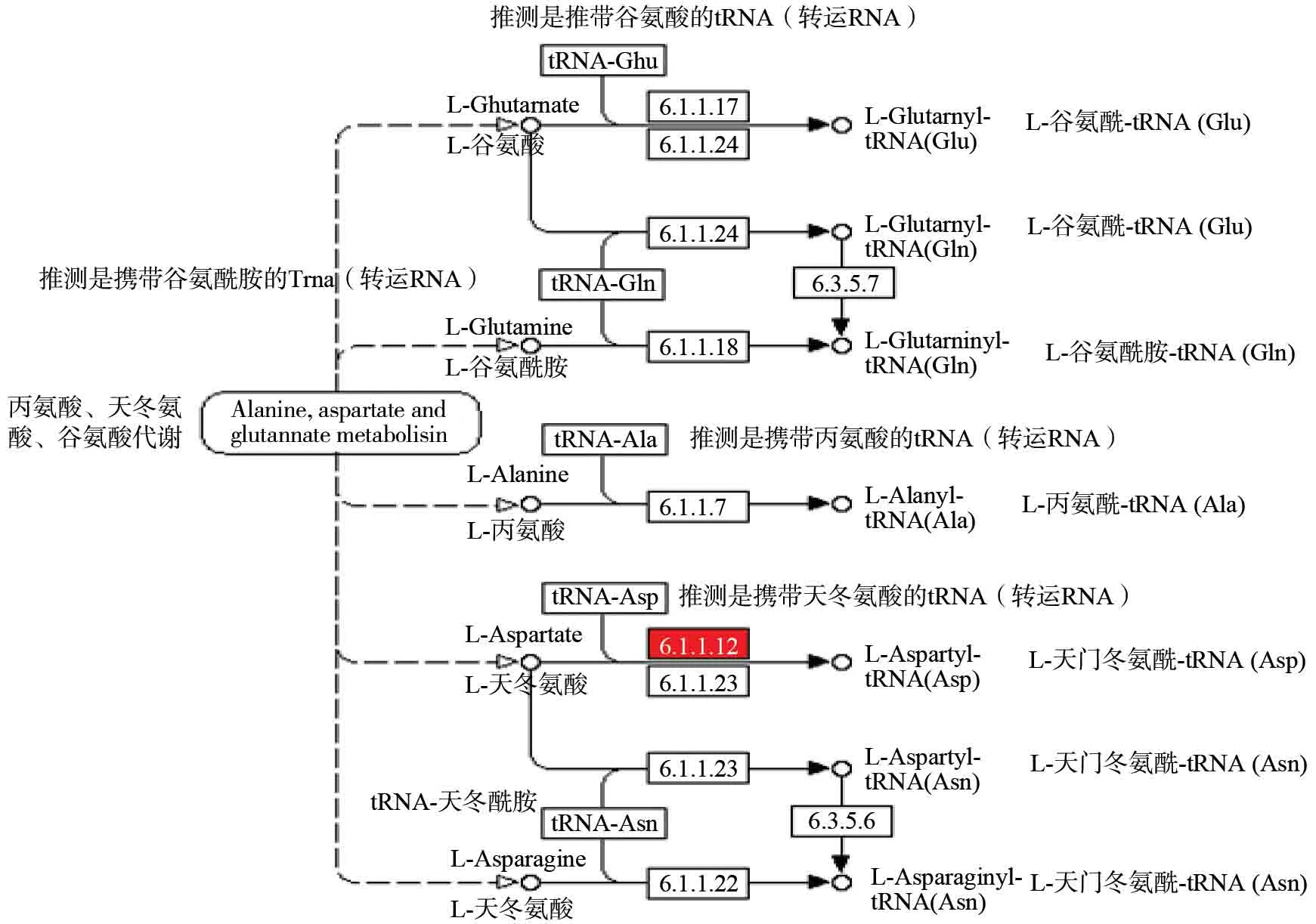
图4 氨酰基—tRNA 生物合成途径Fig.4 Aminoacyl—tRNA Biosynthesis
3 结论与讨论
水培法研究营养元素的吸收、运转规律,结果中包含了元素间的互作。但是砂培法也是有其局限性的:砂培的培养基质沉降后,肥料成分不可能象水培法那么均匀,那么易移动。但砂培的研究结果可直接应用到林业实践中。我国南方山地缺磷少氮,随着杉木经营的集约化,杉木施肥已是杉木营林必需的措施,其施肥理论和施肥技术进行了大量的研究,获得的宏观结果[32-35,37]与本研究微观水平的研究结果相一致:施氮(或磷肥)既能促进氮(磷)的吸收,又能促进磷(氮)的吸收。
由于缺乏参考基因组信息,本研究只能运用无参转录组技术,得到的差异基因信息的准确度可能会受到了限制。但目前对于大基因组的针叶树的测序几乎都是采用de novo 拚接,然后采用BLASTX 进行注释,进行差异基因分析,这样做肯定会有一定的、可允许的拚接误差。
施肥诱导基因响应的分子机制,得到了明确的结果,12个新根样本的转录组分析,获得了74 288个unigenes;施肥可以开启一些基因上调表达,同时也可关闭一些基因表达(基因沉默),还可调节一些基因下调表达。更多的情形是引发基因差异表达不显著。由于针叶树的转基因分子育种瓶颈效应一时难以克服,今后一段时间内的研究方向是,对杉木转录组分析获得的重要基因,研究其吸收,转运和利用途径,其结果可用于指导杉木施肥和杉木营养遗传育种MAS 选择。目前吴小波等[36]也对珙桐DiCCoAOMT1基因进行克隆和生物信息学研究,分析了珙桐CCoAOMT基因家族的表达规律,并克隆分析了其中一个与木质素积累关系密切的基因DiCCoAOMT1,为后续进一步探索珙桐内果皮发育,木质素的积累,种子休眠等生理过程的分子调控机制奠定基础。这也为珙桐展开分子育种迈出了第一步。
本研究发现:Illumina 转录组测序技术是非模式植物(包括具有较大基因组的针叶树)发现基因和研究基因表达谱的一种快速、简便的方法。杉木新根的转录组数据和基因表达信息表明:杉木施肥既会开启和上调一些基因,同时又会关闭和下调一些基因,其生长发育的调控是,向着有利杉木适应环境、竞争资源和生长发育的方向发展。
