基于距离相关系数和KNN回归模型的森林蓄积量估测研究
2020-04-26宋亚斌邢元军江腾宇
宋亚斌,邢元军,江腾宇,林 辉
(1.国家林业和草原局 中南调查规划设计院,湖南 长沙 410014;2.中南林业科技大学 林业遥感信息工程研究中心,湖南 长沙 410004;3.南方森林资源经营与监测国家林业与草原局重点实验室,湖南 长沙 410004)
森林结构参数估测是森林可持续经营和生态环境监测的重要内容。森林蓄积量作为森林结构参数中的一个重要因子,是组成陆地植被生物量的重要成分之一,是评价森林资源数量与质量、反映森林经营管理水平的重要因子[1],因此,准确地估测森林蓄积量对森林经营管理和生态环境保护建设具有重要意义[2]。
目前主要通过人工方法测量得到森林蓄积量,该方法费时费力,是森林资源调查工作中的难点之一。随着遥感技术的发展,将遥感数据与地面数据相结合进行建模,估测出森林蓄积量并绘制出其分布图,是未来森林蓄积量的主要获取方法。应用遥感技术估测森林蓄积量的研究主要体现在两个方面:一是采用不同遥感数据源构建估测模型,进行森林蓄积量估测[3-4];二是采用不同的估测方法,由传统的线性模型向非线性模型方法转变(如人工神经网络[5-6]、k 近邻分类算法等[7-9])。
本研究以湖南省湘潭县为研究区,采用Landsat8 OLI 作为数据源,应用线性模型、传统KNN 算法、距离加权KNN 算法和优化欧式距离的KNN 算法构建森林蓄积量模型,使用十折交叉验证方法进行精度检验,并对检验结果进行对比分析。为市域尺度的森林蓄积量估测提供理论依据和技术支持。
1 研究材料
1.1 研究区概况
湘潭县位于南岳衡山北部,湘江下游西岸,长衡丘陵盆地北段,27°20′~28°05′N、112°25′~113°03′E 之间(图1)。湘潭县属中亚热带东部常绿阔叶林亚带,按植被区系划分,属华中偏东亚系。气候为亚热带季风湿润气候,冬夏两季长,春秋两季短,暑热期长,严寒期短,热量充足,雨水集中,光、温、水空间分布差异小,灾害性天气较多,具有明显的大陆性气候特征。

图1 研究区位置Fig.1 Location of the study area
1.2 数据的获取及处理
1.2.1 数据处理
本次研究采用2014年湘潭县森林资源二类调查的地面数据作为研究样本,每个样地大小为25 m×25 m,样地分布如图2所示,运用标准差分析方法进行筛选,剔除了离群值较大的样本点后留下120个样点作为实验样本。
1.2.2 遥感数据的获取及处理
研究中所使用的遥感数据为2014年与二调同时期的Landsat8 OLI 影像,包括蓝、绿、红、近红外及两个短波红外在内的6个波段,由于Coastal 波段主要用于观测海岸线,因此在这里没有使用该波段。在ENVI5.3 软件中实现数据的预处理过程,包括辐射定标、大气校正、正射校正、几何校正和地形校正[10-12]。将样地位置通过ARCGIS 软件导入到遥感影像中,并提取样地所在像元的DN 值作为该样地的遥感因子。

图2 样地分布Fig.2 Sample plot distribution
2 研究方法
2.1 建模因子的获取与筛选
本次研究所提取的建模因子包括遥感因子与地形因子两个方面,其中遥感因子有:Landsat8 OLI 影像的7个单波段、植被指数[13]以及7个单波段的纹理共生矩阵;地形因子包括:海拔、坡度和坡向(地形因子使用研究区DEM 影像提取)。
如果将所有的候选变量都用于训练模型,则会导致信息沉余[14-15],并且使得模型的可解释性降低,因此要对所提取的建模因子进行筛选[16-17]。目前在同类研究中,最常用的变量选择方法为Pearson 相关系数。但Pearson 相关系数只能度量变量与蓄积量间的线性相关,并且必须服从正态分布假设。因此,本次研究使用距离相关系数来衡量变量与蓄积量的相关性,并选择出更加适合估测蓄积量的变量。距离相关系数弥补了Pearson相关系数的不足,它不仅能反映变量间的线性关系,也可以表示变量间的非线性关系[18],并且不需要任何的模型假设和参数条件。距离相关系数的计算方法如下:
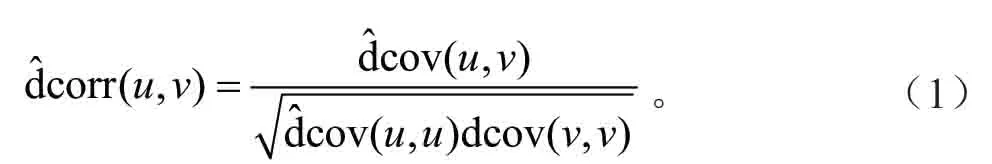

同理计算dcov(u,u)和dcov(v,v)。
2.2 KNN回归模型的构建
K 近邻(k-nearest neighbor,KNN)算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一,并且已经被广泛的应用于林分参数估计和蓄积量反演的研究中[19-21]。该方法的思路是:通过找出一个样本的K个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。也有学者在给样本赋值时,将不同距离的邻居对样本产生的影响给予不同的权重,再把根据此权重计算K个邻居的加权平均值赋值给样本,构成一种给予距离加权的KNN 算法[22-24]。
传统的KNN回归模型在计算距离时,每一个特征在计算距离时具有均等的贡献,没有考虑到样本各个自变量与蓄积量的相关性。因此,本次研究提出一种基于优化欧式距离的KNN 算法,此算法在计算欧式距离时,将各特征与蓄积量的距离相关系数作为权重,重新计算了样本间的距离具体公式如下:
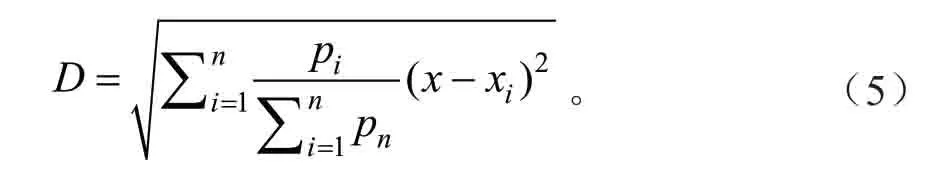
根据优化的欧氏距离,将所有训练样本重新排序,并根据距离加权KNN的方法将k个邻居的值赋值给预测样本。
2.3 模型的评估
本次实验使用十折交叉方法进行精度验证[25],以决定系数(R2)均方根误差(RMSE),相对均方根误差(RRMSE%)[26]3个指标对蓄积量估测模型进行评价,3个指标的计算方法如下:
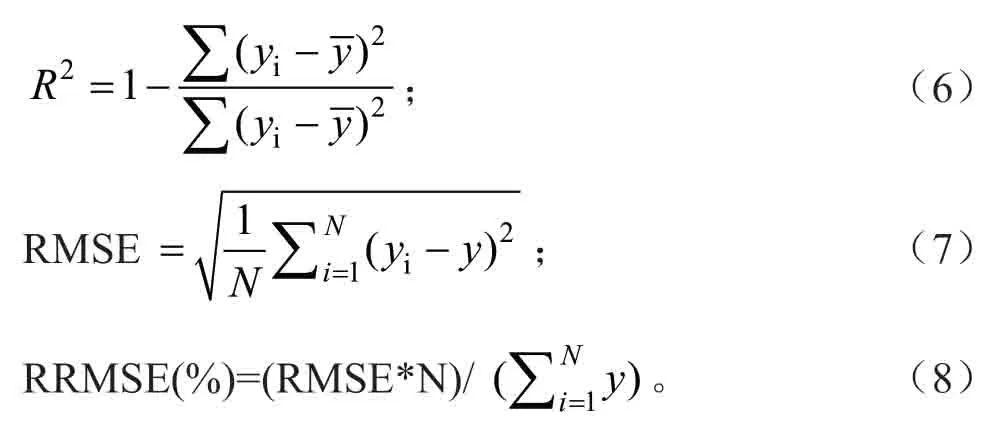
式(6)~式(8)中,yi为样地蓄积量的估测值,y为样地蓄积量的实测值,为样地蓄积量实测值的平均值,N为样地总数。
3 结果与分析
3.1 特征选择结果
本实验根据各个特征与蓄积量间的距离相关系数(DC)将所有特征进行排序,从第一个特征开始依次加入KNN模型中,当加入第7个变量时,模型的决定系数(R2)开始减小,因此取前6个特征作为本次试验的建模变量,特征选择结果见表1。

表1 变量选择结果Table1 Variable selection results
3.2 KNN模型估测结果
研究中通过十折交叉验证的方法对所有样本进行预测,3种模型下样本的预测值和实测值的散点图(图3),通过散点图和残差图可以看出3种模型都取得了较好的拟合结果,其R2均大于0.6,且残差均匀的分布在横轴的两侧。
为了进一步比较3种KNN模型对蓄积量的估测结果,分别计算模型的均方根误差(RMSE)和相对均方根误差(RRMSE%)并汇总(表2)。
由表2可以看出,3种KNN模型的估测结果均高于传统的线性模型,并且在3种KNN模型中,FW-KNN 取得了最好的拟合结果,其决定系数达到0.69,为3种模型中最高;3种KNN模型中,FW-KNN模型取得了最高的估测精度,其相对均方根误差为30.3%,相比于传统KNN模型降低了5.1个百分点,相比于FW-KNN模型降低了3.3个百分点。

图3 3种模型反演结果Fig.3 Inversion results of three models

表2 模型精度验证比较Table2 Comparison of model accuracy verification
4 结论与讨论
研究以湖南省湘潭县为研究区,采用Landsat8 OLI数据与同时期的二调数据结合起来,分别构建了MLR、KNN、DW-KNN 以及FW-KNN 4种蓄积量估测模型,使用十折交叉方法进行精度检验,得到了以下结论:
1)在使用Landsat8 OLI 影像估测蓄积量的过程中,3种KNN模型均取得了良好的拟合效果,说明利用Landsat8 OLI 影像信息构建KNN 蓄积量估测模型是可行的。
2)3种KNN模型的估测结果远高于传统的线性模型,说明利用遥感数据估测蓄积量时,KNN算法要优于传统线性模型。
3)传统的KNN模型在计算样本间距离时没有考虑到特征与蓄积量的相关性并且在给样本赋值时也没有考虑到预测样本与邻居的距离,本次研究中对这两点进行了优化,并构建了一种FWKNN模型,其估测误差相比于传统KNN模型降低了5.1%,说明通过特征与蓄积量的相关性优化样本间的距离是一种较好的KNN 优化方法。
在本研究中,KNN模型相比于线性模型在估测森林蓄积量中表现出了更加强大的预测能力,并且本研究对传统的KNN 算法进行了优化,在计算距离时考虑到了特征与蓄积量的相关性以及给预测样本赋值时加入了样本与K个邻居的距离作为权重,为KNN模型的优化方法提供参考。本研究中,所有的样本均使用一个K值,但每一个样本的最佳K值并没有找到,因此,如何找到每一个样本所对应的最佳K值还有待进一步研究。
