基于机器学习的布匹瑕疵识别研究
2020-04-26项子琦
项子琦
(江西财经大学 软件与物联网工程学院,江西 南昌 330013)
1 研究背景
中国上下五千年中,纺织产品生产过程中的质量控制主要采用人工的手段,工人工作强度大、检测效率低下,还存在不能控制误检率的问题。计算机视觉和人工智能的发展为纺织产品瑕疵识别技术提供了可能。对比传统的瑕疵识别算法,机器学习发挥了传统检测算法的优点,目前国内外机器学习发展特别迅猛。国内外学者提出了大量不同的机器学习理论: 贝叶斯分类器、深度学习、卷积神经网络、支持向量机、动态贝叶斯网络等[1-3]。
在纺织工业中,瑕疵定义为“与所需标准不同的事物”。许多因素可能导致瑕疵,例如织物的生产工艺不正确,纺丝厚度不符合标准等。通常情况下,我们经常可以通过织物上缺陷的类型来判断生产过程中的问题,然后进一步调整生产工艺。因此,织物检测系统的目的不仅在于检测织物中的缺陷,而且在于找到生产中问题的关键并达到改善生产性能的目的。
瑕疵识别模块属于布匹检测系统的核心模块之一。瑕疵识别系统对分类有较高的要求,需要使用模式识别的方法来对瑕疵图像进行分析与分割。
2 分类的基本概念
模式是一些提供给模仿者使用的模块化样本,是对抱有兴趣客观实体的结构性描述。模式类是某些拥有相同特点的样本的集合。模式识别这一技术就是通过模式类对模式进行分类,利用上述技术,计算机通过程序自动化把待识模式归类到不同模式类中去[4]。
模式识别系统主要由5部分组成:数据获取、预处理、特征抽取、分类器设计和分类器(图1)。
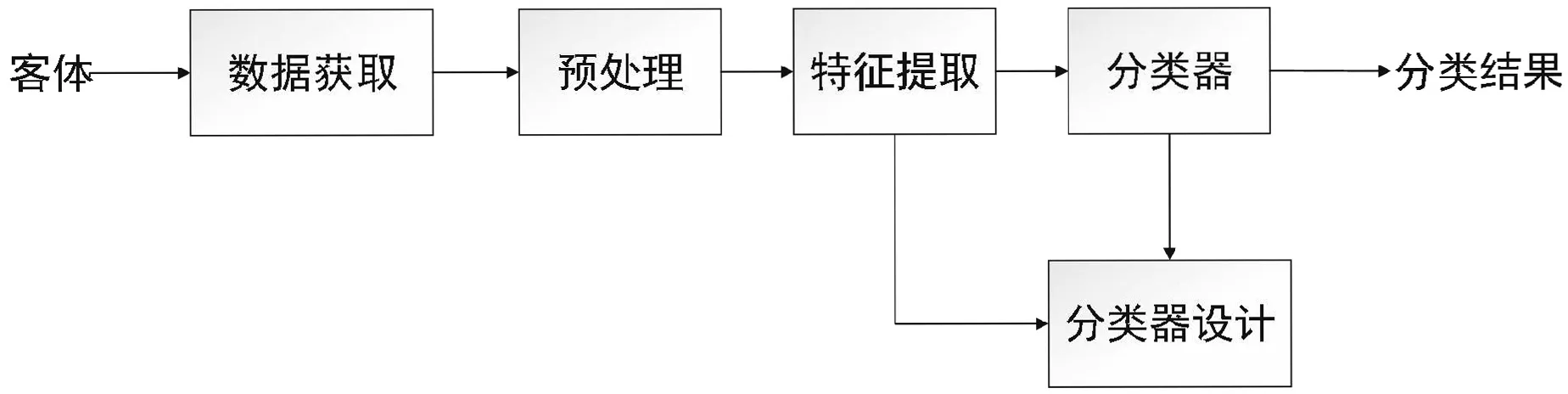
图1 模式识别系统的组成
3 支持向量机
支持向量机(Support Vector Machine,SVM)方法建立在通过内积函数进行非线性变换将输入的空间高维化上。支持向量机方法主要有两个理论基础:VC维理论与结构风险最小原理,其中的VC维理论基于统计学理论。根据有限的基础样本信息通过算法在处理模型的复杂性与提高学习能力这一矛盾之间制衡,得到推广能力最好的结果[5-7]。
在进行瑕疵分类之前,需要使用人员输入成千上万的样本对SVM模型进行训练,由于支持向量机求解二次动态规划问题的耗时很长,一般的普通模式识别时却只需要对有限的几个样本进行分类识别。传统的SVM方法采用的标准二次型优化技术可能是训练算法慢的主要原因:首先,SVM方法需要对核函数矩阵进行计算和存储,就存在内存超限的风险,例如当样本总数目很大时,存储核函数矩阵需要占据计算机的大部分内存;其次,SVM在二次型的寻优过程中要进行大量线性运算,寻优算法在时间上的开销巨大。
近年来,学者针对SVM的特点提出了许多改进优化算法,主要分为两个方面。
(1)块算法(chunking algorithm)。对于给定的训练集,大多数时候支持向量是未知的。块算法假设支持向量已知,对训练集进行迭代训练,通过迭代得到最优结果。
(2)固定工作样本集的方法。块算法看似很优秀,能提高运算能力,但是在大训练集,数据量大,导致迭代次数过多,随着迭代的增加,算法随之复杂,工作样本集也不可避免地增加。因此,固定工作样本集方法正是基于这个问题,将问题局限在固定的子问题个数中,减少了迭代次数,尽可能得到最优结果。
SVM算法用于布匹瑕疵识别的过程中,属于一个多模式识别问题。首先将不同类别的布匹瑕疵图像作为训练样本集,互相通过SVM进行算法处理学习,构造出适合不同瑕疵图像的分类器;然后再采用该分类器对待识别图像库中的所有布匹瑕疵图像进行分类,即算出每幅待识别图像相对于分类器中各个分类面的距离,可以判断出是否为瑕疵布匹[8-10]。
4 结语
介绍了SVM这一机器学习领域的“新星”在布匹瑕疵识别中的应用。SVM方法以结构风险最小化理论为基础,并具有传统机器学习方法所没有的特点:首先,可以得到算法中的全局最优点;其次,避免基础神经网络方法中存在的局部极值问题,且数据量小也能有很好的效果。由于单分类SVM属于模式识别,能够识别新的瑕疵样本,推广性较好,不受限于日常中瑕疵样本少的问题。此外,单分类SVM只需要对正常布匹图像进行训练,降低了数据的获取难度。
布匹瑕疵识别方法仍有大量研究工作,寻找更行之有效的布匹瑕疵识别算法,探索新的模式识别模型。此外,有效并可行的训练算法也是研究的重点之一,一旦有所进展能大幅提高效率。总之,如何让传统纺织行业中的布匹瑕疵识别充分合理地利用机器学习的发展进步仍是目前的研究重点。
