基于区间区域的位置隐私保护方法
2020-04-24宋国超初广辉武绍欣
宋国超,初广辉,武绍欣
山东科技大学 计算机科学与工程学院,山东 青岛266590
1 引言
目前,基于个人消费者需求的智能化,LBS(Location Based Services)[1-2]将伴随无线通信技术和GPS 技术(Global Positioning System)的发展,需求呈大幅度增长趋势。用户通过提供位置服务的APP 连接无线通信可以随时随地定位自己的位置来获取相应的服务[3-4]。例如,出行时获取的导航服务(高德地图),查找娱乐餐饮场所的生活服务(百度糯米),以及查找附近的人的社交服务(微信)等。据报告显示[5],全球LBS(Location Based Service)和RTLS(Real-Time Location Systems)市场规模预计将从2015 年的113.6 亿美元增长到2020 年的549.5 亿美元,CAGR(Compound Annual Growth Rate)为37.1%。
具体来说,用户实时请求LBS 服务时,将自己的精确位置和查询请求发送给LSP(Location Service Providers),LSP将查询到的符合用户需求的结果返回给用户。尽管LSP能够提供各种位置感知的优质服务,但是LSP可能会为了自己的利益泄露用户的信息给其他不法分子,威胁用户的人身和财产安全[6-7]。LBS服务存在着很大的安全隐患,而用户对位置服务的使用规模还在不断地增长,所以位置隐私的安全问题成为一个巨大的挑战[8-10]。
目前,一种被广泛采用的位置保护机制是k -匿名[11-13]。该机制采用集中式系统架构,借助匿名服务器选取k-1 个其余位置,连同用户位置一同发送给LBS服务器,保证用户真实位置被识别出来的概率为1/k。
在实际方案中,匿名服务器需要查询历史请求记录构建候选匿名位置集。这样保证了选取的位置的合理性。然而,现有的大多数研究工作没有考虑到检索庞大的历史记录带来的时间开销问题。并且,随着用户请求位置服务数目的增加,检索历史记录中的数据会越来越耗时,影响匿名保护效果,降低了位置服务的即时优越性。
幸运的是,本文构建区间区域,将其进行Geohash编码[14],这样做既考虑了选取位置的相似性,又借助编码检索避免了时间滞后性,加快检索速度,给用户提供更加快速安全的位置服务。另外,本文还考虑了用户的隐私需求,为用户提供了个性化的隐私保护的位置服务。借助Geohash编码生成候选匿名位置集,如果候选匿名位置集中的位置点个数不满足用户要求的隐私保护程度k 值时,采用虚假位置生成技术。而且在生成虚假位置时,均匀地将区间区域分成k 份,在每一块区间区域内进行随机选择。这样既保证了生成虚假位置的均匀分布,又增加了攻击者识别出真实用户的难度,很好地保护了用户的位置隐私。如果候选匿名位置集中的位置点个数大于k 值,使用位置筛选算法来选取k 个位置点,该算法加快了选取位置点的速度,减少了时间开销。
本文的贡献总结如下:
(1)本文借助Geohash 编码原理,提出了基于区间区域用来构建候选匿名位置集,采用了集中式服务架构实现个性化k-匿名模型来进行位置隐私保护。
(2)本文提出了全覆盖的虚假位置生成算法来解决候选匿名位置集中的位置点个数不满足用户的隐私保护需求k 值。这里,全覆盖意味着将用户所在的区间区域划分为k-1 等份,在每一个划分的子区域内随机选择一个位置,而且选择与道路最近的交叉点来避开不合理的位置(河流、湖泊等),保证了选取的位置覆盖了整个区间区域。
(3)当候选匿名位置集超过k 值,采用位置筛选算法来选取位置点构成匿名位置集发送给LSP。
2 相关工作
本章介绍了空间隐身技术和Geohash 编码应用的相关工作。
2.1 空间隐身技术
空间隐身技术[15]通过扩大空间区域来降低用户的真实位置精度。最具影响力的技术是位置k -匿名,使用区域内其他k-1 个位置来隐藏用户真实位置。
Gruteser和Grunwald[16]提出了一种自适应的空间隐身算法来实现位置k -匿名,该算法利用四叉树进行时空隐身。但是,这种方法有几个假设,比如它对所有请求都设定相同的k 值,这在实际中是不现实的,因为大多数用户在不同的情景下会有不同的隐私需求。
为了解决以上缺陷,Mokbel等人[17]提出了具有代表性的基于Casper 模型的空间隐身方法。该模型通过传输用户定义的k 值来提供用户对位置隐私的偏好。并通过四叉树将空间划分为H 层,每一层都保留了整个空间结构的信息,有效地提高了匿名性能。然而该模型需要过多的协作、可信的用户,因此在用户较少的区域,由于缺少足够的虚拟位置而导致匿名区域的构建失败成为一个主要缺陷。
为了解决用户较少区域的位置隐私问题,Ni等人[18]提出了一种在稀疏区域内构造匿名区域的K-SDCA 算法。该算法通过选择历史查询概率高、地理分布相对均匀、匿名服务器请求内容差异较大的虚拟用户来实现k-匿名,具有较高的安全性和较高的效率。但是,该方法不考虑检索历史查询记录的开销。因此,该算法耗时较长,影响了LBS的服务质量。
文献[19]提出了两个生成虚假位置的规则:(1)每个虚假位置的查询频率应与用户真实位置的查询频率相似;(2)在这些位置的查询频率保持不变的前提下,这些位置应尽可能地分散。然而,由于算法的过程发生在移动客户端上,计算量相对较大,并且对移动客户端的计算能力和存储空间要求很高。
文献[20]考虑到查询概率和匿名区域的面积,将位置隐私泄露问题表示成多目标优化问题,运用低复杂度的虚假位置选择方案生成k-1 个虚假位置实现k -匿名。虽然该方法降低了某些位置点被过滤掉的可能性,但由于算法的过程发生在移动客户端上,计算开销大。
文献[21]提出了基于聚类的k-匿名位置隐私算法来消除异常值,构造匿名集保护用户位置。该算法平衡了隐私保护安全性与位置服务查询质量之间的冲突。然而,由于聚类算法的迭代过程,时间开销没有得到优化。
SpaceTwist[22]是经典的不借助第三方匿名服务器的位置隐私保护算法,它使用锚来代替用户的真实位置。此外,用户可以根据他们的位置信息获得准确的结果。虽然该算法实现了保护位置隐私,但隐私保护水平不高。
文献[23]提出了一种基于映射的位置隐私信息检索技术称为MaPIR,该技术使用位置降维函数将用户真实位置映射到地理空间内生成冗余位置,保护用户隐私信息。根据地球赤道周长40 400 km,位置上的每个有效数字代表相应的距离范围,从而将位置的经纬度映射成了一维的数字,实现了位置降维。该技术可以提高检索速度,但是却不能提供个性化的位置隐私保护。
而本文借助以二分法原理为核心的Geohash 编码技术,可以快速检索历史请求记录数据库。同时,运用虚假位置生成算法和位置筛选算法为用户提供快速的自主的个性化的位置隐私保护。
2.2 Geohash编码应用
Geohash编码是将二维的经纬度坐标点转换为一维的字符串,某一个字符串表示了某一个矩形区域。也就是说在这个矩形区域中的所有经纬度点都共享一套编码也就是字符串。
Liu 等人[24]提出了地理哈希方法,用于构建GIS(Geographical Information System)领域分布式内存的分布式空间索引。该技术提高了空间数据的读写性能,为高性能地理空间计算提供了坚实的技术基础。
Li等人[25]提出了一种基于NoSQL 数据库系统的位置感知WBAN数据监测系统,该系统基于Geohash空间索引,能够高效地处理基于位置的医疗信号监测查询。这种新颖的数据分析方法有利于促进医疗分析服务的快速发展。
Guo等人[26]提出了自适应Hilbert-Geohash编码方法叫做AHG 地理网格系统。AHG 通过网格划分层次结构,可以直接表示被编码对象的位置和近似大小以及相应的编码长度。该方法除了具有加速空间查询的能力外,还具有良好的稳定性和可扩展性,已成功地应用于高性能地理信息系统HiGIS中的多个空间查询工具中。
由于Geohash编码技术通过将地理坐标编码,可以进行快速的空间近邻点检索功能,避免了复杂空间计算的时间开销,能够加快检索速度,常常被运用于地理空间数据检索领域内。另外,通过编码将用户精准位置映射到空间区域中,可以有效地保护用户的位置隐私信息,非常实用。所以,采用Geohash 编码技术既可以减少时间开销,又可以提供安全的位置服务。
目前,提出的位置隐私保护方案都各有特点,为了抵御攻击者的背景攻击,通常借助匿名服务器检索历史请求记录来构造虚假位置实现k -匿名机制,虽然这种策略取得了很好的匿名保护效果,但是大多数策略忽略了检索历史数据带来的时间开销,从而导致提供位置服务的速度变慢,影响了用户的体验度。
针对这样的问题,本文结合Geohash 编码的便捷性,提出了一种能够快速检索的位置隐私保护方案,该方案将用户真实位置泛化到区间区域内,对区间区域坐标转换成汉明码。通过对汉明码进行检索比较,筛选出相同编码的候选匿名位置集。为了给用户提供私人定制的匿名保护,对候选匿名位置集中的位置根据k 值进行不同的处理,提交满足用户要求的匿名位置集。仿真实验证明,本文方法不但能够加快匿名处理时间,而且还可以给用户提供个性化的隐私保护,更加符合实际情景,具有很大的应用前景。
3 预备知识
本章描述了相关定义和系统架构。
3.1 相关定义
首先,介绍位置k-匿名的概念。
定义1(位置k -匿名[16])位置k 匿名,将用户位置与其他k-1 个无法区分的位置发送给LSP,使得用户真实位置被识别成功的概率低于1/k 。这个概念是由Gruteser等人提出的。这里,k 代表了隐私要求,由用户定义。
本文中,用户发送的位置查询信息定义如下。
定义2(位置请求信息LQU) 位置查询信息是由用户发送的,用来请求位置服务的信息。它是一个四元组LQU<Uid,Uloc,T,QC >,分别代表用户ID,用户位置,当前查询时间和查询内容。这里的Uloc是个二元组<lat,lng >,分别表示用户位置的经度和纬度。
匿名服务器对用户真实位置Uloc进行保护,构造匿名位置集代替位置查询信息LQU发送给LBP。匿名位置集定义如下。
定义3(匿名位置集AS) 匿名位置集是由k 个位置构成的集合,包含用户真实位置和其余k-1 个由匿名服务器产生的位置。它是一个多元组,经过匿名服务器匿名处理构造AS,LQU变成了匿名请求AQU<Uid,AS,T,QC >发送给LSP来请求服务。
为了保护位置隐私信息,将一个位置坐标扩展成区间区域,利用区域内的历史请求位置信息来进行保护。具体地,区间区域定义如下。
定义4(区间区域)将位置的经纬度坐标分别映射到一个区间范围所表示的区域称为区间区域。
如图1 所示,假设一用户位置经纬度坐标为(50,30),其红线部分为区间区域为([40,57],[23,40]),其中50属于区间[40,57],该区间称为经度区间,30属于区间[23,40],该区间称为纬度区间。
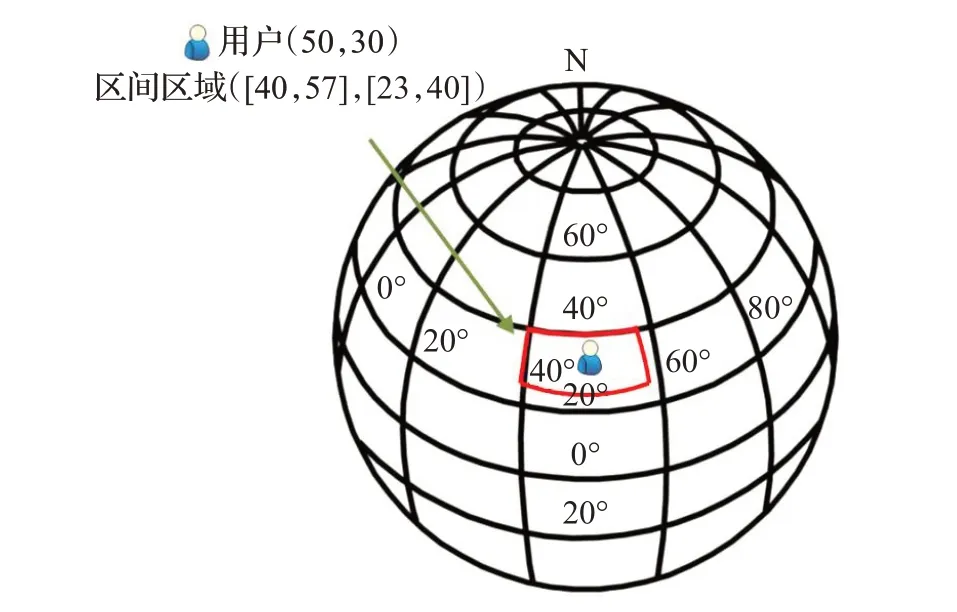
图1 区间区域例子
根据地球投影坐标系原理,将地球上的任意一点都能使用经纬度来表示。由于地球的椭球形状的特点,不同地区的经纬度变化所覆盖的区域大小也不尽然相同。而且,据计算,1 纬度大约能表示111 km 的距离。为了减少通信开销,本文中,区间的变化范围不会超过1。
将用户发送请求时的精准位置映射到区间区域之后,利用Geohash 编码来检索区域内的历史查询位置,现将Geohash编码定义如下。
定义5(Geohash编码)Geohash编码是将二维的经纬度坐标转换成一维的字符串的过程。该字符串称为geohash 码,表示某一个矩形区域。也就是说在某个矩形区域内,所有的二维经纬度坐标共享相同的编码。
将位置坐标进行编码之后,会按照反向检索的方式来查找相近的位置。
定义6(反向检索[24])反向检索是,根据某用户的geohash 码,查找第三方的历史查询记录,找出与之相同编码对应位置的过程。
如图2 所示,用户所在的区间区域的geohash 编码为“wtw3v”,反向检索数据库,对应的第一个和最后一个的位置编码是完全相同的。
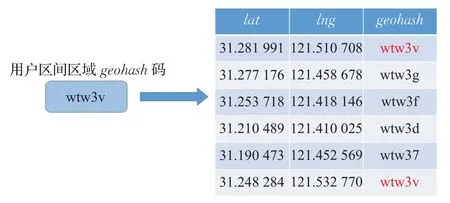
图2 反向检索例子
3.2 系统架构
本文采用了中心式系统架构。该架构包含的部件有位置请求用户、可信的匿名服务器[22]和位置服务提供商,如图3所示。请求过程为:
(1)需要进行位置请求的用户通过移动终端来发送位置请求信息给匿名服务器。
(2)匿名服务器将信息通过匿名算法变成匿名请求信息。
(3)匿名服务器将匿名请求信息发送给位置服务提供商。
(4)位置服务提供商根据发送来的请求信息通过查询位置数据库返回查询结果给匿名服务器。
(5)匿名服务器将结果进行过滤处理。
(6)匿名服务器将过滤结果返回给用户。
其中,起到保护用户位置隐私的关键部件是可信的匿名服务器,其功能为:
(1)能够快速响应位置查询请求,减轻移动用户端的计算开销,提高服务质量。
(2)通过匿名算法构造隐身区域保护用户隐私,避免隐私泄露。
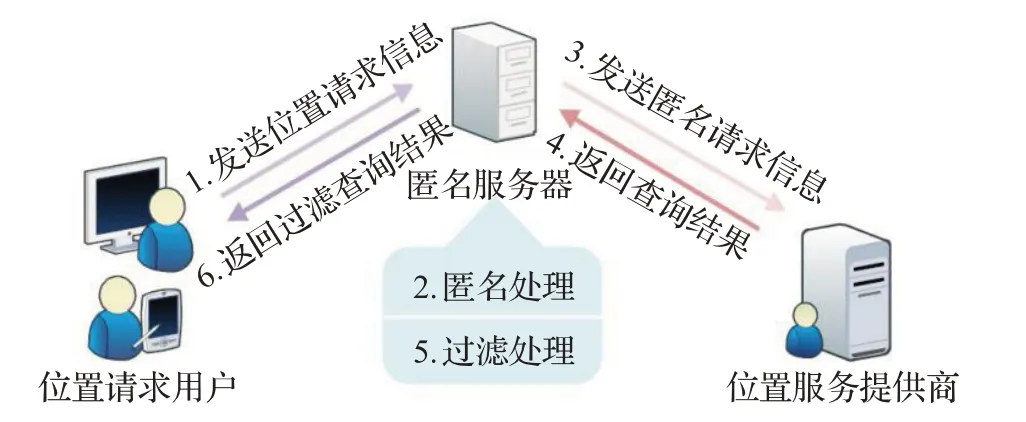
图3 系统架构图
(3)过滤LBS返回的查询结果,减少通信开销。
4 算法设计
本章详细描述了算法的实现过程。本文算法实现需要借助可信的匿名服务器。
4.1 位置泛化阶段
用户发送请求位置服务时,会将自己的精准位置发送给匿名服务器。根据区间区域的原则,匿名服务器首先将用户的经纬度位置泛化到区间区域内。借助随机数,随机产生4 个0 到0.025 随机数,将用户位置的经度和纬度分别减去和加上任意一个随机数,最终构成用户区间区域。例如:假设用户位置为(lat,lng),四个随机数分别为r1,r2,r3,r4,那么用户区间区域为([lat-r3,lat+r1],[lng-r4,lng+r2])。
对于位置泛化,需要说明以下三点:
(1)产生随机数的范围设定在0到0.025的原因是,地理位置1 纬度大约对应111 km 的距离,0.025 大约对应2.5 km,对于最大范围是经纬度前后波动各0.025°,则表示的区域范围大约是:(0.05/0.025)×2.5 km×(0.05/0.025)×2.5 km=25 km2,相当于250个100平的房子占地面积的大小,这个范围也是相当客观的。
(2)随机产生四个随机数,是为了防止攻击者预测出用户的精准位置,对用户精准位置进行了保护。若设置一个随机数,经度和纬度分别向前,向后波动,根据其区间的对称性,该波动的幅度很容易推算出来,从而用户的经纬度坐标也就暴露了。同样地,如果设置两个随机数,经纬度根据同样的方法也是可以推算出来的,所以这里会随机产生4个随机数,成功地避开了区间对称的特性,使得用户的位置不容易被预测出来。
(3)通常,随机数的产生是服从正态分布,也就是说产生的数值大部分是在0.012 5 左右波动的,接近0 和0.025 的随机数占的比例较少。按照数值平均波动0.012 5来计算,则区间区域的平均大小为:(0.025/0.025)×2.5 km×(0.025/0.025)×2.5 km=6.25 km2。
4.2 Geohash编码阶段
用户的区间区域确定了之后,计算该区域的Geohash编码。下面是其编码生成的伪代码。
算法1 Geohash 编码算法(Geohash coding algorithm)
输入:区间区域([lat1,lat2],[lng1,lng2])
输出:geohash 编码,geohash 码长度
1. lat range=[-90,90],lng range=[-180,180];
2. geohash=φ,code=φ;
3. lat mid=sum(lat range)/2;
4. lng mid=sum(lng range)/2;
5. While TRUE
6. if lng1 <=lng mid and lng2 <=lng mid //经度
7. code ←code ∪{0};
8. lng range[1]=lng mid;
9. else if lng1 >lng mid and lng2 >lng mid
10. code ←code ∪{1};
11. lng range[0]=lng mid;
12. else break
13. end if
14. if lat1 <=lat mid and lat2 <=lat mid //纬度
15. code ←code ∪{0};
16. lat range[1]=lat mid;
17. else if lat1 >lat mid and lat2 >lat mid
18. code ←code ∪{1};
19. lat range[0]=lat mid;
20. else break
21. end if
22. End While
23. 根据表1 中base32 映射表,将code 中的0,1 编码成geohash;
24. Return geohash,geohash 码的长度
Geohash 编码算法首先按照Geohash 编码的原则,对区间区域进行编码。一旦区间区域表示的范围不被划分区间完全覆盖时,跳出编码过程。这样做的原因有两个:(1)位置数据是浮点数类型,一般保留小数点后5到7 位的精度;(2)预处理阶段得到的区间区域本身就是一个数值范围,并且数值波动小,最大的上下浮动也只是0.05,在迭代的过程中限制的精度。满足这两个条件,区间区域的编码自身便有精度的限制,不需要用户去自定义设定,而且,编码产生的长度不会过长,也不会过短,避免区域过大或过小。
另外,返回geohash 码的长度是为了进行下一阶段位置检索,用来保护用户的位置隐私。
4.3 反向检索位置阶段
用户真实位置进行了Geohash编码之后,反向检索位置首先根据真实用户geohash 码长度,对第三方历史记录中的单个位置经纬度进行相同精度的Geohash 编码。然后进行检索,选出与之相同编码的位置,并进行去重操作,即重复的位置、将与用户真实位置相同的位置删除掉,最后统计位置个数,并与用户指定的k 值进行比较,若与k 值相同,则将其位置点构成匿名位置集AS,发送给LSP;若小于k 值,则执行4.4节虚假位置生成阶段;若大于k 值,则执行4.5 节位置筛选阶段,筛选合理的k 个位置,满足用户隐私需求。
4.4 虚假位置生成阶段
通过Geohash 编码检索出来的位置点个数小于用户隐私需求k 值时,采用虚假位置生成算法,生成k 个位置进行位置隐私保护。虚假位置生成算法的主要思路是在用户区间区域内均匀地生成k 个位置,其伪代码如下。
算法2 虚假位置生成算法(Dummy locations generating algorithm)
输入:用户区间区域([lat1,lat2],[lng1,lng2]),隐私需求k,用户真实位置Uloc(lat,lng)
输出:匿名位置集AS
1. D1=(lat2-lat1);
2. D2=(lng2-lng1);
3. Dmax=max(D1,D2);
4. d1=lat1,d2=ln g1;
5. AS=φ
6. if k%2==0
7. if Dmax==D1
8. for m=0 to k-1 do
9. Lat=random(d1,d1+(D1/(k-1)));
//从区间(d1,d1+(D1/(k-1)))任选一数赋值给Lat
10. Lng=random(lng1,lng2);
//从区间(lng1,lng2)任选一数赋值给Lng
11. AS ←AS ∪{(Lat,Lng)};
12. Lat=d1+(D1/(k-1));
13. end for
14. else
15. for m=0 to k-1 do
16. Lat=random(lat1,lat2);
17. Lng=random(d2,d2+(D2/(k-1)));
18. AS ←AS ∪{(Lat,Lng)};
19. d2=d2+(D2/(k-1));
20. end for
21. end if
22. else
23. if Dmax==D1
24. for j=0 to 2 do
25. for i=0 to (k-1)/2 do
26. Lat=random(d1,d1+(D1/(k-1)));
27. Lng=random(d2,d2+(D2/2))
28. AS ←AS ∪{(Lat,Lng)};
29. d1=d1+(D1/(k-1));
30. end for
31. d2=d2+(D2/2);
32. end for
33. else
34. for j=0 to 2 do
35. for i=0 to (k-1)/2 do
36. Lat=random(d1,d1+(D1/2));
37. Lng=random(d2,d2+(D2/(k-1)));

表1 十进制数值对应的base32码
38. AS ←AS ∪{(Lat,Lng)};
39. d2=d2+(D2/(k-1));
40. end for
41. d1=d1+(D1/2);
42. end for
43. end if
44. end if
45. AS ←AS ∪{(lat,lng)};
46. Return AS
首先,该算法分别计算经度区间和纬度区间的长度D1和D2,并取出两者的最大值Dmax,接着,判断k 值的奇偶性,若为偶数,根据Dmax分为两种情况,若经度区间的长度较大的话,经度区间均分为k-1 份,在每一份里随机选取一个位置,纬度取的纬度区间内的任意值,高度与用户位置高度相同。否则的话,将经度区间均分为k-1 份。若k 为奇数的话,区间长度长的纬度上均分(k-1)/2 份,短的区间内均分2份,在每一子区域内分别随机选取一个位置点。最后成功构造包含k 个位置的匿名位置集AS。
4.5 位置筛选阶段
当反向检索出来的位置个数大于隐私需求k 值时,要对区间区域内的位置进行筛选。位置筛选算法的伪代码如下所示。
算法3 位置筛选算法(Locations filtering algorithm)
输 入:候 选 位 置 集LS <(lat1,lng1),(lat2,lng2),…,(latnum,lngnum)>,用户真实位置(lat,lng)
输出:匿名位置集AS
1. 候选位置集中的位置个数为num;
2. A=B=C=D=φ;
3. for i=1 to num do
4. If lati>lat and lngi>lng
5. A ←A ∪{(lati,lngi)};
6. Else if lati<=lat and lngi>lng
7. B ←B ∪{(lati,lngi)};
8. Else if lati>lat and lngi<=lng
9. C ←C ∪{(lati,lngi)};
10. Else
11. D ←D ∪{(lati,lngi)};
12. End if
13. End for
14. 分别统计列表A、B、C、D 中的位置个数a,b,c,d;
15. 分别从列表A、B、C、D 中随机选取a(k-1)/num 、b(k-1)/num 、c(k-1)/num 、d(k-1)/num 个位置点添加到匿名位置集AS 中;
16. AS ←AS ∪{(lat,lng)};
17. Return匿名位置集AS
该算法首先将候选位置集中的位置根据用户真实位置经纬度分为四类,再根据相应的比例来选取各类中的位置点,最后连同用户位置添加到匿名位置集AS,发送给LSP,请求位置服务。
4.6 安全性分析
在某些情况下,攻击者可能会与某些恶意用户或位置服务提供商进行合作,以获取合法用户的位置请求信息。幸运的是,本文的方法可以成功地抵制攻击者的共谋攻击。
通常,如果成功推断真实用户位置的概率不随着共谋团体数目的增加而增加,则说明该方法可以抵抗共谋攻击。
下面对本文提出的方法进行了详细的安全性分析。
定理本文提出的方法可以抵制共谋攻击。
证明首先,若攻击者与某一恶意用户谋和,攻击者猜测出真实用户的概率也是1/k 。因为本文将用户的经纬度位置扩展到区间区域内,并进行编码,在历史请求记录中选择与用户区间区域编码相同的位置来进行匿名保护,而且,攻击者只拥有与谋和用户的历史请求记录,却不清楚被攻击用户的历史请求记录。所以,攻击者只能随机猜测真实用户的位置,这样,识别出真实用户的概率为1/k。甚至,当攻击者与多个用户进行谋和时,也不能降低猜测出真实用户的概率。因为,在本文方法中,用户与用户之间是相互独立的,互不影响,所以本文方法可以抵制攻击者与恶意用户的谋和攻击。
然后,若攻击者与位置服务提供商进行共谋,由于本文方法在产生区间区域时使用了随机数,虚假位置的产生和位置筛选都存在随机的因素,而匿名集的产生是没有规律可循的,所以攻击者无法根据匿名集来推测出用户的真实位置,猜测概率仍然是1/k。
综上所述,本文提出的方法是可以成功地抵御谋和攻击的。
5 仿真实验验证与分析
为验证本文所提位置隐私保护方法的有效性,使用Python 编程语言实现算法来进行仿真实验验证。位置数据来自Geolife 数据集[27],该数据集收集了从2007 年4月到2012年8月182个用户的轨迹数据。这些数据包含了一系列以时间为序的点,每一个点包含经纬度、海拔等信息。包含了17 621 个轨迹,总距离120 多万公里,总时间48 000多小时。这些数据不仅仅记录了用户在家和在工作地点的位置轨迹,还记录了大范围的户外活动轨迹,比如购物、旅游、远足、骑自行车。仿真实验主要关注算法处理数据的时间开销以及生成匿名区域的匿名保护效果。
5.1 处理数据时间开销
目前,大多数的技术通过距离计算来挑选候选匿名位置集。图4比较了本文使用的Geohash编码技术与曼哈顿距离[28]以及欧氏距离[29]处理数据的时间开销。欧氏距离公式为:
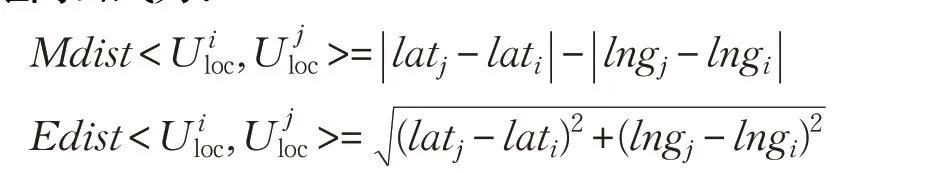

图4 候选位置数据量与时间开销关系图
实验中,将某一用户的第一条位置数据作为该用户真实位置,其余的作为历史数据用来挑选匿名位置集,运行100次取平均值作为输出结果进行比较。
如图4 所示,随着数据量的增加,三种方法的时间开销都会增加,而Geohash编码明显在时间开销方面具有卓越的优势。当数据量达到900条时,花费的时间还不足0.2 s。由于编码只是将二维的数据变成一维的字符串,不需要进行计算。而基于距离的检索,则需要进行距离计算,花费的时间就会大大增大。尤其是,采用欧式距离计算时,存在乘法运算,更是加大了时间开销。因此,通过Geohash 编码检索,可以快速地进行匿名处理,从而给用户提供快速便捷的服务。
5.2 算法执行效率分析
图5 分别比较了本文的匿名算法、Casper 算法[17]、DLS 算法[19]、SpaceTwist 算法[22]和基于聚类的k-匿名算法[21]执行时间随k 值变化的趋势。这里,待处理的历史请求记录为500条。
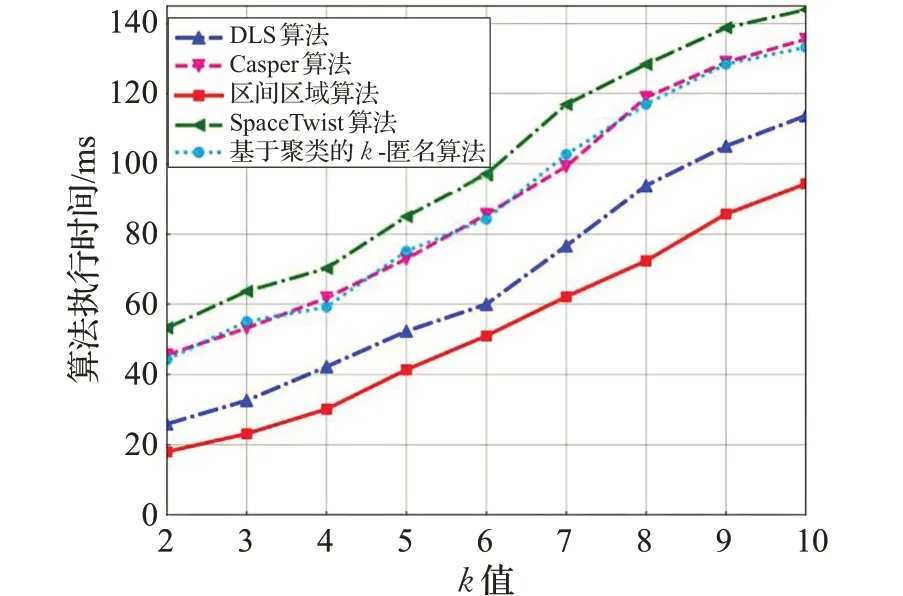
图5 算法执行时间与k 值的关系图
如图5 所示,随着k 值的增加,所有的算法执行时间都会增加,而本文算法时间开销是最少的。具体地,由于不借助第三方匿名服务器,SpaceTwist算法使用客户端附近的锚点来替换用户的真实位置,客户端计算压力大,算法执行时间最长。Casper算法在生成虚假位置时,产生的匿名区域过大,并且会产生大量冗余的位置,时间开销要大于其余算法。基于聚类的k-匿名算法与Casper算法的匿名处理时间类似,因为该算法使用了聚类算法,时间开销较大。而DLS算法在匿名处理时,借助历史记录数据库和查询概率,充分考虑背景信息,需要进行一轮的2k 个虚假位置候选匿名位置集选择,算法时间复杂度要优于Casper 算法。而本文实现匿名保护时,借助Geohash编码检索、生成虚假位置算法和位置筛选算法,可以快速地提供安全的个性化的位置服务。总之,在匿名算法时间开销上,本文算法占极大的优势。
5.3 匿名保护效果分析
匿名熵常用来表示位置匿名保护的程度[30],公式如下:

其中,pi表示真实用户被识别出来的概率,H(R)代表匿名熵,匿名熵的值越大,表明匿名保护的效果越好。
图6 表示的是不同算法的匿名熵与k 值的关系。算法包含随机算法、Casper算法[17]、DLS算法[19]、MOS算法[20]和区间区域算法。
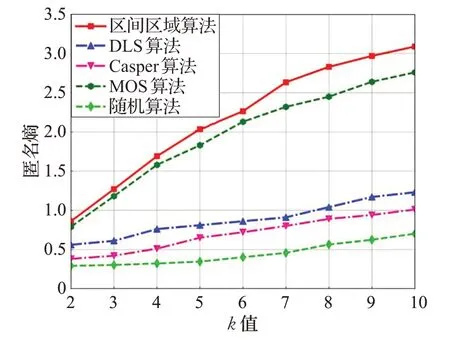
图6 匿名熵与k 值的关系图
如图6 所示,随着k 值的增加,所有算法的匿名熵都会增加,而本文算法的匿名熵始终是最大的。随机算法在指定区域内随机选择位置,时间开销最小,但是匿名保护效果很差。随机产生的虚假位置不考虑位置的合理性,攻击者可以过滤掉许多位置,导致匿名保护失败。Casper算法的匿名保护程度要好一点,因为Casper算法借助第三方匿名服务器的历史请求信息,能够增大真实用户不被识别出来的概率,但是,该算法会产生许多冗余区域,所以它的匿名效果也并不是最优的。而DLS 算法考虑了背景信息,同时,产生的虚假位置都是借助历史上查询概率相近的位置,所以匿名熵能高一点。MOS 算法生成的虚假位置尽可能远离真实用户,攻击者不能轻易识别出真实用户,匿名保护程度要优于DLS算法。而本文的机制在产生虚假位置时,在区间区域内均匀产生虚假位置,并且考虑到位置的合理性,根据实际道路情景信息进行位置调整。在位置筛选时,也选择了与真实用户相似的位置点,所以本文的匿名算法比前面算法的匿名保护都要好。
6 结束语
对于现有的k-匿名机制借助匿名服务器检索数据库时间开销大的问题,本文提出了借助Geohash编码的区间区域位置隐私保护策略。该策略首先将用户的真实位置泛化到区间区域中,然后根据Geohash编码原理来检索相同编码的位置,再根据用户的隐私需求,为用户提供个性化的k-匿名隐私保护服务。仿真实验表明,本文提出的方法在匿名处理时间具有更好的优越性,同时生成虚假位置算法和位置筛选算法保证了虚假位置的分布尽可能均匀,保证了用户真实位置被识别出来的概率降低,达到了很好的匿名保护效果。由于挖掘大量的位置信息能够分析用户的社会属性,未来的工作将充分考虑用户请求位置服务的时间维度,并分析和预测用户行为模型来完善目前的工作,对不确定的不安全因素提前预防,为用户提供可预测的动态位置隐私保护。
