改进级联卷积神经网络的平面旋转人脸检测
2020-04-24田妮莉杨志景BingoWingKuenLingEverettWang
傅 勇,潘 晴,田妮莉,杨志景,Bingo Wing-Kuen Ling,Everett.X. Wang
(广东工业大学 信息工程学院,广东 广州 510006)
0 引 言
近年来,基于深度学习的人脸检测和人脸识别[1-3]引起了广泛的关注。但在一些特殊的场景中,由于平面内旋转(rotation in plane,RIP)导致的人脸表面特征变化,使得这些人脸检测变得极具挑战性。而目前的人脸检测算法恰恰没有考虑到这些特殊的场景,因此需要一种精确快速全方位RIP人脸检测算法,以提高后续的人脸识别精度。
DDFD[4]指出在CNN训练阶段增加多视角多姿态人脸图片,可以提高多姿态人脸检测精度,该方法一方面需要对数据进行增广以检测RIP人脸,另一方面也需要较深的网络,而简单的数据增广会增加接下来多任务学习计算难度,不利于人脸关键点定位。C.Huang等[5]提出了将一张图片检测4次的方法来检测RIP人脸的方法,这种分治策略带来更多的误检测、时间开销成倍增长,显然不满足实际工程应用。H.A.Rowley等[6]提出了一个路由网络先估计候选框角度,再输入网络中识别,但由于没能精准估计角度及使用传统神经网络导致检测时间过长,精度不高。
Cascade CNN[7]通过级联多个CNN逐步过滤非人脸样本,实验结果表明,该方法能够有效实现人脸检测;而MTCNN[8]将人脸分类、边框回归、人脸关键点定位3个任务合并,证明相关联的不同任务地实现多任务学习,可以互相提升性能;PCN[9]也通过级联网络检测了RIP人脸。本文由此在传统的级联CNN的基础上,嵌入一个32net的RIP分类网络,本文不仅能检测任意角度RIP人脸,还进行了人脸关键点定位来实现人脸对齐,人脸关键点定位和人脸检测多任务学习提高了人脸检测性能,最后对本文算法进行了合理的评估。
1 级联卷积神经网络结构
在级联卷积神经网络分类器中,下一级的网络会比上一级更复杂,在模型前期去除大量的负样本,使后面的网络运行时间更短,级联分类器可以快速地检测目标,同时也减少了最后输出的正样本中FP(false positive)数量,提高了分类器地精确率(Precision)。本文由4个卷积神经网络构成一个级联卷积神经网络结构,如图1所示,Conv,MP,AP, fc分别表示卷积层,最大池化层,平均池化层,全连接层,(k×k)为卷积核尺寸大小,底部数字为feature map尺寸×个数。其中网络2(24net)和网络3(32net)为并行结构,输入都为网络1(12net)输出的人脸候选框。级联神经网络一般由3个小网络构成,如本文中的12net,24net,48net。

图1 级联网络4个CNN结构

24net是一个中间的起媒介作用的网络,和12net类似,同时处理人脸和非人脸的二分类和人脸边界框回归,通过12net后剩下的检测框尺寸重新调整成24×24大小,进一步通过24net筛选检测。24net包含3个卷积层、两个最大池化层和一个全连接层,进一步地拒绝大量地错误候选框,通过边界框回归偏移量校正网络输出的人脸候选框,最后进行非极大值抑制(NMS)。
48net结构如图1所示,类似于24net,但更复杂,增加一个卷积层,同时输出了5个关键点坐标信息。本网络验证了相关联的多任务学习可以提高人脸检测精度。
2 改进的级联卷积神经网络
本文改进了一个级联卷积神经网络,如图1中32net是本文增加的一个网络。检测器整个测试图片传输途径如图2所示,Pnet(12net)为第一个网络,输出较多候选框经过NMS后,同时输入Rnet(24net)和Cnet(32net),Rnet检测竖直人脸后经过NMS,Cnet保留旋转人脸并校正,最后输入Onet(48net)通过NMS去除IoU比值超过阈值的框。参考文献[8],给定一张图片,缩放到不同的尺寸来构建一个图像金字塔,输入到第一个建议网络(12net),产生较多地候选窗口同时对候选边界框回归,初步的非极大值抑制去除重叠区域比率很高的检测框。

图2 测试图片传输途径
剩下的检测窗口同时输入改善网络(24net)和分类网络(32net),分类网络保留在平面内旋转角度[45°,315°]之间的候选框,通过Softmax层输出类别后,进行相应的仿射变换,变换成竖直方向的正脸,再输入最后的输出网络(48net)得到人脸候选框和关键点坐标;同时12net输出的候选框输入24net进一步检测筛选掉非人脸框,经过非极大值抑制后,将剩下候选框输入最后的48net得到人脸候选框和关键点坐标,最后将两次48net输出的候选框合并通过非极大值抑制消除IoU(交并比)比值超过阈值的框,得到最终的输出。也就是说,当测试图片中包含旋转角度过大的人脸时,通过12net,32net,48net校正在平面内旋转人脸候选框,得到人脸框和相应的关键点坐标;测试图片中的正脸,旋转角度[-45°,45°]之间的人脸通过12net,24net,48net,检测输出相应的人脸候选框。
2.1 分类网络
本文将平面内旋转人脸检测看作一个多分类问题,即将平面空间划分为4个类,并将某一旋转角度下的人脸划分到其所属的类中,如图3所示,1、2、3类被32net保留。

图3 平面内旋转人脸类别
32net是一个4分类网络,如图3所示,将任意平面内旋转(rotation-in-plane,RIP)角度的人脸分为4类。网络1输出的所有的候选窗口调整成32*32大小输入32net,再对RIP角度人脸进行4分类,将一个平面内的人脸按照角度划分成4类,每个类别都包含一个90°区间大小的RIP人脸。32net网络结构如图1所示,包含3个卷积层、3个池化层和两个全连接层,为了提高分类准确率,在每个卷积层后加入BN[11]层,输入每一维度减去自身均值,再除以自身标准差,使用随机梯度下降法训练,这些均值和方差也只在当前迭代的batch中计算,将数据以mini-batch的形式逐一处理,但测试时对每个样本逐一处理,BN层有正则化效果,可以加速网络学习等优势。对于这个4分类问题,每个样本xi, 使用交叉熵损失函数
(1)
其中,pi是样本xi属于各个类别的概率,分类模型经过Softmax激活函数之后,4个类别概率总和变为1,这里归一化的作用是输出4个直观的概率值,yi∈{0,1,2,3} 指示各个类别的真实标签。
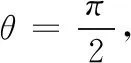
2.2 仿射变换
如图2所示,48net输入为上一级中两个网络输出的所有候选框。若这一级也就是最后一级输出含有32net中产生的候选框,先进行仿射变换,仿射变换是将RIP人脸候选框坐标进行变换,得到实际人脸框在整个测试图片上的坐标,变换矩阵为
(2)
(3)
(4)
二维旋转变换公式
M=B1×B2×B3
(5)
首先将旋转中心移动到坐标(0.5,0.5)处,然后执行θ角旋转,当为图3中的1类时,候选框旋转90°,当为类别2时,候选框旋转180°,当为类别3时,候选框旋转270°,再将旋转中心移回到原来位置,得到旋转人脸候选框的坐标,同样,我们可以求出RIP人脸的关键点坐标。这里只旋转了候选框,而之前32net是旋转框内的图片。最后将候选框进行非极大值抑制(NMS),得到最终的输出。
3 实 验
这部分介绍了网络训练、数据预处理和多任务学习中各个任务的训练细节及作用。同时为验证本文提出的级联卷积神经网络在人脸检测任务中的性能,本文人脸检测方法与当前最新的算法在FDDB数据集上对比,该数据集是权威的人脸检测的评测基准,包含2845张图片,共计5171个人脸,人脸标注为椭圆标注。接下来评估本文方法在RIP人脸数据集的图片上的性能,最后评估本文方法的运行效率。
本文实验用到Python2.7、Matlab、VS2013编译环境,使用Caffe框架,采用GPU提高计算速度,GPU型号Nvidia Titan Xp,GPU内存为16 G。
3.1 训练过程
本文对4个网络单独进行训练,第1、2、4网络训练参考文献[5],结合人脸二分类、人脸框回归、人脸关键点定位3个任务训练一个级联卷积神经网络常规人脸检测器。本文为了检测RIP人脸,增加一个分类网络。制作训练集和验证集训练第3(32net)网络,是一个轻量级的网络模型,损失函数为式(1),接下来介绍其训练细节。
32net训练数据来源于LFPW,该数据集包含大量简单场景下的常规人脸,首先对图片进行较小的平移、旋转和镜像等方法进行数据增广,图片原来的人脸标注也需要重新计算,再对图片进行3个大角度旋转及人脸框标注的坐标进行变换,最后裁剪图片中的人脸,得到4个类别训练数据,每个类别图片20 K左右,使训练集覆盖各个RIP角度的人脸。这里主要保存RIP角度较大的人脸候选框,所以在类别0训练集中加入了非人脸及部分人脸,这样12net检测出的非人脸候选框及RIP角度很小的人脸都会被32net筛选掉。
本文通过训练大量的人脸图片解决RIP人脸检测和关键点定位,第1、2、4网络主要参考文献[8],训练数据来源于WIDER FACE[12],负样本和真实人脸框IoU比率小于0.3,正样本IoU比率大于0.65,部分人脸IoU比率介于0.4到0.65之间,人脸关键点回归数据来源于CelebA[13],级联网络训练集数据组成比率为3∶1∶1∶2,分别为负样本、正样本、部分人脸样本和包含人脸关键点坐标样本。
3.1.1 人脸分类
网络学习到一个2分类问题,对最后输出的feature map判断,当预测为正类时,经过坐标变换求出人脸候选框。对于每个xi, 类似于式(1),使用逻辑回归交叉熵损失函数
(6)
其中,pi是样本xi属于人脸的概率,通过网络输出得到,yi∈{0,1} 代表真实样本标签。
3.1.2 人脸边界框回归
对于每一个候选窗口,预测它和最接近它的真实样本框(左顶点坐标,高和宽)的偏移量,学习一个回归问题,对于每个xi, 使用欧式距离损失函数
(7)
3.1.3 人脸关键点定位
类似于人脸框回归,人脸关键点预测也是一个回归任务,使用最小化欧式距离损失函数
(8)
3.2 人脸框校正
网络同时学习人脸关键点回归和人脸框回归任务时,极大程度提高了两个任务单独训练的准确度,本文主要为了提高检测RIP角度人脸精度。人脸关键点坐标是相对于人脸框的相对位置,而不是直接在整张测试图片中定位出坐标信息。为了更准确定位出关键点坐标,48net训练时只训练竖直方向人脸,训练单一的样本使得人脸关键点坐标和人脸框之间对应关系简单,更容易完成多任务学习,也简化了测试时的计算步骤。
人脸框回归测试效果如图4所示,粗略框由人脸二分类得出,边界框回归校正后的为准确框。测试图片时,当最后一级网络输出不加回归偏移量时,预测为粗略框,增加回归向量偏移量后校正后为准确候选框,直观表明人脸框回归任务可以提高人脸检测精度。图4是改进后的网络输出,简单的级联网络只能检测和校正竖直人脸。

图4 人脸框回归偏移量校正人脸候选框
3.3 FDDB人脸数据集评估
FDDB使用椭圆标注定义两种评估类型:连续得分和离散得分,跟随FDDB网站的评估程序和步骤来检测本文的人脸检测器性能,在FDDB数据集对比不同的人脸检测器,如图5和图6所示,可以看出,本文的方法在FDDB数据集表现和MTCNN[8]检测效果接近,优于本文提到的其它方法,本文主要为了检测旋转人脸,接下来我们将测试本文方法在旋转人脸数据集上的表现。
3.4 评估旋转人脸
本文创建了一个旋转人脸测试集,包含725张图片,853个人脸,其中603张图片来自CelebA[13],将这些图片分别进行3个大角度的旋转,使人脸覆盖上文提到的4个类别及任意RIP角度,然后对其标注进行相应坐标变换,另外122张图片从网上下载,主要为家庭合影、瑜伽、街舞、艺术表演和体育运动背景图片,我们对图片中的人脸标注了矩形边界框。一些检测图片效果如图7所示。
接下来评估了分类器在该测试集上的性能,绘制PR曲线,如图8所示,MTCNN[8]很难完成RIP人脸检测,召回率最大时都没有到达0.5。实验结果表明,普通级联卷积神经网络不能精确地检测RIP人脸,很多RIP人脸未检测到,本文提出的改进方法提高了RIP角度的人脸检测的查全率,也提高了查准率,本文方法在该数据集上检测召回率为0.847,精确率为0.9。本实验采用召回率(Recall)作为评价指标,召回率越高,检测效果越好,召回率计算公式如下
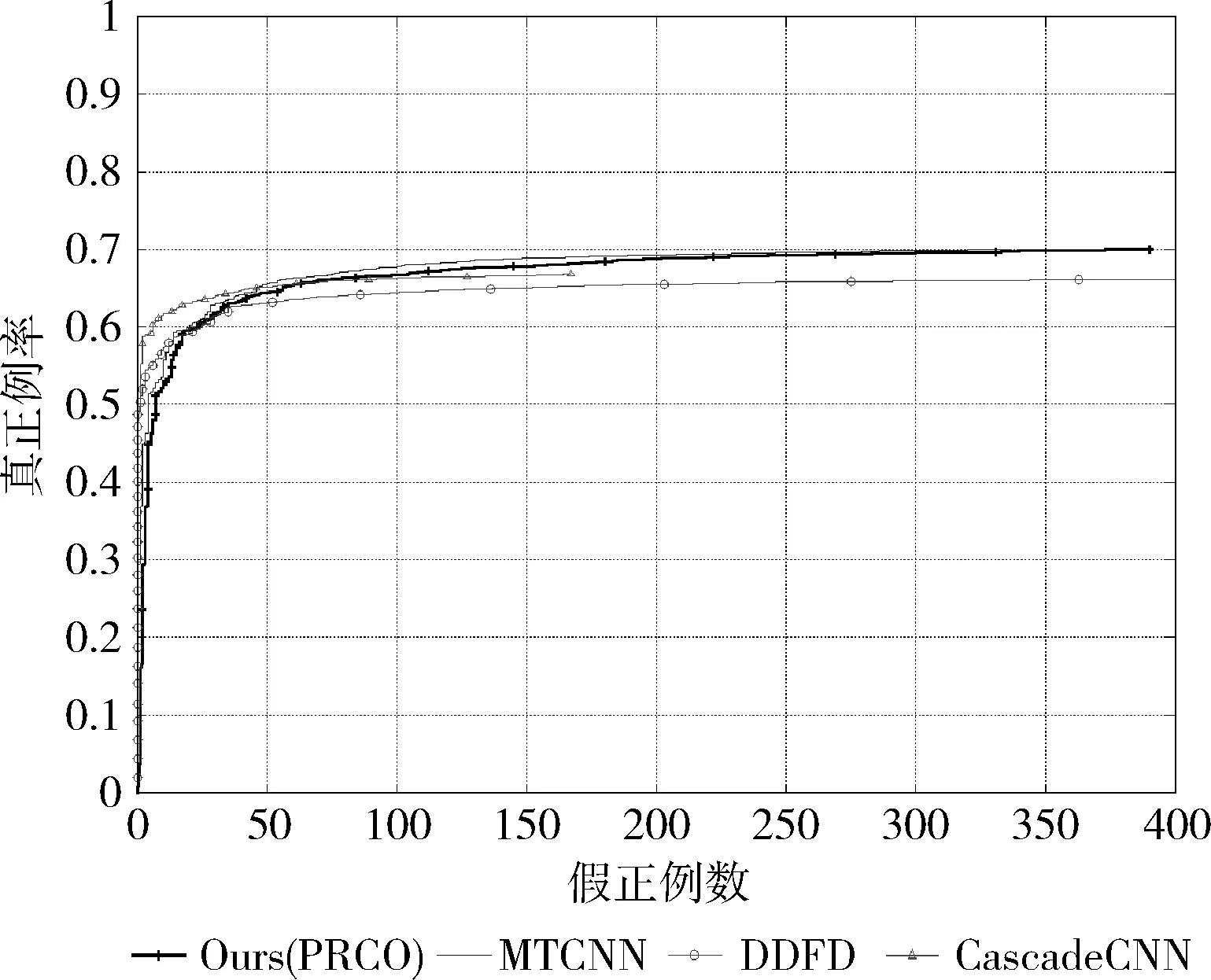
图5 对比其它方法连续得分效果

图6 对比其它方法离散得分效果

图7 部分检测结果样例图像
(9)
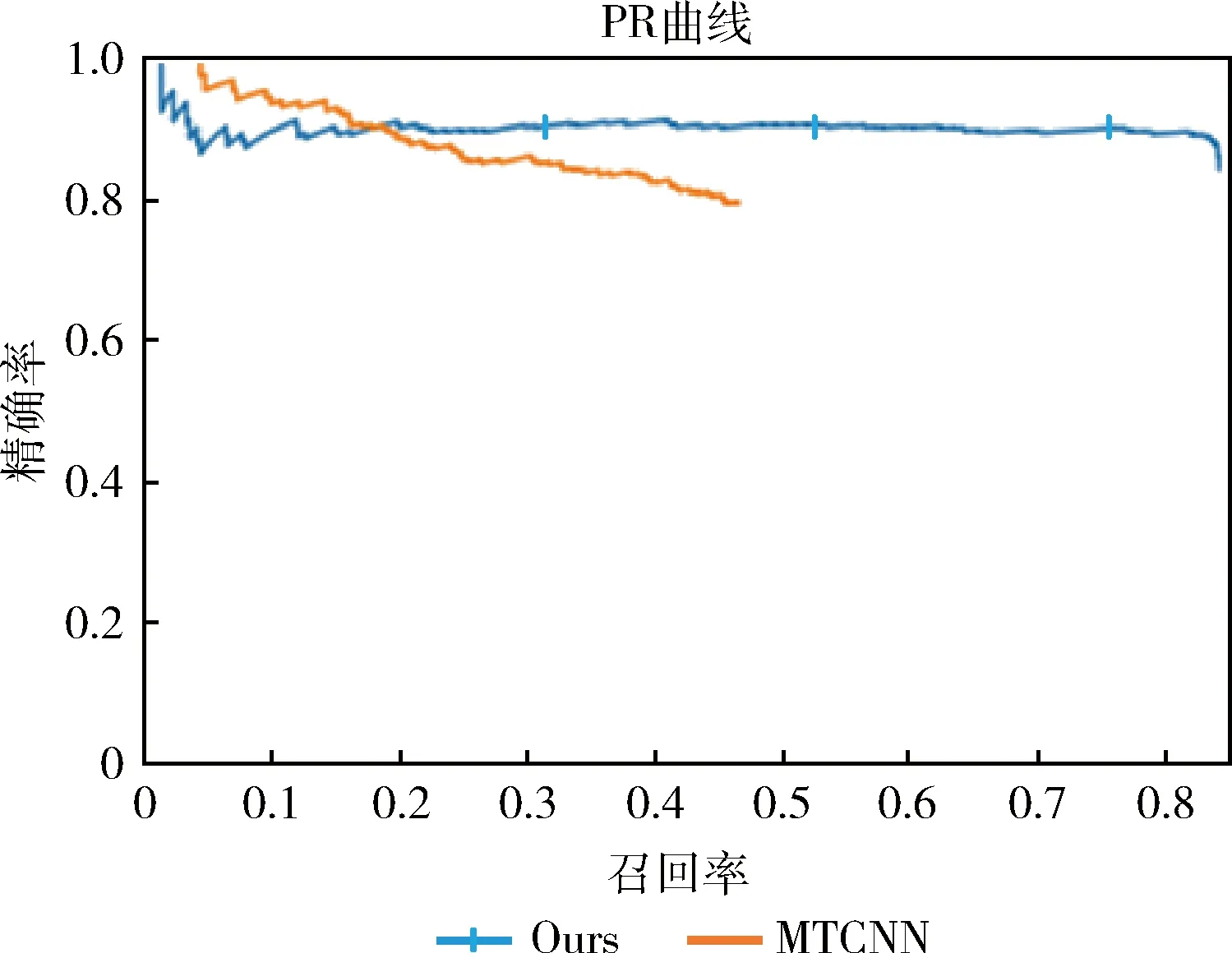
图8 旋转人脸测试PR曲线
3.5 运行效率
本文改进的级联卷积神经网络取得了较快的运行速度,本文模型尺寸较小,通过降低网络输入尺寸达到更高的速度,计算本文的方法和MTCNN[8]在所有FDDB数据集图片的运行平均速度,共2845张图片,使用MATLAB平台,GPU加速,见表1,实验结果表明只增加人脸候选框旋转变换和一个小的分类网络,没有增加过多的时间花费。

表1 速度对比
4 结束语
本文改进了一种RIP人脸检测和关键点定位方法,实验结果表明,本文的方法可以很好检测RIP人脸,本文人脸关键点定位主要为了获得更好的人脸检测效果,同时进行人脸关键点定位和人脸框回归任务可以提高人脸框回归精度。本文主要改进了一个级联网络,由4个网络组成,将平面内旋转人脸检测看作一个多分类问题,很好解决了RIP人脸检测。未来将研究平面外旋转(rotation off plane,ROP)[14]人脸检测模型,与本文方法进行融合,搭建一个完整的多姿态人脸检测系统。
