基于模型剪枝和半精度加速改进YOLOv3-tiny算法的实时司机违章行为检测①
2020-04-24姚巍巍
姚巍巍,张 洁
(西南交通大学 机械工程学院,成都 610031)
随着经济高速全面发展,我国对交通运输的需求越来越大,轨道交通由于其便捷和运量大的特性,在我国交通运输中的地位愈为重要.自2011年“四横四纵”高速铁路干线陆续建成通车以来,我国铁路运输的速度和运输总量实现了质的突破.铁路运输生产力的高速发展,对铁路行车的安全保障提出了更高的要求.确保机车的平稳运行已成为铁路运输部门的重中之重,提高铁路机务部门对机车运行安全的监控水平也成为当务之急.
铁路安全是一个复杂的系统工程,由铁路运输生产人员、铁路设备和铁路环境这3 部分所组成.随着科技的发展,车辆设备和铁路环境都有了较大的发展进步,铁路运输生产人员逐渐成为提高铁路行车安全的重要因素.因此对系统中的人加强监管就显得极为重要.
司机行为识别是目标检测的一个重要的应用场景.在行车途中,司机的驾驶行为是否符合安全规范直接关系到全车人的人身安全,所以对司机进行视频监控是一项重要的安防措施.现有的行为分析以人工挑选分析LKJ 中保存的视频数据为主,抽样不均匀、分析质量不高等问题突出,且只用于司机的绩效评定.实现实时自动分析以及预判的安全驾驶监督系统已经成为铁路行业的迫切需求.
安全驾驶监督系统离不开目标检测技术的发展.自2012年深度学习问世以来,其在图像识别中表现出了极佳的效果,并逐渐取代了传统特征机器学习的地位.在目标检测领域,一批高精度的算法不断刷新了识别精度的上线,并逐渐为工业界所使用.然而,当前国内外大多数智能司机行为识别集中于汽车行业,由于汽车内部狭小,驾驶员人脸和手部等有明确的特征,可以达到实时行为识别的目标[1-4].而对于机车来说,现有的系统一般搭载于昂贵的远程大型服务器上,只能在列车运行结束后收集运行保存的监控视频检测,无法实现实时和随车检测,只能进行司机非安全行为发生后的追查和定责.
因此,采用一种低成本,可随车一起运行的嵌入式设备,在其上部署可以实时运行的监控系统,以便实时传回违章信息便成为一项极有意义的工作.为解决实时、高精度检测司机安全驾驶监督的问题,本文选择玩手机这种较为难以肉眼识别的行为为例,对目标检测中检测速度较快的YOLOv3-tiny[5,6]算法进行了加速,最终将其成功的部署在了计算能力较低的嵌入式设备上部署,实现了较高精度下实时运行的目的.
1 实验数据
1.1 实验数据采集
为能够确保数据的多样性,本文采集多个铁路局机务段货车及客车的驾驶室原始视频数据,标记其中出现手机的图片共5491 张.标注,从中随机选择4919张图片(含5890 个手机对象)作为训练集,剩余的572张图片(含892 个手机对象)作为验证集,如表1 所示.

表1 司机驾驶室图片数据集
1.2 数据增强与标注
为了对抗过拟合、提高样本多样性和图片质量,在数据集较少的情况下对数据进行增强,采用双边滤波、随机水平镜像翻转、随机亮度改变和0°~10°随机角度旋转对数据集进行扩增,采用LabelImg 进行人工画框标注,只标注被遮挡面积比小于0.5 的手机图片以确保精确性,如图1 所示.

图1 增强和标注数据集
2 加速目标检测网络
2.1 YOLO算法原理
为实现在线实时高精度检测,本文选取精度较高同时推理速度较快的YOLOv3 作为基础网络.YOLOv3是一种one-stage(单阶段)的目标检测深度学习算法,其集精确的和推理的快速性于一身,自其提出至今,在工业界已有了广泛的应用[7-10].YOLOv3 在Coco 和Pascal-voc 等开源数据集上均有不俗的表现,其速度和精准度在相同输入大小的情况下均优于SSD[11]、faster-RCNN[12]等主流算法,尤其是YOLOv3-tiny 网络以其非常快的检测速度、较少的参数总量在嵌入式领域和边缘计算受到亲睐.YOLOv3 主要包含以下3 种网络,如表2 所示.

表2 YOLO 网络对比
表2 中精度一栏是在Coco 测试数据集上得到的精度,检测速度一栏是在嵌入式设备jetson Nano 中测试得到.可见虽然YOLOv3 和YOLOv3-spp 网络的精度较高,但由于其复杂的网络在计算量受限的嵌入式设备很难达成实时运行的目标.决定网络运行消耗的时间由模型在每一层计算所耗时间和前后网络层参数传递所耗时间决定,YOLOv3 和YOLOv3-spp 较深的网络层数使得运行需要在完成上一层网络推理之后才能传入到下一层网络进行推理,对于嵌入式这种并行处理能力差的设备来说,如非直接缩减网络的层数,则仅对每层的参数进行半精度优化和剪枝也无法缩减网络在前后传递中浪费的时间.而YOLOv3-tiny 的网络层数较少,主要运行时间消耗在网络每一层计算中,这就为优化提够了条件.尽管精度仅为YOLOv3 的一半,但由于文中针对的是单一司机违章行为目标的目标检测而非coco 数据集中80 个类别的目标检测任务,YOLOv3-tiny 针对此类任务仍有较好的性能和向下优化的空间,如下文中的实验所证.此外,YOLOv3-tiny在占用硬盘空间和运行内存均处于优势.因此,我们选用YOLOv3-tiny算法作为实现实时违章检测的主干网络.
YOLOv3-tiny 网络结构如图2 所示.与双阶段目标检测算法,如faster-RCNN 等网络不同的是,在输入图片经过主体网络推理后,YOLOv3 网络直接通过3 个不同尺度(13×13,26×26,52×52)的输出通道直接得到包含目标框坐标、目标置信度和目标框内物体分类在内的特征图,最后经过非极大值抑制算法(nms)去掉重复目标后得到最终输出结果.而YOLOv3-tiny 为了节省计算量,只在两个尺度上输出特征图,分别为[B,3×(4+1+C),13,13]和[B,3×(4+1+C),26,26],其中B 为每次载入图片的数量,3×(4+1+C)为输出特征图的通道数,C 为每一类的概率,3×(4+1+C)代表特征图上每个1×1 的点对三个anchor(锚定框)进行目标框的回归,以此增强对不同大小物体的识别,如图3 所示.
2.2 模型剪枝
深度学习通过众多的参数计算推理得到预测结果,其中有相当多的参数都是冗余且对预测结果无影响的.当模型训练时,原始网络需要一个足够大的参数空间以充分的寻找最优解.但当模型训练完之后,我们只需要保留最优的参数也一样可以达到和原参数空间一样的效果.我们可以把剪枝视为在原有模型构成的参数空间里中搜寻了一条最有价值的计算路径[13],这样模型的精度不会降低,而使模型运行的更有效率,这就是进行模型剪枝的意义.本文采用模型剪枝的方法对训练后模型进行保持原精度情况下计算量和参数总量的缩减.模型剪枝可以根据细粒度和粗粒度分为权重剪枝和通道剪枝两类,通道剪枝方法由于其独有的简单、可行性、总计算量较小和不需要特殊的硬件库的优势,在近几年得到了相当迅速的发展,并已实际应用于一些工程中[14-16].通道剪枝本质上从通道这一层面上对卷积层中的卷积核的重要性进行区分,去除对网络输出结果影响小的卷积核,以此实现计算总量和模型体积的缩小.

图2 YOLOv3-tiny 网络
我们采用了对Batch Normalization 层(批标准化层,下称为BN 层)进行L1 惩罚的方式进行通道剪枝.在神经网络的计算中,BN 层实际上进行了两步运算,如式(1)所示:(1)对输入特征图所有参数规整到均值为0,方差为1 的正态分布范围内.(2)让每个规整后所有参数在训练过程中学习到对应的两个调节因子γ 和β,对标准化后的值进行微调,使之更适于梯度下降.

其中,ai代表输入的每个通道的特征图,为Bl×Hl×Wl;u,σi分别是均值和方差;γi和βi是每个通道特征图所对应的两个调节因子.实际上,γ 可以视为BN 层特征图每一通道的权重,如果当前输入的通道Ci对应的权重γi出现γi=0 或γi≈0 的情况,那么就会有γi×τ=0,特征图对应的输出通道即全为常数0,不会再对接下来的运算产生影响.因此,我们可以利用BN 层中的缩放因子γ 衡量特征图每个通道的重要性,当γi=0 或者γi≈0 时,即可剪去γi对应特征图的通道,最终剪去γ=0 对应的上下卷积层的卷积核,以此完成减少计算量和缩小模型体积的任务,如图4 所示.

图3 YOLO 检测过程图

图4 BN 层剪枝示意图
然而,一般训练之后神经网络中的γ 值通常呈正态分布,并不会有很多参数等于或者靠近0.因此,我们需要在训练网络的同时减小γ,这被称之为稀疏化训练.通常使用L1 次梯度法稀疏每个BN 层的γ 值,如式(2)所示.

其中,u 代表损失函数的学习率;u ∇l代表训练中原始损失函数的梯度,它是从损失的反向传播中得出的;η 是超参数,决定了L1 次梯度法的每次梯度下降大小,根据经验,η 应在1e-4~1e-5 之间取得[15];sgn(γl- u∇l)决定了L1 次梯度法的损失方向.
2.3 TesnorRT 模型简化及半精度加速
TensoRT 是NVIDIA 为深度学习的高速推理需求所推出的一个高性能深度学习推理平台.它包括深度学习推理优化器和运行器,可为深度学习推理应用提供INT8 和FP16(半精度)优化,例如视频、语音识别、推荐系统和自然语言处理等.在深度学习的部署中,降低精度推断可显着减少应用程序延迟,这是许多实时服务,自动和嵌入式应用程序的要求.
在搭建TensorRT 加速引擎时,需要将原模型转化为TensorRT 可以读取的形式,如caffe、onnx 的模型结构.TensorRT 自带的接口NvcaffeParser 提供了Caffe 结构模型中卷积层、激活层和池化层等常见层的接口,而YOLOv3-tiny 中的Upsample 层(上采样层)及YOLO 层(检测层)需要自行编写后自定义插入.Upsample层实现了数据图H,W 方向上的调整,放大输入的特征图以适应联结、矩阵加法等操作,常见的Upsample 方法有线性插值、最近邻值等.YOLO 层实现了从特征图中挑选置信度(confidence)大于预设值的目标输出的目的,并将挑选出的特征与锚定框大小计算回归出目标框真实位置和长宽值.本文将最近邻值的Upsample层和YOLO 层添加到了TensorRT 加速引擎中.
TensorRT 通过实现模型简化和半精度对模型进行加速,其中模型简化通过整合卷积层、激活层和BN 层为CBR 层实现;半精度加速通过在平台支持的情况下,将数据精度需求从32 位float (浮点数)降低为16 位float,可极大的提升计算效率.
2.4 总体流程
我们提出的算法总体流程如下:(1)首先进行稀疏训练,在训练模型的同时使BN 层γ 因子尽可能地收缩;(2)当稀疏训练完成时,执行修剪以移除冗余参数;(3)微调修剪后的模型以获得最终模型;(4)搭建TensorRT 推理加速引擎,编写自定义层;(5)将模型读入TensorRT 加速引擎中,部署在嵌入式设备上.训练流程图如图5 所示.
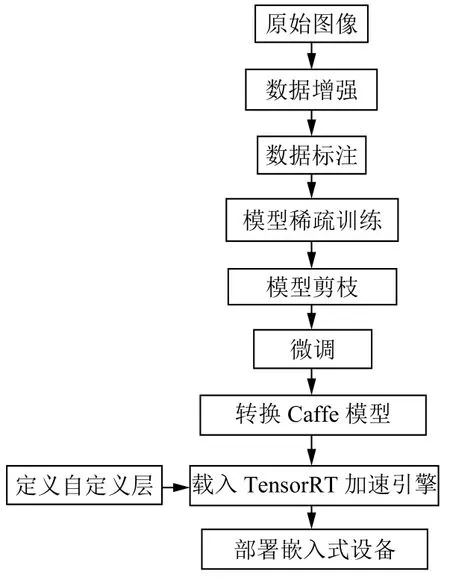
图5 训练部署流程
3 实验结果与分析
本文使用了Pytorch 框架完成YOLO算法的搭建,主要训练硬件设备为:①处理器:Intel 9400f;②GPU 显卡:RTX2070 8G.操作系统为Ubuntu16.04,python 环境为python3.6.8.部署嵌入式平台为较为廉价、适于工业部署的NVIDIA Jetson Nano,如图6 所示.Jetson Nano 是NVIDIA 公司2019年新推出的嵌入式高性能开发板,其采用NVIDIA Maxwell™架构,配备128 个CUDA 核心,内存为4 GB,搭载的运行环境为JetPack 4.2.

图6 Jetson Nano
为提高显存利用率,增加batch size(批大小),采用了NVIDIA 的apex 技术进行混合精度训练.选取准确率P (precision)、召回率R (recall)、平均精确率均值mAP (mean Average Precision)、F1 值、检测速度和参数总量作为评价准则.其中,precision 指的是被正确检测出的物体占总被检测出的物体的比例,recall 指被正确检测出的物体占验证集中所有物体的比例.precision和recall 一般情况下是成反比关系,即recall 越大,precision 越小,反之同理.而mAP 为目标检测任务中最重要的指标,决定了检测的效果.mAP 一般通过改变检测时置信度(confidence)阈值得到Precision-recall 曲线,计算Precision-recall 曲线的面积得到mAP 值.为了在计算机中更快速精确的求mAP 的大小,通常使用插值近似的方法,如式(3)所示.
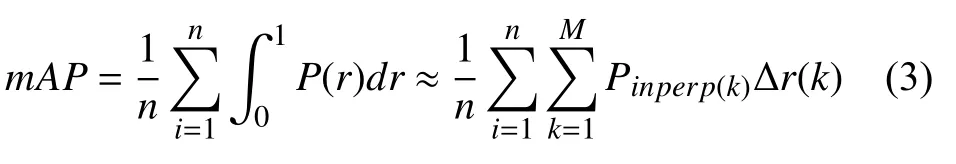
本文同时以正常训练模式和稀疏化训练模式训练了两个YOLOv3-tiny 模型,设置稀疏训练超参数η=1e-4 进行训练.表3 展示了YOLOv3-tiny 网络稀疏化训练后的各项指标,可见稀疏化训练后的各项指标均处于相当优秀的水平,0.965 的mAP 保证了高精度检测的目的,甚至要高于正常训练,这是因为稀疏化训练也可以视为进行了L1 正则化,降低了模型对训练数据的过拟合.图7 显现了稀疏化训练后γ 系数的稀疏化水平.YOLOv3-tiny 网络共有11 层BN 层,这11 层BN 层共有4512 个γ 系数,40%的γ 参数的绝对值下降到0 值附近,满足进行剪枝的条件.随后进行剪枝并进行微调.

表3 YOLOv3-tiny 训练结果

图7 稀疏化训练后全γ 系数分布图
表4 展示了剪枝后各个卷积层变化情况,剪枝后的模型各卷积层通道大小由之前的2 的n 次方数变为不再有规律可循,这便是非结构剪枝在现有模型中搜寻了一条最为有效的计算路径的结果.
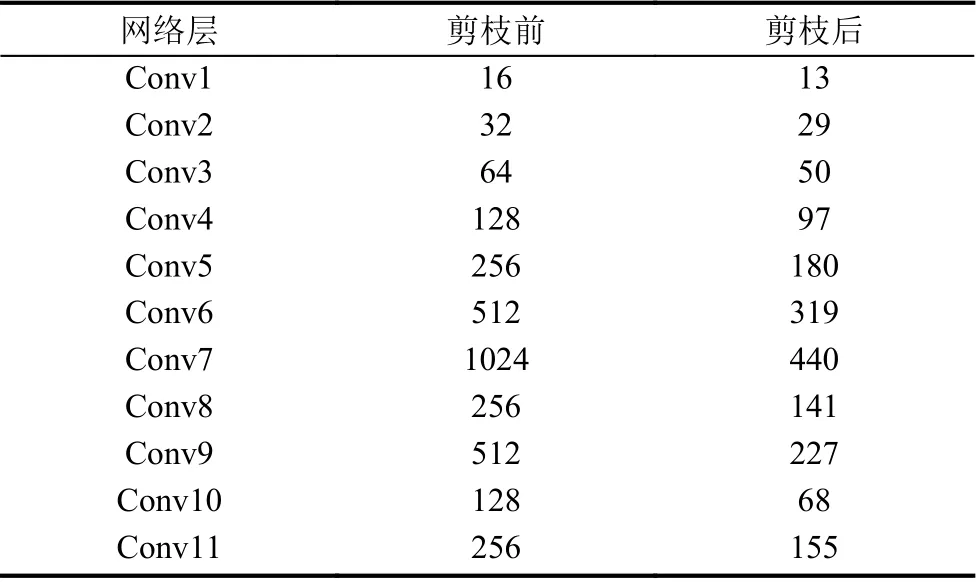
表4 剪枝后的模型各卷积层大小
表5 展示了剪枝后并微调后改进模型(下文称为Prune-YOLOv3-tiny)在Jetson Nano 上的表现.可见在微调后,Prune-YOLOv3-tiny 模型的精度略有上升,而在检测速度相较原模型提高了76.5%,计算总量降低为原模型的43.2%,在参数总量上降低为原模型的31.4%.尽管只有40%的γ 参数被剪去,模型参数总量依然下降很大.由表4 可见,Conv1、Conv2、Conv3 等参数较少的卷积层被剪去的较少,而如Conv6、Conv7、Conv8 等参数较多的卷积层剪去的参数较多,参数最多的Conv7 有高于一半的参数被剪去,这是剪枝后模型参数总量要更少的原因.而对于计算复杂度,参数最多的Conv7 层并非是计算量最大的层,考虑计算量需要综合每层输入输出的特征图大小.对YOLOv3-tiny 模型来说,Conv6 是模型计算量最大的层并没有如Conv7 一样被剪去一半以上,这是计算总量的缩小程度低于参数总量的原因.

表5 原网络与改进网络对比
随后,将原YOLOv3-tiny 模型加载到搭建好的TensorRT 加速引擎中以生成半精度加速的模型.表6展现了YOLOv3-tiny 模型在TensorRT 加速引擎中的效果.相较于原模型,TensorRT 加速的半精度模型的精度没有变化,检测速度提高52.9%,而参数总量没有明显下降.
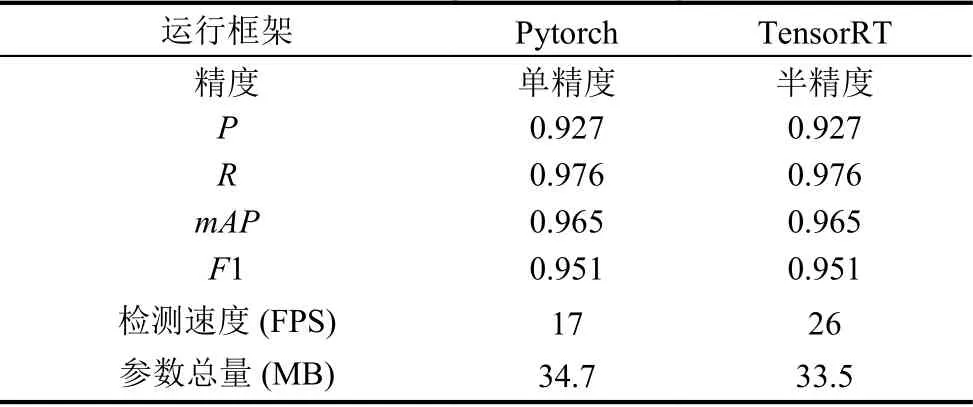
表6 YOLOv3-tiny 在不同推理平台上对比
最后,我们将Prune-YOLOv3-tiny 模型加载到搭建好的TensorRT 加速引擎中完成最终的加速模型(下文称为最终模型),表7 展现了最终模型的效果评估.经过模型剪枝和半精度加速的最终模型相较于原模型精度没有下降,检测速度提高了117.6%,而在参数总量上降低为原模型的39.5%.图8 展示了最终模型的识别效果.

表7 原模型与最终加速模型对比

图8 加速模型检测效果
4 结语
在这项工作中,我们成功的对目标检测中经典的深度学习神经网络YOLOv3-tiny 进行了通道剪枝和半精度加速,在精度不变的情况下减少了改进后神经网络的计算总量和参数总数.我们在计算能力较低的嵌入式设备上成功部署了剪枝后的模型.所提出的模型在嵌入式设备可以达到37 帧每秒的检测速度,与现有模型相比,我们的模型除了需要在稀疏化训练中增加一个η 超参数外,在速度和体积上均占有优势,而精确率、召回率和平均精确率均值不变,实现了高精度下实时检测的目的.
