基于速度的轨迹停留点识别算法①
2020-04-24蔡小路
蔡小路,曹 阳,董 蒲
(华南师范大学 计算机学院,广州 510631)
随着带有定位模块的智能终端使用量的增加,移动对象位置数据的获取变得越来越普遍.而轨迹数据能够反映移动对象的部分隐藏信息[1],通过识别轨迹中的隐藏信息加入语义信息,可以得到体积较小、质量较高、便于理解的带有语义信息的轨迹.将原始轨迹转换为语义轨迹为目的地位置预测[2]、城市道路的规划[3]、充电桩分布的规划[4]、动物习性的调查[5]等提供了解决方法.因此,对轨迹数据进行语义转换的需求将会变得越来越大.Alvares,Bogorny 等人[6]提出了一种将原始轨迹转换为语义轨迹的模型,模型得到了广泛的应用[7-9].模型先将物体的移动路径切分为“停留点(stop)”和“移动点(move)”两部分,再将停留点与地理信息库相匹配为停留点附上地理背景信息,然后将这些带有地理信息的停留点按照时间先后顺序排列后即为语义轨迹.因此,原始轨迹转换为语义轨迹的关键是如何准确识别出原始轨迹中的停留点或停留域.
目前关于轨迹停留点识别的算法大致可以两大类:静态方法和动态方法[10].Alvares,Bogorny 等人[11]提出挖掘原始的轨迹数据中的语义信息是理解这些数据的前提,认为停靠点是轨迹集合中具有重要意义的子序列集合,将轨迹与预先定义好的重要位置的交集视为停靠点.静态算法的主要缺点是用户需要指定有意义的位置.因此,如果事先没有定义一些有意义的特殊位置,静态方法就无法识别出停留点信息[12].而动态停留点识别方法则不需要事先知道停留点或停留域位置,也可以发现停留点位置.Ashbrook,Starner 等人[13]对传统的K-Means算法进行改进来提取出轨迹中有意义的点.方法要求首先选取一个初始中心点并定义覆盖半径,将中心点覆盖半径内的点进行标记并计算这些点的均值点.将均值点作为新的中心重复上述操作,直到中心点不再变化,将上述标记的点视为一个停留域.然后从未被标记的点中选择一个初始中心点进行新的停留域的筛选,直到所有点都被标记.K-Means算法的K 值和初始中心点的选取是重要问题,选取不当会导致最终的结果产生很大的误差.Zhou,Frankowski 等人[14]提出了名为DJ-Cluster 的基于密度和连接的算法,算法核心思想是:计算每一个点的一定距离(EPS)内的邻域点.当点的数量小于MinPts 时将其标记为噪声.邻域点数目大于MinPts 时,邻域不属于任何一个已知停留点类时则将其标记为一个新的停留点类,反之合并到所属类中.基于密度聚类的停留点识别算法可以克服K-Means算法的缺陷,但是仅考虑了轨迹的空间特征而忽略了时序性.Hwang,Evans[15]提出了一种“自上而下”的光栅采样方法,该方法采用预先定义的GPS 采集器进行数据收集,将具有显著区分值的光栅单元作为停留点进行聚类.Palma,Bogorny[16]提出了CB-SMoT(基于聚类的停止和轨迹移动)算法来提取已知和未知的停留点.CB-SMoT算法是一种考虑了时间和空间特征的基于密度的聚类算法,通过选取速度比速度阈值慢的点来生成停留点.Zhao,Xu[17]指出[16]中估计参数Eps 适当值的分位数函数并不能稳定地确定参数的适当阈值.因此提出了一种改进的CB-SMoT算法,提出了一种计算EPS 参数的方法,但由于需要用户区分低速部分和高速部分,计算起来仍然困难.Yan,Parent[18]在CB-SMoT 的基础上加入最短停留时间参数来过滤掉“伪停留点”(例如,短期低速拥堵不应是一个停留点).Lv,Chen[19]提出了一种层次聚类算法,首先从GPS 轨迹中提取访问点,然后对这些访问点进行聚类形成停留域.Chen,Ji[20]针对GPS 点的时间序列特性,提出了一种改进的基于密度的聚类算法T-DBSCAN,并定义了两个新的前提条件(单停留域内的状态连续性和停留点间的时间间断性)作为调整聚类中轨迹点选择的理论基础.Yang,Li[21]将Eps 坐标系划分为网格单元.通过遍历数据集,每个数据点根据其经度、纬度和时间分量被分配到相应的网格单元.再计算每个网格单元内的数据点数量,将网格点数大于MinPts 的单元标记为核心网格单元.从核心网格单元出发,采用广度优先遍历策略搜索其相邻的核心网格,并将最大的相邻核心网格单元集标记为停留点簇.
然而上述方法无法有效地分辨出移动目标是从建筑物穿过还是在建筑内有过停留这一问题,也不能合理地设置时间阈值来聚类缺失记录点.当移动目标于某一地理位置产生活动时,速度会低于整条轨迹的平均速度.针对这一物理特性和前文论述的研究缺陷,本文提出了一种改进的停留点识别框架:先确定轨迹中的缺失子轨迹,再按缺失轨迹的平均速度对缺失轨迹进行插值,然后采用基于速度的时空聚类方法来识别轨迹中的停留点.
1 基于速度特征的轨迹停留点识别算法
1.1 轨迹预处理
由于移动目标物体会在不同的场景中移动,场景的不同导致采集到的轨迹数据特点也会不同.当行人进入建筑物内时,因为信号受到遮挡,无法收集到理想的数据.用户轨迹进入建筑物可以分为两种情况:在建筑物内有停留和穿过建筑物.停留点识别算法应正确地识别出前者而过滤掉后者.当距离一定时,停留时间越长,该轨迹段内的按时记录的点的密度越大;而对于穿过建筑物情景而言,用户的移动速度不存在剧烈变化.
因此针对前文描述的数据缺失或偏差等情况,采用插值法对缺失轨迹的记录点进行填充:将缺失轨迹前后两端点的时间差作为缺失时间,两点间的距离作为缺失轨迹的缺失距离.因为单体建筑范围一般小于200×200 m2,且为了防止前条轨迹结束点与后一轨迹的起始点小于设定的缺失距离而导致两条轨迹因为插值导致合并造成最终的提取结果产生偏差,所以对缺失轨迹通过缺失时间的大小来进行区别.当缺失轨迹的缺失距离小于200 m,缺失时间小于2 小时,缺失轨迹的前后两条轨迹视为同一条轨迹.将缺失时间与轨迹记录点时间间隔的比值视为缺失点的数目,将缺失距离按缺失数目等距插值填充,然后采用卡尔曼滤波器对填充后的整条轨迹进行平滑处理得到最终的实验数据集.
1.2 停靠点识别算法
本文在ST-DBSCAN算法的基础上提出了基于轨迹速度的密度聚类算法(V-DBSCAN,Velocity-Based DBSCAN).对于经过预处理后的轨迹点,采用以下步骤进行处理:1)使用时间阈值和速度阈值对实际轨迹点进行筛选,生成候选停留点邻域.2)沿候选停留点邻域的时间轴将其相邻点数大于密度阈值的点进行聚类,得到最终停留点.具体算法见算法1.

?
如算法1 所示,算法首先根据轨迹点的加速度、相邻轨迹速度范围和速度持续时间等特征将轨迹切分成速度相近的子轨迹段,再依次对子轨迹进行停留点识别.识别算法首先计算子轨迹点集合Traj 的半径阈值Eps(算法详情见算法2),再计算Traj 的整体平均速度(Mspeed).Traj 中所有点的初始状态为未标记状态,从起始记录点开始,按记录点时间顺序依次对每一个点进行筛选过滤.如果当前点(pi)处于未标记状态,则调用retrieve_neighbor 函数,retrieve_neighbors 函数根据Eps、T 和Mspeed 三个条件阈值,从Traj 中筛选出pi的所有满足条件的相邻点.如算法3 所示,函数依次根据时间、距离和速度三个条件筛选出pi半径阈值(Eps)范围内速度小于Mspeed*e 且与pi的时间间隔小于时间阈值(T)的轨迹点.结果集则是pi的候选停留点邻域.若pi的候选停留点邻域中轨迹点的数量小于minPs,将pi标记为噪点,反之则将pi与其邻域用类ID 进行标记.然后再按时间顺序迭代地对pi邻域中未被标记的点进行筛选,直到Traj 中所有点都被标记.
计算Traj 空间半径阈值Eps的函数spatial_threshold 如算法2 所示.本方法是受文献[22]提出的R N N-D B S C A N算法启发而得出的,在R N NDBSCAN算法中通过计算每个目标的k 最近邻近点,建立所有目标的k 邻近点索引表来进行密度聚类.在spatial_ threshold 中,先求出每一个点与其他任一点的地球球面距离,筛选距离最短的k 个值放入all_kth_distances 中,再求得all_kth_distances 的平均值,返回均值.

?
从原始轨迹点中筛选候选停留点集的过程为:对连续的两个时刻内的运动状态进行判断,当pk与pi的时间差小于时间阈值T,则对两点间的距离进行判断,若距离小于半径阈值,且pk的速度小于速度阈值Mspeed*e (0<e<1),则将pk添加到pi的邻域点集中,并计算下一点是否为pi的邻域点,直到所有点筛选完毕.具体方法如算法3 所示.

?
2 实验分析
为了评估 V-DBSCAN算法的有效性,本章节将其与ST-DBSCAN算法[23]在提取的停留点的数目和准确度方面进行实验比较.实验数据集共两组:第一组数据集为GeoLife 数据集中user ID=20 的用户的所有轨迹数据,采样点间隔为5 s,共177 683 个记录点,用于验证算法的提取能力,下文称数据一;第二组是志愿者收集的带有停留点标记的轨迹数据,采样时间间隔为2 s,共14 479 个记录点,用于验证提取到的停留点的准确性,下文称数据二;两组数据集的属性都相同,包有时间戳、经纬度、海拔基本信息.轨迹数据基本信息如表1 所示.

表1 轨迹数据点基本信息表
2.1 参数设定
为了防止不恰当的参数设定造成最终结果的偏差,本节探索参数对结果的影响,并确定最终的对比实验的参数.此处的实验数据集为另一志愿者室外步行状态下的轨迹点,时间间隔(t)为2 s,共12 797 个轨迹记录点.整条轨迹含26 个人工记录的停留点.
如表2 所示,经过多轮实验探索得出:时间阈值设为30 倍的记录点时间间隔(例如间隔2 s 记录一个点的情况下,时间阈值设为60 s),密度阈值设为1.5 倍的时间阈值大小,即45 倍的记录点时间间隔时,提取出的停留点数最接近实际情况.

表2 参数对结果的影响
2.2 实验结果
实验一测试两种算法在相同时间、半径阈值,各个密度阈值下,对轨迹中停留点的提取能力,采用数据一作为实验数据来进行对比验证.时间阈值设为30 倍的记录时间间隔,密度阈值设为记录时间间隔的45 倍,密度阈值下为0.75 倍轨迹平均速度.从图1 中可以看出相同的实验参数下,V-DBSCAN算法提取的停留点数都要大于ST-DBSCAN算法.这是因为目标用户在实际移动中往往存在两个或多个停留点相隔较近的情况,此种情景下停留点间的移动点的数量会非常少.当ST-DBSCAN算法的半径阈值设置过大或密度阈值设置过小时,就会将停留点间的移动点也划分到停留点中,导致相近的两个或多个停留点被识别为一个停留点.针对停留点间的移动点的瞬时速度大于两边停留点的瞬时速度这一物理特征,V-DBSCAN算法对轨迹点速度进行筛选,只有当轨迹点的速度小于设置的速度阈值时才将该点进行后续的筛选,因此可以对地理距离相隔较近的多个停留点进行很好的划分.因此在识别停留点的提取能力上V-DBSCAN算法要强于ST-DBSCAN算法.

图1 停留点提取数量对比
实验二测试两种算法对轨迹中停留点的提取能力,采用数据二作为实验数据来进行对比验证(T=60 s,MinPts=90,e=0.75).两者的对比实验结果如图2 所示,其中黑色大圆点为V-DBSCAN算法的结果,白色小圆点为ST-DBSCAN算法的结果.
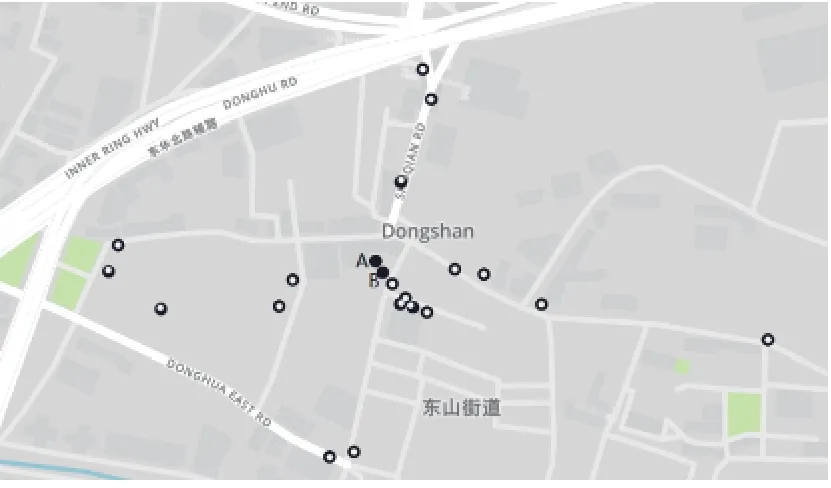
图2 停留点准确性对比
从图2 中可以看出,当仅考虑对停靠点的提取能力时,V-DBSCAN 相对于ST-DBSCAN 提取出更多的停靠点,例如图中A、B 两点.其中A、B 两点的原始轨迹数据由于建筑物的遮挡而缺失,所以未改进的STDBSCAN算法无法识别出这两停留点.因为对于STDBSCAN算法的时间阈值T 范围内可能存在多个停留点,这是ST-DBSCAN算法参数不能基于轨迹特征来设定导致的缺陷.为此本文中提出了基于速度的密度聚类方法,在ST-DBSCAN算法的基础上考虑轨迹点速度来提取停留点,极大改善了ST-DBSCAN算法对停留点提取不完全的问题.
3 总结
本文针对空间轨迹停留点提取过程中的轨迹点缺失和半径阈值难以确定等问题,提出了基于轨迹点速度的密度聚类算法.由于传统的基于密度的聚类方法将轨迹的时间和空间两个属性分开来进行考虑,忽略了两者之间的联系.V-DBSCAN 的设计是通过对一定范围内的缺失轨迹点进行插值填充再根据速度和时间来筛选出轨迹中的停留点.试验结果表明,相对于STDBSCAN,V-DBSCAN 一方面被证明具有更好的轨迹聚类能力.另一方面,V-DBSCAN 可以自动计算出轨迹的Eps半径距离,减少了人为设定参数的不确定性.但是,时间阈值和密度阈值仍然要人为设定.在后续的研究中会考虑本算法对多用户的多条轨迹提取停靠点的处理能力,并根据不同用户的停靠点计算多个用户间的用户相似性.
