基于深度学习的客流量统计方法①
2020-04-24韩晓微王雨薇谢英红齐晓轩
韩晓微,王雨薇,谢英红,齐晓轩
(沈阳大学 信息工程学院,沈阳 110044)
当前,智能视频监控是计算机视觉的重要应用领域,其不同于原有的视频监控方法,智能视频监控通过计算机视觉方法对各种图像序列进行处理,从而自动的实现对行人、交通等情况的有效监控[1,2],而人流统计则是近年来此领域的关键技术之一[3].人流统计主要通过目标检测、跟踪等多方法结合实现,此技术在当前已有了一定的研究成果,但由于目标的快速移动与遮挡等情况的存在,使得客流统计仍存在着严峻的挑战.
对于目标检测与跟踪方法,Felzenszwalb 等人[4]提出了多类目标检测方法,其先通过DPM 的人工特征提取,再进行Latent SVM 分类,此方法成为在深度卷积神经网络出现之前最有效的识别算法.Girshick 等人[5]首次首次在目标检测中使用深度学习理论,其通过卷积神经网络实现目标候选框特征的提取,之后利用SVM 实现分类工作.Ren 等人[6]提出了用于实时目标检测的候选框网络RPN,其可以从任意尺寸的图像中得到多个候选区,能够与卷积神经网络结合实现端到端的训练,此网络与Fast R-CNN[7]结合并共享卷积层特征之后的网络称为Faster R-CNN.Henriques 等人[8]提出了一种核相关滤波器,其通过加入正则项建立模型,利用循环矩阵进行稠密采样,又通过多通道特征的提取,实现了较为鲁棒的跟踪.Mueller 等人[9]提出了上下文感知滤波跟踪算法,实现了背景干扰下的有效跟踪.
对于人流统计方法,Raheja 等人[10]采用高斯混合模型对背景像素进行描述,提出了一种多模态背景的双向人员计数算法,实现了在人口密度较低情况下的准确计数.Wateosot 等人[11]通过对象分割对人的头部进行识别,然后使用粒子滤波方法跟踪头部的深度颜色特征,进而实现对于人头的统计工作.Songchenchen等人[12]提出了一种基于特征融合的人群计数方法,其通过图像特征提取和纹理特征分析,利用多源数据对人群数量进行估计,实现了高密度、静态图像中的人数统计.Chauhan 等人[13]提出了一种基于深度学习框架的数学计数回归方法,该方法首先估计出每个区域内的人数,之后通过各个区域的人群数量估计之和求得整个图像中总人数.李笑月[14]通过SVM 对样本进行训练得到行人分类器,利用Mean-Shift算法进行目标跟踪,判断目标是否离开场景来实现计数.这些算法多是使用垂直于地面的摄像头进行监控,通过这种方式能够有效的应对目标遮挡情况,但当监控视频角度发生偏转时,算法的准确性会受到影响.
本文以餐饮业为背景,为实现对进店客流量的统计,设计基于深度学习的餐饮业客流量统计方法.此方法首先通过多数据集对YOLOv3-tiny 方法进行训练,实现对于目标的准确检测,然后设计多通道特征融合的核相关滤波目标跟踪算法,实现对于快速移动目标的稳定跟踪,最后设计基于双标准框的目标进门行为判断方法,实现了对于客流量的有效统计.
1 本文算法设计
1.1 YOLOv3 目标检测算法
YOLOv3[15]在原始两个版本[16,17]的基础上进行了多尺度预测与网络结构等方面的改进,使其检测的速度更快,准确率更高.YOLO 各个版本的性能对比见表1所示.

表1 YOLO 各版本性能对比
1.1.1 YOLOv3算法原理
YOLOv3 的输入图片尺寸为416×416 像素,通道数为3,其采用了Darknet-53 的网络结构,主要实现YOLOv3 的特征提取工作,其共包含53 个卷积层,卷积层中使用的卷积为3×3 和6×6,具体结构[18]见图1所示.
Darknet-53 之后通过类似于FPN 网络[19]实现特征融合,网络总共划分3 个尺度,分别为13×13、26×26、52×52,其中每个尺度先构成各自尺寸的特征图,再使用卷积核实现各特征图间的特征融合.此网络通过在多个尺度的融合特征图上进行独立的检测工作,最终实现对于小目标检测性能的有效提升.
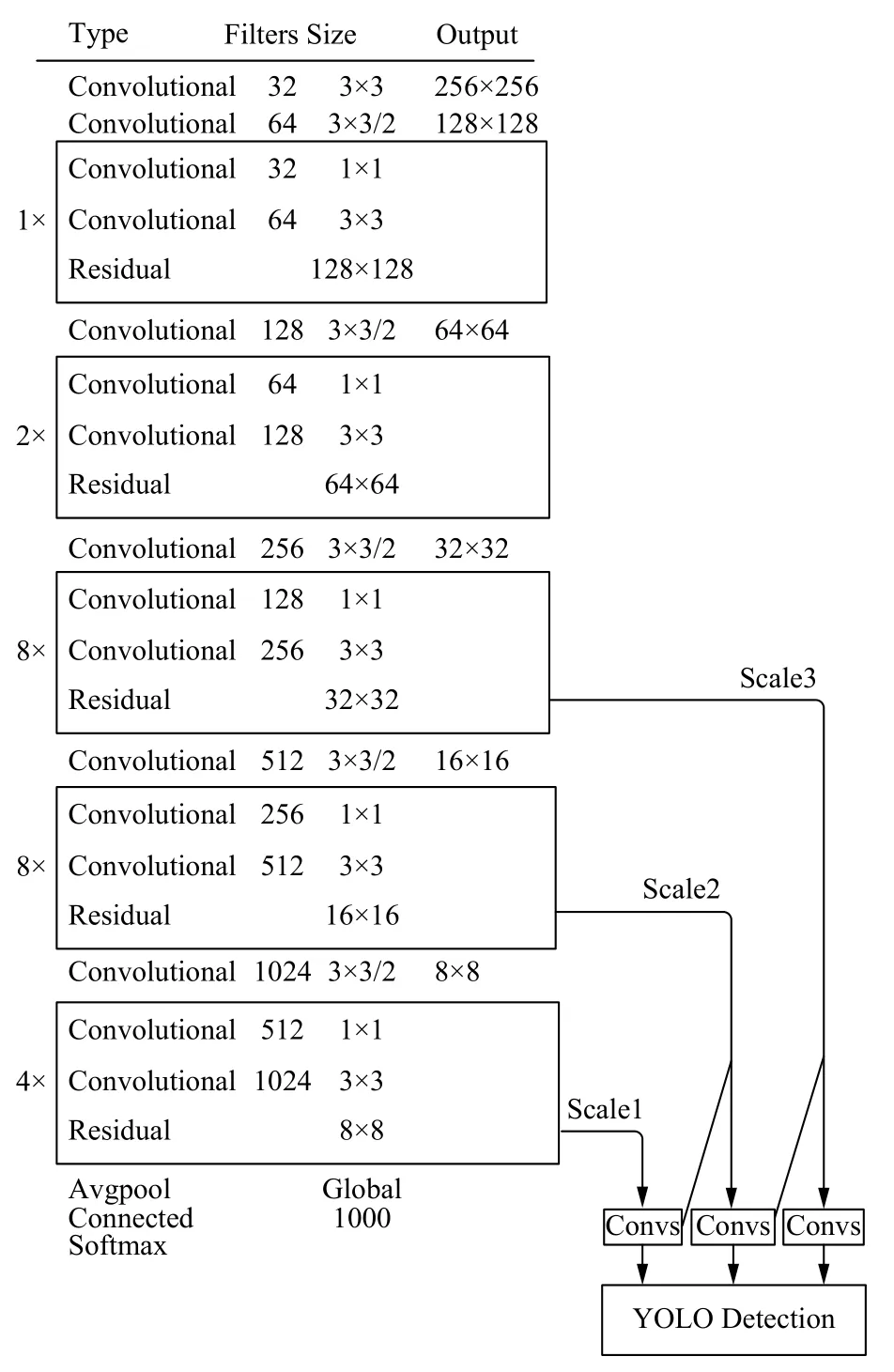
图1 YOLOv3 网络结构
YOLO 在训练时的损失函数计算公式为:
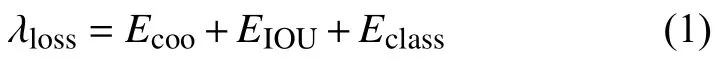
其中,Ecoo为检测结果与标定数据间的坐标误差,EIOU表示两者间的IOU 误差,Eclass则表示分类误差.
Ecoo的计算公式为:
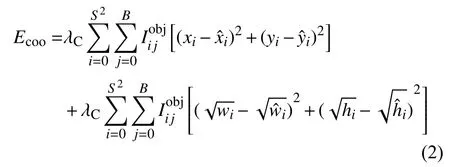
其中,λc为权重误差,表示在第i 个网格的第j 个预测框负责目标,S 表示特征图的网格尺寸,B 为每个网格预测框的数量,wi和hi分别表示预测框的宽和高,和代表真实的宽高,( xi,yi)代表预测框的中心坐标,则代表真实坐标.
EIOU的计算公式为:
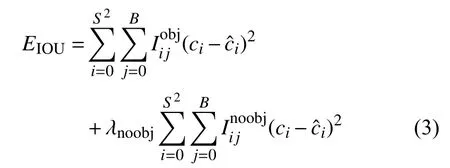
其中,λnoobj表 示分类误差的权重,表示第i 个网格的第j 个预测框不负责目标,ci表示第i 个网格预测的置信度值,表示其真实置信度值.
Eclass的计算公式为:
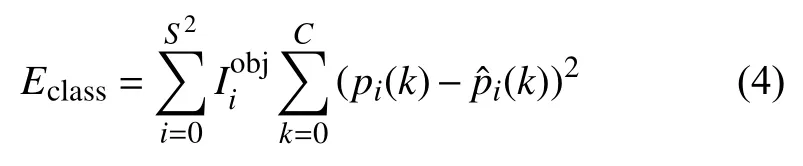
YOLOv3-tiny 的网络结构在YOLOv3 的基础上进行了修改,减少了卷积层、取消了残差层,并且减少了输出尺度的数量.此模型的整体性能虽不如YOLOv3,但由于YOLOv3-tiny 的模型复杂度得到了减小,使得其运算速度实现了进一步的提升,而本文需要在CPU环境下实现,YOLOv3-tiny 能够保证整体算法的实时性,因此本文选取了YOLOv3 的轻量级版本YOLOv3-tiny 作为最终的目标检测模型.
1.1.2 训练过程
(1)样本准备
使用LableImg 对图片序列中的人群进行标注,实验共涉及45 家门店不同时间段的5000 张图片,具有普适性,通过这些标注好数据集对模型进行训练.本文算法针对目标为行人,因此在模型训练时取消了对其它类别事物的识别,只保留了person 标签.
(2)参数设置
本文对模型的训练阶段,动量参数设置为0.9,其影响梯度下降到最优值时的速度,训练使用小批量随机梯度下降进行优化.初始学习率η =0.001,衰减系数设置为0.005,此系数的设置防止过拟合现象出现.前1000 次训练的学习率为ηlr=η×(Nbatch/1000)2,通过学习率的设置保持网络的稳定,Nbatch为模型运行的批次数,之后的学习率为10-3.
1.1.3 检测结果
本文将训练后的模型分别对10 家不同门店的不同时间进行测试,图2 为其中3 个门店的识别效果,其中门店A 有强光影响,门店B 有较多汽车遮挡,门店C 的视野不清晰.通过图2 可看出,此算法对3 个门店均能实现准确的检测,有较强的鲁棒性.

图2 各门店识别结果
1.2 多通道特征融合目标跟踪算法设计
1.2.1 核相关滤波算法
核相关滤波器利用正则化的最小二乘法,通过求极值的方法实现对滤波器的求解.通过对每张图片中目标及其周围一定范围的图像块进行滤波器的训练,其中目标位置图像块x 的尺寸为M×N,在滤波器训练过程中通过循环矩阵实现密集采样,图像块xi中i ∈{0,···,M-1}×{0,···,N-1}.滤波器通过回归最小化进行求解,具体表示为:
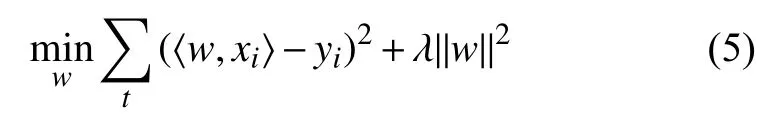
其中,〈 ,〉表示点积,w 为滤波器的参数,y 为期望的目标输出,λ 为正则化参数,能够防止模型过拟合现象,使模型得到更好的泛化能力.
利用核函数 κ (x,y)=〈φ(x),φ(y)〉,将高维非线性变换到低维函数实现加速计算,其中ϕ 表示将特征向量映射到核空间的函数.因此将式(5)的解w 表示成输入的线性组合[20],即为:

其中,α 是w 的对偶空间变量,即为滤波器系数.
根据文献[21]可以得到α 的解,具体求得α 为:

通过循环矩阵性质可知k 仍是循环矩阵,结合循环矩阵的性质求解到傅里叶域中的α 为:

其中,和 表示他们各自的傅里叶变换.为多通道的高斯性核函数,其计算公式为:
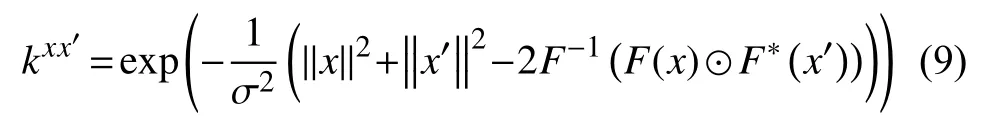
其中,⊙表示各元素的对应相乘,F-1表示傅里叶逆变换,*表示复共轭,σ 为高斯核函数带宽参数.
通过上述训练过程,根据循环矩阵k 构建训练样本和测试样本的核函数,将分类器的求解转化到傅里叶域中,对目标下一帧位置进行求解,其目标响应f(z)为:
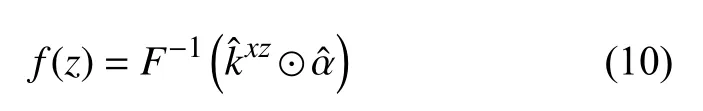
1.2.2 多通道特征融合设计
颜色特征是一种全局特征,其不受目标的旋转、平移等变化的影响.CN 特征[22]基于传统颜色特征的优势,将原有的RGB 的三通道特征进一步映射到11 维,实现了从3 种颜色到11 种颜色的扩展.CN 颜色属性对于一张输入的目标图像I,将a 位置的像素值I(a)映射到CN 空间,进一步得到共11 维的颜色概率特征图[a1,a2,···,a11].HOG 特征描述目标的方向梯度,获取HOG 特征首先需进行灰度处理,然后利用Gamma 校正法对目标进行颜色空间归一化,以此降低光照变化的影响,从而实现降噪效果;之后对每个像素点进行梯度方向和大小的求解,计算此点的梯度幅值和方向;最后进行细胞单元(cell)、块(block)直方图的构建,通过对块的HOG 特征进行整体串联,实现目标框HOG 特征的提取[23].
本文所采用的HOG 特征的每个cell 为4×4 像素,其获取到的特征为31 维,CN 为11 维特征,由于单一的目标特征提取会导致跟踪不够准确的情况,因此本文提出了一种可以将这两种特征进行融合的方法.由于核相关函数只需进行向量间的点乘运算,因此对于两种特征的融合工作就是将这些特征进行维度的串联,所得的最终目标的特征维数为42 维,其融合方式具体表示为:

其中,PC、PH分别表示CN 和HOG 特征.
1.3 进门行为判断方法设计
本文实现的是对进入门店的客流量统计,现有的多数算法是通过垂直于地面的摄像头进行监控,利用分割线对图像进行区域划分,之后通过对目标经过各分割线的过程实现对垂直视野中的人数统计.但本文使用的视频监控方式为水平方向或与地面夹角不超过50 度,现有的策略并不适用于本文所研究的对进入门店的客流统计背景.因此本文对目标进门行为判断方法进行了设计,从而实现对客流量的统计.
首先初始化双标准框与目标感兴趣区域,双标准框是根据不同餐饮门店的方位与角度进行手动标定,其为之后判定目标是否进门提供依据,标定示意图见图3 所示.

图3 双标准框标定示意图
在实际应用场景中,不同摄像头距目标门店的距离各不相同,因此需要对摄像头所拍摄的视频序列进行预处理,确定目标感兴趣区域.当目标进入感兴趣区域时开始对其进行整体的识别跟踪工作.在双标准框确定之后,本文将参数分别设为1.2、1.5、2 作为双标准框外框尺寸同比例扩大的倍数,并且在这些参数下分别对算法实现整体的测试.经过实验得到当参数为1.2 时,目标从进入感兴趣区域到最终进入门店的过程过短,算法在对目标进行跟踪的过程中会产生更多跟踪漂移的情况.当参数为2 时,有更多的背景被圈定进去,使得算法整体的运行效率降低.因此通过实验,本文将1.5 作为最后感兴趣区域的参数,在此参数下,能够有效的减少其它背景区域的干扰,提升算法运算效率.感兴趣区域示意图见图4 所示.

图4 感兴趣区域示意图
本文对客流量的统计是在双标准框基础上,通过其与同一目标的初始位置与终止位置的相对关系进行确定.整体判断流程为:当目标初始位置在门外,通过跟踪过程目标终止位置在门内,则定义目标进入了门店,实现人数累计,若不满足此条件,目标则未进门.
通过目标框与内标准框的重叠比例实现对目标与门店的位置关系判断.标准框的设置能够获取其坐标信息,目标识别与跟踪工作实现对于目标坐标信息的获取.其中得到目标框面积为Sobj,内标准框面积为Sid,重叠比例即为:
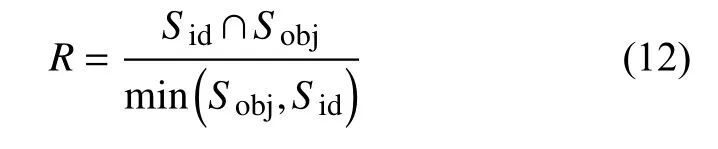
其中,∩为取交集操作,min(,)为求取两个目标框的较小值,标准框与目标框的尺寸均存在不确定性,因此保留较小值能有效防止比例漂移的情况.
当初始目标出现时判断目标与内标准框的重叠比例,本文算法将初始重叠阈值设为0.4,R >0.4时表示目标在门内,R <0.4时表示目标在门外.当目标跟踪结束时,终止重叠阈值设为0.8,当R >0.8则表示目标进入门内,反之目标则未在门内.
2 实验结果与分析
本文算法通过Python 实现,编辑平台为Atom,所使用的计算机为主频3.40 GHz 的CPU 以及8 GB 的内存.
2.1 目标跟踪结果分析
为了验证算法的有效性,本文选取了10 个门店30 天不同时间段的视频序列进行测试,将本文算法与KCF算法的结果进行对比试验,选取了其中两个门店的结果进行分析.图5 的门店A 存在着光照强烈变化的情况,初始阶段两个算法均能实现稳定的跟踪,而当目标弯腰时KCF算法产生了漂移现象,而本文算法能够保持稳定的跟踪.图6 的门店B 存在着车辆遮挡情况,当目标侧身时KCF算法跟踪产生误差现象,而本文算法能够一直准确的进行跟踪.这是由于CN 和HOG特征的融合丰富了目标表观特征描述,能够应对目标表观变化情况,并且相关滤波器算法通过循环矩阵与核化等方法的使用,大大降低了算法运算的复杂度,使得目标在快速移动时能保持稳定的跟踪效果.

图5 门店A 跟踪结果

图6 门店B 跟踪结果
2.2 客流量统计结果分析
本文所使用的实验数据为多个餐饮业门店的实际监控视频录像,视频格式为AVI,文本共选取了10 家门店30 天的录像进行结果测试,其中涉及白天与晚上.图7 所示为门店15 一天的客流量统计情况,其中将视频序列分成8 段,前4 段为白天光照条件较好时的情况,后4 段为晚上光线较差时的情况,通过该图可知,在多个视频序列下本文算法的统计结果与实际客流量基本一致,只有在晚上时有少量的出入,这是由于晚上的光线较差,目标背景间的差异较小导致的,但本算法在多目标进入门店发生遮挡等情况下有较好的表现,此门店整体统计的准确率为94.8%.图8 为10 家门店各自一天累计进店客流的统计结果,其中菱形标注本为算法的统计结果,正方形标注为实际人工客流的统计结果,本文方法整体客流统计平均准确率可达93.5%.

图7 门店15 客流统计图

图8 各门店人数累计分布图
为了验证本为算法的准确性与鲁棒性,本文通过10 个店铺各自的准确率及误算情况,进行对算法的评估.通过客流量检测值与真实值之间的误差情况进行准确率的计算,误算人数为算法整个过程中出现的错误情况,其中漏检人数包含在误算人数中.
从表2 可看出本文算法的准确率几乎均在90%以上,能得到平均准确率为93.5%.表中出现漏检的情况为夜间光线差和特殊天气情况导致的背景与目标间的差异较小,但在人群较多进入店铺时,本文算法能够得到准确的统计结果,这是由于本文目标进门行为判断算法的设计,使得目标在发生遮挡情况时能够进行稳定的统计.通过表3 中本文算法与文献[14]算法的对比,可以得到本文算法有更高的准确率,这是由于本文使用了基于深度学习的目标检测算法,使得对目标的初始检测更加准确,设计了目标跟踪算法,使得当目标发生快速运动时跟踪器能有更好的稳定性.
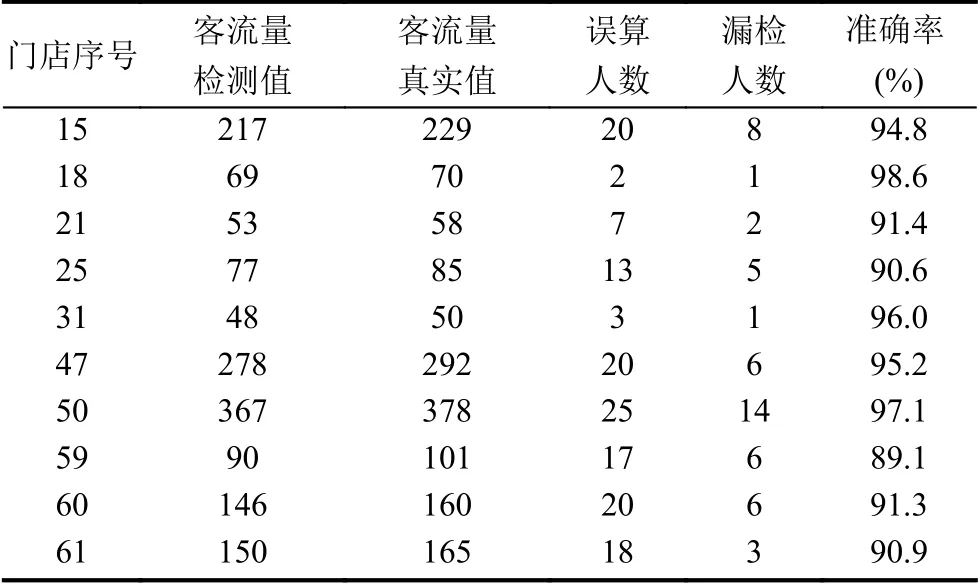
表2 客流量统计结果准确率

表3 两种算法客流量统计结果准确率对比
3 结论与展望
本文算法实现的是对于进门客流量的统计,算法整体流程首先是对获取的监控视频,利用卷积神经网络进行特征提取,训练YOLOv3-tiny 模型实现目标的识别,之后通过多特征融合的核相关滤波器设计,实现对于快速移动目标的稳定跟踪,最后通过进门行为判断方法的设计实现对于客流量的准确统计.通过实验验证,本文算法的平均准确率能达到93.5%.在目标快速移动和遮挡情况下能够实现准确的统计,但在光线昏暗的情况下算法的准确率需要进一步的提高,这是由于在光线较差的情况下目标与背景间的差异较小,使得算法对目标特征的获取产生了误差,在之后的研究中将进一步改进目标跟踪方法,改变获取特征的方式,将多特征融合进行特征提取的方式转换成深度卷积特征,实现对于目标特征更准确的描述,从而进一步提升算法的稳定性.
