利用外部知识辅助和多步推理的选择题型机器阅读理解模型①
2020-04-24盛艺暄
盛艺暄,兰 曼
(华东师范大学 计算机科学与技术学院,上海 200062)
机器阅读理解是自然语言处理的核心任务之一,目标是利用机器自动理解自然语言文本,从给定文本中获取回答问题的答案信息.高质量的机器阅读理解对于搜索、问答、智能对话等任务都发挥重要作用.根据答案是否是从文章中直接抽取的文本片段,机器阅读理解任务可以分为两类,抽取式和非抽取式.典型的抽取式任务有CNN/DailyMai[1],CBTest[2]等这类完形填空任务,以及SQuAD[3],TriviaQA[4]等这类片段抽取型任务.典型的非抽取式任务有MCTest[5],RACE[6],MCScript[7]等选择题型任务.
选择题型任务与上述直接抽取式任务最大不同在于答案候选项往往是与文章内容相关的归纳总结或文本改写,而非完全截取自文章中某文本片段.因此,需要机器通过从文章或借助外部知识进行推理,获得正确答案.表1 是来自MCScript 数据集中两种类型问题举例,问题1 的回答可由文章中下划线句子推理得出去蒸桑拿是为了解压:而问题2 则需要借助外部知识辅助推理,因为全文并没有提及蒸桑拿所穿服装的信息,因此结合文章中粗斜体句子信息(蒸桑拿很热),并利用(steam bath,RelatedTo,sauna),(bath suit,RelatedTo,swimsuit),(nude,DerivedFrom,swim),(jeans,UsedFor,clothing),(clothing,UsedFor,warm)等从外部知识库得到的相关外部知识,帮助机器正确推理并回答问题2.相比问题1 这类仅需推理文章可得到答案的问题,问题2 这类需外部知识辅助的问题属于选择题问题中难度大的问题,因为它不仅需要文章信息,还需要外部知识辅助才能得到答案,对模型推理要求更高.
解决阅读理解的问题时,可能会同时遇到问题1 这类仅需推理文章就可获得答案的问题,以及问题2 这类需外部知识辅助推理的问题,需要模型对两类问题都能较好地处理才能取得总体性能的提高.然而,目前选择题型机器阅读理解模型的研究大多是解决仅需推理文章可获得答案的问题.这些模型精心设计文章、问题和候选项的语义表示以及这三者之间信息交互方式.例如,Parikh 等[8]利用正交表示排除不相关的选项,并根据排除操作的结果增强文章的语义表示.Zhu 等人[9]利用选项之间的相关性建模选项语义表示.Wang 等人[10]将问题和选项分别与文章同时进行交互得到既包含问题信息又包含选项信息的文章表示用于答案预测.此外,也有一些研究工作意识到推理在选择题型阅读理解中的重要性,设计了多种多步推理方式.例如,Lai 等人[6]将GA Reader[11]应用于选择题,利用多步推理机制与文章问题之间的注意力机制结合的方式,进行固定次数问题和文章之间的信息交互用于答案预测.Xu 等人[12]在计算文章、问题和侯选项三者交互的语义表示后,采用强化学习进行动态多步推理得出正确答案.然而,上述模型都是针对仅需推理文章可获得答案的问题,没有外部知识的辅助,模型处理类似问题2 需外部知识辅助推理的问题时能力受限,无法正确推理回答问题,因此需外部知识辅助推理的问题是这类模型提高总体性能的一个突破点.
为帮助回答问题2 这类需外部知识辅助推理的问题,Wang 等人[13]和Chen 等人[14]尝试把从外部知识库中得到的词之间关系的表示向量加入词的嵌入表示中,通过隐式方式引入相关外部知识信息,但这些模型仅仅只利用外部知识信息以及文章、问题和候选项这三者的信息进行浅层的语义匹配.然而,利用外部知识辅助的问题往往对模型推理要求更高,上述模型并没有进行多步推理,导致该类模型不能深入地利用外部知识信息以及文章、问题和候选项这三者的信息共同进行融合推理.
为了解决需外部知识辅助推理的问题,从而帮助提升选择题机器阅读理解模型的总体性能.本文提出一个利用外部知识辅助和多步推理的选择题型机器阅读理解模型,该模型不仅引入与回答问题相关的外部知识,进行外部知识与文章、问题和候选项的信息交互用于建模语义匹配表示,还利用包含外知识信息的语义匹配表示进行多步答案推理,从而更好地利用外部知识信息帮助模型推理出答案.本文在国际语义测评竞赛2018年任务11 的数据集MCScript[7]上进行了对比实验,结果表明本文提出的方法有助于提高需外部知识辅助回答的问题的准确率.
本文的组织结构如下:首先在上述内容中介绍了本文的研究动机及相关工作,然后将在第1 节介绍本文提出的模型;在第2 节中说明实验设置,包含数据准备,模型参数设置和评估标准;在第3 节中展示实验结果并分析;最后在第4 节总结本文工作.
1 利用外部知识辅助和多步推理的选择题型模型
本章将介绍本文所提出的利用外部知识辅助和多步推理的选择题型机器阅读理解模型.本文目标是提高需外部知识辅助推理的问题性能来帮助提高总体性能,所以需要引入一定量的外部知识,然而仅需推理文章得到答案的问题原本只需要利用文章信息就可推理出答案,额外引入的外部知识对其而言可能会是噪声信息,容易影响仅需推理文章得到答案的问题性能.因此,在实现本文提高需要外部知识辅助的问题的目标的同时,应至少保持仅需推文章得到答案的问题性能不降低.因此本文基于Co-Matching 模型[9](一个针对解决仅需推理文章得到答案的问题的鲁棒性强的选择题型机器阅读理解模型),增加对外部知识的显示利用和多步知识推理功能,通过进一步提升模型解决需外部知识辅助推理问题的能力,从而提高模型总体性能.下面首先介绍本文提出的模型,然后阐述本模型与Co-Matching 模型的不同.
与解决仅需推理文章信息得到答案的模型不同,本文模型除了输入文章、问题和选项,还需要输入与文章、问题和选项这三者有关的外部知识.通常外部知识是采用图结构存储的知识库形式,每条外部知识采用三元组的形式(外部知识选取的相关内容将在第2 节实验配置介绍).图1 为本文提出的模型的概括图,展示了本文模型预测一个选项作为答案的概率的过程.将所有数据输入以后,该模型通过嵌入层、编码层、外部知识融入层、文章问题及选项信息交互层、答案层进行逐层处理,并在答案层输出预测的答案.下面从模型的输入开始,按数据处理的顺序逐步介绍上述5 层.
1.1 模型的输入
为便于模型描述,本文将采用下列符号化的表示定义选择题型机器阅读理解任务.该任务输入一个以四元组表示的选择题型阅读理解的全部数据<D,Q,C,K >,模型从答案候选项集合C 中选择概率最高的选项作为预测答案输出.四元组中给定的文章D 包含 s个句子 {DS1,DS2,···,DSs} ,其中第j句DSj的长度为lDSj个词,问题Q的长度为 lQ个词,答案候选项集合C 是包含y 个选项的集合{ c1,c2,···,cy} ,其中第i 个选项ci的长度为lci个词,相关知识集K 是从外部知识库中筛选出的与D,Q,C 有关的集合,是包含 p 个外部知识的三元组的集合,其中每个知识三元组k 表 示为k=(subj,rel,obj).s ubj 和o bj 是至少包含一个词的三元组头、尾节点,长度分别为lsubj和lobj.rel是 subj和obj之间的关系,长度为1.
1.2 嵌入层
嵌入层将输入的四元组中的每个词投射到一个语义表示的向量空间.以问题Q 为例,其中每个词表示为词嵌入后得到其中表示问题中第n 个词的嵌入表示,本文采用预训练的Glove 词向量[15]并拼接人工特征作为每个词的嵌入表示.人工特征为多个二值特征,表示该单词是否出现在文章D 中、问题Q 中、候选项ci(i ∈[1,y])中、同时出现在文章D和候选项ci(i ∈[1,y])中,同时出现在问题Q和候选项 ci(i ∈[1,y]).同样,对文章的句子D Sj(j ∈[1,s])和选项 ci(i ∈[1,y])中每个词进行向量映射后,分别得到EDSj和 Eci.此外,外部知识集合中每个三元组的词进行向量映射后,可表示为k =(Esubj,Erel,Eobj).
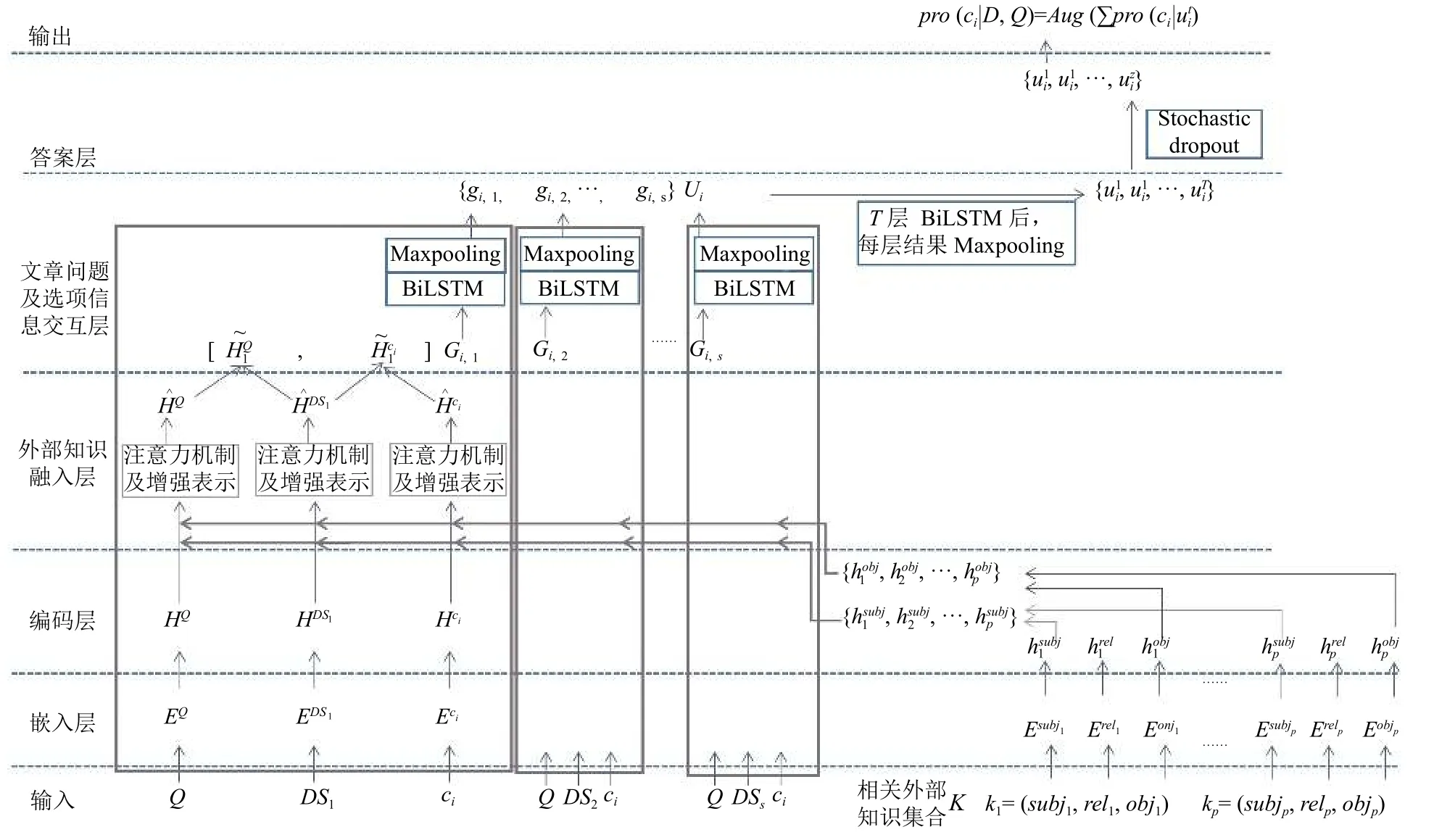
图1 利用外部知识辅助和多步推理的选择题阅读理解模型
1.3 编码层
编码层是为每个词的嵌入表示生成上下文依赖的编码表示.本文使用双向长短期记忆网络(BiLSTM)对文本进行语义编码.以问题 Q为例,采用如式(1)经过BiLSTM得到其语义表示 HQ∈RlQ×2h:
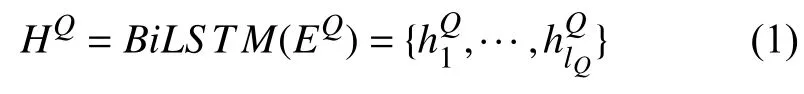
1.4 外部知识融入层
外部知识融入层是为了把外部知识引入模型,受Mihaylov 等人[16]解决完形填空中针对名词类型问题的启发,本文在进行文章问题及选项的信息交互之前,通过外部知识和文章、问题及选项中每个词的语义匹配关系得到每条外部知识的权重,并按各条外部知识的权重表示文章、问题和选项的每个词,再将每个词分别按外部知识的权重和上下文编码的权重的结果进行按权重的线性加和(见式(4)),这样得到既包含外部知识信息又包含上下文依赖信息的词表示.以问题 Q中第n个词为例,如式(2),本文首先采用注意力机制求得外部知识集合K 中每条外部知识三元组和该词之间的关系权重,并按权重线性加和得到∈R1×2h:

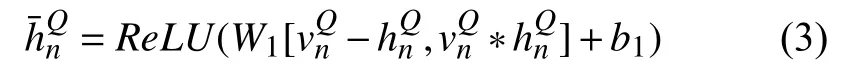
其中,ReLU 是一种非线性激活函数,[ ,]是拼接操作,-和∗ 是元素减和元素乘操作,W1和b1是训练参数.随后将 Q 中第n 个词优化后的外部知识按权重的表示向量和上下文编码向量进行有权线性加和,如式(4)

其中,α ∈R1×2h是一个随机初始化可训练的向量.经该层处理后,问题 Q 表示为,其中每个词表示都包含外部知识信息和上下文信息.类似地,对文章中的句子和选项采用同样操作可分别得到和.
1.5 文章问题及选项信息交互层
为了生成文章、问题和候选项这三者之间的交互语义匹配表示,使模型关注到这三者匹配度高的部分,信息交互层在Wang 等人[9]提出的Co-Matching 匹配方式的基础上进行了改进.Co-Matching 模型仅仅利用文章、问题和候选项三者的上下文编码直接进行语义匹配,缺乏外部知识的辅助,因而回答需外部知识辅助推理的问题时能力受限,而为了使外部知识的信息能够参与语义匹配中,本文使用外部知识融入层的输出替代只有上下文编码信息的表示,并通过注意力机制同时计算问题和文章中每个句子的语义匹配关系以及各个选项和文章中每个句子的语义匹配关系.以问题Q 和文章中第 j 句D Sj的信息交互为例,用如式(5)和式(6)计算得到包含外部知识信息和问题信息的文章中第 j 句的表示:
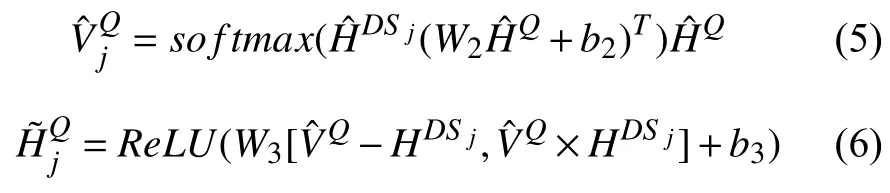
同时对选项 ci进行类似处理可得.然后将和进行拼接可得既包含外部知识信息又包含问题 Q和选项 ci信息的文章中第 j 句的语义匹配表示Gi,j=对每个问题、文章中某句子和某一个候选项构成的任一组合 {Q,DSj(j ∈[1,s]),ci(i ∈[1,y])}都可采用上述四层处理,得到一个语义匹配的表示Gi,j,i 和 j分别表示第i 个选项和文章第 j 句.以第i 个候选项ci为例,在得到融入了外部知识、问题和候选项信息的文章中所有句子的表示 { Gi,1,Gi,2,···,Gi,s}后,采用如式(7)将文章句子的矩阵表示Gi,j变成向量表示gi,j:

由此可以得到由文章中所有句子语义匹配表示向量组成的语义匹配表示 Ui={gi,1,gi,2,···,gi,s},Ui中含有经过语义匹配的外部知识辅助信息、以及问题文章和选项的信息.
1.6 答案层
答案层采用多步推理机制实现答案预测.用多层BiLSTM 对信息交互层得到的语义匹配表示 Ui进行推理,根据每层BiLSTM 的输出,得到一系列输出结果,其中T 为总推理步数,为第t 层BiLSTM 的输出.然后,对每层BiLSTM 的输出使用最大池化操作得到.在多步推理的过程中,为避免出现某步推理偏执的问题(“step bias problem”),本文对多步推理的结果使用Liu 等人[19]提出的随机丢失策略(Stochastic dropout),即按一定的随机丢失概率随机丢弃中的一些结果,随机留下z (z ≤T)步推理结果.然后本文根据留下的推理结果计算选项ci为预测答案的概率,并计算余下步骤的概率均值,得到综合考量多个推理步骤后选项ci作为预测答案的平均概率:

1.7 本文模型与Co-Matching 模型的异同点比较
本文提出的模型是基于Co-Matching 模型,但与Co-Matching 模型在各层中都存在不同.(1)在嵌入层,本文加入了人工特征表示词匹配关系,对回答一些候选项与文章有词共现的问题有帮助.(2)在编码层,本文增加对外部知识的编码.(3)额外增加外部知识融入层丰富词表示,使模型具有灵活丰富的外部知识的信息辅助.(4)在文章问题及选项信息交互层,Co-Matching 模型仅利用文章,问题和选项的信息做语义匹配,本文模型使用外部知识融入层的输出,在进行三者信息交互时有外部知识的信息参与,增强了机器阅读理解模型回答需要外部知识辅助类问题时的语义匹配能力.(5)在答案层,采用了多步推理机制而并非单层答案预测层,可更进一步利用外部知识信息帮助推理,解决了仅利用外部知识信息进行浅层语义匹配的缺陷,增强了模型的推理能力,更有利于推理需外部知识辅助的问题.
2 实验设置
本章介绍实验的设置,包括数据准备,模型参数设置和评估指标.
2.1 数据准备
数据集:本文使用国际语义测评竞赛2018-SemEval的任务11 的数据集MCScript 进行实验.MCScript 是旨在于让大家探索使用外部知识进行机器阅读理解的数据集,其中每篇文章对应若干问题,每个问题有2 个选项,需从中选择一个正确答案.数据集中同时包含需要外部知识辅助推理的问题(表中“cs”类型)和仅需文章信息可推理答案的问题(表中“text”类型),“cs”类问题和“text”类问题比例约3:7,“cs”型的问题数量比“text”类型的问题的数量少.因此,“cs”类型问题应该有较大变化才能影响数据集的总体效果.数据集的具体分布如表2 所示,“all”是所有问题,“#”表示数量.
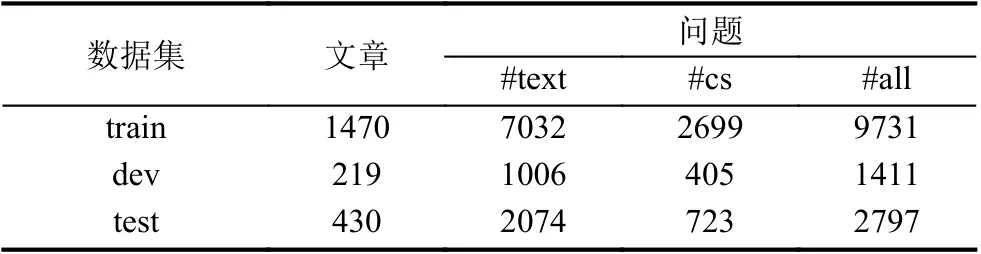
表2 数据集MCScript 的数据分布
外部知识集合K 的构建:由于要给模型输入相关的外部知识,本文采用如下3 个步骤挑选得到与 D,Q和C 有关的外部知识集合K.第1 步,从外部知识库中搜索包含 D ,Q和C 中词语(去停词)的知识三元组.本文使用图结构存储的ConceptNet[20]作为外部知识库,ConceptNet 做外部知识库是因为其采用多种资源构建,包含OMCS[21],Open Multilingual Word Net[22],Open-Cyc[23],DBPedia[24],JMDict[25]和“Games with a purpose”[26-28].知识图中每两个节点和其连接边可组成一个外部知识三元组,两节点分别是 subj 和o bj,边为两节点的关系r el.第2 步,根据以下两点对外部知识进行打分:(1)外部知识中的词在给定的不同文本中出现的重要性不同,在候选项中出现最重要,问题其次,文章更次;(2)外部知识三元组里出现在给定文本中的词数在外部知识总词数的占比,并排序选出得分最高的前50 条知识.其中一条外部知识三元组k 的相关性得分的计算如式(10)和式(11):

式中, scoresubj为 s ubj分数,有4 个值,取值方式为:subj中的词如果出现在选项中给4 分,如果出现在问题中为3 分,如果在文章中给2 分,不出现给0 分.scoreobj类似.式(11)中c nt()为 词语数量,∪表示两者中出现过的所有词,∩表示两者中共同出现的词.第3 步,为防止外部知识出现频率对模型选答案造成影响,使两条选项所对应的外部知识数量一致,本文首先把选项对应的外部知识进行排序,保留所有选项前 x条外部知识( x为对应外部知识最少的选项的外部知识数量).所有只与文章或与问题有关的外部知识则都保留.
2.2 模型参数配置
本文提出的模型采用Pytorch 框架构建实现.词嵌入为300 维预训练Glove 词向量[15]和8 维人工特征拼接的308 维向量.MCScript 数据集中每道题对应2 个选项,人工特征为8 维,即是否出现在文章D,问题 Q,选项 c1,选项 c2,同时出现在文章D 和候选项c1,同时出现在文章D 和候选项 c2,问题Q 和候选项中c1,问题Q 和候选项 c2中.由于外部知识三元组中r el是外部知识库自己定义的字符表示并且种类固定(ConceptNet中为34 种),本文采用34 个308 维随机初始化向量分别表示这些关系.BiLSTM 的隐层是150 维,损失函数是NLLLoss.采用Adamax算法[29]以0.002 为初始学习率开始训练,并在每10 个批大小(batch size)进行更新.为防止过拟合,嵌入层和编码层都采用概率0.4 的丢失策略(dropout).答案层采用8 层的BiLSTM 进行8 步推理,答案层随机丢失的概率也为0.4.模型共训练50 轮(epoch).
2.3 模型评估
本文采用准确率来评估模型,如式(12)计算.

3 实验分析
3.1 与其他模型的比较
表3 展示了本文模型与其他模型的实验对比结果.其中“—”表示数据未提供,“*”表示是使用原作者提供的代码复现的结果,除了MITRE 均为单模型结果.
表3 中Random,Sliding Window,Bilinear Model 和Attentive Reader 是MCScript 上的实验基线系统.Co-Matching[10]是本文模型的基线系统.HMA[30],TriAN[12]是竞赛前两名的单模型结果.MITRE[31]是竞赛第3 名的集成模型的结果,因为其使用不同结构的模型集成,并非同一结构不同随机种子训练的模型集成,因此将其3 个集成模型MITRE(NN-T),MITRE(NN-GN)和MITRE(LR)的结果也列在表中.其中GCN[13]和TriAN[12]是隐式引入外部知识到模型词嵌入层中的模型,而本文模型是在编码之后显示引入外部知识的模型,其余模型都未引入外部知识.

表3 不同模型的准确率对比(单位:%)
本文模型在MCScrip 中需要外部知识辅助的问题(“cs”类型的问题)上取得了79.95%的准确率,超过Co-Matching 的准确率2.92%,甚至超过了MITRE 集成模型在“cs”类型的问题上0.95%的准确率.而仅由文章推理可得答案的问题(“text”类型的问题)取得了81.53%的准确率,相比于Co-Matching 的准确率提升0.32%,说明本文模型在引入外部知识时保持“text”类型的问题性能不降低.从总体性能和问题占比情况看,本文模型取得了81.01%的准确率,相比Co-Matching提升了1%,这主要是靠在数据集中相对数量少的、占比约30%的“cs”类型问题近3%的提升所贡献的.该实验结果与本文目标通过提升需外部知识辅助问题的性能,从而帮助选择题型阅读理解是一致的.另外,与表3 中总体性能(“all”问题的准确率)超过本文模型的集成模型MITRE 和单模型TriAN(扩展训练数据)比较,MITRE 效果好于本文模型是因为其使用3 个子模型集成,然而其3 个子模型各自的在“all”问题的准确率均低于本文单模型效果;与单模型TriAN(扩展训练数据)比较,本文模型准确率比TriAN 低0.93%,这是因为TriAN 使用了额外的大规模单选题数据集RACE做训练,而本文未使用额外训练数据.当TriAN 只用MCScript 进行训练时结果为80.51%,本文模型的结果高于其结果0.50%.
3.2 不同外部知识数量的影响
为了深入分析不同外部知识数量对模型的影响,表4 展示了不同外部知识的结果.当知识数量为100条时,“cs”类问题的效果最好,但总体性能相比50 条时略有下降.整体观察表格中数据情况,可以发现当外部知识数量越高,模型的效果整体呈降低趋势,这可能是由于随着外部知识的引入同时会带来噪声,说明构建外部知识集合K 的方式、外部知识被引进模型及与文章问题选项三者交互的方式仍可以被改进.
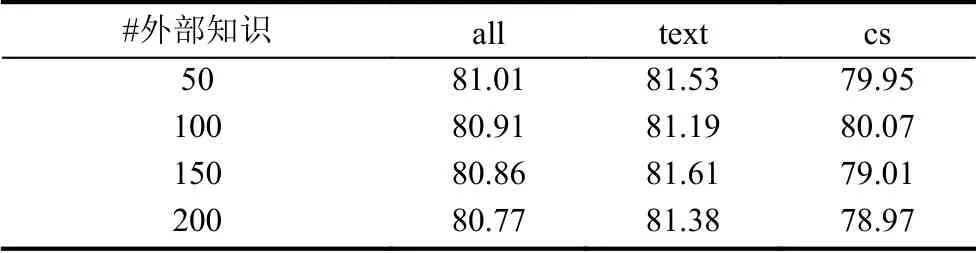
表4 不同外部知识数量情况下test 上的准确率(单位:%)
3.3 模型模块消减实验
本文还进行了消减实验用以分析外部知识的引入以及利用外部知识和文章信息一起进行推理的作用.首先本文模型分别与如下3 种模型对比:(1)“-外部知识引入”是指仅采用上下文编码信息进行匹配和多步推理,仅在本文模型上删去外部知识引入层;(2)“-答案多步推理”是在本文模型上删去多步推理答案层,仅使用Co-Matching 模型原本的答案层,但保留了外部知识的引入;(3)“-外部知识引入&答案多步推理”是在本文模型中删除外部知识引入和多步推理两种模块.表5 给出了消减实验的结果,“-”表示删减某个模块.
对比表5 中“本文模型”和“-外部知识引入”发现删除外部知识的辅助在“cs”类型问题上有1.94%的下降,并且表中包含外部知识引入的模型(“本文模型”和“-答案多步推理”)在“cs”类型问题的结果都高于其余两种无外部知识辅助模型的效果,证明加入外部知识信息是有助于回答需要外部知识辅助类型问题的.
对比表5 中“本文模型”和“-答案多步推理”,发现在“cs”类型问题的表现上下降0.94%,说明在语义匹配的基础上进一步利用外部信息推理是对答题有帮助的.“-答案多步推理”和“-外部知识引入”对比,发现删去多步推理机制比删去外部知识引入对“text”类型的问题影响更大.对比“-答案多步推理”和“-外部知识引入&答案多步推理”,发现在“text”类型的问题上“-答案多步推理”要略逊0.10%,说明引入外部知识信息后若仅采用语义匹配,不增加推理步骤可能会对“text”类型的回答略有影响,也证明了利用外部知识进行推理(而不仅仅是语义匹配)在使模型尽可能不降低“text”类型的效果上略有帮助.

表5 test 上的消减实验准确率(单位:%)
3.4 模型运行时间分析
表6 中为本文模型和基线模型Co-Matching 每一轮(epoch)平均训练时间、训练至目标函数的损失值波动平稳的收敛时间和全部测试数据的测试时间.本文模型对基线模型Co-Matching 的各层都增加了功能,时间的主要增长来源应是额外增添的外部知识融入层和多步推理答案层,因此训练时间、收敛时间和测试时间都有所增加,但增加的时间在合理可控的范围内.

表6 每轮的运行时间分析(单位:s)
4 结论与展望
针对需要外部知识辅助的单项选择题阅读理解问题,本文提出了一个利用外部知识辅助和多步推理的选择题型机器阅读理解模型,这个模型在保证引入外部知识的情况下,不降低回答仅需文章推理的问题性能的同时,提高需要外部知识辅助问题的性能,从而提高模型的整体性能.本文的实验结果证明提出的模型的有效性,然而对比人类的结果还有巨大的差距,因此接下来将更深入分析人类回答两类问题的特点,模拟人类的回答方式探索更细致有效的外部知识引入模型的方式,研究不同外部知识引入方式对模型性能的影响.
