网络驱动的未识甲骨字特性及场景语义预测
2020-04-21焦清局刘永革利萍金园园刘国英高峰
焦清局,刘永革,仇 利萍,金园园,熊 晶,刘国英,高峰
(1.安阳师范学院计算机与信息工程学院,河南安阳455000; 2.甲骨文信息处理教育部重点实验室,河南安阳455000; 3.河南省甲骨文信息处理重点实验室,河南安阳455000; 4.安阳师范学院历史与文博学院,河南安阳455000; 5.中国社会科学院先秦史研究所,北京100732)
甲骨学的研究为人们探究中国文字的起源、殷商史及中国文明史具有重要的意义。然而,单纯依靠文献的传统甲骨学研究已不能满足当今社会发展的需要,特别是不能快速有效地破译未识甲骨字的语义。随着甲骨学研究成果和文献的积累,甲骨学知识逐步呈现系统和大规模化。为利用计算机技术研究甲骨学提供了基础数据。近年来,在甲骨字的输入和可视化、识别、语义分析、网络甲骨学等方面已有一些初步探索和研究。甲骨字的输入为甲骨学文献和著录的数字化提供了必要的工具。2004 年,为对甲骨文字、拓片、文献等信息数字化,刘永革等[1]开发了甲骨字输入法:将甲骨字转化为图片,并通过插入图片的方法输入甲骨字。为了更好地输入甲骨字,肖明等[2]利用模糊信息分析理论研究了象形码编码模型。顾绍通等[3]通过编码研究,可从形和音的角度输入甲骨文:首先,利用部件对甲骨字进行拆分,然后,将甲骨字部件与标准键盘的26 个键位建立映射关系,最后,按照规定顺序输入甲骨字部件对应的键位,完成甲骨文输入。与顾绍通等的方法类似,聂艳召等[4]将甲骨字拆分成更小的部件(称为笔画或码元),然后设计编码系统,进而输入甲骨字。在计算机技术辅助的甲骨学研究中,甲骨字识别在甲骨异体字(异体字是同一个甲骨字的不同写法)辨别、甲骨学文献数据库建设等方面具有重要作用。栗青生等[5]通过对甲骨字向图的转换,进而识别甲骨文字。该方法首先把甲骨字的一些重要端点和交点抽象为图中的点;然后,根据甲骨字形连接图中点之间的边,进而形成该甲骨字的图;最后,根据图的匹配算法识别未知甲骨字。2014 年,高峰等[6]首先利用语境分析生成的候选字库得到对应的甲骨文语义构件向量,然后结合Hopfield 网络识别的结果计算待识别的甲骨文模糊字的匹配度,根据匹配度识别甲骨字。2016 年,顾绍通等[7]通过对甲骨字的拓扑提取和编码抽象甲骨字,并通过拓扑配准算法识别甲骨字。同样利用图像处理的方法,GUO等[8]首先利用Gabor 变换和稀疏表达提出一种层次表示(hierarchical representation)法,然后结合卷积神经网络(convolutional neural network, CNN)识别甲骨字。在甲骨文语义分析方面,2012 年,袁冬等[9]提出基于实例的甲骨文释文机器翻译方案,并实现一套机器翻译系统。2015 年,高峰等[10]首先构建一个融合甲骨文和现代汉语的语义知识库,然后通过可拓模型解决甲骨卜辞问题。同年,熊晶等[11]在文本挖掘的基础上,结合语义Web 技术,将实体及其关系资源描述框架(resource description framework,RDF)抽象化,并在生成的RDF 集合中进行语义搜索,利用本体关系和推理挖掘RDF 对象间显式或隐式的语义关系。在网络甲骨学方面,2016 年,DRESS 等[12]选择60 个甲骨文动物字作为研究对象,通过提取这些甲骨字的特征向量,计算相似性距离,构建动物甲骨字的认知网络。焦清局等[13]从系统的角度研究甲骨学,并利用甲骨拓片数据,通过建模构建甲骨字网络。在甲骨字网络之上,对网络属性进行分析,为用计算机技术预测未识甲骨字的语义提供数据和理论支持。
语言是人类驱动(human-driven)的复杂适应系统[14],从复杂系统或复杂网络的角度对自然语言的研究可以充分捕捉语句、词、字之间的语法和语境的内在关联信息,也有助于揭示语言的结构化和语言在演化过程中的未知属性[15]。2001 年,CANCHO等[16]首次利用复杂网络的方法构建并研究英语同现网络。随后,从复杂网络的角度对语言进行研究,包括语言网络的构建及其特性分析、语言中未知属性分析、基于网络视角的语言认知分析等。2005 年,STEYVERS 等[17]构建并分析了3 种语义网络,并对它们进行网络特性的对比分析。此外,还提出一种语义网络增长模型。同年,韦洛霞等[18]根据词同现构建了汉语网络,并揭示网络的无标度特性。ARBESMAN 等[19]构建了英语和西班牙的音韵(phonologically)网络,并详细分析了具有相同小构件的西班牙语和英语在音韵和语义之间的差异。SIEW 等[20]不仅构建了音韵网络,而且使用模块结构(module structure)挖掘算法,从音韵网络中挖掘17 个模块,并分析了模块的特性。 2017 年,DAUTRICHE 等[21]利用字之间的相邻音韵关系构建音韵相邻网络,分析发现,与随机网络相比,音韵网络有较高聚类系数和传递性。2019 年,LIANG等[22]利用构建的206 个现代汉字共现网络(cooccurrence network)分析其演化过程中的统计参数关系,结果表明,现代汉语拓扑结构的光谱行为(spectral behavior)在演化过程中具有一致性。ARRUDA 等[23]提 出 一 种 基 于 段 落(paragraphbased)的文本表示方法,利用此方法揭示了真实的文本具有较强的社团结构特性。通过构建语言的语义网络、句法网络、概念网络、信息网络以及社会网络可揭示人类的认知系统[24]。SIZEMORE 等[25]通过构建语义特征网络探索知识鸿沟(knowledge gaps)问题,并揭示语义特征网络在语言学习过程中的重要性。HAGOORT[26]从多重脑网络的角度揭示了人类处理语言的过程。
未识甲骨字的语义预测是目前甲骨学研究中面临的重要问题和难题。虽然计算机技术辅助的甲骨学研究取得了一些进展,但要预测未识甲骨字的语义还很远。为了解决以上问题,本文从系统的角度对未识甲骨字进行研究。首先,利用甲骨文拓片数据构建了甲骨字网络;其次,对未识甲骨字在网络上的重要性、信息丰富度、闭合性进行研究;最后,结合网络特性和拓片的上下文语境对未识甲骨字的场景语义进行了预测。
1 甲骨字网络的构建
为了分析未识和已识甲骨字在网络上的不同特征,需要构建甲骨字网络。本文以甲骨拓片为基础数据,并利用文献[13]中的方法构建甲骨字网络,即网络矩阵M。此方法共包含3 个步骤。第1,选定一片甲骨拓片,假设此拓片上有2 个甲骨字i 和j,则可用式(1)和式(2)定义甲骨字i 和j 之间的距离wij,并将wij值赋予Mij处。在式(1)中,int eral 的值可用式(2)计算:如果2 个甲骨字之间没有残缺的字(由于年代久远,甲骨拓片中的甲骨字可能出现脱落),li和lj表示甲骨字i 和j 在拓片中的位置,并且字j 在字i 的后面,那么int eral 的值为lj-li;如果甲骨字i 和j之间有残缺的甲骨字,那么int eral 的值有两部分组成,其中一部分为β,表示残缺甲骨字之间的距离,在本文中,设置为2。第2,如果2 个甲骨字在不同的拓片上同时出现,分别计算这2 个甲骨字在不同拓片上的相似性距离,相加后赋予相似性矩阵对应的位置。第3,根据71 455 片拓片,得到6 199 个甲骨字(包含甲骨异体字)之间的相似性矩阵,此矩阵共包含160 964 条边。
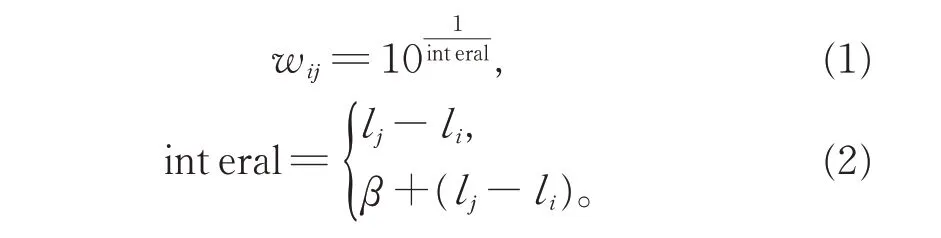
2 未识甲骨字特性定义
为破译未识甲骨字的语义,需要对已识和未识甲骨字的网络特性进行分析,并利用已识甲骨字的特性指导未识甲骨字的考释。本文以甲骨字网络为基础数据,对已识和未识甲骨字在网络上的重要性、信息丰富度、考释难易程度进行详细分析,进而为未识甲骨字的考释提供方法指导。
2.1 介数中心性
首先对未识甲骨字是否值得进一步研究进行探索。由于本文使用甲骨字网络抽象甲骨文系统,因此,需要对未识甲骨字在甲骨字网络中对应结点的重要性进行研究。在复杂网络中,介数中心性(betweenness centrality, BC)是结点重要性的一种指标[27],以经过某个结点的最短路径数目来刻画结点的重要性:
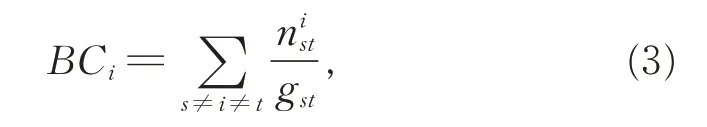
其中,gst表示从结点s 到结点t 的最短路径数目,nist为从结点s 到结点t 的gst条最短路径中经过结点i 的最短路径数目。
2.2 结点的强度和度
拓片是甲骨文字系统存在最为有力的载体,也是计算甲骨学家能够获取的最直观的数据,它构成了甲骨文系统的基本语义单元。甲骨文拓片中字与字之间的相互关联信息是预测未识甲骨字的重要信息。本文构建的甲骨字网络以原始拓片为基础数据,通过抽象同一拓片中字(i)与字(j)之间的前后顺序定义它们之间的距离,而字i 和j 之间的权重通过它们在不同拓片中形成的距离叠加得到。因此,构建的甲骨字网络不仅能反映字与字之间的语境信息,而且能反映字与字之间在不同拓片中出现的次数。
如果一个未识甲骨字在不同拓片中出现次数较多,并且所在拓片含有的甲骨字较多,那么,此未识甲骨字因其在甲骨文系统中包含的信息较丰富,其语义被预测的可能性较大。在甲骨字网络中,未识甲骨字的信息丰富度表现为结点(i)的强度(S,式(4))和与此结点相连且权重大于0 的个数(U,式(5))。
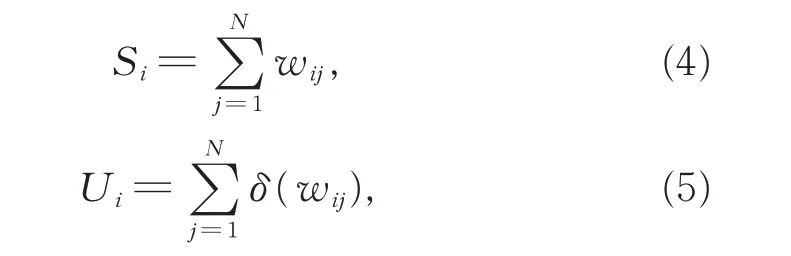
式(4)和(5)中,N 表示网络矩阵M 的结点数,wij表示结点i 和j 之间的权重值。当wij大于0 时,δ 取值为1,否则取值为0。
2.3 未识甲骨字的闭合系数
在2.2 节中,分析了一个甲骨字与其他甲骨字之间在不同拓片出现的情况(U 值)以及不同拓片同时出现的强度(S 值),这些结果为破译未识甲骨字的语义提供了重要的信息。但是这些信息只是从模糊的角度反映未识甲骨字语义推理的重要性。如,一个未识甲骨字(i)有较大的S 和U 值,而与字i 相连的都是未识甲骨字(可标记为[i1,i2,…,in])。由于甲骨字[i1,i2,…,in]的语义是未知的,因此也无法从[i1,i2,…,in]中获取有用信息进而预测i 字的语义。同样,对于一个具有较大S 和U 值的已识甲骨字j,与j 字相连的都是已识甲骨字(可标记为[ j1,j2,…,jm]),那么j 字也无法为破译未识甲骨字提供有用信息。这种现象称为甲骨字的闭合性(见式(6)和图1)。
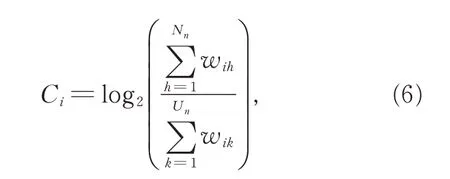
式(6)中,Ci表示甲骨字i 的闭合系数,Nn和Un分别表示已识和未识甲骨字的个数,wih和wik分别表示甲骨字i 与已识和未识甲骨字连接的权重。由于连接的权重和值较大,对其取对数。
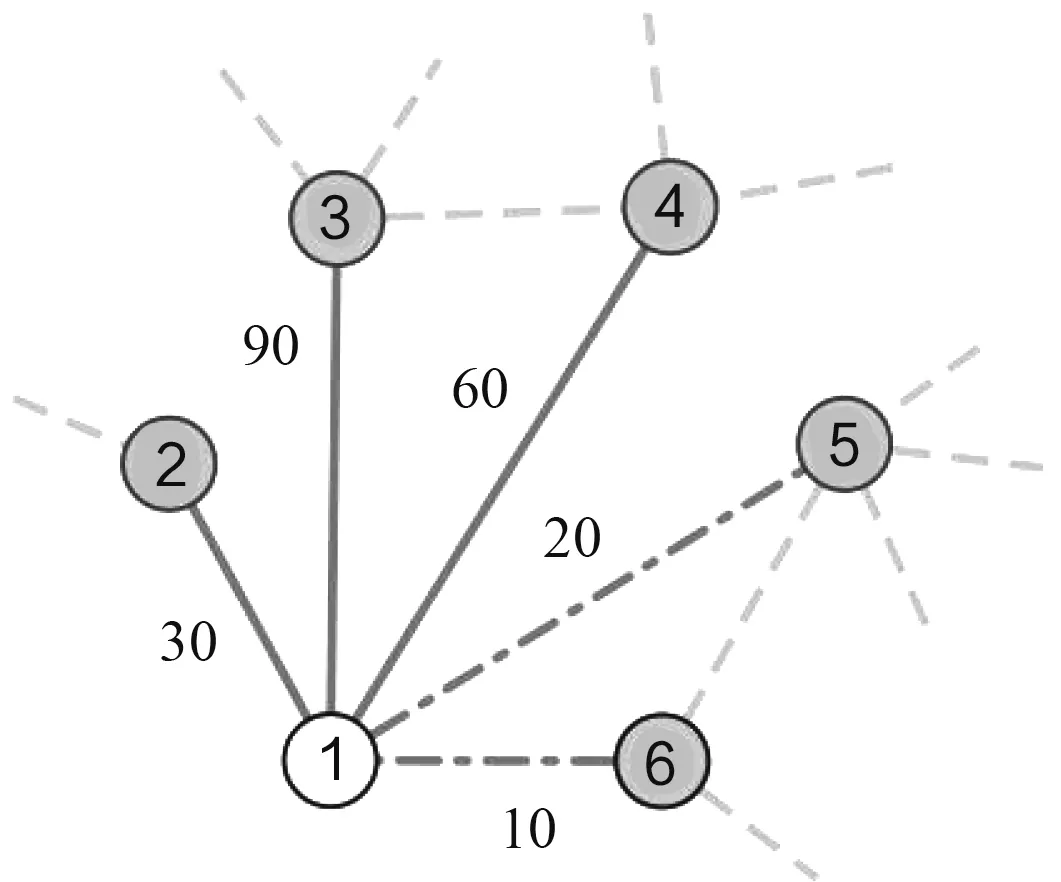
图1 闭合系数计算示意图Fig.1 An example to calculate closed coefficient
一个未识甲骨字的闭合性的绝对值越大,被破译的可能性越小;而一个已识甲骨字的闭合性值越大,此字为破译其他未识甲骨字提供的信息就越少。从式(6)中可以推断,如果一个未识甲骨字i 与其他已识甲骨字连接的权重越小,而与其他未识甲骨字连接的权重越大,Ci的负值就越小,|Ci|绝对值就越大;如果一个已识甲骨字j 与其他已识甲骨字连接的权重越大、而与其他未识甲骨字连接的权重越小,Cj的值就越大。总之,在甲骨文字系统中,如果已识甲骨字的Cj值和未识甲骨字的|Ci|值较大,对破译未识甲骨字语义的困难就越大。对于一个未识甲骨字i,如果它的Ci值越大,说明此字与已识甲骨字连接较为紧密,可用信息越多,破译的可能性越大。
在图1 中,与甲骨字1 相连的甲骨字共有5 个,分别为甲骨字2,3,4,5,6,它们与甲骨字1 的权重分别为30,90,60,20,10,如果甲骨字2,3,4 为已识甲骨字,甲骨字5,6 为未识甲骨字,那么甲骨字1 的闭合系数C1为
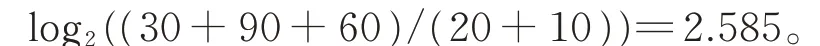
3 实验结果分析与讨论
3.1 未识甲骨字的重要性
为计算未识甲骨字在甲骨字网络中的重要性,首先计算所有甲骨字的介数中心性(式(3));然后,对所有甲骨字的介数中心性值进行排序,排序后的结果为SBC;最后,选出排名前NS的结点,计算NS中未识甲骨字所占比例PS:
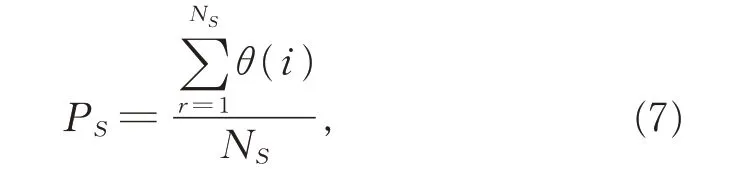
式(7)中,当甲骨字i 为未识字时,θ 取值为1,否则取值为0。
图2表示的是当Ns=[50,100,200,…,1500,1600]时(由于已识甲骨字的个数为1 602,所以NS的最大值设置为1 600),未识甲骨字在BC 值上的PS值。从图2 中可以看到,当NS=50 时,PS在BC 上的值为10%,即前50 个甲骨字中,仅有5 个字是未识甲骨字;当NS=100 时,PS在BC 上的值为13%,即前100 个甲骨字中,仅有13 个字是未识甲骨字。随着NS值的增大,PS值也逐步增大。当NS=1 600 时,PS值为52.06%,其结果意味着未识甲骨字的重要性甚至大于已识甲骨字。因此,未识甲骨字语义预测对重新认识甲骨文系统、殷商文化和古代史都有重要意义。
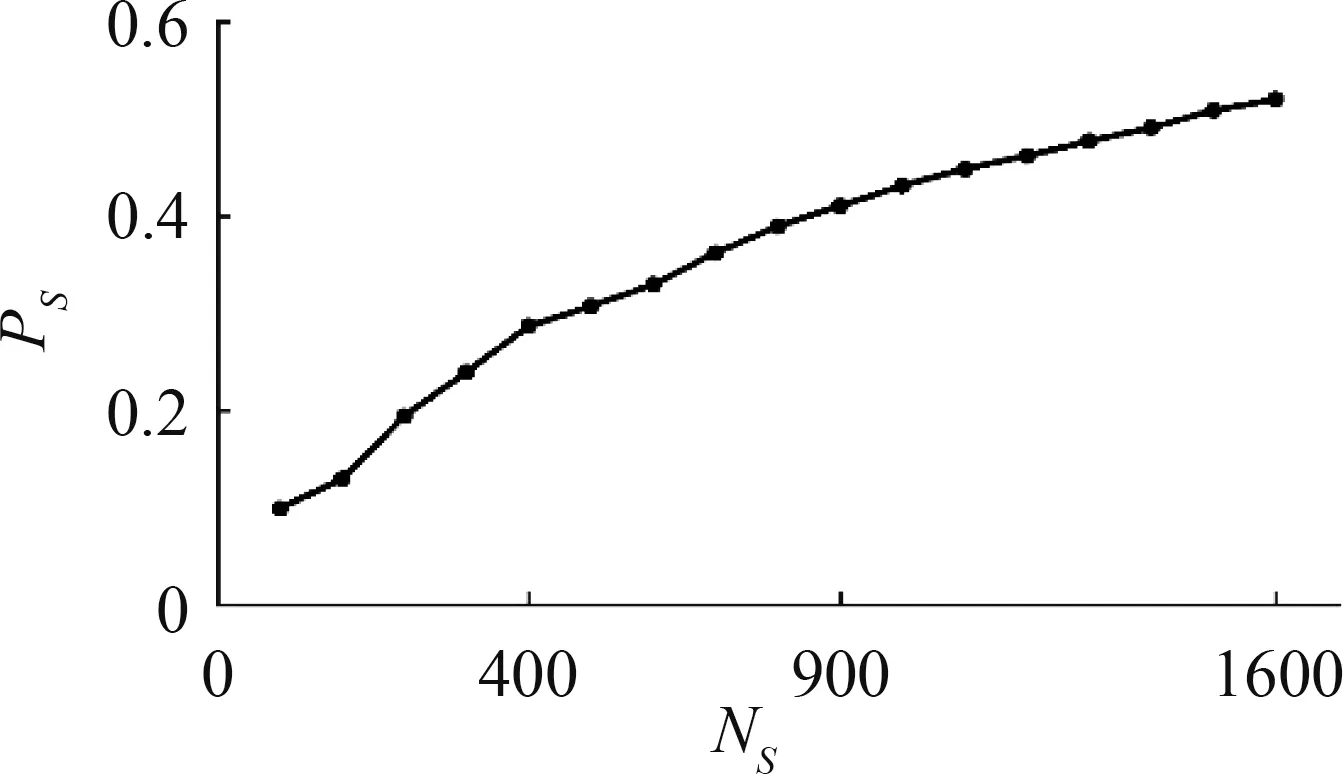
图2 未识甲骨字在BC 值上的PSFig.2 The values of PS of unknown oracle characters on BC
3.2 未识甲骨字的信息丰富度
未识甲骨字的信息丰富度是语义预测的直接依据。依据S(式(4))和U(式(5))的定义,分析未识甲骨字的信息丰富度:第1,计算所有结点的S 和U值;第2,对结点的S 和U 值进行排序,取出排名前NS个结点,计算NS中未识甲骨字所在的比例PS(式(7) ) 。 图 3 表 示 的 是 当 Ns=[50,100,200,…,1500,1600]时,未识甲骨字在值S(图3A)和U(图3B)上的PS值。从图3 中可以看到,当NS=50 时,PS在S 上的值为10%,即前50 个甲骨字中,仅有5 个是未识甲骨字;当NS=100 时,PS在S 上的值为17%,即前100 个甲骨字中,仅有17个是未识甲骨字。随着NS值的增大,PS值也逐渐增大。可以看到,甲骨字的S 值越大,其语义被破译的可能性就越大。对于U 值,随着NS值的增大,PS值也逐渐增大。如,当NS=50 时,PS在S 上的值为6%,即前50 个甲骨字中,仅有3 个是未识甲骨字;当NS=100 时,PS在S 上 的 值 为12%,即 前100 个 甲骨字中,仅有12 个是未识甲骨字。从U 值中可以看到,与S 值相比,U 值在破译甲骨字语义上起更重要的作用。综上,甲骨字的信息丰富度在预测甲骨字语义上具有重要的支持作用,而一些未识甲骨字(具有较大的S 和U 值)的可用信息足以预测其语义。
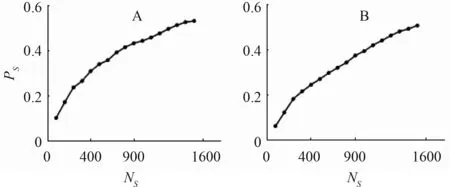
图3 未识甲骨字在S 和U 值上的PSFig.3 The values of PS of unknown oracle characters on S and U
3.3 未识甲骨字的考释难易程度
闭合系数(式(6),C)可以定义未识甲骨字的考释难易程度,即未识甲骨字的闭合系数越大,此字的语义被破译的可能性越大。考释难易程度有助于解决首先预测那些未识甲骨字的语义问题。图4 给出了已识甲骨字和未识甲骨字的C 值。需要注意的是,在计算C 值时,如果分子和分母其中一项为0,不计算此字的C 值。通过筛选,共得到已识甲骨字1 397 个,未识甲骨字3 367 个。从图中以看到,对于已识甲骨字,有2.79%(共39 个,见表1)的甲骨字C值小于0,即这些甲骨字与未识甲骨字连接紧密;有0.21%(共3 个)的C 值等于0,说明这些甲骨字与已识甲骨字和未识甲骨字连接的权重相等。而C 值较大(大于4)的甲骨字仅占到所有已识甲骨字的5.94%(共83 个),大部分(91.05%,共1 272 个甲骨字)已识甲骨字的C 值分布在0 ~4。
通过以上分析可知,已识甲骨字并没有较强的闭合性,可以为未识甲骨字语义的预测提供重要的可用信息。对于未识甲骨字,C 值小于等于0 的共有234 个(见表1),而C 值分布在0 ~4 的共有2 863个(占85.03%)。与已识甲骨字连接紧密而与未识甲骨字连接稀疏(即C 值大于4)的未识甲骨共有270 个。与已识甲骨字一样,未识甲骨字的闭合性较弱,这为预测未识甲骨字的语义提供了重要的理论和数据依据。特别是对于具有较大C 值的270 个未识甲骨字,是需要破译的首要目标。

图4 已识和未识甲骨字的C 值Fig.4 The values of C of known and unknown oracle characters

表1 不同C 值的已识和未识甲骨字的个数和占比Table 1 The number and percentage of known and unknown oracle characters on different values of C
闭合性为首先预测那些未识甲骨字的语义提供了重要的数据支持,因为这些未识甲骨字与已识甲骨字紧密相连,且在不同的拓片中多次出现,并构成相对完整的语义单元。更进一步,对已识甲骨字(连接性甲骨字和非连接性甲骨字)进行模糊分类。连接性甲骨字在拓片中起“连接”的作用,如“卜”字的出现,表明此拓片用于占卜,对于预测未识甲骨字的语义提供的信息较少。另外,“卜”字在所有的拓片中共出现了至少20 375 次[13],能够提供可用信息非常少。由于这些甲骨字有较高的U 值,因此,去掉U 值排名前100 的甲骨字,然后计算已识和未识甲骨字的闭合性C。图5 给出了已识和未识甲骨字的闭合系数。从图5 中可看到:(1)没有出现有较高C值的已识甲骨字,(2)没有出现具有较高|Ci|值的未识甲骨字。因此,已识和未识甲骨字都不具有很强的闭合性,可以利用已有的拓片数据信息预测未识甲骨字的语义。
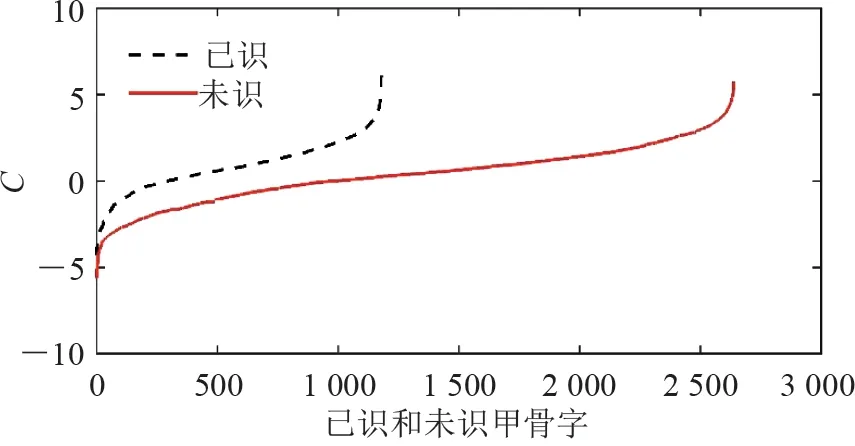
图5 筛选连接性甲骨字后的已识和未识甲骨字的闭合系数Fig.5 The closed coefficient of known and unknown oracle characters by selecting linked oracle characters
3.4 未识甲骨字的场景语义预测
通过对未识甲骨字的特征分析可知,如果一个未识甲骨字的介数中心性、强度和度以及闭合系数有较大的值,那么此字的场景语义最有可能被破译。依据此结论,对未识甲骨字(标记为P,此字的介数中心性、强度和度以及闭合系数值较大)(异形体为,,)的场景语义进行预测。为了充分利用甲骨拓片的上下文信息,首先,对未识甲骨字P 的前置甲骨字B 出现的次数FB(式(8))、间隔前置甲骨字Bi出现的次数FBi(式(9))、后置甲骨字A 出现的次数FA(式(10))、间隔后置甲骨字Ai出现的次数FAi(式(11))进行计算。

式(8)~(11)中,TN表示所有甲骨拓片的个数,当wPB和wPA值为10 时(可由式(1)和(2)推理),γB和γA取为1,否则取为0。当wPBi和wPAi值为时(可由式(1)和(2)推理),γBi和γAi取为1,否则取为0。
然后,对FB、FBi、FA、FAi进行排序;第3,在筛选B、Bi、A、Ai为已识甲骨字的情况下,计算FB、FBi、FA、FAi的值。通过计 算发现,当FB为1 889(最大值)时,甲骨字B 为(简体字为受),说明甲骨字P与B 经常联合出现。根据甲骨文语法知识[28],甲骨字B 后应与名词联合使用。因此,推测未识甲骨字P 的词性应为名词。进一步对FA进行分析,当FA为最大(1 676)时,甲骨字A 为(简体字为于)。同样,根据甲骨文语法知识知,的前面经常与名词连用,因此,推测未识甲骨字P 词性为名词。
为了预测未识甲骨字P 的场景语义,对FB值的前置甲骨字B 做进一步分析,当FB=531 时,前置甲骨字B 为(简体字为牢)。字在甲骨文系统中用来表示圈起来饲养家禽[29]。那么,字是否与家禽以及一些动物有关?接下来,通过扩大P 字的搜索范围,即计算P 的后置甲骨字FA和间隔后置甲骨字FAi。当FA=FAi=455 时,P 字后置甲骨字为一(简体字为一)、间隔后置甲骨字为(简体字为牛);不仅如此,P 字也经常(FA=241)和甲骨字二(简体字为二)共同出现。P 字和一定数量的家禽共同使用(或出现),由此推断P()字为参与“祭祀”场景的描述。为了验证推断的正确性,进一步对未识甲骨字P 的间隔后置甲骨字进行分析,当FAi=336时,P 字和甲骨字(简体字为祖)共同出现。通过分析,预测未识甲骨字P 用于“祭祀祖先”场景语义的描述。不仅如此,未识甲骨字P 和后置甲骨字(简体字为疾)联合使用(FA=226)。以上情况说明,未识甲骨字主要用于描述“祭祀祖先”的场景,并在祭祀的同时祈祷先人保佑后人健康。
4 结 论
甲骨文是地下出土中我国最早的成文古典文献遗产,是汉字汉语的鼻祖,承载着真正的中华基因。对未识甲骨字的考释是甲骨学研究的最主要内容,可以广泛推动甲骨学的发展。然而,现有计算机技术辅助的研究方法无法进一步破译未识甲骨字的语义。为了破译未识甲骨字的语义,本文以甲骨拓片为基础数据,首先,通过抽象甲骨文字在拓片中的上下文语境构建甲骨字网络;然后,在甲骨字网络之上,分析未识甲骨字的重要性、信息丰富度、闭合性等特性,为预测未识甲骨字的场景语义提供理论依据;最后,根据网络特性和甲骨拓片的上下文语境预测未识甲骨字的场景语义。本文的研究可为用计算机技术破译未识甲骨字的语义提供研究思路。但尚有很多问题需要改进:第1,构建的甲骨字网络不完备。现有的甲骨拓片约有15 万片,而文中仅使用了约7.1 万片。甲骨拓片的不足会严重影响甲骨字网络的完备性,而甲骨字网络的不完备会降低语义预测的正确率;第2,使用文中方法预测的未识甲骨字语义是模糊的,还不能精准预测其语义,即找到与现代汉字的映射关系;第3,提出的未识甲骨字预测方法是半自动化的计算机辅助方法。甲骨字与甲骨字之间的语义推理需要甲骨学家、古文字学家的参与,无法智能地完成场景语义的预测。这种半自动化的计算机辅助预测模型并不理想。
为了克服文中方法的缺点,今后的研究将从以下两个方面对计算机辅助的甲骨字语义预测做改进。首先,收集文中未使用的甲骨拓片(约8 万片),建立完备的甲骨字网络,提高语义预测的正确率。其次,利用机器学习、人工智能等最新算法,设计更加智能的未识甲骨字语义预测模型,如神经网络及其衍生方法:卷积神经网络(conventional neural network, CNN)[30]、递归神经网络(recurrent neural network, RNN)[31-32]、图 卷 积 神 经 网 络(graph conventional neural network,GCNN)[33]等。其 中递归神经网络及其衍生的长短期记忆网络(long short term memory network, LSTM)[34-35]由于其良好的记忆功能已被广泛应用于自然语言处理,特别是语言模型中的上下文残缺词的推理;而图卷积神经网络在处理图(graph)(或称为网络)数据方面具有高效性能,使其成为神经网络研究领域最活跃的分支[36]。在今后的研究中,笔者将使用图卷积神经网络处理甲骨字网络(或称甲骨字图),并结合长短期记忆网络标注未识甲骨字的语义,进而减少预测模型的人工干预,推动计算机技术辅助的未识甲骨字语义预测的进展。
