基于改进多尺度排列熵的列车轴箱轴承诊断方法研究
2020-04-16李永健刘吉华张卫华
李永健 宋 浩 刘吉华 张卫华 熊 庆
(1.五邑大学 轨道交通学院,广东 江门 529020;2.西华大学 汽车测控与安全四川省重点实验室,四川 成都 610039;3.西南交通大学 牵引动力国家重点实验室,四川 成都 610031;4.西华大学 汽车与交通学院,四川 成都 610039)
轴箱轴承作为转向架的关键零部件,将列车全部负荷经转向架承受并传递至轮轨,使各车轴、车轮承重均匀分配。随着列车速度不断提高,轴承等主要零部件在高速工况下的服役环境变得更加恶劣,容易发生故障,为行车安全带来重大隐患。因此,在列车复杂工况下及时检测轴箱轴承的早期故障成为走行部状态监测研究的热点和难点。
列车实际运营中对轴箱轴承的主要检测方式为车载轴温报警装置[1],轨边声学诊断系统(TADS)[2]以及基于振动的共振解调技术[3]。轴温报警相对滞后而不能及时发现轴承早期故障,轨边声音诊断无法在列车运行过程中实时监测,基于振动信号的诊断技术由于克服了上述缺点而得到了广泛应用。一般而言,振动信号的分析方法主要有基于峰值、有效值等指标的时域分析和基于傅里叶变换等的频域分析。然而,由于转速不恒定等因素引起振动信号呈现出较强的非线性和非平稳性,为了描述频率随时间的变化历程,基于小波变换、希尔伯特黄变换以及温格尔威利分布等的时频分析方法应运而生[4-6]。这些方法由于各自的局限性,难免产生不稳定的结果。近年来,随着非线性分析技术的不断发展,不同的非线性特征提取方法被用于旋转机械的故障诊断。熊庆等[7]研究了多重分形趋势波动分析特征参数的敏感性和稳定性,并成功运用于滚动轴承的定量故障诊断;Yan等[8]将近似熵用于机械设备的健康监测;Li等[9]用层次模糊熵提取滚动轴承的故障信息,结合改进支持向量机分类器建立了智能故障诊断系统;Wu等[10]将多尺度排列熵应用于滚动轴承的故障诊断。
研究者Bandt等[11-12]基于相邻值比较思想提出了排列熵技术,用以度量时间序列的复杂性参数,该方法尤其适用于处理含噪信号。随后,巴基斯坦学者Aziz和Arif经由粗粒化处理建立了多尺度排列熵算法[13],较之于单一时间尺度下的排列熵,它能够进一步挖掘蕴藏于时间序列中多个尺度下的信息,更加全面的表征系统的随机性和复杂性,在脑电波信号的应用研究中取得了良好的效果[14]。此外,多尺度排列熵技术还被用来刻画旋转机械的健康状态[10],实验结果显示,针对轴承的正常状态以及不同组件的损伤,多尺度排列熵方法均能够通过原始振动信号有效表征。然而该方法仍然存有缺陷:在粗粒化处理后,时间序列的长度会减少,而数据点的多少会影响熵值的计算精度以及稳定性,若信号中包含的数据点较少,熵值误差会显著增加,尤其当原始信号为短时的时间序列时尤为明显。为了提高经典多尺度排列熵算法的稳定性和精度,本文从粗粒化过程着手,对传统方法进行完善,提出了改进的多尺度排列熵。新方法有效解决了在处理较短的含噪信号时存在的熵值突变、精度低的问题,可以得到稳定性好、精度高的排列熵值。
因此,本文将改进的多尺度排列熵用于提取轴箱轴承复杂振动信号中隐含的故障特征信息,同时为了降低提取特征中的冗余信息和减小特征维数,马氏距离[15]被用来选取包含最多敏感信息的故障特征。最后,与遗传算法优化的支持向量机(GA-SVM)[16]相结合,对轴箱轴承的不同故障进行智能分类。实验结果表明,本文提出的基于改进的多尺度排列熵、马氏距离以及GA-SVM的故障诊断方法能够有效对轴箱轴承不同位置故障进行精确识别。
1 改进多尺度排列熵
1.1 多尺度排列熵
多尺度排列熵将粗粒化过程与排列熵相结合,通过求取粗粒化时间序列的熵值得到不同时间尺度下的计算结果,可以挖掘到隐藏在时间序列中更丰富的特征信息,从而精确反映出系统的变化情况,比原始单一尺度[11]获取更多的状态量。多尺度排列熵技术的计算主要由两部分组成,详细过程如下[11-13]:
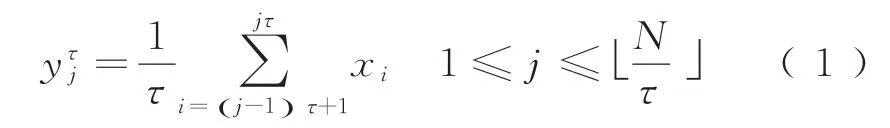
式中:τ为尺度因数,取正整数为小于或等于a的整数。
(2)对粗粒化后的时间序列计算排列熵PE值,即可得到多尺度排列熵MPE
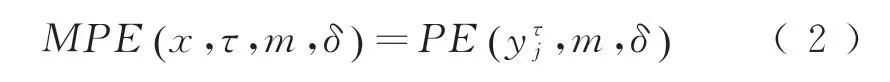
式中:m为嵌入维数;δ为时延参数。
在应用研究中,由上述2个步骤计算的多个尺度下的PE值虽然效果良好,但是依然存在缺陷:①在粗粒化过程中,对每一数据点的处理并非完全一致,即MPE不是对称的,这会导致PE值突变。如尺度因数取3时,其粗粒化过程见图1。理想情况下x3和x4与x2和x3处的计算模式应完全相同,但是从图1中发现x1、x2、x3与x4、x5、x6于x3处断开,造成x3与x4存在断点而PE值不稳定。②求取排列熵时信号的数据点越多结果越稳定,然而多尺度分析会降低时间序列的长度,随着尺度因数的增大,用于计算PE的信号长度越短,这样会不断增加熵值误差,使得对系统的表征精确性降低。
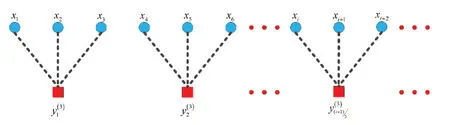
图1 尺度因子等于3时的MPE过程示意
1.2 改进多尺度排列熵(MMPE)
为了完善和提高传统多尺度排列熵的性能,本文从粗粒化步骤入手,建立改进多尺度排列熵。仍然以尺度因数3为例(见图2),区别于原有算法的是新方法中同一时间尺度τ下,经粗粒化处理后可获得τ组时间序列,从而解决“断点”处的突变问题,而经典算法中只有一组时间序列。数学过程为:
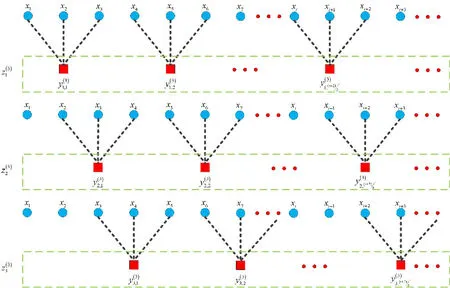
图2 尺度因子等于3时的MMPE方法示意
(1)对给定信号以改进粗粒化过程进行处理,得到τ组新的时间序列

(2)对于每一组新的粗粒化时间序列z(τ)i|(i=1,2,…,τ),求取它的PE值,然后计算τ个时间序列熵值的平均值,即可得到时间尺度τ下的排列熵,具体为

(4)MMPE的熵值大小实则是系统内在变化的一种外在表现,由系统产生的信号说明了其本身的随机性和复杂性,熵值越小表明信号越规则,反之则说明系统较无序和杂乱。
2 MMPE和MPE算法比较分析
2.1 参数选择
由多尺度排列熵的定义可知,在计算时需要设置4个参数:N、m、τ、δ。一般而言,嵌入维数取值范围为3≤m≤7,当m≤2时,由于重构时间序列中蕴含的重要信息量太少,将会使算法的有效性大打折扣;而m值过高,又会增加计算量,且对时间序列的细微变化也难以描述[8],鉴于此该参数取m=4。此外被分析信号数据点的多少将会影响PE值的精度,信号越长熵值精度越高,然而太多的数据点在计算时会更耗时,若数据点太少则不能精确反映系统的状态变化,文献[17]建议取N≥5m!,此处取N=2 048。由于时延参数对最终结果的影响微乎其微,为了方便求解,给定δ=1。根据研究需要,时间尺度选择τ=20。
2.2 仿真对比分析
为了说明MMPE的优点,通过仿真信号高斯白噪声和1/f噪声进行分析研究。2种信号长度均为5 000个数据点,时域图和频谱图见图3。从图3中可知,高斯白噪声比1/f噪声更加具有复杂性。然后用MMPE和MPE算法分别求得2种信号的排列熵值,见图4,从图4中可以看出,在不同尺度下MMPE方法所求熵值较之MPE方法稳定;另一方面随着尺度因数的增大,排列熵值在单调递减。为了分析改进方法的误差,分别对高斯白噪声和1/f信号各取100个样本,求取尺度1~20下的PE,计算每一尺度的熵值误差,见图5。通过分析图5可以证实,从尺度1~20下改进算法比传统的MPE技术得到更加精确结果,误差小且抑制了突变的发生,由此证明MMPE技术具有良好的稳定性。

图3 高斯白噪声和1/f噪声时域与频谱
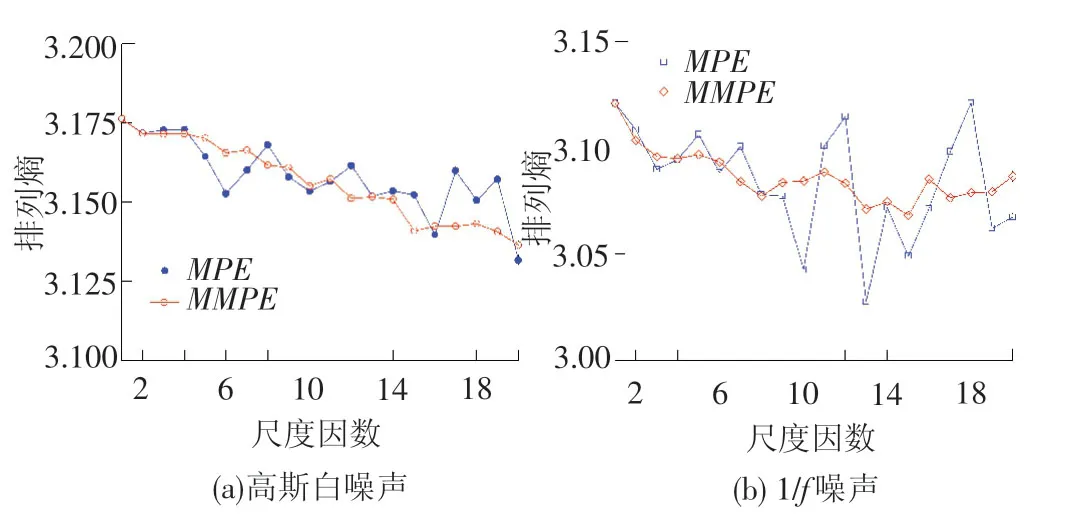
图4 高斯白噪声和1/f噪声排列熵
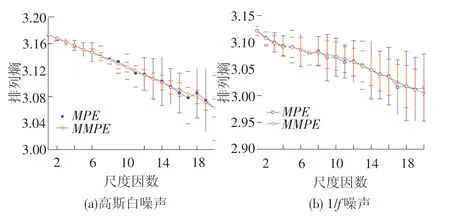
图5 高斯白噪声和1/f噪声排列熵误差
3 损伤检测方法
轴箱轴承是列车上最关键的旋转零部件之一,一旦轴承内部有组件发生缺陷,都会产生不同程度的振动脉冲信号。由于轴箱处于复杂多变的运行环境,各个部件的频率容易调制,引起加速度信号表现出相当的复杂性,而且在高速、低速和加减速时轴承的振动幅值、频率皆呈现出强烈的非稳定性。此处基于非线性的MMPE技术分析非稳定的轴箱信号,计算不同时间尺度下的排列熵信息以表征轴承的健康状态。然而,所有尺度下的熵特征既蕴含了关键的轴承状态信息,同时大量的不相关信息也被一并提取。如果所有的熵值作为诊断向量,将会导致识别精度的下降而且更加耗时。为了提高效率和识别率,对特征向量加以筛选。马氏距离[15]作为最常用的特征选择方法之一,在诸多领域的研究中被广泛采用。顾名思义,该方法主要以不同特征间的马氏距离对所有特征进行排序,进而评估不同时间尺度下的熵值对轴承状态的区分能力。因此,本文通过马氏距离算法选取区分性能最优的熵特征为诊断向量,结合经典的SVM分类识别技术,对轴箱轴承实现智能化的损伤检测。主要分为4个步骤:
Step1应用MMPE方法计算不同健康状态下的多尺度排列熵值。根据本文2.1节中分析给定相关参数:N=2 048,δ=1,m=4,τ=20。
Step2通过马氏距离算法评估所有时间尺度下的熵特征,选取排序最前的5个熵值重新组建诊断向量。
Step3在新特征向量中,任意选取50%样本用于训练分类模型,剩余50%样本进行分类测试。
Step4由训练样本得到SVM分类方法的关键参数,由测试样本完成轴承不同健康状态的智能分类,通过诊断精度识别轴承的运行状态。
4 试验验证
为了对文中提出的故障诊断方法进行有效性验证,借助于客车检修基地的轮对跑合试验台完成了不同健康状态轴箱轴承的跑合试验以便采集加速度数据。试验平台结构示意见图6(a):整个轮对由安装于下方的摩擦轮驱动,轮对两侧分别安装2个轴箱轴承,为了便于比较,一个轴承为损伤状态,而另一个保持健康状态,轮对由相应的夹具固定,静态力加载通过升高下方整个基座来实现,试验时施加20 k N的径向力;试验装置实物图见图6(b)。
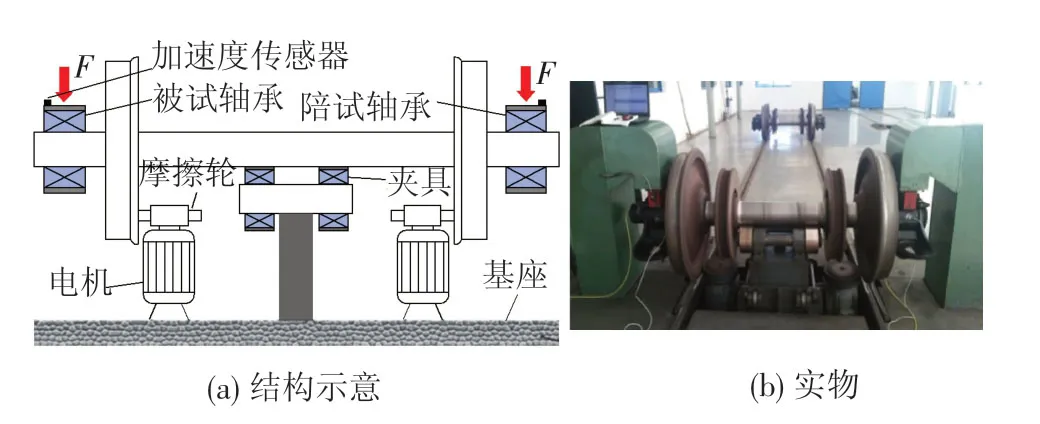
图6 实验平台结构示意及实物
对于轴箱轴承而言,采集信号时最好将传感器置于外圈承载区,因为此处产生的冲击更强烈。从图6可以发现,该试验装置的承载区处于轴箱12 点钟位置,但是该位置被用来加载静态力。因此为了尽可能采集到包含重要信息的加速度信号,传感器应安装在接近承载区位置,见图7。

图7 传感器安装位置
试验用轴承为客车轴箱轴承,是一种型号为NJ(P)3226X1的双列圆柱轴承。分别在轴承的内圈、滚动体和外圈上通过电火花方法产生划痕缺陷,损伤尺寸宽度为0.1 mm、深度为0.43 mm。试验过程中,车轮转速恒定为230 r/min,收集数据时选用25.6 k Hz的采样率。不同状态下轴箱振动信号时域图见图8,不管振动幅值还是冲击周期,从图8中无法判断轴承的运行状态,这是由轴箱运行工况的复杂性所致。
首先利用实测信号评估该方法对干扰噪声的鲁棒性。以健康状态的加速度信号为基础,分别添加大小各异的高斯白噪声,使得合成信号的信噪比SNR依此为20、25、30、35 d B。然后对不同信噪比的新信号求取多尺度熵值,曲线结果见图9。从图9中可以发现,在大部分时间尺度下排列熵值并未发生突变,呈现出了良好的稳定性和一致性,说明MMPE技术对噪声具有优越的抗变换性。
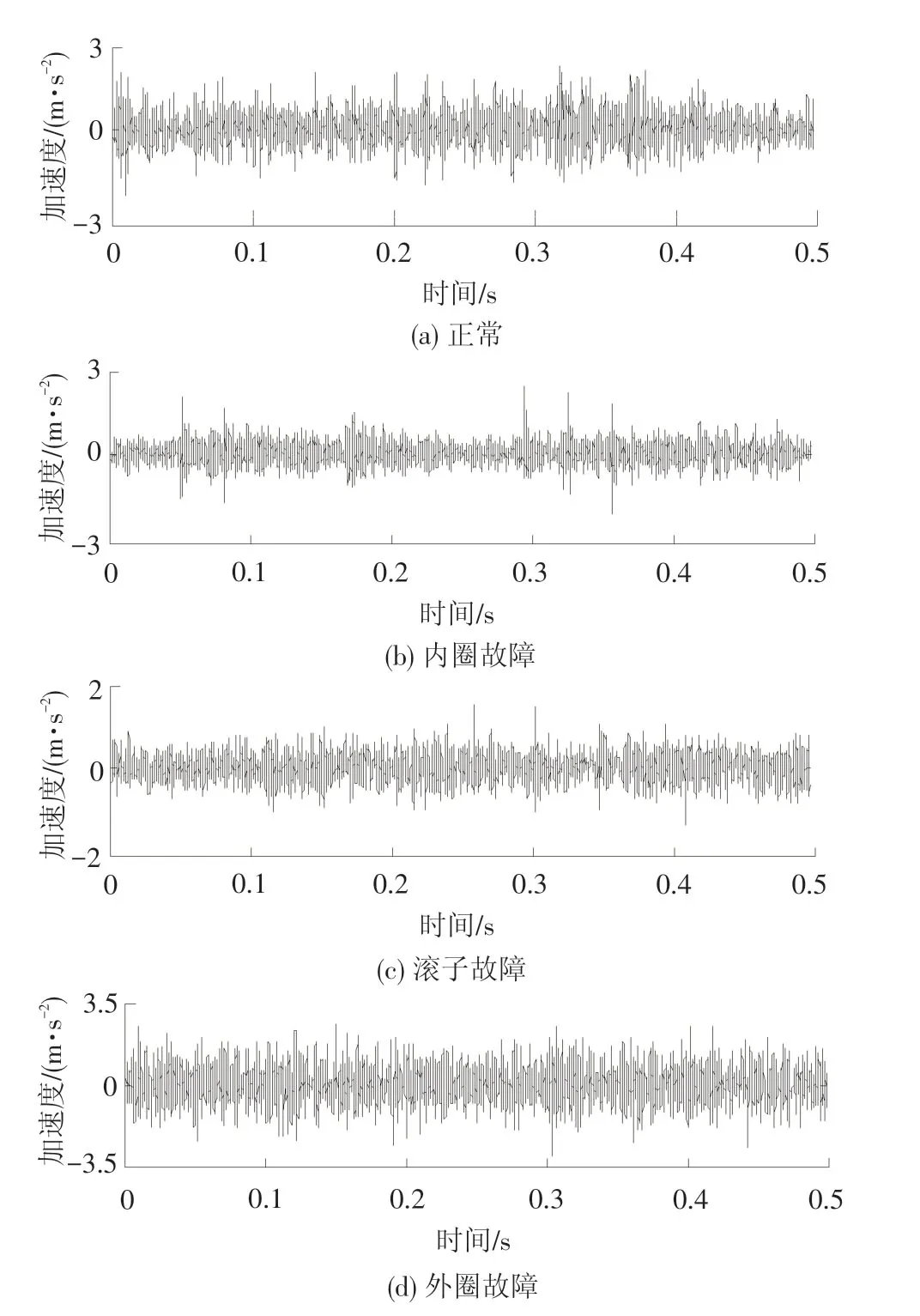
图8 不同健康状态轴箱轴承的时域波形
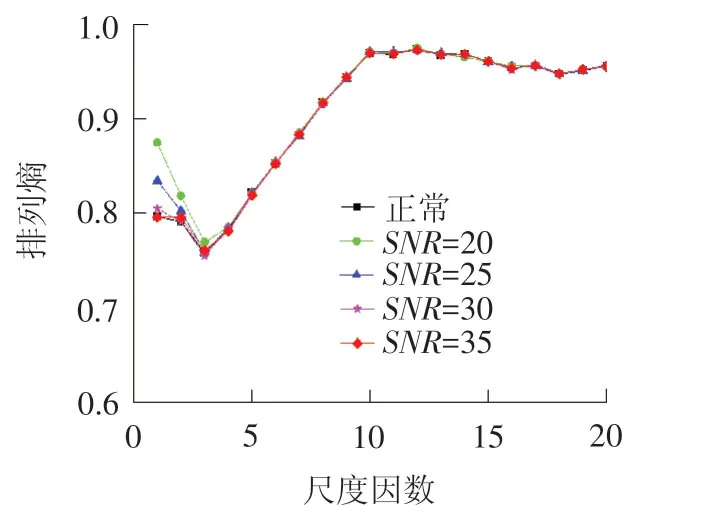
图9 正常状态轴承信号在不同信噪比SNR下的排列熵
其次,对健康状态以及3种损伤(内圈、滚子和外圈)的加速度信号应用MMPE方法完成熵值提取。分别计算不同健康状态下的多尺度熵值,并绘制曲线,见图10。通过观察可发现,外圈损伤的熵特征值在不同尺度下呈现出不断上升后略微下降的趋势,而健康状态和另外2种损伤均表现为先递减、递增和下降的特征,由此不仅充分体现了轴承运行工况的复杂性,而且表明原始单一尺度下的熵值在刻画轴承运行状态时存在的局限性。
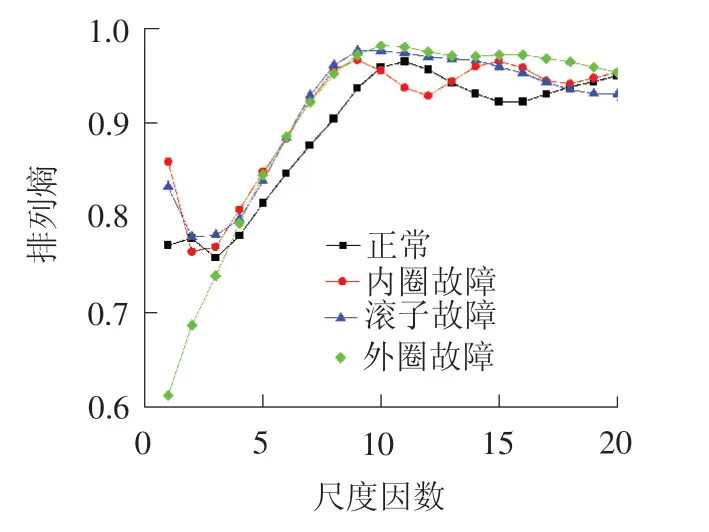
图10 不同状态轴箱轴承的排列熵
最后,将正常状态和其他3种故障状态轴承分别取30个样本,合计120个样本。对每个样本提取MMPE熵值,建立原始特征集。将所提取的特征集使用马氏距离算法进行排序,最能表征不同轴承故障状态的特征向量排在前面,评估后最前面的5组熵值被用来重新组建智能故障诊断的新向量,其中,任意15个样本用来训练分类模型,剩余15个样本进行识别测试。经过遗传算法优化的SVM分类器(核函数为径向基函数)进行训练、测试,最终得到的故障分类结果见表1。

表1 本文方法测试分类精度 %
从表1可知,文中提出的故障诊断方法对不同类型故障的识别率达到了98.33%,除了一个内圈样本被误分类到滚动体故障外,其余样本均被正确识别,充分证明了该方法在轴箱轴承诊断中的有效性。
为了与传统的排列熵算法对比,现对相同的120个振动信号样本求取MPE值,参数设置与MMPE方法一致,从提取的原始特征集中选择前5个尺度下的故障特征进行SVM分类器的训练和测试,参数设定与前文一样。测试结果见表2,识别率下降到了95%,有2个正常状态被分到了外圈故障,一个滚子故障被误分为内圈故障。该比较结果说明了文中改进方法的优越性。

表2 MPE方法提取状态特征测试分类精度 %
最后,我们考虑不使用马氏距离方法进行特征优选,而是随机选取5个不同尺度下的MMPE故障特征向量作为诊断特征集。随机选择的5个尺度分别为1、5、7、10、12,在与前文相同参数设置下,将训练和测试样本输入SVM分类器。最终识别结果见表3,测试样本中有2个滚子故障的样本被分类到内圈故障,此时正确识别率为96.67%,较之文中所提方法低1.66%,表明使用马氏距离算法进行特征优选的必要性。
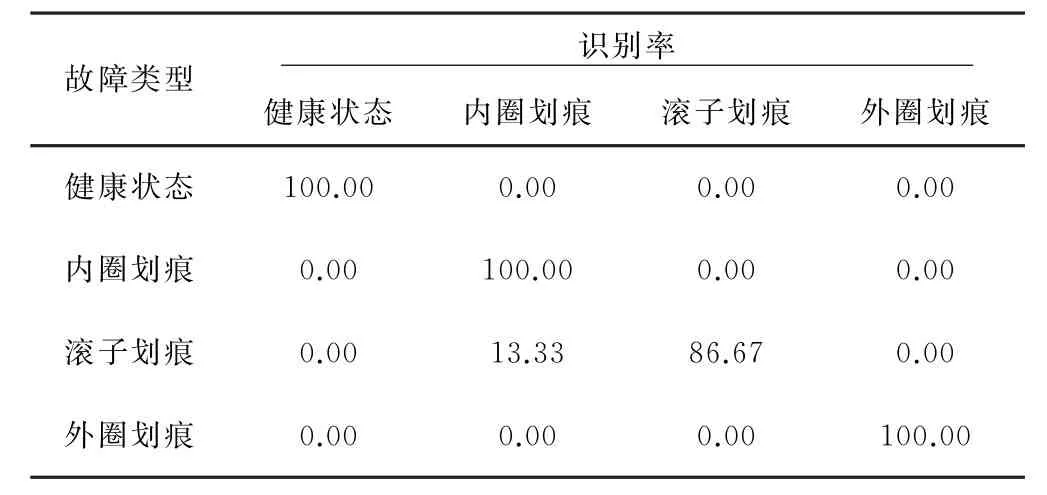
表3 随机选取状态特征测试分类精度 %
5 结束语
轴箱轴承在列车运行过程中发生故障时,处于复杂服役环境下会表现出多种随机性和动力学行为。本文对基于非线性的MPE方法做了必要改进,提出了MMPE方法。与2种仿真信号进行比较,得出了更为稳定的结果。随后将该方法应用于客车轴箱轴承的实验数据特征提取,结合马氏距离和基于遗传算法优化的支持矢量机,建立新的轴箱轴承故障诊断方法,实现了故障的正确分类。通过比较分析发现文中所用方法的优越性,为智能化故障诊断提供了一种新的思路。笔者后续将会继续对基于熵的非线性分析方法进行深入研究,以期能够运用于工程实际,保障列车安全运行。
