利用位置增强注意力机制的属性级情感分类*
2020-04-15张周彬梁俊葛杨嘉林
张周彬,相 艳+,梁俊葛,杨嘉林,马 磊,2
1.昆明理工大学 信息工程与自动化学院,昆明 650504
2.昆明理工大学资产经营有限公司,昆明 650051
1 引言
情感分类,也称观点挖掘,是自然语言处理(natural language processing,NLP)中一项重要的任务[1-2]。粗粒度情感分类是对文档级(篇章级)或句子级的评论文本进行情感极性判断,而细粒度情感分类是对评论文本中的实体属性进行情感极性的识别。例如,对于评论“The food was very good,but the service at that restaurant was dreadful.”,细粒度的情感分类需要识别出属性“food”的情感极性是正向的,而属性“service”的情感极性是负向的。不同属性的情感极性不仅依赖于上下文的情感信息,还依赖于特定属性的语义信息[3]。因此,对于特定属性的情感极性识别应该将上下文和属性相结合,充分利用属性和上下文的依赖关系。
解决属性情感分类的传统机器学习方法包括语法规则[4]和支持向量机(support vector machine,SVM)的方法[5],这些方法大多需要大量人工特征,包括情感词典[6]、解析树[7]等。这类方法的性能很大程度上受限于人工特征的质量。Hu 和Liu[8-9]提出了针对不同商品评论的情感分类方法。Qiu 等人[10]利用属性抽取和构建情感词典的方法进行属性情感分类。
近些年,随着深度学习的发展,神经网络在NLP中得到了广泛的应用。越来越多的学者提出利用深度学习技术。前期一些学者提出利用深度学习和传统的方法相结合处理属性级情感分类的思路。Nguyen和Shirai[11]提出基于循环神经网络和句法分析树的方法进行属性情感分类。Dong 等人[12]提出一种自适应的循环神经网络应用于文本情感分类。这些方法均加入了深度学习的方法进行特征提取,相比于传统的方法取得了比较好的性能,但是它们需要借助情感词典、句法分析树等方法的辅助,且网络结构相比比较复杂。为了克服这些缺陷,大量研究人员对深度学习技术进行了深入研究,仅利用递归神经网络、卷积神经网络(convolutional neural networks,CNN)等学习语义信息,这些模型在情感分类上也取得了比较好的效果[13-14]。Chen 等人[15]提出使用卷积神经网络进行属性情感信息的提取。Xue 等人[16]提出基于卷积神经网络和门控机制的模型进行属性情感信息的提取。Ruder等人[17]提出一种分层双向长短时记忆神经网络模型,引入词语之间和句子之间的语法规则技术进行属性级情感分析。Wang 等人[18]将上下文中每个词和从句的重要程度结合起来,提出一种具有词语级和句子级联合训练的分层注意力机制网络结构。支淑婷等人[19]提出融合多注意力属性和上下文的双向长短时记忆神经网络(bi-long short term memory,Bi-LSTM)的方法,在Bi-LSTM 的不同位置加入不同类型的注意力机制,从不同角度抽取情感特征。Ma 等人[20]提出将上下文和属性分别建模,然后利用交互式注意力网络结构分别学习上下文和属性的有效表示。Tang等人[21]使用两个LSTM(long short term memory)网络分别从属性词的左侧和右侧分别建模,捕捉属性的上下文信息。Tay等人[22]通过对上下文和属性分别建模捕捉它们之间的关系,然后送入神经网络中自适应地捕捉属性词和它的情感词。以上方法均取得比较好的结果,同时验证了LSTM 网络和注意力机制对属性级情感分类的有效性。
本文基于LSTM 网络和注意力机制进行了研究。Tang等人[23]提出目标相关长短时记忆神经网络(targetdependent long short term memory,TD-LSTM)模型和目标连接长短时记忆神经网络(target-connection long short term memory,TC-LSTM)模型。TD-LSTM模型是通过Bi-LSTM 网络对特定属性的上下文信息进行独立编码,然后连接前向LSTM 网络和反向LSTM 网络,最后隐藏层的输出的特征向量作为最终的表示,进行属性情感分类。TC-LSTM 网络则是在TD-LSTM 模型基础上的改进,将属性词向量矩阵与句子的上下文词向量矩阵进行拼接作为模型的输入,让模型学习到更加有效的属性情感特征。这两个方法都有很大的局限性,仅仅借助LSTM 网络对属性的情感特征进行提取。Wang 等人[24]提出基于注意力的长短时记忆神经网络(attention-based long short term memory,AT-LSTM)模型和基于属性嵌入的注意力网络(attention-based long short term memory with aspect embedding,ATAE-LSTM)模型。这两个模型是在Tang 等人提出的模型基础上的改进,它引入了注意力机制去选择性地关注与属性密切相关的内容信息。AT-LSTM 模型是在上下文隐藏层的输出特征向量上拼接属性词向量,然后利用注意力机制让模型选择性关注与当前属性密切相关的内容信息,从而生成更加准确的属性情感特征向量。而ATAELSTM 模型则是在AT-LSTM 输入层引入属性连接组件,将属性词向量连接到输入词向量中,让模型能够在Bi-LSTM 网络编码过程中学习更多与属性相关的语义特征信息。Ma 等人[20]提出交互式注意力网络,使属性和上下文互动学习获得更有效的属性情感特征。以上模型进一步验证了LSTM 网络和注意力机制对属性情感分类的有效性,但是它们均忽视对属性单独建模和属性对于上下文监督的作用。因此,本文提出位置增强注意力机制网络模型,将LSTM 网络和注意力机制相结合构建模型,且对属性和上下文分别独立建模,然后利用属性去监督上下文让模型生成更加准确的属性情感特征向量。
到目前为止,大部分的模型都忽视属性词对属性情感分类的作用,同时忽视了属性与上下文中的相对位置关系。事实上,属性的情感极性主要由其相邻词来表达。越接近属性的词语越可能表达它的极性。例如评论“The price is reasonable although the service is poor.”中,属性“price”的情感极性表达的词语是“reasonable”,而不是相隔较远的“poor”。根据语言规则,上下文和属性之间的位置关系在属性级情感分类建模中有着重要的意义。根据这一特征,本文提出一种基于位置增强注意力(position-attention,P-ATT)的属性级情感分类模型,以下称为P-ATT。该模型的主要创新之处为:(1)以属性词为中心,计算上下文中其他词和属性词之间的相对位置,并在上下文的输入层和隐藏层分别加入该相对位置向量,从而更好地表征上下文中每个词对属性的重要程度;(2)利用两个LSTM 对上下文和属性词独立编码,利用编码后的属性词向量监督上下文注意力权重的计算,该权重对最终的情感分类起到关键作用;(3)对上下文和属性分别单独建模,并利用属性去监督上下文,生成与属性密切相关的属性情感特征。本文模型在SemEval 2014 Task4 的数据集上进行了二分类和三分类的实验,验证了模型的有效性。
2 基于位置增强注意力的模型
2.1 属性词和上下文相对位置的计算
在属性级情感分类任务中,上下文中的单词和属性词之间的相对位置包含着很重要的特征信息,属性附近的词更有可能表达它的情感极性,并且随着相对距离的增大影响越小。例如图1 所示,对于该上下文中涉及的属性1“price”的情感由位置2 的“reasonable”表达,而非位置7 的“poor”表达。属性2“service”的情感由位置2 的“poor”表达。本文对位置信息的处理方法为:(1)检索到属性词所在的位置i,设置该位置的权重为0;(2)以属性词为中心,在属性词的两侧设置两个工作指针,分别依次计算属性词左右两侧单词和属性词之间的相对位置i的值li;(3)将获得相对位置的序列进行处理,计算公式:

Fig.1 Positional relationship between words and aspect in context图1 上下文中单词和属性之间的位置关系
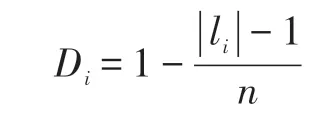
2.2 P-ATT 模型
本文提出的P-ATT 模型如图2 所示,上下文的输入包括位置向量和上下文向量,属性的输入为属性向量,二者分别送入LSTM 网络,得到上下文隐藏层向量和属性隐藏层向量。位置向量拼接至上下文隐藏层向量构成上下文表征,属性隐藏层向量进行平均池化得到属性表示。之后利用属性表示去监督上下文表示计算上下文中每个单词注意力权重,最后该注意力权重与上下文隐藏层向量相乘,得到评论文本最终的有效表示,并利用该表示进行情感分类。

Fig.2 Position-enhanced attention network model图2 位置增强注意力网络模型
2.2.1 上下文和属性的输入
属性级情感分类的任务是判别句子中不同属性的情感极性。对于长度为n的上下文,长度为m的属性,属性可能是一个词也可能是一个短语。实验数据集中的所有单词映射到glove训练的连续、低维度的实值词向量,每个单词wi对应一个确定的词向量vi∈Rd。
上下文不同单词对应的词向量乘上对应的Di,获得位置向量矩阵。利用上下文的索引序列检索出涉及的词向量构成上下文词向量嵌入矩阵。将vp和vc拼接,得到最终的上下文输入。属性词向量矩阵的获取方式和上下文词向量矩阵的获取方式一样。以上的dp dc dt表示向量维度,n、m分别表示上下文和属性的长度。
2.2.2 属性和上下文表示
如图2,属性词向量矩阵vt通过LSTM 网络进行编码,得到属性隐藏层向量。之后对属性隐藏层向量进行均值处理,均值作为属性表示,去参与上下文每个单词的注意力权重的计算,准确抽取上下文中和属性情感特征密切相关的信息。属性隐藏层向量均值定义为:

此外,vp和vc拼接得到上下文的输入,送入LSTM网络进行独立编码,获得隐藏层向量。该隐藏层向量再次拼接vp,得到上下文的表示。
2.2.3 利用注意力机制进行情感分类
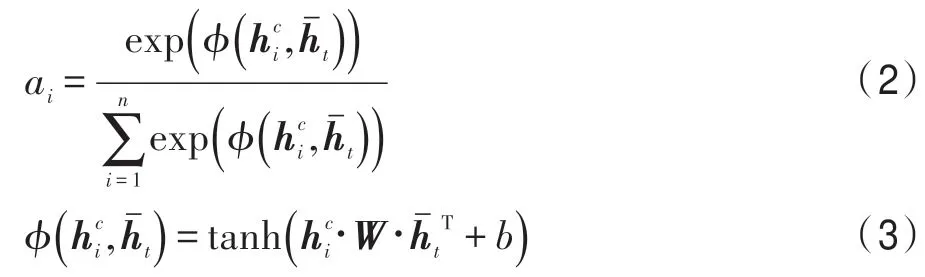
式中,W表示权重,,b表示偏置。之后将注意力权重ai和上下文隐藏层向量进行乘法运算,生成与属性高度相关的特征向量Cf:

将特征向量Cf送入softmax 函数,输出最终特定属性的情感极性。
2.3 模型的训练
在P-ATT 模型中,使用随机梯度下降算法更新所有的参数Θ:

式中,λτ为学习率。
损失函数采用交叉熵代价函数,同时为了避免过拟合,加入L2 正则化,通过最小函数来优化模型,定义如下:
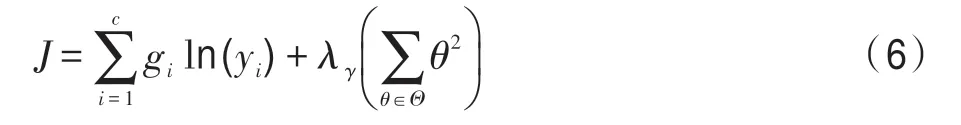
其中,gi表示上下文中特定属性正确的情感类别,yi表示上下文中特定属性预测的类别,λγ表示正则化的权重。
3 实验结果及分析
3.1 实验数据
本文提出的P-ATT 模型在SemEval 2014 Task4 Restaurant 和Laptop 数据集上进行了实验,验证PATT 模型的有效性。SemEval 2014 数据集两个数据集组成:Laptop 评论语料和Restaurant 评论语料。评论有三种情感极性:正向、中性、负向。表1 显示了两个数据集中训练集和测试集样本的数量。

Table 1 Experimental data statistics表1 实验数据统计
3.2 实验参数的设置
实验中,上下文词向量维度dc、属性词向量维度dt、位置词向量维度dp以及LSTM 隐藏层输出的词向量的维度dh都设为300。词向量均采用Pennington等人[25]提出的预训练的glove 词向量,并且所有词汇外的单词都通过从均匀分布U(-0.1,0.1)中抽样来初始化。同时通过均匀分布U(-0.1,0.1)采样给出所有权重矩阵的初始值,并将所有的偏置b初始化为0。通过每个batch_size=128 个样本进行训练模型训练,Adam 优化算法的初始学习率为0.01,Dropout 设置为0.3。
3.3 基线模型
为了全面评估P-ATT 模型性能,本文将其和多个基线模型进行了比较,比较的基线模型有:
LSTM:该模型为参考文献[23]所提出的模型。仅使用一个LSTM 网络对上下文进行建模,然后将隐藏层的输出做均值处理作为最终的表示,并送入softmax 函数计算每个情感标签的概率。
TD-LSTM:该模型为参考文献[23]所提出的模型。通过前向和反向LSTM 网络对特定属性的上下文信息进行独立编码,然后将两个LSTM 最后隐藏层输出的特征向量进行拼接作为最终的表示,进行情感分类。
TC-LSTM:该模型为参考文献[23]所提出的模型。该模型是在TD-LSTM 模型基础上的改进,将属性词向量矩阵和上下词向量矩阵进行拼接作为模型的输入,提取属性更有效的特征进行情感分类。
AT-LSTM:该模型为参考文献[24]所提出的模型。在LSTM 网络中引入属性词向量的注意力机制,能够让模型选择性地关注和属性联系密切的情感信息,从而生成更准确的属性情感特征向量。
ATAE-LSTM:该模型为参考文献[24]所提出的模型。该模型是在AT-LSTM 模型的输入层引入属性连接组件,将属性词向量拼接在上下文词向量中,然后利用双向LSTM 网络和注意力机制学习更多与属性相关的语义特征信息。
3.4 实验分析
本文采用准确率来评估属性情感分类的效果,定义如下:

其中,T是预测正确的样本数,N是样本的总数。准确率度量的是所有样本中预测正确样本的百分比。
3.4.1 与基线模型的比较
本文将6种模型在SemEval2014 Task4 Restaurant和Laptop 两个不同领域语料上进行了实验,表2 给出了6 种模型在属性级情感分析任务中三分类准确率比较情况。
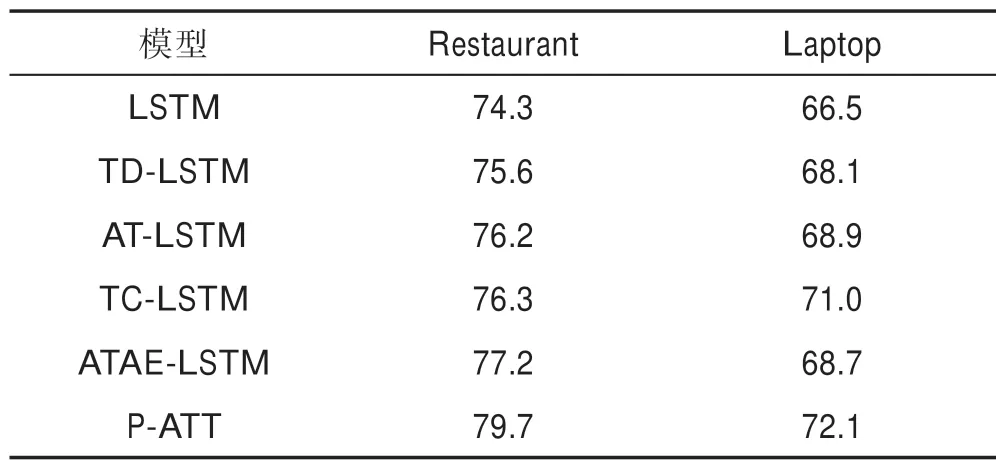
Table 2 Comparison of accuracy among different models and three classification tasks表2 不同模型三分类任务中准确率对比 %
P-ATT 模型在Restaurant和Laptop 两个不同领域的数据集上均取得比较好的效果。模型ATAELSTM 和TC-LSTM 的准确率明显高于模型TDLSTM、AT-LSTM、LSTM。从实验结果和模型框架对比说明,在模型的输入层加入属性词向量可以很好地帮助模型挖掘不同属性和上下文中不同单词之间的语义关联信息,更加准确地将对应的情感信息识别。在Restaurant 和Laptop 语料 上,ATAE-LSTM 模型相比TD-LSTM、LSTM 模型分类准确率分别提升1.6、0.6 和2.9、2.2 个百分点,相比TC-LSTM 模型在Restaurant语料上提升0.9 个百分点,验证了注意力机制在属性情感分类任务中的有效性,同时也说明属性参与上下文的特征提取的必要性。
P-ATT 模型在输入层的上下文词向量矩阵中引入了位置信息,将位置加权的词向量矩阵和对应的上下文词向量矩阵进行拼接,让模型更好地关注上下文中不同位置的词和属性之间的相关程度。然后利用LSTM 网络对上下文和属性分别建模,由于属性信息的有限性和属性与上下文中各个单词信息的相关性,将属性进行均值处理,同时在上下文的隐藏层的输出再次拼接位置信息,强化位置信息的重要程度,最后利用属性去参与上下文注意力权重的计算,更好地挖掘属性和上下文不同词的相关信息,强化重要信息,弱化次要信息。在Restaurant 和Laptop 两个不同语料上,本文提出的模型相比ATAE-LSTM 模型情感分类的准确率提高2.5 和3.4 个百分点,验证了模型P-ATT 的有效性。
为了进一步验证本文提出的P-ATT 模型的有效性,将Restaurant 和Laptop 数据集中的中性样本剔除,只保留正向和负向的样本进行二分类实验,实验结果如表3 所示。

Table 3 Comparison of accuracy among different models and two classification tasks表3 不同模型二分类任务中准确率对比 %
从表3 的结果可以看到,剔除中性样本后,5 个模型属性情感分类任务的性能都有明显的提升。通过观察两个不同领域语料中的中性情感样本很容易发现,中性情感的样本中绝大部分都是对属性的客观描述,而没有表达情感。例如“This is a consistently great place to dine for lunch or dinner.”对于属性“lunch”,只是阐述了一个事实,并没有对属性表达情感。另一个问题是评论的自由性导致评论中对于属性情感的含蓄、潜在表达和句子过于复杂导致模型不能很好地识别情感特征。因此,属性情感分类的难点也是这个原因。通过实验结果的对比,本文提出的模型获得最好的结果,和其他模型中最好的模型ATAE-LSTM 相比,在Restaurant 和Laptop 两个不同领域的语料上准确率分别高出1.2和0.7个百分点,获得了92.1%和88.3%比较好的结果。验证了本文模型能够很好地解决不同领域的属性情感分类问题。
3.4.2 不同位置向量对于属性情感分类的作用
P-ATT 模型在上下文的输入层和隐藏层同时加入了位置信息,为了验证不同的位置信息的作用,本文还与只利用一种位置信息或者不利用位置信息的模型进行比较。第一种称为IP-ATT(input-position attention)模型,只保留上下文输入层处的位置信息,其余部分与P-ATT 一致;第二种称为HP-ATT(hiddenposition attention)模型,只保留上下文隐藏层处的位置信息,其余部分与P-ATT 一致;第三种称为NP-ATT(no-position attention)模型,是将上下文输入层和隐藏层两处的位置信息都去掉。
以上模型在Restaurant 和Laptop 数据集上分别进行了三分类实验,实验结果如图3 所示。P-ATT 模型在两个数据集上均取得最好的结果。相比NPATT 模型,在Restaurant 和Laptop 两个不同领域的数据集上分别提升2.2 和1.9 个百分点。IP-ATT 模型的性能稍低于P-ATT 模型,但是高于HP-ATT 模型。说明在上下文输入层和隐藏层加入位置信息的有效性,同时也说明在输入层加入位置信息的效果相比在隐藏层加入位置信息更加有效。位置信息的加入使得LSTM 网络在训练过程中会结合不同单词和属性之间的位置关系来编码上下文的信息,有利于模型挖掘更加有效的属性情感信息。
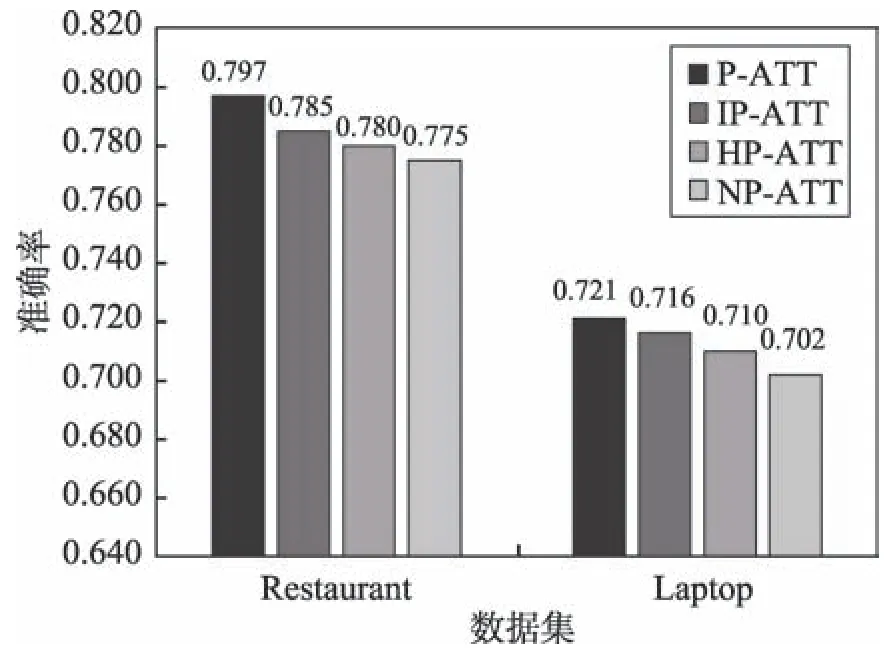
Fig.3 Impact of position information on classification accuracy图3 位置信息对分类准确率的影响
3.4.3 可视化注意力机制
为了更好地理解本文提出的P-ATT 模型对于上下文中不同单词对特定属性情感极性的影响程度,本文从训练的语料中抽取出一个样本,可视化上下文中不同单词的注意力权重。如图4 所示,颜色越深表示注意力权重越大,对属性情感的影响程度也越大。例句“The price is reasonable although the service is poor.”含有两个属性“price”和“service”,它们对应的情感词分别为“reasonable”和“poor”。从热力图很明显地看到,加入位置信息的P-ATT 模型相比NPATT 模型更能准确地识别出上下文中对应属性的情感信息。
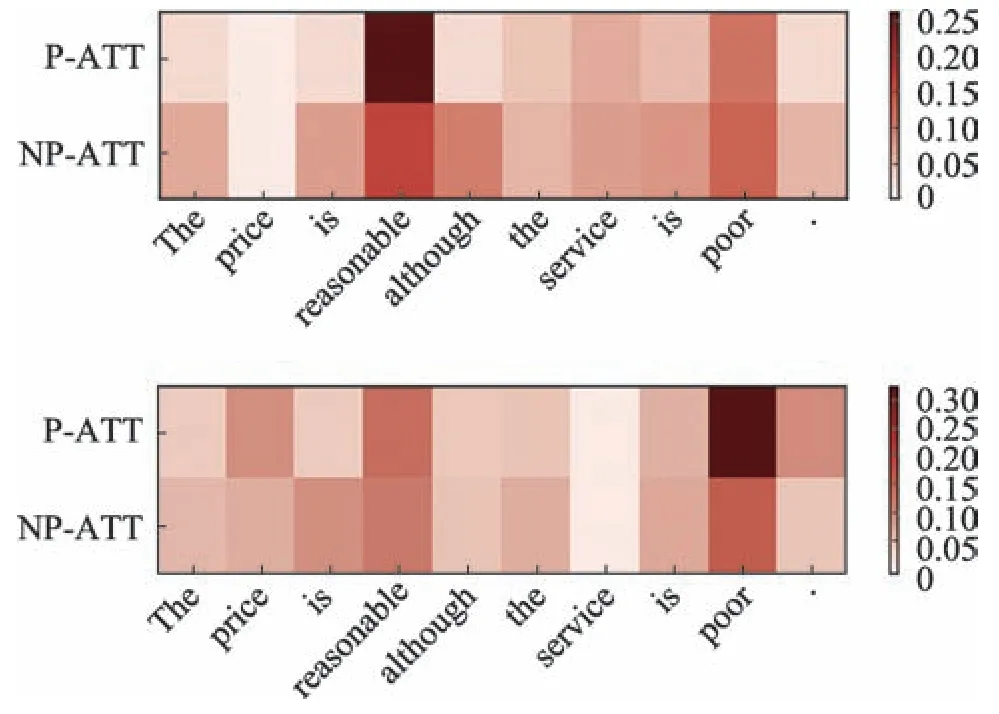
Fig.4 Effect of attention visualization图4 注意力可视化的效果
4 结束语
针对属性情感分类任务,本文提出的位置增强注意力机制模型充分利用属性在上下文中的位置信息和注意力机制提取情感特征。模型在上下文的输入层和隐藏层分别引入位置信息,在第一次位置信息参与下通过LSTM 网络独立编码特定属性的上下文的信息,隐藏层的输出再一次引入位置信息。然后借助属性的均值去计算上下文中每个词的注意力权重,准确地表示出不同单词对属性的影响程度,挖掘上下文中属性的情感信息。在两个不同领域的数据集上进行实验,实验数据表明本文提出模型的有效性,能够很好地解决属性情感分类任务。
本文提出的模型对于属性词序列采用平均化的方式进行处理,没有有效地关注属性中的重要信息,对于模型准确捕捉属性的情感信息有一定的影响,如何提取属性中的重要信息是下一步工作的重点。
