利用随机森林算法对学生成绩评价与预测研究
2020-04-14吴兴惠周玉萍邢海花
吴兴惠 周玉萍 邢海花
摘要:对学生成绩数据的挖掘,寻找成绩数据中潜在的知识和信息,对教学质量的提高有着积极的指导意义。本文提出一种自学习分类算法(随机森林),以某校学生成绩为数据对象,对数据中前期成绩进行分析,预测后期专业课的平均成绩。并对得到的课程重要性排序结果,对学生上课时能够进行针对性的讲解有一定的辅助作用。
关键词:随机森林;成绩分析;预测
中图分类号:TP181
文献标识码:A
文章编号:1009-3044(2020)04-0254-02.
收稿日期:2019-10-25
基金项目:海南省教育科学规划课题:基于一种自学习分类算法的学生成绩评价研究(QJY20181071)作者简介:吴兴惠(1975—),女,海南儋州人,海南师范大学副教授,硕士,从事计算机应用研究。
衡量一个学生掌握在校期间所学的知识的好坏主要看学习成绩,因此如何科学合理的对学生成绩进行评价也是作为评估课堂教学质量好坏的一个很重要的依据之一。通过学生前期学习的成绩来预测后期的成绩,对教学质量的提高有一定的促进作用。
目前,已有很多学者对学生成绩进行预测做了研究。采用密度全局K-means算法对学生数据进行聚类分析,挖掘影响学生成绩的相关因素,并对学生成绩进行预测分析[1]。构建结合决策树和LMBP神经网络算法的分析预测模型,并应用于教育数据挖掘中,可以实现学生成绩分析及预测[2]。采用数据分类中的C5.0算法,以该分数区间为预测目标,构建了成绩的细分预测规则,实现了成人学位英语考试的成绩细分预测系统[3]。对于学生成绩评价,有提出的基于主成分分析法对学生成绩进行综合评价[4],也有对影响学生成绩因素的重要性进行排序的研究。
自学习分类算法(随机森林算法)是一种集成学习算法,是利用多个决策树对样本进行训练、分类并预测。主要应用于分类和回归。因此随机森林被应用于很多领域。许允之把随机森林算法应用到环境保护中,用其预测徐州雾霾情况,最后分析和阐述了徐州对雾霾的治理措施。结合随机森林与端梯度提升算法,并使用十折交叉验证确定最佳的预测模型,应用于预测冠心病住院费用[6]。结合深度学习与随机森林算法提出一种大数据特征选择算法,设计基于随机森林的特征消除算法,对高维大数据集进行特征降维处理[7]。针对构建智慧校园学生画像的数据缺失与高维特征问题,引入外部数据弥补缺失的数据,辅助用户建模,提出一种基于随机森林的双向特征选择算法(RFBFS)解决高维特征问题[8]。这些研究没有将随机森林算法应用于学生成绩进行评价研究分析。
本文提出一种自学习分类算法-随机森林分类算法预测学生成绩,并通过实验说明该算法在对学生成绩数据预测上的有效性,希望该算法在教学管理能起到积极的改进作用。
1 随机森林算法
1.1 决策树
决策树是基于树结构来进行决策的一种算法。它是一树状结构,它从根节点开始对数据样本(由实例集组成,实例有若干属性)进行测试,根据不同的结果将数据样本划分成不同的数据样本子集。每个数据样本子集构成一子节点。生成的决策树的每个叶节点对应一个分类。它有ID3、C4.5、CRAT、SLIQ等。一棵决策树的生成过程主要有3个部分,即特征选择、决策树生成和剪枝。其中最关键的问题是特征选择,不同的分裂标准对决策树的泛化误差有很大的影响。ID3决策树算法是根据信息论的信息增益来进行评估和特征选择的,C4.5决策树算法是用信息增益率来选择特征的,CRAT决策树算法采用的是Gini指数来进行选择的。
1.2 随机森林
随机森林在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性的选择。随机森林算法简单、易于实现、计算开销小,在很多现实任务中展现出强大的性能。
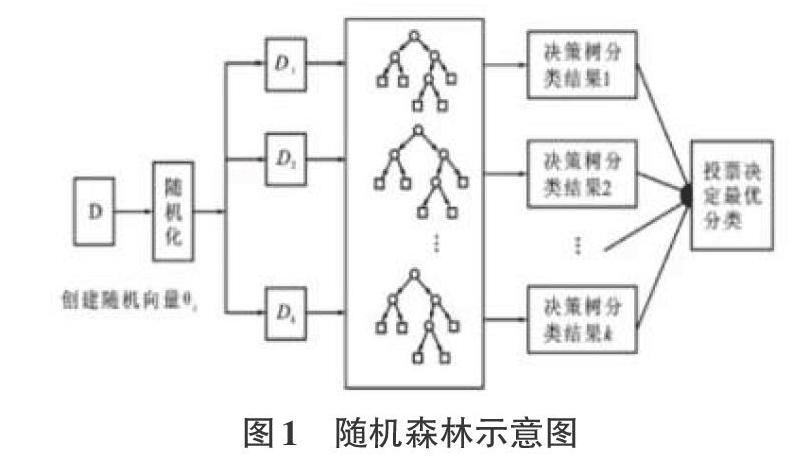
随机森林分类是由很多决策树分类模型组成的组合分类模型,每个决策树分类模型都有一票投票权来选择最优的分类结果。随机森林分类的基本思想:首先,利用bootstrap抽样从原始训练集抽取k个样本,每个样本的样本容量都与原始训练集一样;然后,对k个样本分别建立k个决策树模型,得到k种分类结果;最后,根据k种分类结果对每个记录进行投票表决决定其最终分类[9]。随机森林构建主要包括以下3个步骤:
(1)为N棵决策树抽样产生N个训练集。每一棵决策树都对应一个训练集,主要采用Bagging抽样方法从原始数据集中产生N个训练子集。
(2)決策树构建。
决策树的构建过程包括两个步骤:先构建独立的决策树,然后多棵决策树形成“森林”,在每棵树的生长过程中,由指数.最小原则选出M个特征变量中m个属性中的最优划分。节点分裂原则一般采用CART算法或C4.5算法。在随机森林算法中,选中的属性个数称为随机特征变量。
(3)随机森林形成及算法执行。重复步骤(1)、(2),构建大量决策树,形成随机森林。算法最终输出由多数投票方法实现,将测试集样本输入随机构建的N棵决策子树进行分类,总结每:棵决策树分类结果,并将具有最大投票数的分类结果作为算法最终输出结果[10]。
随机森林示意图如图1所示:
2 基于随机森林的学生成绩评价
本文的实验数据来自某高校2012级信息学院计算机系四个班的学生成绩。用以上提出的随机森林模型对学生前期成绩数据建模,预测后期的专业平均成绩。由预测结果得到各门课程的重要性。由此结果,教师在教学过程中可重点进行教学,提高教学质量,达到培养人才目的。
2.1 数据预处理
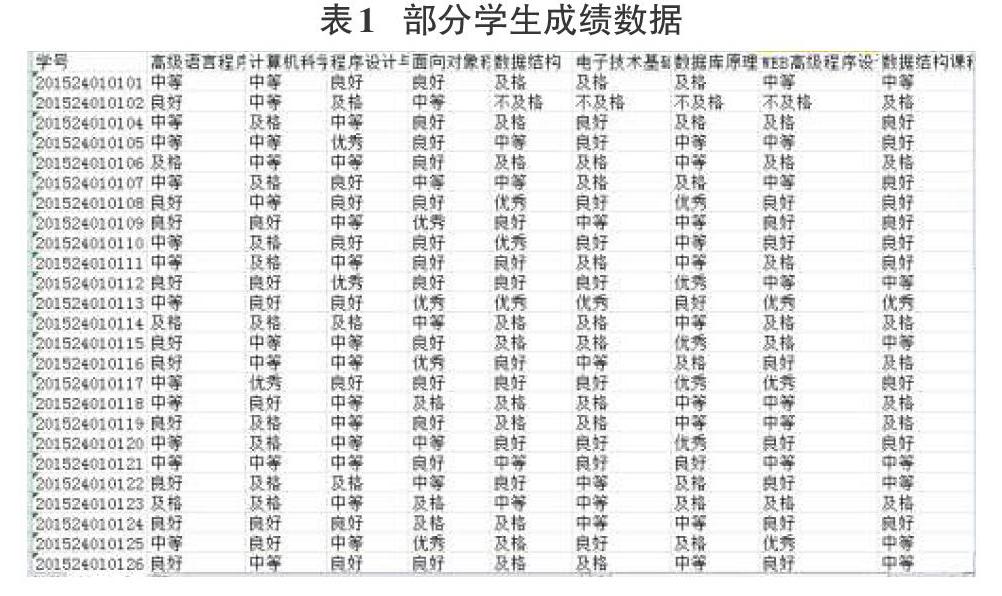
本文的数据来自某2012级信息学院256名学生8896条成绩。由于采集到的数据是不完整的含有噪声的冗余数据,因此需要对数据进行预处理。原始数据中的属性个数很多,删除一些不相关的属性,如学年、学分、班级以及课程性等。采用分箱法对学生成绩数据进行离散化处理。处理后的数据将分为五个等级,分别为:60分以下为不及格,60-70为及格,70-80为中等,80-90为良好,90-100为优秀。离散化后的数据如下表所示:
2.2 实验验证与结果分析
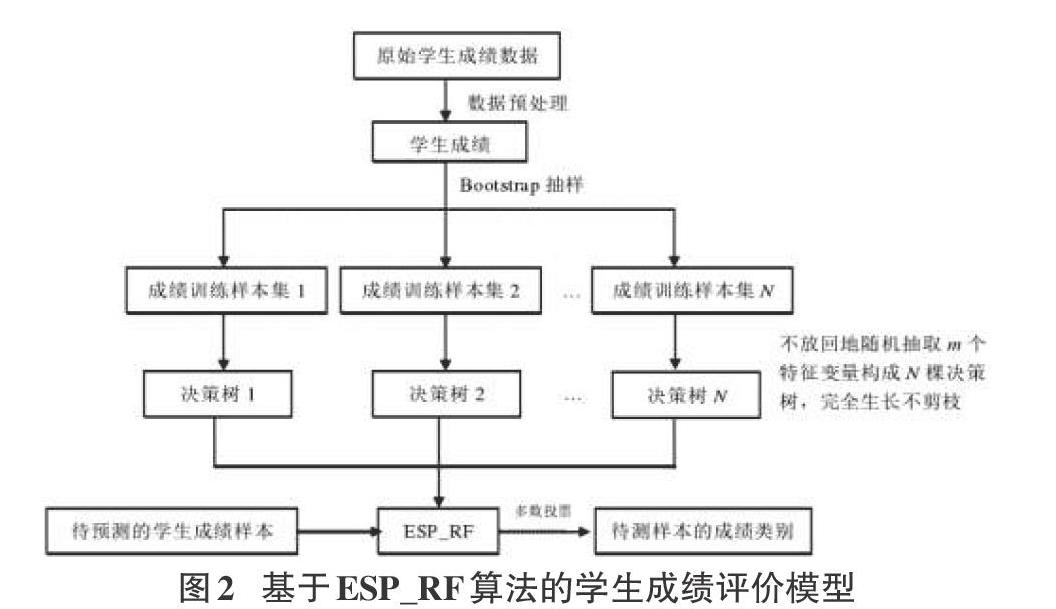
本实验采用python语言平台Anaconda3实现。首先构建了如图2所示基于ESP_RF算法的学生成绩评价模型结构。
首先,确定随机森林模型中两个重要参数:树节点的变量个数mtry的值和树的个数ntree。通过实验得到,当决策树数量取值大于400以后,错误率趋于稳定,以此将ntee值设为400。并从实验得到当决策树节点所选变量数为3的时候,模型的误判率均值是最低的。实验结果如图3所示。
通过学生第一至第四学期的成绩预测第五学期的专业课成绩,并对影响下学期的课程进行排序。如图4所示:
从以上实验中可以得出:
1)这几门课程中“数据结构”对学生专业学习课程的影响最大。其次是“数据库原理”“WEB高级语言程序设计”“程序设计与算法训练”“面向对象程序设计”和“数据结构课程设计”。
2)“电子技术基础”“计算机科学概论”对学生成绩影响较小。
根据实验得到的模型中两种自变量重要程序排序对比结果,实践课成绩对后期学生专业学习的影响较小,在今后的教学过程中,能够有针对性地对学生教学有所倾向,为学生对后续课程的学习打好基础。
本研究在对学生成绩数据进行处理时,由于所收集到的数据存在缺失、多次补考值等问题,进行离散化处理后,得到的模型效果不是特别理想。也没有过多考虑其他因素对成绩的影响。在将来的研究中,可以考虑其他因素及与多种模型进行对比以得到更加准确的结果。
参考文献:
[1]谢娟英.学生成绩关键因素挖掘与成绩预测[J].南京信息工程大学学报:自然科学版,2019(3):316-325.
[2]吴强.基于决策树-LMBP神经网络的学生成绩分析及预测模型的研究[J].成都信息工程学院学报,2018(3):274-280.
[3]孙力,张凯.基于数据挖掘的网络教育学习成绩细分预测的研究与实现[J].中国远程教育,2016(12):22-29.
[4]钱浩韵.基于主成分分析法的学生成绩评价[J].南京工业职业技术学院学报,2017,17(4):21-24.
[5]许允之.基于随机森林算法的徐州雾霾回归预测模型[A].《环境工程》编委会、工业建筑杂志社有限公司.《环境工程》2019年全國学术年会论文集[C].《环境工程》编委会、工业建筑杂志社有限公司:《环境工程》编辑部,2019:6.
[6]夏涛,徐辉煌.基于机器学习的冠心病住院费用预测研究[J].智能计算机与应用,2019(9).
[7]冯晓荣.基于深度学习与随机森林的高维数据特征选择[J].计算机工程与设计,2019,40(9).
[8]杨长春.基于随机森林的学生画像特征选择方法[J].计算机工程与设计,2019,40(10).
[9]吕红燕,冯倩.随机森林算法研究综述[0].河北省科学院学报,2019,40(10).
[10]梁琼芳,莎仁.基于随机森林的数学试题难易度分类研究[J].软件导刊,2019(9).
[通联编辑:王力]