机器学习在网络隐私安全中的应用研究
2020-04-14陈勤中杨晨郑澳谢新雨
陈勤中 杨晨 郑澳 谢新雨

摘要:机器学习作为当下人工智能领域最火热的前沿技术,正在一步一步颠覆各个产业。未来,它将会渗透到我们生活的方方面面,成为我们身边不可或缺的一项技术。而这其中,网络安全则是能够让机器学习大展拳脚的领域。在众多网络安全问题中,隐私保护是一个比较棘手的问题,因而它更加需要机器学习等新技术、新方法、新观点的引入来帮助解决一些问题。为此展开的研究内容包括机器学习概述、机器学习在网络安全中应用的意义、机器学习在网络安全研究中的应用流程以及机器学习在隐私保护中的应用四个部分。其中重点阐述隐私保护的相关问题,提出将深度学习方法中最先进的匹配算法与信息理论数据保护技术相结合,从而引入到生物识别认证中。在确保匹配精确度损失最小的同时,总结出高标准的隐私保护算法,使得商业、政府实体和最终用户都能够更广泛地接受隐私保护技术。
关键词:机器学习;网络安全;隐私保护
中图分类号:TP309.2
文献标识码:A
文章编号:1009-3044(2020)04-0009-04
收稿日期:2019-12-04
基金项目:2019年大连外国语大学大学生创新创业训练计划项目(项目编号:201910172189);2019年辽宁省大学生创新创业训练计划项目(项目编号:201910172064);大连外国语大学创新创业教育中心资助;2017年辽宁省高等学校基本科研项目(项目编号:2O17JYTO9)
作者简介:陈勤中(1998—),男,大连外国语大学本科生,主要研究方向为机器学习、网络安全、密码学;杨晨(1980—),男,副教授,硕士,主要研究方向为机器学习安全与隐私保护;郑澳(1999—),女,大连外国语大学本科生,主要研究方向为大数据安全、隐私保护;谢新雨(1999—),女,大连外国语大学本科生,主要研究方向为网络安全、大数据技术应用。
随着信息技术的发展进步,人类在工作学习以及沟通交流上变得极为高效,但与此同时,人们对隐私安全的定义也在不断地刷新。你的上网购物记录会透露你的消费习惯;你的微博会告诉世界你的生活习惯;你的朋友圈和联系人会暴露你的人际网络;你的电子邮件和短信会显露你的工作状态;你手机上的App可以定位你的位置……这些问题依靠传统的隐私保护技术就可以得到很好的解决,而在一些新兴的科技领域中,传统的隐私保护技术已经很难解决所有的问题了。比如,在生物特征识别技术中,用于识别用户身份的敏感信息极容易成为被攻击的对象,但在此之上进行的技术优化虽然增强了其安全性,却使得被保护用户信息匹配的精确度降低了。这无疑会带来糟糕的用户体验使得该技术难以普及,而问题背后则是现有隐私保护算法存在严重缺陷,这种缺陷仅靠人工优化成本巨大且收效甚微,因此急需一种解决问题的新思路。而近年来随着人工智能领域的兴起,机器学习技术的引进为诸多走入瓶颈的产业带来了新的希望,网络安全就是其中受益颇丰的重要领域,机器学习技术深入应用到隐私保护的相关问题中,将为解决生物特征认证中匹配精确度与安全性相互制约的问题提供新的思考。
1 机器学习概述
1.1 介绍
机器学习是人工智能的一个分支。人工智能致力于创造出比人类更能完成复杂任务的机器。这些任务通常涉及判断、策略和认知推理,这些技能最初被认为是机器的“禁区”。与人工编程相比,机器学习系统自动地从数据中学习程序,这一点非常吸引人。在过去的二十年里,机器学习已经迅速地在计算机科学等领域普及,被广泛应用于网络搜索、垃圾邮件过滤、推荐系统、广告投放、信用评价、欺诈检测和股票交易等领域。
1.2 基本原理
机器学习使用实例数据或过去的经验训练计算机,以优化计算机性能标准[1]。当人们不能直接编写计算机程序解决特定的问题,而是需要借助于实例数据或经验时,就需要机器学习。
现实世界总是有规律的。机器学习正是从已知实例中自动发现规律,建立对未知实例的预测模型并根据经验不断提高、不断改进预测性能。所谓的“学习”,其实就是模型训练。更直白地说,是根据一些已知条件,推导出一个结论,这个结论是一个函数,函数的某些部分是一个常量,但是常量本身并不是已知的。我们需要分析海量数据,去进一步推断出缺失的这些常量。
2 机器学习在网络安全中应用的意义
机器学习在网络安全中应用的意义主要体现在,机器学习依靠自身强大的数据分析能力,在应用的同时,可以幫助用户及时且有效地对网络安全事件做出响应。尤其是遇到团队安全技能不足的状况时,可以设置自动执行来代替团队执行一些琐碎的系统安全任务,有利于切实保障用户的网络安全。另外,机器学习与传统的电子科技产品进行融合,有助于清除产品中的恶意软件,进而达到提高产品安全系数和运行稳定性的目的。
立足于网络安全领域,机器学习和深度学习是网络安全技术不可缺少的组成部分,尤其是深度学习,已经成为信息安全领域关注的焦点。并且,在网络信息安全技术领域,整个行业都以借助深度学习为网络空间安全提供解决方案作为重要抓手,在地域未知攻击、实时检测、应对系统漏洞与威胁等方面进行应用。随着信息技术的发展,攻击行为也在不断地升级变化,因而,机器学习与深度学习在应对攻击、维护网络安全方面更加具有优势和发展潜力,也是整个网络空间安全领域发展的趋势和导向[2]。
在网络安全领域应用机器学习、神经网络等技术,对于提高网络的安全性,降低网络的维护成本,有着积极的意义。人工智能与其他传统产业的结合,已经收获了许多丰硕的成果。将机器学习技术应用到网络安全领域,必将为网络安全技术带来新的发展方向,引领网络安全进入崭新的阶段。除此之外,利用人工智能技术进行网络攻击的手段也已经出现。未来,网络攻击与防御将会是两方人工智能技术的比拼。所以,将机器学习应用于网络安全中是有益且有必要的,机器学习必将推动网络安全技术获得长足的进步[3]。
3 机器学习在网络安全研究中的应用流程
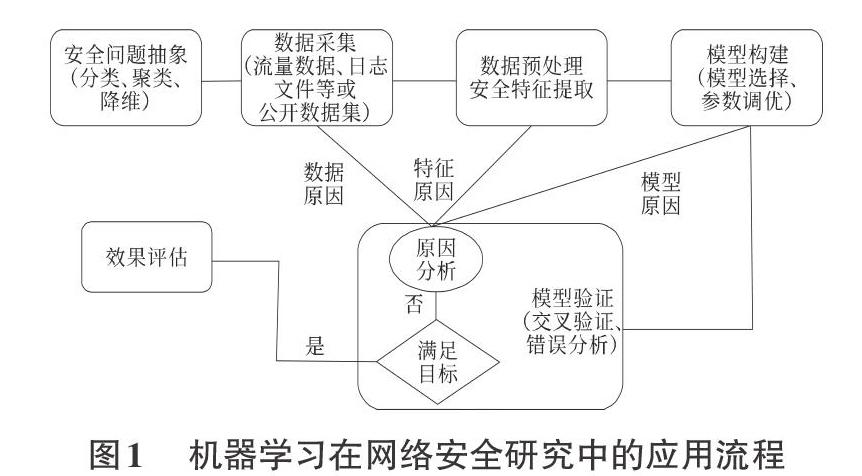
机器学习从大量数据中获取已知属性,解决分类、聚类、降维等问题。如图1所示,机器学习在网络空间安全研究中一般的应用流程,主要包括安全问题抽象、数据釆集、数据预处理和安全特征提取、模型构建、模型验证以及模型效果评估六个阶段。在整个应用流程中,各阶段不能独立存在,相互之间有一定的关联关系[4]。
按照逻辑顺序总结来看,第一步,通过映射将网络空间中的安全问题抽象为机器学习能够处理的类别对象,这种类别对象通常指的是分类、聚类、降维等问题。第二步,通过Wireshark、Netflow、日志收集工具等手段从系统、网络以及应用三个层面釆集大量机器学习算法需要用到的有效数据。第三步,对釆集到的原始数据进行清洗和处理之后,完成对缺失、异常、非平衡以及未分割数据集数据的预处理优化。通过机器学习进行数据集的相关准备,整理集合出训练集、验证集和测试集。最后,将网络空间中最具有安全问题的属性提取出来以完成安全特征的提取。第四步则是整个流程中的中心环节,这一环节根据数据预处理之后的数据集参照目标问题类型,选择出最恰当的机器学习算法,并完成参数的调整和优化。第五步,通过k倍交叉验证等多种验证方法对训练的模型进行验证,确认模型是否稳定且足够有效。第六步,通过对测试集进行效果评估来检验机器学习模型的学习效果以及泛化能力。而这其中对于不同类别、不同领域问题的效果评估,通常会釆用不同的评估指标。
4 机器学习在隐私保护中的应用
4.1 介绍
鉴于我们每天都会留下大量的数字足迹,因此在当今世界,隐私越来越受到关注。隐私的形式可能是我们在论坛注册的信息、上传到社交媒体网站的照片或视频,甚至可能是我们的历史浏览记录。这些足迹的某些部分具有积极的性质,它是用户心甘情愿地提供给第三方的信息,但令人惊讶的是,我们的数字足迹的很大一部分属于我们的数字影子。数字影子本质上就是我们可能会在不经意间留下的数字足迹的一个子集。这些信息中有很大一部分是敏感的,并且有人担心它可能会落入坏人之手。现代加密技术在维护某些形式的敏感信息的方面做得很好,但有些数据类型和应用程序仍然难以得到保护。
4.2 敏感信息
敏感信息通常是指为了保护个人或组织的隐私安全,必须保护其免受未經授权访问的数据。这些可以是与个人有关的个人信息、与组织有关的商业信息或者与政府机构有关的机密信息。从大众的角度来看,重点关注的应该是个人可识别信息(PII)形式的个人信息,因为这些信息可用于追踪个人,并可能对个人的人身财产安全造成伤害。以社保账户和银行账户为详细信息形式的(PII)信息,一般使用对称加密技术将其锁定在密码墙后面,但图像和视频等媒体数据并不那么简单。通常,保护媒体隐私信息的复杂性源于数据存储实体需要访问信息才能提供某些特征这一事实。例如,在社交媒体网站上自动标记用户图像,或者生物特征认证系统中需要访问用户的生物特征,以便将来进行匹配。事实上,生物特征数据是完全符合我们认为能够确保安全的既具有高度敏感性、但又难以获得的数据类别。
4.3 生物特征识别
生物特征识别(Biometrics)技术是一种通过计算机利用人体所固有的生理特征或行为特征来进行身份认证的技术。如图2所示,生物识别数据通常分为两种类型,生理和行为识别。生理识别技术包括我们的生物学特征,如面部识别、指纹和虹膜。行为识别技术通过我们的长期习惯来表现,例如我们的签名、步态或者敲击键盘的方式。通常,生理生物特征被认为是“硬”生物特征,更适合单独使用,而行为生物特征被认为是“软”生物特征,通常与其他形式的身份验证结合使用。
指纹、虹膜、人脸、静脉等生物特征,是人生来就具有的,并且具有唯一性,可以用来很精准地对一个人的身份进行识别判断。同时,相对于密码输入,生物特征具有验证便捷的特点。但是,这些生物特征数量少而且无法更改,一旦泄露就会存在安全风险。随着指纹识别、人脸识别、语音识别等生物特征认证技术的应用,针对此类技术的攻击模式也将不断涌现。
4.4 特征模板的保护
生物特征模板保护的目标是以类似于保护文本密码的方式来保护生物特征数据。由于原始生物识别数据无法像文本密码一样进行更改,因此其安全性至关重要。理想的生物特征模板保护算法应具有以下特性。
1.安全性。给定受保护的模板,提取其原始生物特征数据应该是不可行的。
2.可取消性。如果旧模板遭到破坏,可以从原始生物特征中生成新的保护模板。
3.性能。模板保护算法不应导致生物识别系统匹配性能(FAR和FRR)的损失。
值得注意的是,与使用模板非保护的算法相比,模板保护算法通常会导致匹配精度的损失。这导致模板安全性与生物认证算法的匹配准确性之间会有一个权衡。从安全性的角度来看,加密散列函数是生物特征模板保护算法的理想选择,但是生物特征数据的某些属性使基于散列法的安全性面临很大的挑战。基于散列的安全性要求从生物特征中读取不同的数据所提取的模板之间进行精确匹配。由于生物特征数据在读数之间显示出显著的内在差异,因此提取与之完全匹配的模板是非常困难的。甚至比特位单个的变化都会导致摘取的散列值有非常大的不同。另外,由于在散列取值被破坏的情况下无法更改生物统计数据,所以还需要以某种方式实现其可取消性。
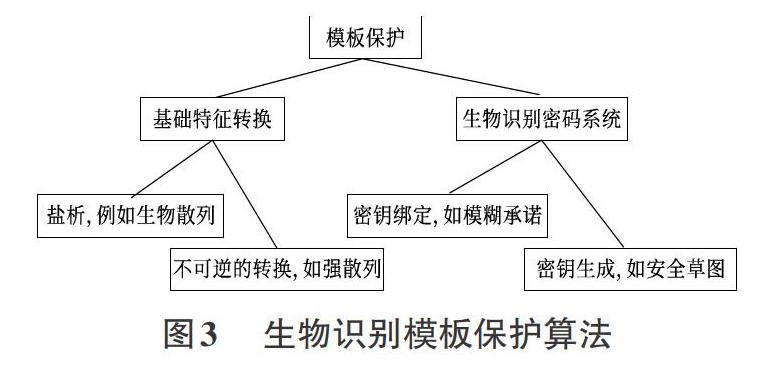
尽管在实现基于散列的生物特征数据模板安全性方面存在困难,但还是提出了几种方法。如图3所示,生物模板保护算法大致可分为两类:生物识别密码系统和基础特征的转换。
4.5 算法综述
我们归纳出已有研究中的一些将深度神经网络在表征学习上的能力与信息理论的数据保护技术相结合的算法,其主要特征是:1)提供可证明的基于散列算法的安全模板;2)在确保安全性的基础上将匹配精确度的损失降到最小;3)不使用外部密钥。
总结了三种在受保护域中进行匹配的算法,每种算法的贡献如下:
1)局部区域散列(Local Region Hashing)
(1)首先,基于密码散列的模板保护算法不存储特定用户的数据。
(2)分析了不同特征提取器对基于散列的生物模板保护的适用性。
⑶提议建立共有信息的度量标准以量化攻击者拥有的信息所导致的嫡损失。
2)深度安全编码(Deep Secure Encoding)
(1)一种利用目标编码解决特征空间均匀性问题的新模板保护算法。
(2)基于PIE和Multi-PIE的面部模板保护的最新成果。
⑶分析了使用简单代码(如MEB)进行目标编码的利弊。
3)深度随机散列(Deep Stochastic Hashing)
⑴从算法推广到新类的能力的角度为该领域未来的研究奠定基础。
⑵提议学习适用于隐私保护匹配的二进制表征的新损失函数。
⑶从隐私保护匹配的角度分析通过不同算法学习到的二进制表征。
需要注意的是,这些应用到生物识别中的隐私保护算法并非用于对外部攻击者的识别,而是为了解决特征模板所存在的安全性与匹配精确度二者难以兼得的固有缺陷问题。
4.6 算法解析
4.6.1 局部区域散列(LRH)
局部区域散列算法背后的原理是评估特征提取器的适用性,以用于基于密码散列的面部生物特征模板的保护。假设即使基于密码散列的模板保护算法无法对从整个面部提取的特征进行精确匹配,但对于从面部局部区域提取的特征来说却要容易得多。通过比较局部二进制模式(LBP)、定向梯度直方图(HoG)和自编码器堆叠学习的特征,发现像LBP和HoG这样的人工制作的特征提取信息甚至比最简单的表征学习形式还要糟糕,这促进了匹配精度和模板安全性兼顾的表征学习形式的研究。该算法的优点是没有存储用户数据,没有使用外部密钥,并且所使用的特征不是特定于用户的。缺点是由于较高的模板安全性导致了匹配精度的损失以及特征空间的不均匀性。总之,该算法是对该问题的初步研究,为更好地解决该问题奠定了基础。
4.6.2 深度安全编码(DSE)
深度安全编码算法的主要目的是直接解决均匀性问题。它被设计了理想的模板安全性功能,并利用深度卷积神经网络(CNN)学习到它的映射,进而完成预定的目标。理想的特征是随机生成的用户代码,我们称之为最大嫡二进制(MEB)代码。由于这些是按位随机生成的,因此它们具有最大的嫡,这使得对散列码的暴力攻击的搜索空间非常大。一旦CNN被训练用来学习从用户的注册样本到MEB码的映射,它的性能就会泛化,从而为已注册用户的其他样本生成相同的代码。该算法具有较高的模板安全性,在容错率(FAR)<=1%,真实接受率(GAR)>95%時,达到了最先进的匹配性能。该算法的优点包括:散列的特征空间均匀统一、模板安全性和匹配精度最为先进,以及显示模板的安全性和匹配精度在同一方向上的理论联系增加了。该算法的主要缺点是CNN仅针对已注册用户进行训练,而不能推广到新用户,因此,新用户注册时需要重新训练神经网络。
4.6.3 深度随机散列(DSH)
深度随机散列算法为解决深度安全编码算法中新用户注册时重新训练的问题而诞生。它的思想是学习使用深层CNN的与类无关的二进制编码器,然后使用密码散列函数对这种编码进行散列处理以产生受保护的模板。该算法使人能够从学习到的二进制表征中确定所需的属性,并将重点放在了神经网络产生无须重新训练即可推广到新类表征的能力上。深度安全编码的思想是设计一个三部分组成的损失函数,该函数考虑了表征的每个理想属性,即类分离,均匀性和对爬山攻击的抵抗力。它的三部分包括传统的“Triplet Loss”损失函数,以及非均匀性和随机边缘部分。进行的实验比较了深度随机散列与深度安全编码的性能,以及在深度随机散列中使用三部分损失函数的各个组成部分之间学习的表征形式,进而发现拟定的损失函数确实可以推广到新类别,并且学习了适合我们目的的表征形式。然而,评价指标的改进却显得微不足道,这表明可能需要进一步试验更大的数据池。这项工作作为未来方向的初步研究,为相对较新的表征学习领域的隐私保护匹配奠定了基础。
4.7 现实意义
综上所述,将深度学习领域取得的最新进展中的优点引入到生物特征模板保护领域,开辟了一个相对较新的用于隐私保护匹配的表征学习领域。提出的算法“深度安全编码”已经实现了最先进的匹配性能和面部模板安全性,并突出了所声明的有效性。这些发现以利用深度学习算法的其他形式将算法思想扩展至新的生物特征识别技术,为生物特征模板保护领域的发展带来了新的机遇。这样的基础研究,着重强调用户数据的保护,同时最大限度地减少与降低匹配精度有关的开销,对于很多方面都是有益的。在为模板提供保护的同时,匹配精度的下降是阻碍生物识别身份验证如面部或者指纹解锁等应用程序接受更高标准的模板保护的主要原因之一。实现可验证的模板安全性标准,同时使匹配精度损失最小的算法的开发,不仅鼓励数据存储实体接受更高保护标准的用户隐私,而且不会降低其提供的服务质量。另外,上述算法不需要任何秘密密钥或有关算法内部工作的隐藏信息,因此可以公开。这样做可以提高用户对这些技术的信任度,因为可以切实地保护它们的数据,使得匹配用户敏感数据的技术更广泛地被接受。最后,算法的应用范围超出了生物特征识别认证的领域,而且前文所介绍的概念可用于各种隐私匹配的保护。或许,此项研究能够引起人们对尚未考虑隐私保护但在不久的将来可能具有重要意义的新领域的兴趣,例如自动面部标记、图片密码、网络浏览模式分析、情感分析等[5]。
5 结束语
本文以隐私保护为例深度阐述了机器学习在网络安全中的应用。首先介绍了机器学习的相关概念与基本原理,其次声明了机器学习在网络安全中应用的重要意义,随后又梳理了机器学习在网络安全研究中的应用流程,最后详细解析了在隐私保护领域怎样通过机器学习克服生物特征识别中安全性与匹配精确度之间相互约束的难题,并归纳总结了三种解决此类问题的算法。可以肯定的是,在隐私保护之外的其他网络安全领域中,机器学习也能为相关问题的解决提供帮助。未来,机器学习一定能够在网络安全领域发挥更大,甚至是中流砥柱的作用!
参考文献:
[1] 周志华.机器学习[M].北京:清华大学出版社,2016:1.
[2] 彭彦鑫.机器学习、深度学习与网络安全技术[J].计算机产品与流通,2018(4):66.
[3] 刘金鹏.基于机器学习技术的网络安全防护[J].网络空间安全,2018,9(9):96-102.
[4] 张蕾,崔勇,刘静,江勇,吴建平.机器学习在网络空间安全研究中的应用[J].计算机学报,2018,41(9):1943-1975.
[5] Rohit Kumar,Pandey.Privacy Preserving Representation Learning using Deep Neural Networks[D].University at Buffalo,the State University of New York,2017.
[通联编辑:代影]