矿山信息物理融合系统多节点智联策略
2020-04-11马洋锦付茂全许志李敬兆
马洋锦,付茂全,许志,李敬兆
(1.安徽理工大学 电气与信息工程学院,安徽 淮南 232001;2.大同煤矿集团有限责任公司 安全监管五人小组管理部,山西 大同 037000)
0 引言
矿山信息物理融合系统(Cyber-Physical System,CPS)在智慧矿山建设中具有重要作用[1-2]。随着无线通信技术的不断发展,矿山CPS不断引入基于不同无线通信协议的感知节点,导致矿山CPS感知节点种类繁多,且无线通信网络错综复杂[3-4]。矿山CPS通信节点无法与现有的多类感知节点实现智能连接,难以满足当前矿山CPS建设需要。
目前,建立矿山CPS多节点连接的主要方案是在通信节点上集成多种通信模块构成多模态通信节点,并采用周期性任务调度的方式依次唤醒各通信模块,不断切换多模态通信节点工作模态,实现与多类感知节点的分时通信[5-6]。但该方案无法实现通信节点与感知节点的精准配对,通信的时效性和连续性均得不到保障。渐进式神经网络作为一种深度神经网络,具有对已有数据进行学习,提取和记忆特征信息的能力[7]。因此,本文提出了一种基于渐进式神经网络的矿山CPS多节点智联策略,应用渐进式神经网络控制多模态通信节点精准切换工作模态,实现与多感知节点的通信智能连接,达到异构无线通信网络自主建立的效果。
多模态通信节点工作模态的控制与感知节点通信方式、节点间距离等因素密切相关,相关因素考虑越全面,渐进式神经网络训练时任务越细致,对多模态通信节点工作模态的控制准确率越高。但随着训练任务的增加,渐进式神经网络列数增多,网络结构渐趋复杂,若直接使用数据集对渐进式神经网络进行训练,极易出现因梯度不稳定导致的网络收敛速度慢、训练精度低等问题[8]。针对该问题,本文应用异步优势动作评价(Asynchronous Advantage Actor-Critic,A3C)算法[9-12]异步生成训练数据,打破训练数据之间的时间关联,提高神经网络训练的稳定性,改善渐进式神经网络的训练效果。
1 矿山CPS无线通信网络架构
目前矿山CPS中对物理信息进行采集的无线感知节点的通信方式主要有LoRa,ZigBee,Bluetooth,RFID等[13]。多模态通信节点作为矿山CPS通信接口,具备与不同类型感知节点进行实时数据交互的能力。基于多模态通信节点的矿山CPS无线通信网络架构如图1所示。
多模态通信节点硬件部分主要以ARM嵌入式微处理器为核心,集成了LoRa,ZigBee,RFID,Bluetooth等无线通信模块及工业以太网接口。多模态通信节点根据无线感知节点所处位置的环境状况、通信状态、干扰情况等切换工作模态,智能选择通信方式,从而与多种无线感知节点进行信息交互,再通过以太网接口将采集的信息传输至地面监控中心。

图1 矿山CPS无线通信网络架构
2 基于渐进式神经网络的多节点智联策略


图2 渐进式神经网络结构
由于渐进式神经网络结构不断扩大,在对之前训练的数据进行融合时,为保持神经网络维度的统一,需要对数据进行M处理,即采用一个单隐藏层的多层感知机(Multilayer Perceptron,MLP)(图3)对前列神经网络的数据进行融合处理,并以一定的维度输出到下一列神经网络中。
MLP中输入神经元个数N=i-1,输出神经元个数P与经M处理后的下一列渐进式神经网络的维度相等。MLP隐藏层输出为
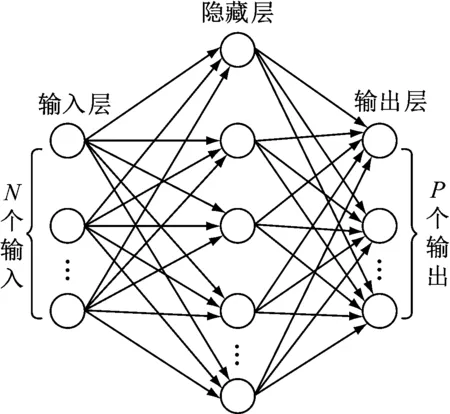
图3 MLP结构
F(AX+B)=sigmoid(AX+B)
(1)
式中:X为输入信息矩阵;A为X的权重矩阵;B为MLP的偏置矩阵。
渐进式神经网络第j层、第k列神经元输出为
(2)

基于渐进式神经网络的多节点智联策略如图4所示。多模态通信节点的输入信息矩阵X经归一化处理后得到矩阵Y;Y作为渐进式神经网络的输入,经处理后转化为输出信息矩阵Q;对输出信息矩阵Q进行L处理(采用变换矩阵与Q相乘)后得到控制矩阵I;多模态通信节点根据控制矩阵I所包含的控制信息进入相应的工作模态,并对通信参数进行调节,完成与感知节点的数据交互。

图4 多节点智联策略
多模态通信节点的输入信息矩阵X由z组状态向量x1,x2,…,xz构成,这些状态向量由工业以太环网上的其他通信节点和已建立通信连接的感知节点提供。为消除输入信息矩阵X量纲的影响,对X进行归一化处理,得
(3)

渐进式神经网络的每一列神经网络都会对网络的输入进行运算,但不同列的神经网络由于是在不同任务下训练出来的,所以对输入信息特征进行提取后,通过运算得到的输出不同。对于任意一列神经网络,若输入数据与训练样本的特征匹配,经运算后产生的输出值很大,否则输出值很小。若输入数据与训练样本特征不匹配的神经网络列数较多,则产生的多个小输出值会累积并对多模态通信节点造成干扰,必须滤除该类神经网络的输出。同时,需要保留输入数据与训练样本特征相匹配的神经网络的输出。因此,对渐进式神经网络的输出矩阵Q进行L处理:
(4)
(5)
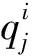
3 基于A3C算法的渐进式神经网络训练
A3C算法框架如图5所示,执行者根据当前任务状态和策略函数决定下一步动作,使任务的状态发生变化。值函数根据动作执行后任务状态的变化情况对执行者的当前策略函数给出评价,执行者根据该评价对策略函数的参数进行修改,同时值函数根据评价与任务当前状态返回值对自身参数进行调整,从而对执行者作出更精确的评价。

图5 A3C算法框架
以值函数表示任务当前状态返回值与执行动作后值函数的联合数学期望:
V(s,θv)=E[r+γV(s′,θv)]
(6)
式中:V(s,θv)为值函数,s为执行者当前状态,θv为值函数的特征参数;r为任务当前状态返回值;γ为执行动作后的值函数权值;s′为执行者执行动作后的状态。
为了判断在状态s下执行动作c的可行性程度,定义优势函数:
A(s,c,θ,θv)=r+γV(s′,θv)-V(s,θv)
(7)
式中θ为策略函数的特征参数。
若选择执行动作c后得到的实际效果比期望效果好,即r+γV(s′,θv)>E[r+γV(s′,θv)],则A(s,c,θ,θv)为正,否则A(s,c,θ,θv)为负。
在A3C算法中,通过策略函数计算出所有起始任务的当前状态返回值,再由策略梯度定理[14-15]得到策略函数的梯度:
(8)
式中p(c|s,θ)为状态s下策略函数更新后执行动作c的概率。
根据策略函数的梯度对策略函数的特征参数θ进行优化,使执行者选择执行的动作能够获得更好的反馈。
值函数的梯度为
Gθv=∂(r-V(s,θv))2/∂θv
(9)
根据值函数的梯度对值函数的特征参数θv进行优化,使执行者当前状态更接近实际值,从而提高参数训练的准确度。
4 实验验证
为验证采用A3C算法训练渐进式神经网络的有效性,进行了基于Darknet深度学习框架的渐进式神经网络训练实验。实验环境配置:Intel i9-9900K处理器、NVIDIA GTX 1080Ti显卡、32 GB内存、Windows 10操作系统、Python 3.7开发工具。实验超参数设置:初始学习率为0.001,权值衰减系数为0.005,动量参数为0.9。采集1 200组感知节点的状态数据,每组数据包括感知节点三维坐标、距感知节点300 m以内的其他感知节点数量、感知节点所采集的数据类型、感知节点与多模态通信节点之间的距离。通过对状态数据叠加高斯噪声实现数据扩充,得到7 200组数据,用来构成渐进式神经网络的训练数据集。在相同的软硬件平台上,使用同一训练数据集,采用A3C算法前后渐进式神经网络训练精度如图6所示。可看出采用A3C算法训练渐进式神经网络具有收敛速度快、训练精度高等优势。
为验证渐进式神经网络对多模态通信节点的控制效果,在某矿进行了多模态通信节点与感知节点的通信实验,节点布置见表1。

图6 渐进式神经网络训练精度曲线

表1 节点布置
当多模态通信节点工作模态与感知节点通信方式匹配,且多模态通信节点与感知节点通信时的丢包率小于5%时,则视为模态转换成功。多模态通信节点工作模态转换准确率为
(10)
式中εt表示第t(t=1,2,…,β,β为多模态通信节点数)个多模态通信节点是否成功转换工作模态,若转换成功,则εt=1,否则εt=0。
先将所有感知节点设置为LoRa通信方式,同时设置初始工作模态分别为ZigBee,RFID,Bluetooth的多模态通信节点各50个。实验开始30 min后记录所有多模态通信节点的工作模态,并利用式(10)计算LoRa模态转换准确率。同理可得ZigBee,RFID,Bluetooth模态转换准确率,见表2。
从表2可看出,在渐进式神经网络控制下,多模态通信节点从随机初始工作模态转换为LoRa,ZigBee,RFID,Bluetooth目标工作模态的准确率分别高于80%,84%,86%,93%,表明渐进式神经网络对多模态通信节点工作模态的控制准确度高,可使多模态通信节点的工作模态根据感知节点通信方式可靠转变。
5 结语
提出了一种基于渐进式神经网络的矿山CPS多节点智联策略。采用渐进式神经网络控制多模态通信节点,实现了多模态通信节点工作模态与感知节点通信方式的自主匹配,提升了矿山CPS通信节点的自主组网能力;以A3C算法优化渐进式神经网络的训练过程,加快了网络收敛速度,提高了训练精度。该策略不足之处在于渐进式神经网络占用了多模态通信节点一定的存储资源和计算资源,使得通信节点的数据处理能力受到制约。因此,简化渐进式神经网络的结构并减少网络计算次数,提升多模态通信节点数据处理效率,将是今后研究的方向。

表2 多模态通信节点模态转换准确率
