矿山语义物联网自动语义标注方法
2020-04-11张楠谢国军叶青赵小虎
张楠,谢国军,叶青,赵小虎
(1.矿山物联网应用技术国家地方联合工程实验室,江苏 徐州 221008;2.中国矿业大学 信息与控制工程学院,江苏 徐州 221008;3.中煤科工集团常州研究院有限公司,江苏 常州 213015;4.天地(常州)自动化股份有限公司,江苏 常州 213015)
0 引言
物联网技术在矿山领域的应用使矿山生产向自动化、信息化、智能化迈进。国家“十三五”规划[1]提出要实现“地下无人采矿”,这对煤矿井下智能设备的信息处理、信息共享及故障自诊断等技术有了更高要求。煤矿现有的技术体系尚不能支持全面的设备自主智能交互,主要体现在[2-4]:传感数据海量且多样,难以建立原始数据与实际意义的关系;各类故障信息存在异构性,自动化排障水平低。
语义网技术可以为数据提供语义支持,在知识表示及人工智能方面有很大优势[5]。本体技术[6]是语义网技术的核心,使用本体的基本元素(概念、概念关系、属性、公理等)能够对领域概念和关系进行规范化表述。随着语义网技术的多元化应用,语义物联网[7]概念被提出,它是物联网技术的增强。结合本体技术与物联网进行具体应用时,需要与实例联系起来,语义标注技术[8]是指对实例对象数据进行处理和标记,其目标是基于机器可理解的方式标注传感网络中的内容,实现机器自动操作与机器间数据共享。
目前,学者们针对各类物联网前端感知设备构建了通用本体[9-11],在矿山安全领域,使用本体技术对特定范围灾害进行知识库构建与语义标注应用[12-15]。现有研究存在以下问题:构建的通用物联网本体无法直接拓展到煤矿领域;煤矿领域本体只考虑重用某个或某几个通用本体来驱动语义标注,忽略井下数据的高动态性,本体库实时性差,无法自动更新;对实例对象数据进行标注时,针对本体的数据属性与定义域方面,只能通过手动构建,无法自动确定数据属性相关知识;构建基础本体时,往往需要查阅大量资料,耗费大量人力和时间,且资料中的传感数据一般是由相应的传感器采集的原始数据,数据海量、分析困难,较难从中得到高级层次的概念。针对上述问题,本文提出矿山语义物联网自动语义标注方法,用于对大量井下设备及实体相关的数据进行描述。
1 传感数据语义化处理框架
传感数据语义化处理框架如图1所示。以基础本体库构建与传感数据语义标注知识自动获取两线并行开始,再将二者结合,从传感数据中挖掘知识来驱动本体的更新与完善,实现本体的动态更新、拓展与更精确的语义标注,增强机器的理解力。
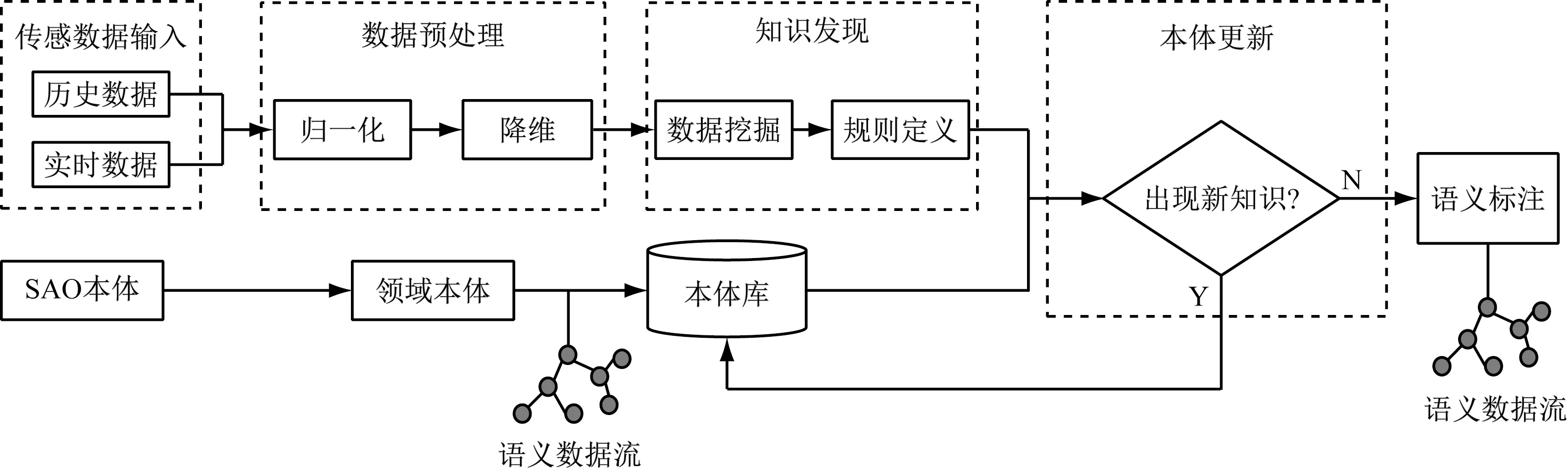
图1 传感数据语义化处理框架
1.1 基础本体库构建
在矿山物联网中,传感器采集的信息类型多样、来源广泛,多以数据流的方式进行传输。SAO(Stream Annotation Ontology)[16]允许发布关于物联网数据流的内容衍生数据,可以对原始数据流进行采样及聚合,故通过重用SAO构建基础本体,如图2所示。SAO使用sao:StreamEvent概念的广义定义来表示时间区域的人工分类;对于特定的数据流,它通过概念sao:StreamData拓展SSN(Semantic Sensor Network)本体[17]中描述的传感器观察(SSN:observation),可链接时间间隔(Segment)或时刻点(Point),这方便了对本体库进行实时更新;流数据分析(sao:StreamAnalysis)链接了传感数据的近似表示方法(降维技术),是对后续数据属性标注的一个指导。确定本体的专业领域和范畴,按照一定规范与标准,建立领域本体后,即可对矿井设备及传感信息进行统一规范化描述,消除信息异构性,作为驱动语义标注的基础。
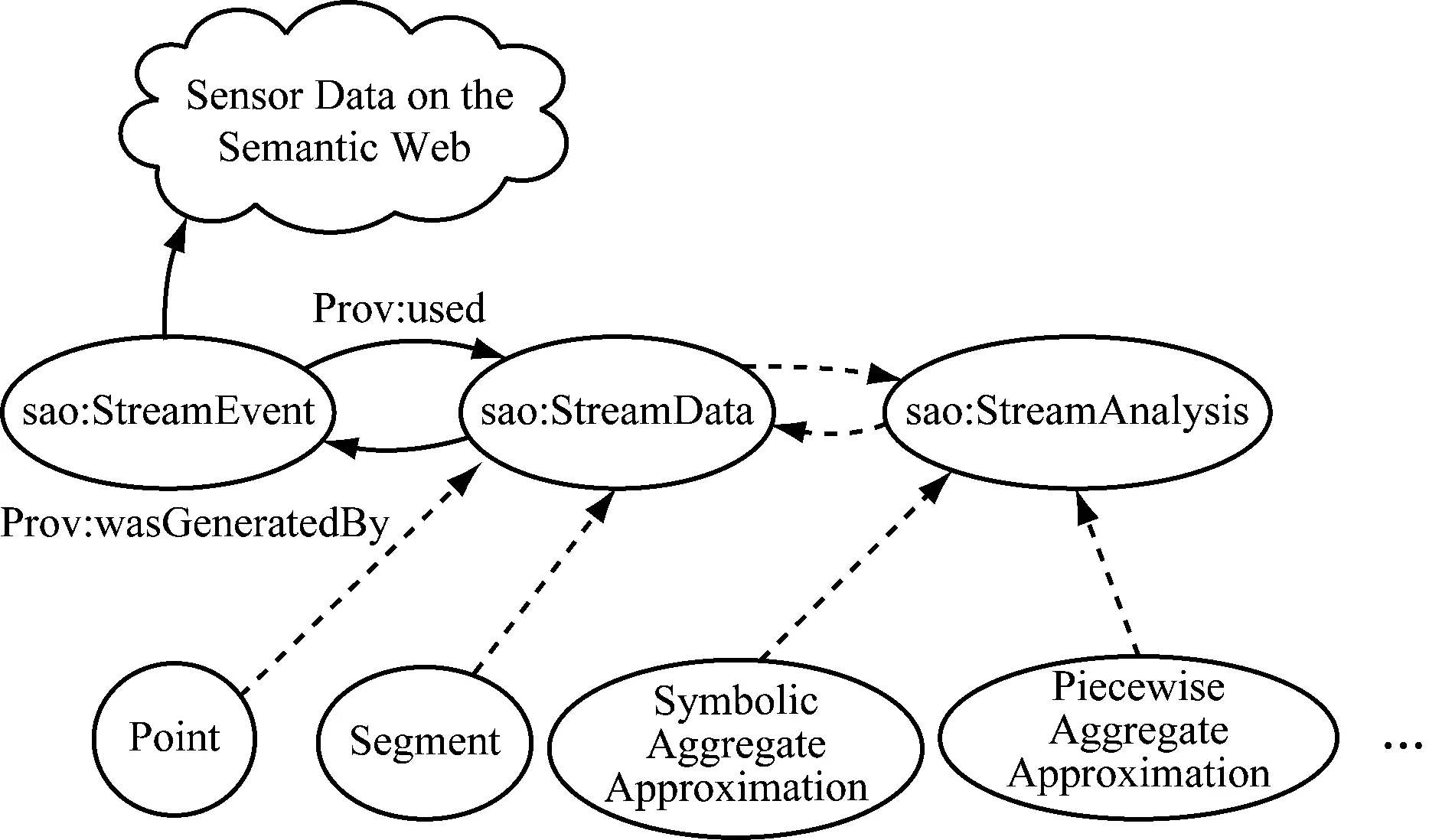
图2 矿山语义物联网数据语义标注参考本体
1.2 传感数据语义增强
感知矿山物联网体系中,在感知层中存在各类检测和监控设备,感知数据源源不断地从感知层透过网络层传输到应用层。感知数据反映了设备的实时状态和变化趋势,其语义层面的理解和智能处理都是基于数据属性描述实现的。
在自动获取数据语义标注知识的过程中,使用机器学习方法对感知数据流进行特征提取与数据分析,根据预先构建的本体确定相关数据属性与属性关系。从海量数据中挖掘出概念间的关系,提高本体质量,将低层次的观测数据转换为高层次的概念,完成数据的语义强化。
2 矿山语义物联网自动语义标注实现
以矿井提升系统为例,阐述在实际应用中如何根据传感数据语义化处理框架实现本体到实例化的语义标注过程。主传动系统是矿井提升机的重要组成部分,通过构建主传动系统故障基础本体,使用相关传感数据自动化提高数据属性描述的准确性与智能性,实现故障自诊断与智能维护。
2.1 主传动系统故障本体构建
“七步法”是具有代表性的领域本体构建方法,它提供了一种开发领域本体的步骤及思路,分为确定范围、列举概念术语、重用本体、定义层级关系、定义属性关系、定义属性约束、创建实例七步。使用“七步法”构建领域本体的流程如图3所示。
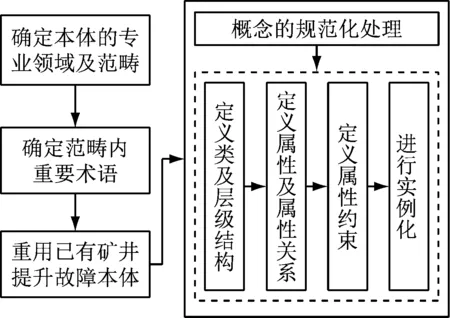
图3 领域本体构建流程
结合主传动系统状态感知设备实际情况及相关学科资料,列出设备组成及对应可能故障列表,确定实际生产中可能发生的故障事件及其原因范围、术语;重用已有的矿井提升系统故障本体[18-20],自上而下定义分类概念与概念分类层次。主传动系统故障原因类本体层次结构如图4所示。
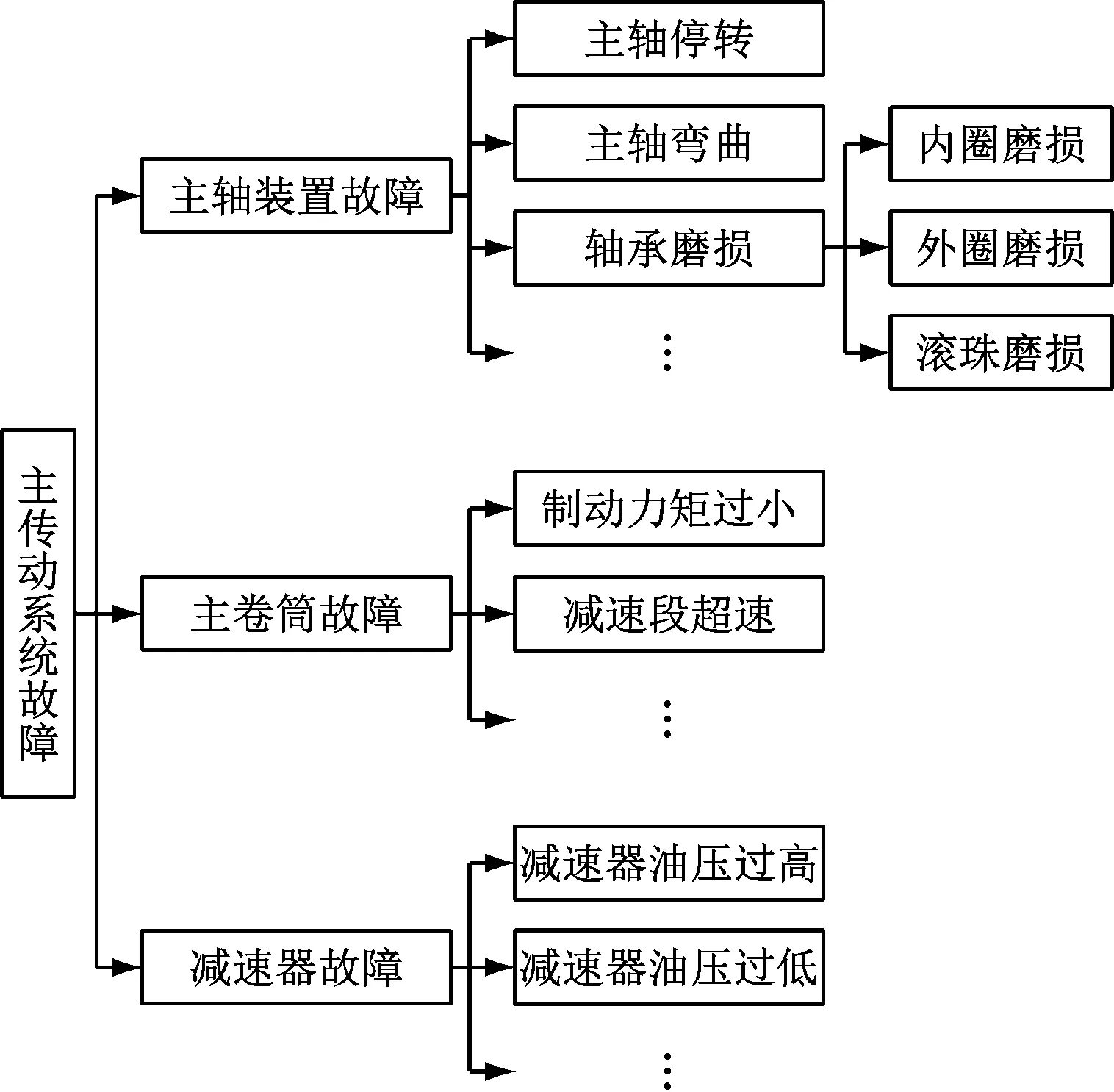
图4 主传动系统故障原因类本体层次结构
确定原因类本体结构后即可利用Protégé本体编辑器工具中的AddSubClass添加故障类及子类:属性及其关系是对故障概念的细化,分对象属性和数据属性,对象属性包括故障对象的状态,如停转、磨损等;属性约束是属性的定义域和值域,即故障发生位置与对应判断标准的参考。建立好属性后,选中Individual一栏,给类添加Member进行实例化。编辑后使用开放式接口将建好的本体生成不同格式文档,按需输出,即可不受异构平台的限制,实现诊断知识的共用。
2.2 传感数据语义增强处理流程
图4中,定义轴承磨损子类时,需要添加数据属性,即不同位置轴承磨损子类或实例具有的数据特征,并确定其值域。然而,从传感器原始数据中很难发现故障的明显特征,无法直接对主传动系统故障领域本体的轴承磨损类进行实例化数据属性标注,需要对数据进行进一步处理。由原始传感数据到抽象语义知识,即使用原始数据自动地提取概念进行语义强化,弥合初始本体构建过程中对数据属性的描述与由实时数据提取出的真实属性之间的偏差,完成实例化过程的标注。以轴承内圈磨损、外圈磨损、滚轴磨损为例,由原始传感数据到抽象语义知识的转换如图5所示。

图5 由原始传感数据到抽象语义知识的转换
2.2.1 传感数据预处理
实时传感数据一般呈数字形式,采样率高,时间序列维度较高。为了实现信息由低级向高级的表达,需要减少必须处理的数据量,降低处理难度。首先对代表故障模式的敏感特征进行构建,提取相关时域和频域信息,得到具有关键物理意义的统计特征;然后利用降维技术减少特征数量[21],去除冗余信息。
本文使用最常用的主成分分析法[22](Principal Component Analysis,PCA)对数据进行降维处理。PCA是一种正交回归方法,基于特征空间线性转换技术,其目标是找到数据中使得投影误差最小的元素,去除噪声和冗余,用一组正交向量重新构建得到新的数据空间。该方法保留了原有数据特征,可达到简化模型和压缩数据的效果,即可使用低维简单的特征表达传感数据蕴含的信息,可用于数据属性的描述。此外,PCA方法易于在计算机上实现,有利于将计算过程部署到井下边缘节点处的相关计算中心当中,方便进行本体实时更新与语义标注。
2.2.2 知识发现与自动语义标注
通过PCA将原始传感数据转换为降维数据集后,为了提取语义知识来定义数据属性的值域,选择机器学习中的无监督学习方法来进行知识发现。无监督学习方法用于发现数据中的模式,输入无标签的数据样本,可以根据特征自动学习,将数据进行分组。K-Means聚类[23]是无监督聚类算法中的最典型最易实现的算法,它基于原型的、划分的距离技术,当用户输入数据集合与类别数后会自动迭代收敛。经过聚类,每个集群都代表一个未标记的概念。
本文使用基于语义Web的规则语言[24](Semantic Web Rule Language, SWRL)来描述提取到的概念和数据属性。SWRL中定义的规则遵循以下语法形式:antecedent⟹consequent,即标记的先行条件成立,则后续概念成立。这种规则是数据属性关系的参考,井下智能设备会根据描述的规则进行推理排障。如在本体更新轴承磨损子类定义、向实例添加数据信息时,可自动根据传感数据的处理结果确定值域、修改推理规则,进行数据的语义化标注。
3 实验分析
3.1 数据来源与处理
使用美国凯斯西储大学采集的电动机驱动端滚动轴承振动信号数据进行实验分析。驱动端的轴承型号为SKF6205。用电火花分别对轴承的外圈、内圈、滚珠进行单点损伤加工,制造故障轴承。分别将不同情况的故障轴承重新装入测试电动机中,安置在驱动端的加速度传感器记录振动加速度信号数据。设采样频率为12 kHz,采集正常、外圈故障、内圈故障、滚珠故障4种模式的振动信号数据各45条,每条含6 000个样本点。随机选取各状态振动信号数据1条,截取连续的500个振动信号样本点,如图6所示。
(a)正常样本振动信号
(b)外圈磨损样本振动信号

(c)内圈磨损样本振动信号

(d)滚珠磨损样本振动信号
构建13个时域特征(特征编号对应为1—13):幅值和(sum),幅值绝对值和(abs_sum),第5%分位数(per5),第95%分位数(per95),第99%分位数(per99),均值(mean),最小值(min),最大值(max),标准差(std),方差(var),中位数(median),偏度(skew),峰度(kurtosis)。这样,每一条时间序列的6 000个数据信息就可由13个数据特征去代替。部分计算结果见表1。

表1 部分数据的时域特征值
设置PCA的特征维度数为13,各主成分的方差值占总方差值的比例分布(贡献率)情况如图7所示。
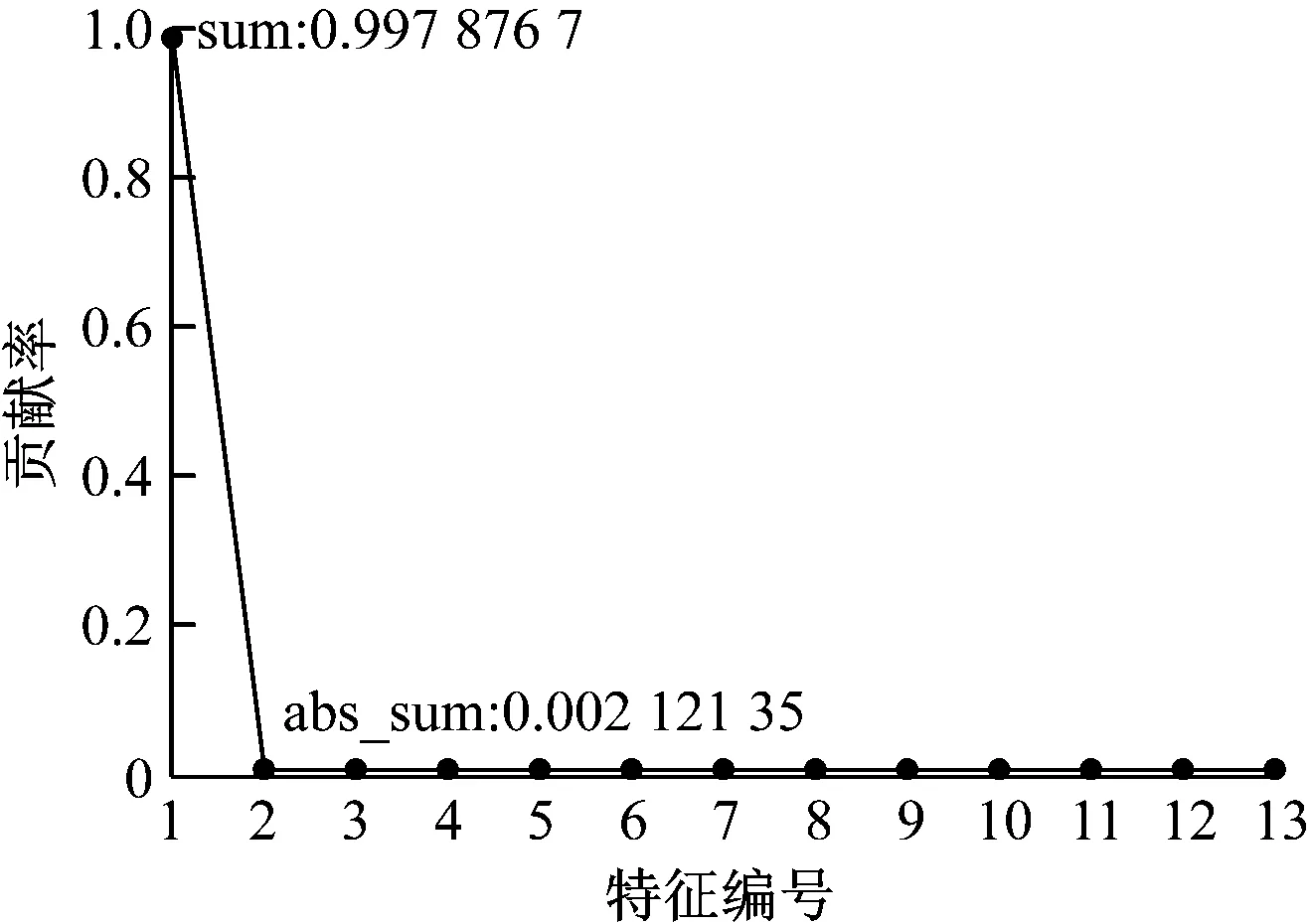
图7 轴承振动信号特征分布
将特征方差由大到小排列,当特征方差的比例和大于0.8时就可以将其作为主成分。设PCA方法的降维维度为2,即选取2个特征组成二维特征向量。经过PCA降维处理后,部分数据的二维特征值见表2。经过特征提取与降维处理后,传感器原始数据可以用二维数据(Feature1,Feature2)表示。
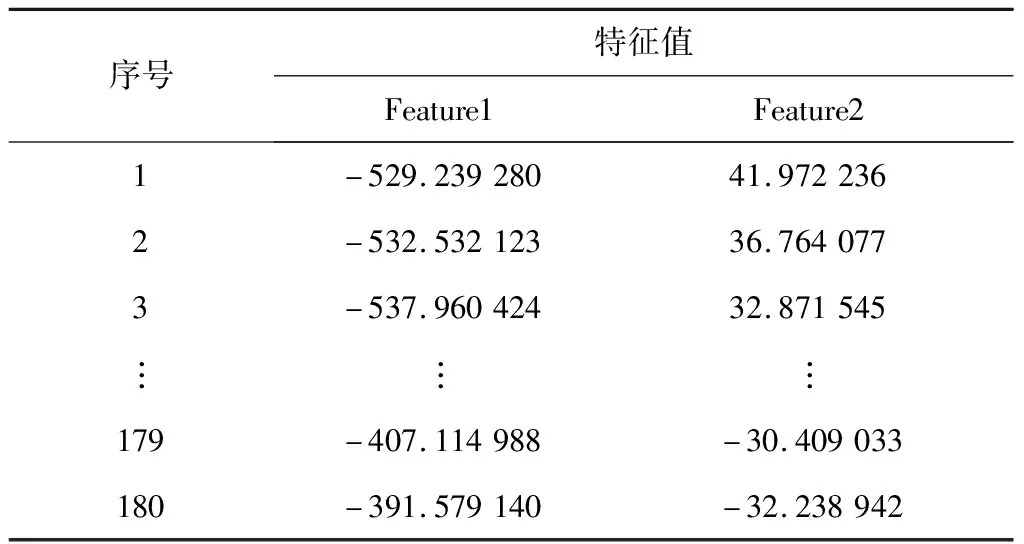
表2 部分数据的二维特征值
3.2 基于规则的数据属性描述
将降维处理后的数据去掉模式标签并进行聚类,设置类别个数为4,迭代次数为300,10次随机初始化,距离度量为自动。数据集中的样本点被分成4个集群,如图8所示。将聚类结果与有标签的数据对比,发现归类基本正确。
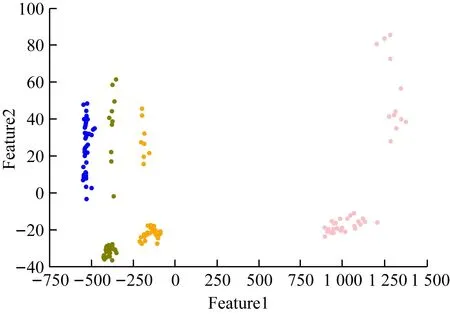
图8 降维数据集聚类结果
以聚类结果作为规则生成基础,得到语义表示规则,见表3。在进行语义增强与本体更新时,可使用Protégé中的OntoGraf插件根据规则描述类和属性间的关系。对应到图4,轴承磨损的子类即内圈磨损、外圈磨损、滚珠磨损对应的数据属性名称分别为Inner Fault,Outer Fault,Ball Fault,定义域均为dimension_Feature1,dimension_Feature2。在进行实例化时,可以将自动处理后的数据保存在数据库中,按照需求的时间间隔定时向本体发送数据,根据实际数据更新拓展对应数据属性值域。在机器互操作中进行查询推理时,可以利用表3的规则判断实际故障情况。
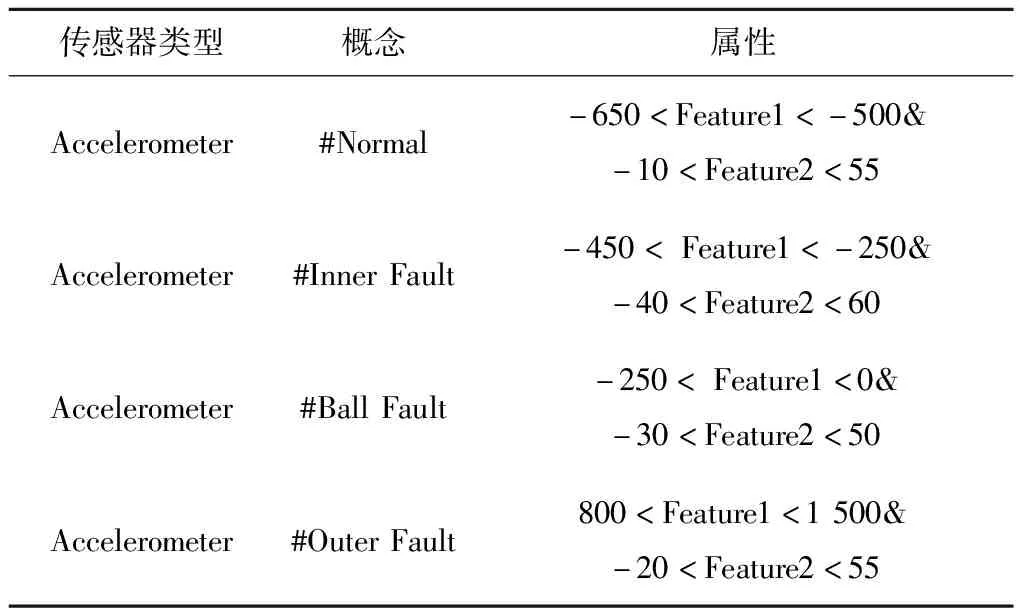
表3 语义表示规则
4 结语
提出了矿山语义物联网自动语义标注方法,以矿井提升系统主轴故障为例,结合SAO本体和本体重用构建矿井提升系统主轴故障领域本体。为了加强实例数据属性描述的准确性,使用PCA降维方法与K-means聚类方法对数据集进行分组,提取出数据属性与概念的关系,进行本体更新与优化。通过实验验证了在本体实例化过程中,可利用机器学习技术从传感数据中自动提取概念,实现传感数据的自动语义标注,这种增强数据语义的方法是有效的。
