基于LLE-RF的中药三维荧光光谱分类识别
2020-04-11樊凤杰轩凤来纪会芳
樊凤杰, 轩凤来, 白 洋, 纪会芳
(1.燕山大学 电气工程学院,河北 秦皇岛 066004;2.解放军第二六一医院,北京 100094)
1 引 言
中药指纹图谱技术是中药鉴定与中药质量控制的关键技术[1],三维荧光光谱由于灵敏、快速等优点正逐渐成为中药指纹图谱研究的有力工具,因此,对中药三维荧光谱信号进行特征提取是中药光谱分类识别的关键。
目前,常用的三维荧光光谱特征提取方法有参量化方法以及主成分分析(principal components analysis,PCA)等方法[2]。胡泽建等[3]于1998年提出了参量化方法,通过提取三维荧光光谱的平均值、标准差、z值的累积率分布、原点矩、中心矩、重心等特征参量作为光谱特征,该方法虽然有明确的几何特征意义,但只是将提取的特征简单的组合。PCA算法是在不丢失主要信息的基础上进行数据降维,用维数较少的新变量代替原来维数较多的变量[4]。
局部线性嵌入(locally linear embedding,LLE)作为一种非线性的流形学习算法,通过寻找高维数据中所隐藏的低维流形结构进行特征提取,该算法复杂度低,便于实现[5]。
本文提出了LLE-RF组合算法,采用LLE算法对补虚类中药三维荧光光谱数据进行特征提取,并将LLE算法提取的特征向量输入随机森林(random forest,RF)分类器进行分类识别。
2 数据预处理
2.1 样品配制
分别配制24味补虚类中药(表1所示)5个不同浓度的溶液制剂。
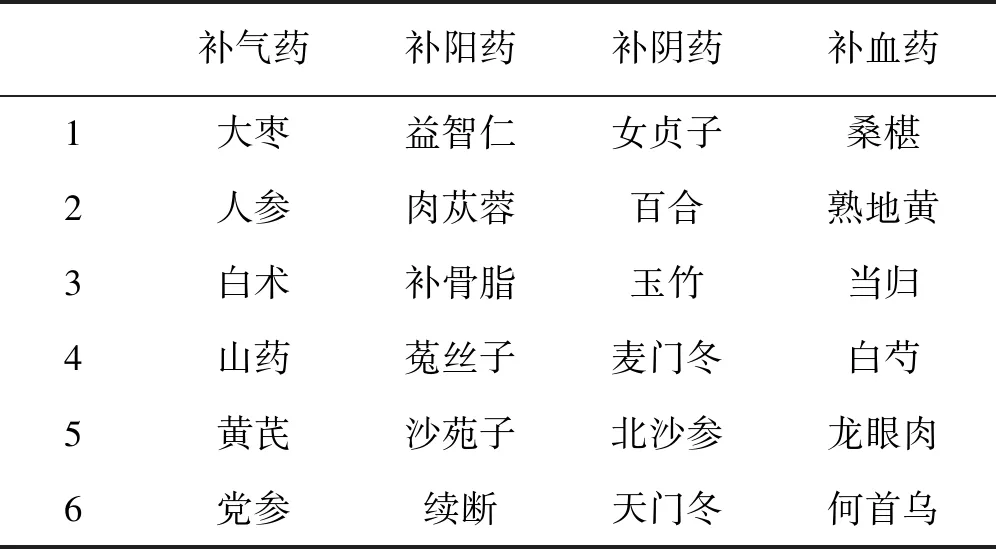
表1 24味补虚类中药Tab.1 24 tonifying herbs
具体配制过程如下:首先称取24味补虚类中药各1 g,分别放入250 mL烧杯中,加入100 mL蒸馏水浸泡30 min,用武火煮沸,再用文火熬煮35 min,冷却至室温,过滤至100 mL容量瓶,加蒸馏水稀释,得到每味中药的10 mg/mL溶液制剂;再用胶头滴管从10 mg/mL的溶液制剂中提取 8 mL 溶液至25 mL量筒中,加蒸馏水至10 mL,即得到浓度为8 mg/mL的溶液制剂。按上述方法依次配制6 mg/mL、4 mg/mL、2 mg/mL的溶液制剂,进而得到24味中药5个不同浓度的溶液制剂。
2.2 实验过程
使用英国Edinburgh Instruments公司生产的FS920号稳态荧光光谱仪,分别测量不同浓度的补虚类中药溶液的荧光光谱。为保证光源的使用寿命,测量时需将仪器冷却降温至-19 ℃后再进行测量。测量前需设置荧光光谱仪的测量参数,设置积分时间0.1 s,激发波长EX扫描范围为220~550 nm,发射波长EM扫描范围为240~570 nm。为尽量避免瑞利散射的干扰,设置发射扫描波长起点始终滞后激发波长20 nm,激发与发射步长均为10 nm。
2.3 光谱去噪
每一浓度下中药三维荧光光谱数据均采用总体平均经验模态分解(ensemble empirical mode decomposition,EEMD)[6]算法降噪,以6 mg/mL的人参溶液为例,测量得到如图1、图2所示的人参溶液三维荧光光谱图以及等高线图。等高线图是三维荧光光谱图在激发波长与发射波长所在平面的投影。
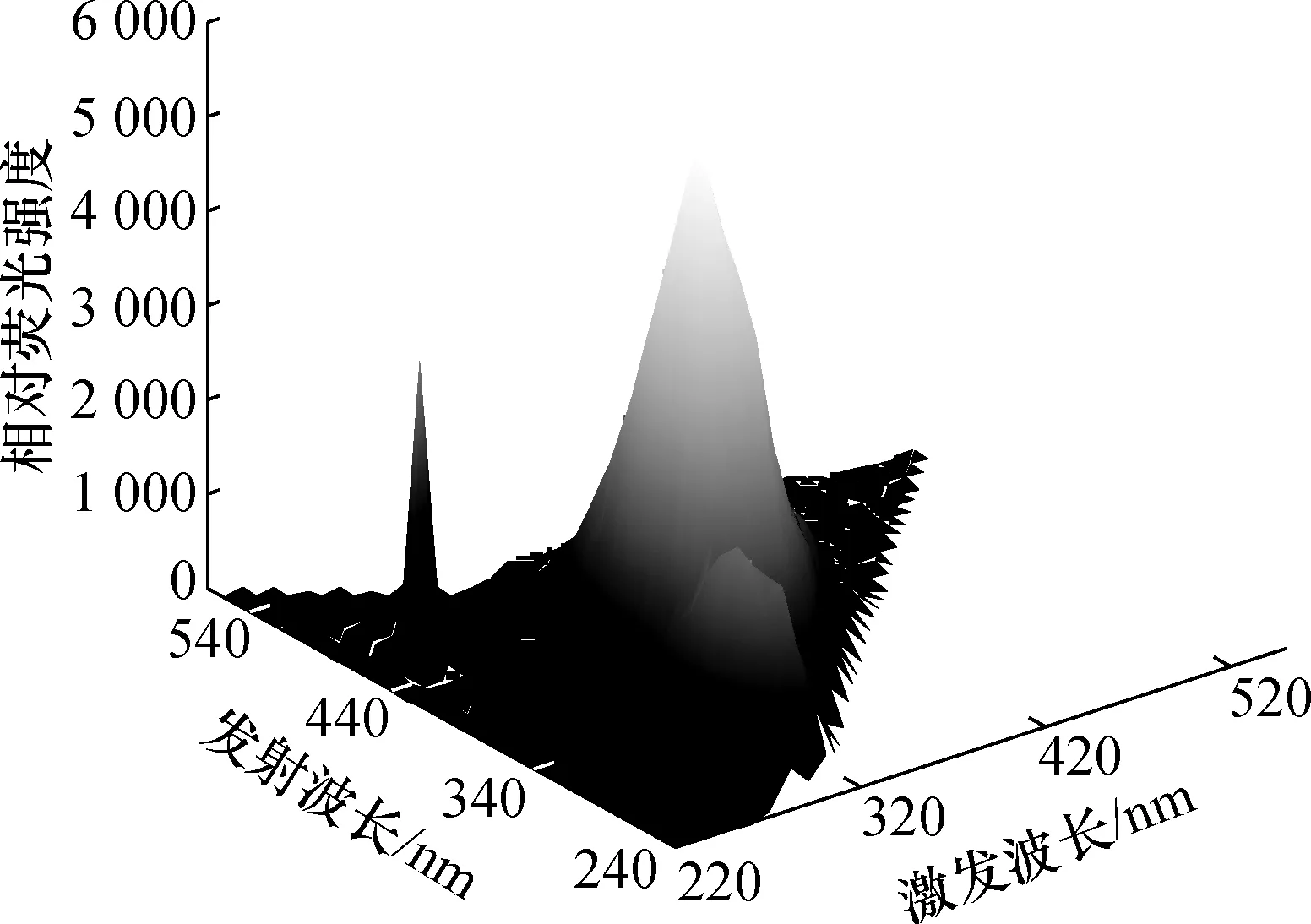
图1 人参溶液三维荧光光谱图Fig.1 Three dimensional fluorescence spectrum of ginseng solution
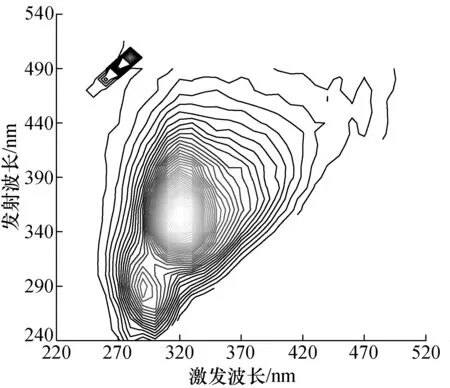
图2 人参溶液等高线图Fig.2 Contour map of ginseng solution
由图1、图2可以看出,在激发波长270~370 nm、发射波长240~440 nm范围内存在主荧光峰与次荧光峰,在激发波长220~320 nm、发射波长440~540 nm范围内存在噪声。利用EEMD对荧光光谱数据降噪,降噪后的三维荧光光谱图及等高线图如图3、图4所示。由图3、图4可以看到在激发波长220~320 nm、发射波长440~540 nm范围内的噪声已经消除。经EEMD降噪后的数据格式为34×34,将每个样本矩阵首尾相接,构成1×1 156形式,并将120个不同浓度的样本数据整理成 120×1 156矩阵形式。
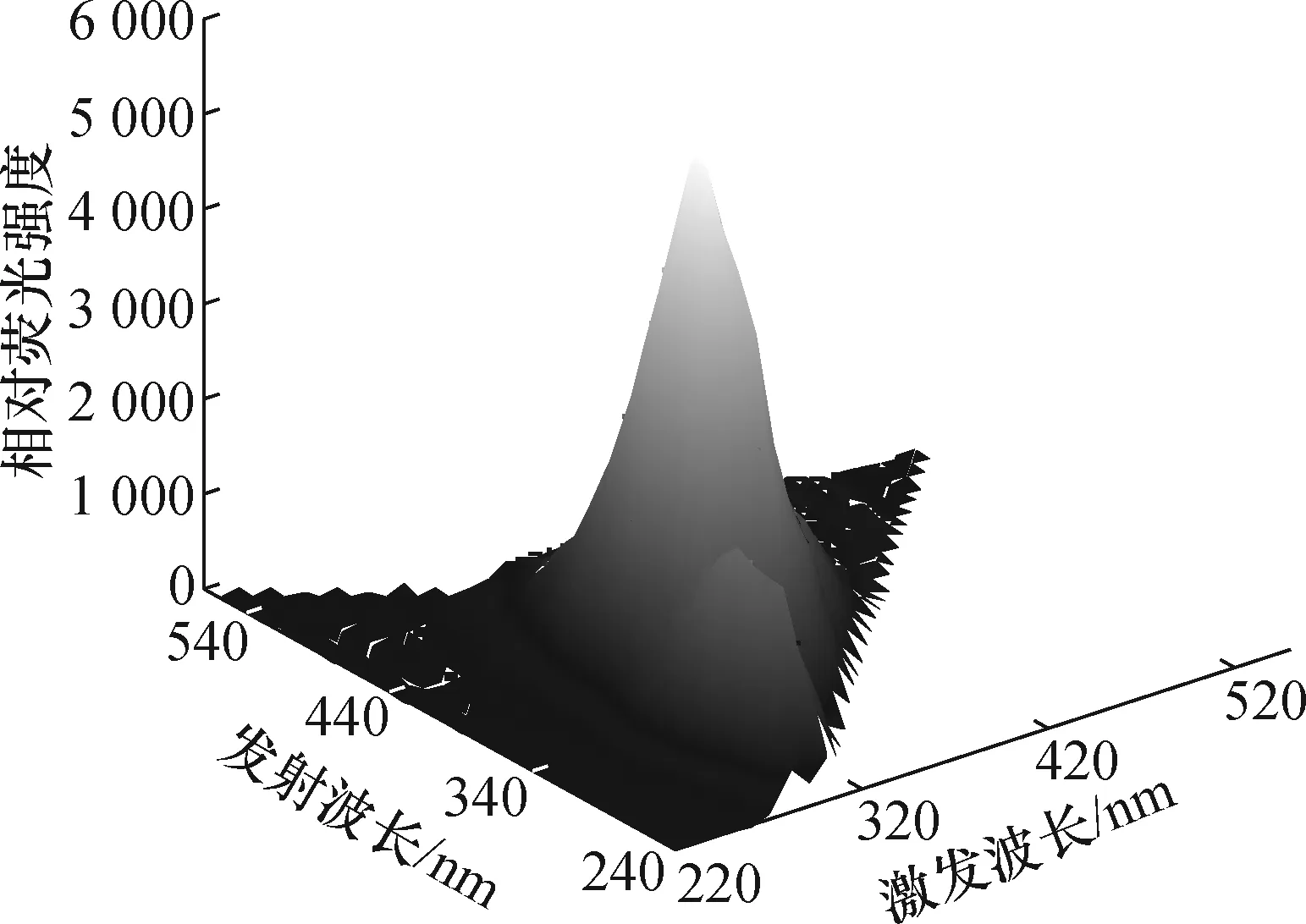
图3 降噪后的人参溶液三维荧光光谱图Fig.3 Three dimensional fluorescence spectra of ginseng solution after denoising
3 特征提取与分类识别
3.1 特征提取
3.1.1 LLE算法
LLE是用局部的线性逼近整体的非线性,能够使降维后的数据保持原有的拓扑结构,具有平移、旋转和伸缩不变性,并且有整体最优解,不需要迭代,避免了局部极值问题[7~9]。
设中药三维荧光光谱信号为X,其中,X=[x1,x2,…,xn],xi∈Rm,i=1,2,…,n;m为信号维数,Rm为m维空间的样本数据;映射到低维空间的信号Y=[y1,y2,…,yn],yi∈Rd,d为光谱信号降维后的维数,Rd为映射到d维空间的样本数据。
LLE算法主要步骤如下:
(1) 采用k近邻法寻找每个浓度下中药光谱的k个近邻点;
(2) 依据近邻点计算出该样本点的局部重建权值矩阵,要求误差函数最小,即:
(1)
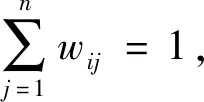
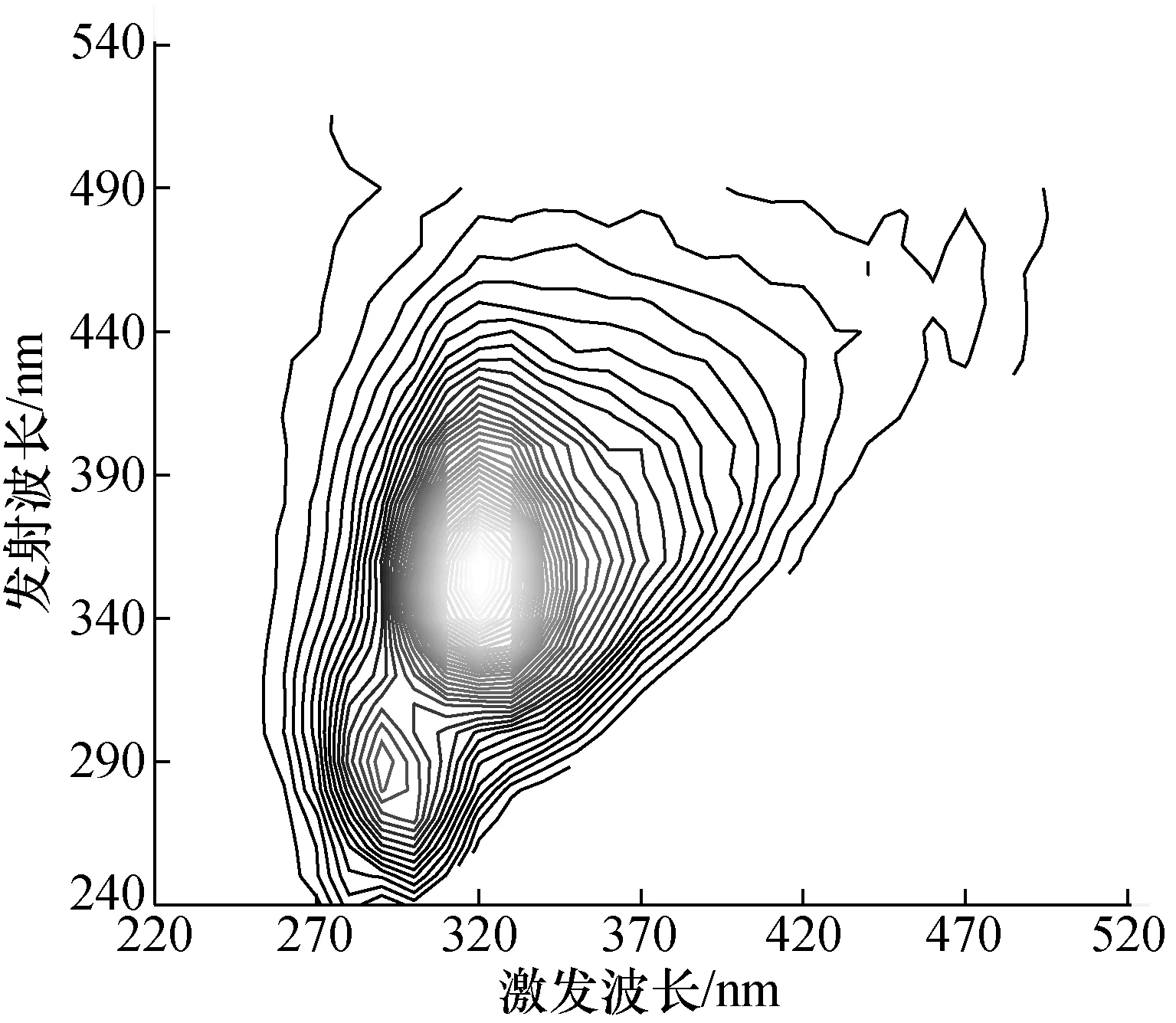
图4 降噪后的人参溶液等高线图Fig.4 Contour map of ginseng solution after denoising
(3) 由该中药光谱的局部重建权值矩阵和其近邻点计算出该样本点的输出值,即d维嵌入值,并且映射条件应该满足:损失函数最小,即
(2)
为了保证上式有唯一解,低维嵌入应该满足
(3)
3.1.2 LLE算法提取特征数据
采用RF对LLE算法不同嵌入结果进行分类识别,确定合理的近邻点数以及本征维数。同时,为了验证LLE的有效性,将其与PCA进行比较。为解决原始数据维数问题,选择累积贡献率为95%的前8个特征量PC1、PC2、PC8代表原始样本的光谱特征,即每个中药光谱样本选择8个特征量代替原来高维空间的样本数据。当LLE中k=8,d=8时,LLE及PCA得到的部分特征数据分别如表2、表3所示。
3.2 分类识别
RF算法是一种集成学习算法,将多个决策树组合在一起达到分类识别的目的[10,11]。
建立RF算法的步骤如下[12,13]:
(1) 通过Bootstrap法按不同的比例从原始数据中有放回地抽取X个训练样本建立X棵决策树,剩余的样本数据形成OOB数据,构成测试样本;
(2) 在生成每棵树的过程中,通常需要在每个节点处从所有的特征变量中随机抽取N个变量,然后选择出最具有分类能力的变量对样本分类;
(3) 每棵树都完全生长,不进行剪枝;
(4) 根据生成的多个树分类器对新的数据进行分类,分类结果按照每个树分类器的投票多少而定。
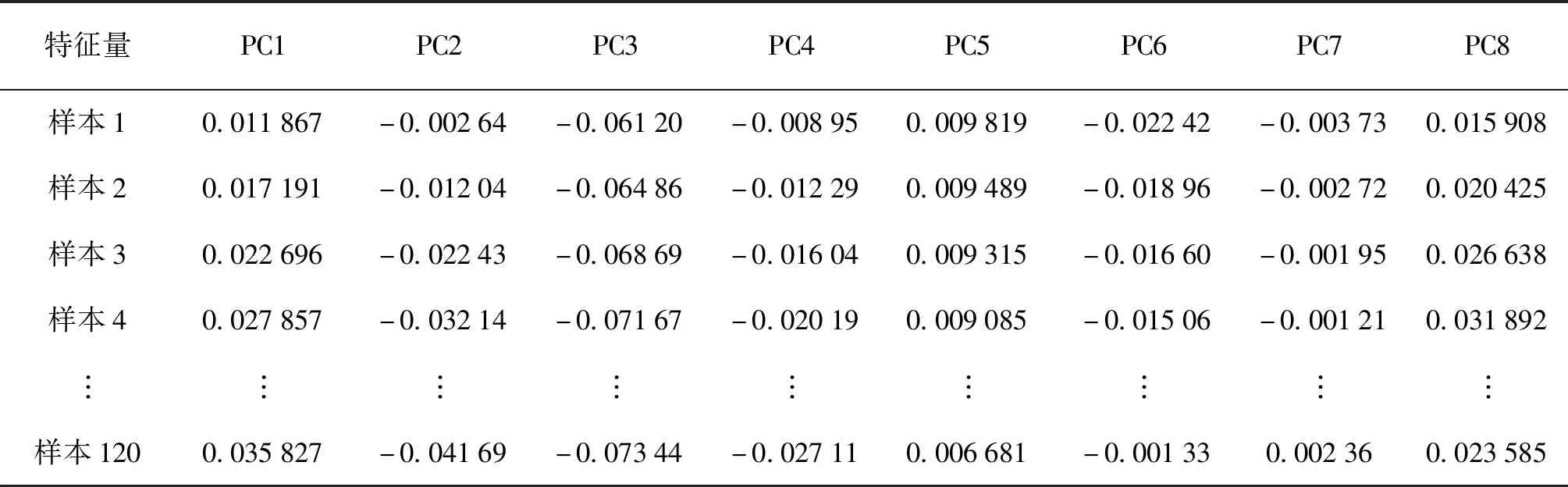
表2 LLE提取的特征数据Tab.2 Features data extracted from LLE
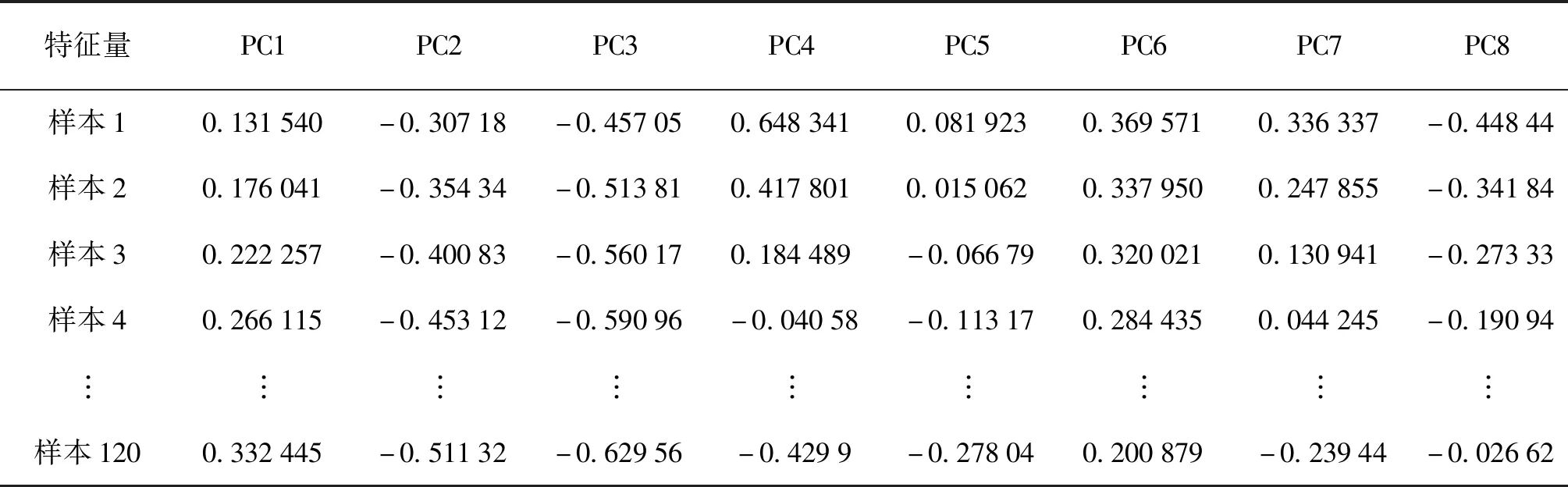
表3 PCA提取的特征数据Tab.3 Features data extracted from PCA
3.3 实验结果和分析
采用LLE及PCA对降噪后的中药三维荧光光谱数据进行特征提取,然后分别构建LLE-RF、PCA-RF组合算法分类模型,即将LLE、PCA提取的特征向量输入到RF分类器中进行分类识别。由于训练样本和测试样本比例不同时,RF分类器有不同的分类效果,因此,设置训练样本和测试样本的比例分别为3:2、7:3、4:1、21:4时,观察分类识别的正确率,记训练集的比重r分别为0.6、0.7、0.8、0.84时从原始数据中有放回地抽取训练样本,建立相应的决策树,剩下的样本作为测试样本。
当采用LLE算法时,为了得到较好的嵌入结果,即寻找合理的k和d,当固定d取6时,k依次取2、3、4、5、6、7、8、9、10、11、12,分析RF分类正确率变化情况。按照同样的方法,分别固定d取7、8、9、10,k依次取2、3、4、5、6、7、8、9、10、11、12时,分析随RF分类正确率变化情况。图5为当比例r=0.6、0.7、0.8、0.84时,LLE-RF分类正确率变化情况。
由图5可看出,RF的分类效果与r、k以及d有关。k值越大,LLE得到的嵌入结果所代表的信息越丰富,同时要求本征维数d也要相应增大,因此,图5中的4个图都呈现波动性增长。由图5(d)可以看出,当r=0.84、k=8,d=8时,LLE-RF可以得到较好的分类效果,达到95%。
因此,本文选择LLE算法中k=8,d=8,RF中r为0.84时构建LLE-RF组合算法分类模型。为了验证LLE的有效性,将其与主成分分析进行比较,构建PCA-RF组合算法分类模型。
分类模型中均标记补气类为第1类,补阳类为第2类,补阴类为第3类,补血类为第4类,利用分类准确率与运行时间评价分类性能,分类效果如表4所示,两种算法分类模型预测结果如图6与图7所示。

图5 r不同时LLE-RF分类正确率变化情况Fig.5 The change ofLLE-RF classification accuracy rate with different r
由表4可以看出,LLE-RF与PCA-RF模型分类精度不同。LLE-RF模型的分类准确率达到95%,PCA-RF模型的分类准确率为90%。此外,LLE-RF模型运行时间较PCA-RF短。

表4 不同分类模型识别效果Tab.4 Recognition effect of different classification models
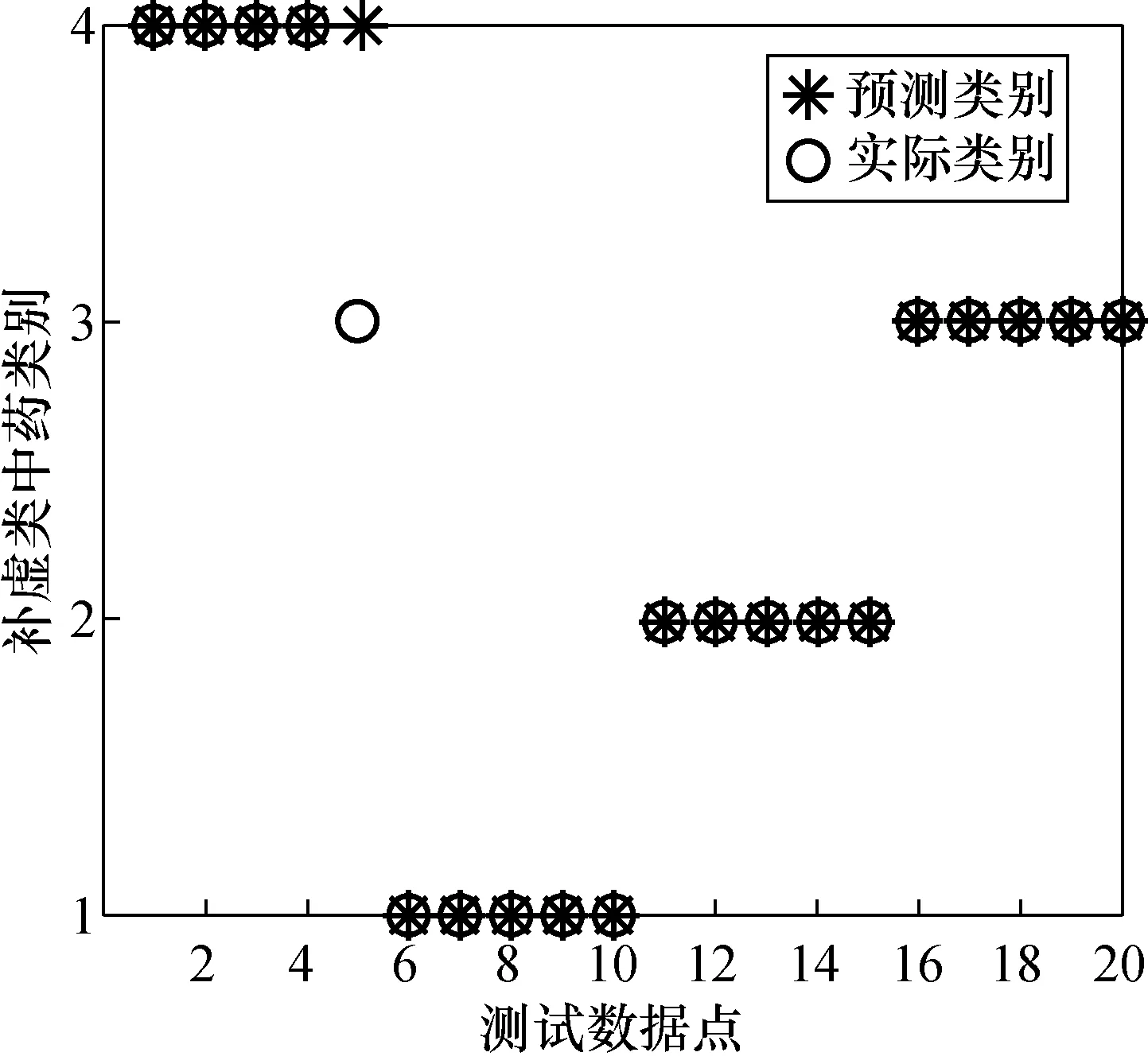
图6 LLE-RF模型预测结果Fig.6 LLE-RF model prediction results
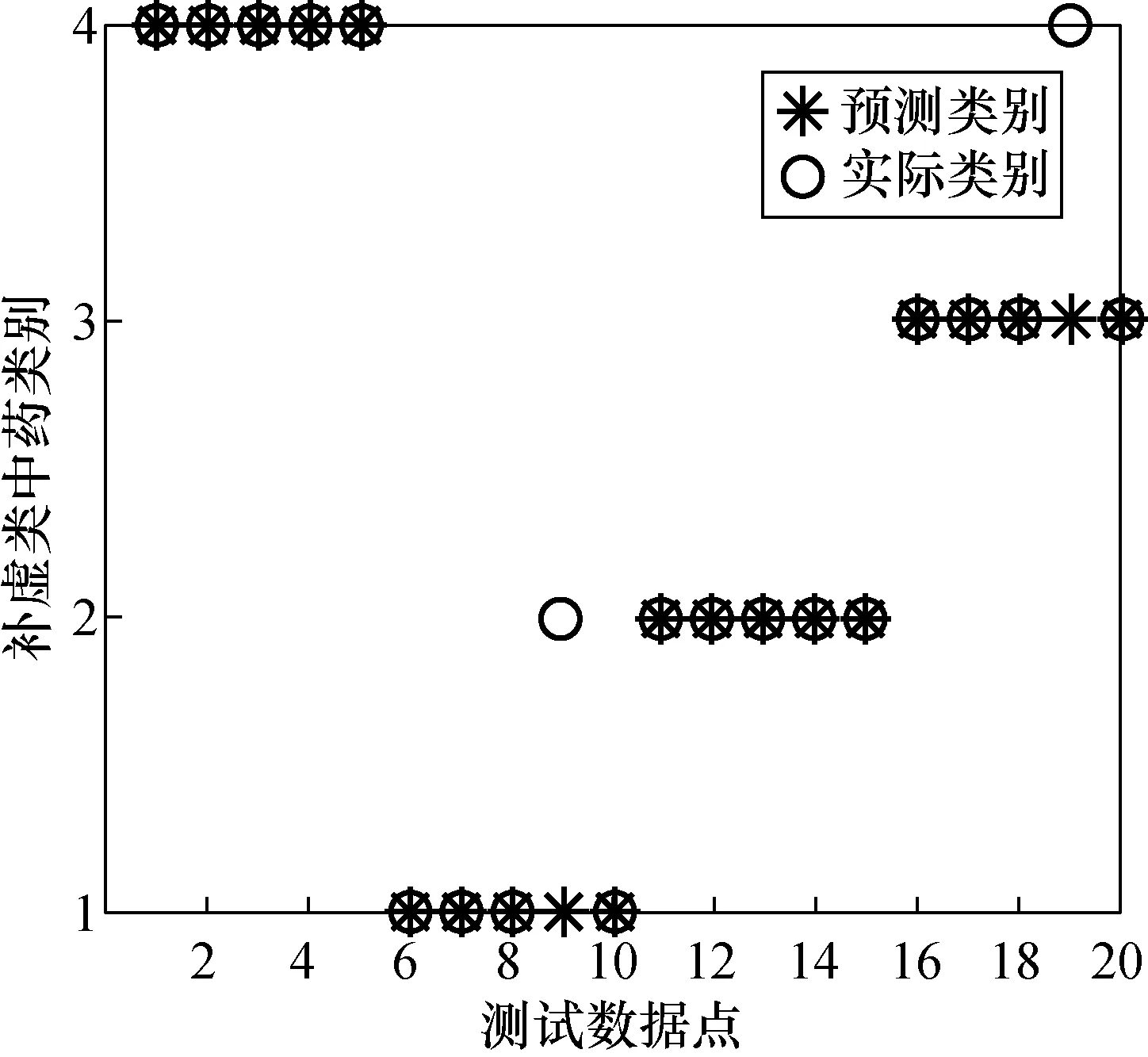
图7 PCA-RF模型预测结果Fig.7 PCA-RF model prediction results
由图6可以看出,LLE-RF模型中有一个样本被错误识别,实际类别为第3类,但被错误识别为第4类。
由图7可以看出,PCA-RF模型中有2个样本被错误识别,实际类别为第2类和第4类,但被错误识别为第1类和第3类。由于采用LLE提取特征时,通过局部的线性逼近整体的非线性,使降维后的特征数据仍然保持原有数据的拓扑结构,而PCA提取特征时,是从线性的角度提取了互不相关的特征来代表原始数据,因此,当提取中药三维荧光光谱特征时,对于RF分类器,采用LLE比PCA分类准确率高。
4 结 论
针对中药三维荧光光谱数据特征提取问题,本文在采用LLE算法提取补虚类中药三维荧光光谱的非线性特征基础上,构建了LLE-RF组合算法分类模型。实验结果表明:LLE特征提取算法在选择合理的近邻点数和本征维数基础上,可以得到较好的嵌入结果。在RF分类器中,通过选择合理的训练集与测试集比例,LLE-RF组合算法分类准确率优于PCA-RF算法。因此,采用LLE算法可以发现中药三维荧光光谱数据中的非线性结构。在后续的研究中,将对LLE算法进一步优化,更好地提取中药三维荧光光谱特征,提高分类精度。
