基于协同过滤的自适应Web服务QoS预测方法
2020-04-09郭志川黄逍颖
庄 崟,郭志川,黄逍颖
(1.江苏有线技术研究院有限公司,江苏 南京 210001;2.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190;3.中国科学院大学,北京 100049)
0 引 言
随着互联网技术的发展,Web服务的便捷性导致用户对它的需求逐渐增大。如今大量的Web服务充斥互联网,在增加用户选择的同时,也提出了更高的要求:面对相同种类和条件下的服务,除了满足功能性需求之外,用户希望得到更高的服务质量(QoS)。目前,服务QoS预测已经成为Web服务领域的一个热点问题[1-6]。这需要根据一些指标来对已有的服务进行衡量,在这些指标的对比之下,根据每一个用户的具体需求来对用户进行个性化的服务推荐,缩小用户的选择范围,从而更高效地享受相关服务。
QoS度量有多种方法[7-12],服务器端度量的QoS值(价格、流行度等等),服务提供商通常会在广告中展示内容,这些对于不同的用户来说都是相同的,但是在客户端度量的QoS值(响应时间、吞吐量、服务可用性等)在不同的用户之间却会因受到不可预测的网络连接和完全不同的用户环境的影响而大相径庭。需要对不同的用户获得精确的个人用户端Web服务的QoS值,而QoS值的准确测量需要对用户端得到的Web服务进行评估,因此选择一种合适的评估方法是非常必要的。但是在实际操作中,从用户角度去评测Web服务是很困难的。它具有如下缺点:(1)为了得到QoS信息,用户需要执行相关的服务调用,服务提供者可能会收取调用费用,同时会增加资源消耗;(2)随着网络上的Web服务数量的日益增多,测评所有的Web服务将很耗时;(3)为了连续监视Web服务的QoS性能,服务用户需要定期调用评估服务;(4)为了深度评测Web服务,服务用户还需要做更多的工作。因此,为了更好地对用户端QoS进行评价从而做到推荐,目前最流行的做法是对用户端的QoS以预测的方式进行,从而使用户不需要再对每个Web服务进行测评,并且可节约时间。
采用协同过滤的手段已被证明是当前预测精度最高的方法[13-16]。WSRec算法具有很好的效果[16],但是目前单一采用协同过滤的预测精度不高,尤其是在矩阵较为稀疏的情形下。基于此,文中将多种协同过滤方法进行动态组合,给出了一种基于协同过滤的自适应QoS服务预测方法,以提升用户体验。
1 算法描述
提出一种基于协同过滤的自适应QoS服务预测方法,解决现有的Web服务QoS预测方法当中精度较低的问题。方法流程如图1所示。
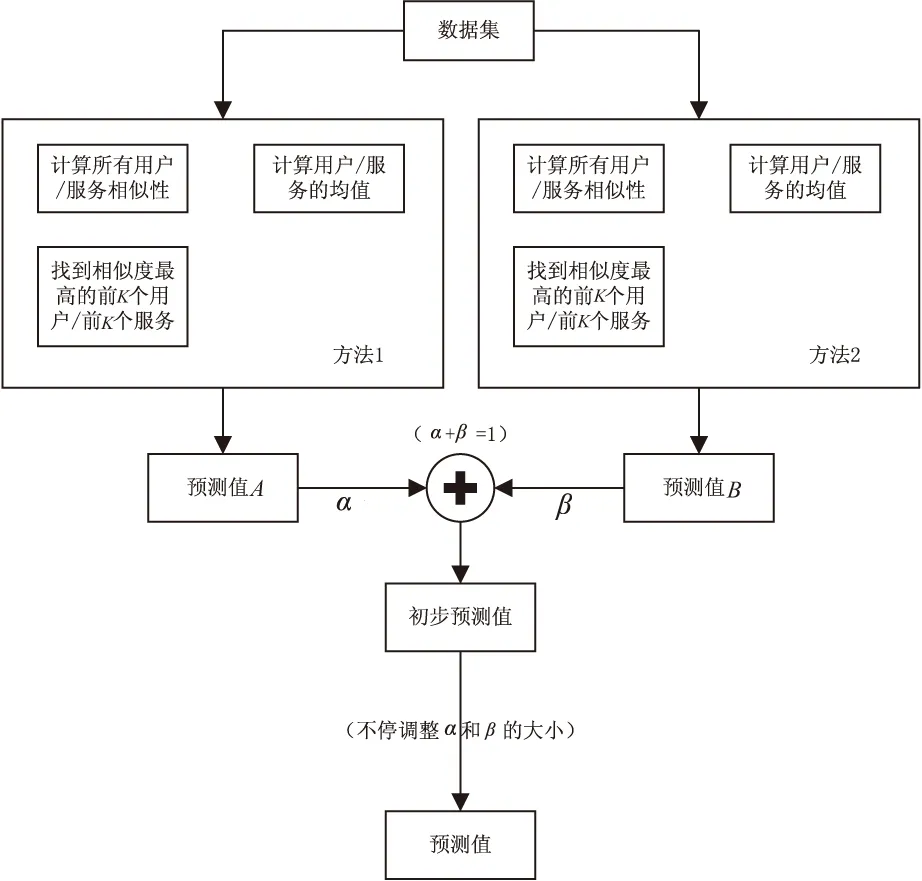
图1 基于协同过滤的自适应Web服务QoS预测方法的流程
具体的算法描述如下:
(1)用户端向服务端提出基于QoS的Web服务请求。
(2)服务端根据用户端提出的Web服务请求,以及已有的用户端的其他Web服务QoS数据,以及与该用户端相类似的其他客户端的Web服务QoS数据,生成用户-服务矩阵,其中每一列代表一种Web服务,每一行对应一个用户。
(3)在该用户-服务矩阵中,计算两两用户以及两两服务之间的相似度,然后对相似结果进行聚类分析;相似度的计算采用的是皮尔逊相关系数:
Sim(ui,uj)=
(1)
Sim(ui,uj)=
(2)
其中,u表示用户,i表示服务,ui表示第i个用户,si表示第i个服务。Sim(ui,uj)表示用户ui和uj的相似度,Sim(si,sj)表示服务si和sj的相似度。r(ui,s)表示用户ui对每个服务的QoS值,r(si,u)表示每个用户对服务si的QoS值。
(4)根据相似性找到对于目标用户的K个最接近用户,或者找到对于目标服务的K个最接近服务。记录下它们对应的相似度值。
(5)把步骤4记录的相似度值与K个用户(或者K个服务)的均值相结合,利用如下公式得到对该QoS值所做出的预测值A:
(3)
(4)

基于混合协同过滤的QoS服务预测方法,特征在于首先计算两两用户以及两两服务之间的相似度,然后对相似结果进行聚类分析,找到对于目标用户的K个最接近用户以及对于所需Web服务最接近的K个项目,并把计算出的相似度与K个用户(或者K个服务)的均值相结合,形成对该QoS值所做出的预测值A。
(6)同步骤1~步骤5,不同之处是在计算两两之间的相似性的时候,使用一种改进的UPCC和IPCC相关系数:
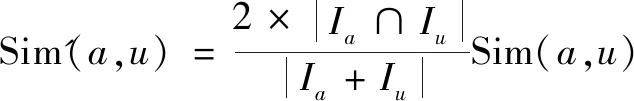
(5)
(6)
从而得到预测值B。
其中,|Ia∩Iu|是用户a和用户u共同调用的服务,Ia是用户a调用的服务,Iu是用户u调用的服务。|Ua∩Uu|是共同调用服务i和j的用户,Ui是调用服务i的用户,Uj是调用服务j的用户。
(7)把预测值A和B以一定的权值相结合,得到目标用户(或项目)的QoS值:

(7)
α+β=1
(8)
通过自适应调整权值α与β的大小,得到较好的QoS预测值。
以上所述的基于混合协同过滤的QoS服务预测方法,通过预测值A和B以一定的权值相结合得到目标用户(或服务)的QoS值。在不同的数据集里,通过调整权值系数的值,得到该条件下最优的QoS预测方案。
2 实验结果
基于WSDream(339*5 825)数据集来进行相应的实验,WSDream是一个公开的QoS方面的数据集。将数据集文件分别以8∶2的比例,划分为训练数据集和测试数据集。然后以训练数据集为输入,输出测试数据集中各用户-项目的预测评分。最后对预测评分进行协同过滤的评价指标评估:
平均绝对偏差(MAE)计算公式如下:
(9)
均方根误差(RMSE)计算公式如下:
(10)
这两个指标主要是通过计算预测值与实际值之间的偏差来评估目标方法的预测精度。
表2~表4分别是采样10%、20%、30%作为测试集之后得到的结果。结合3张表发现,文中方法在MAE、RMSE指标上优于单独使用WSRec(一种改进的协同过滤)方法,如表1所示。结合每张表上α的取值,在α=0.65附近时,MAE和RMSE可以达到最低值。
表2~表4显示了文中方法中α的取值对于预测精度(MAE/RMSE)的影响(分别为抽取10%/20%/30%的数据集作为测试集)。结合每张表上α的取值,在α=0.65时,MAE和RMSE可以达到最优值。

表1 改进方法与WSRec方法的比较

表2 α取值与预测精度的关系(抽取10%作为测试集,α的最优值:α=0.65)

表3 α取值与预测精度的关系(抽取20%作为测试集,α的最优取值范围:0.4<α<1)

表4 α取值与预测精度的关系(抽取30%作为测试集,α的最优取值范围:0.5<α<1)
针对不同的抽样率,MAE与α取值的曲线关系如图2~图4所示。

图2 10%抽样关系

图3 20%抽样关系
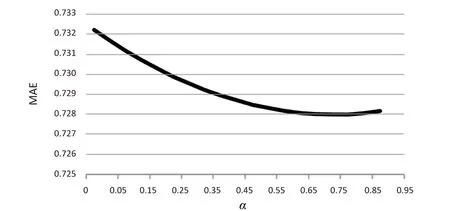
图4 30%抽样关系
3 结束语
采用协同过滤的手段是当前预测精度较好的方法,但是目前单一采用协同过滤的预测精度不高,尤其是在矩阵较为稀疏的情形下。该文有效改进了这一问题,使得QoS预测精度得到提高。提出的采用两种协同过滤进行混合的算法,可以通过自适应调整权值的大小,提高协同过滤算法的精度。该算法改进了皮尔逊相关系数法可能在数据稀疏的情况下对相似性给予过高估计的不足,从而提高了最终的QoS预测值的精度,同时指标上也优于WSRec方法。
