一种改进的TextRank关键词提取算法
2020-04-09李志强潘苏含胡佳佳
李志强,潘苏含,戴 娟,胡佳佳
(扬州大学 信息工程学院,江苏 扬州 225000)
0 引 言
随着信息化的快速普及,网页中的信息数据日益增多。面对海量的文本信息,如何准确、高效地对文章内容进行检索,成为目前的研究热点。对于文本的分析,一般会先从关键词入手,一篇文章的关键词不但可以概括文章的主题,还能反映整篇文章所表达的主要内容与情感倾向。因此,高效、准确地获取关键词,对于文本分类、自动摘要和文本检索至关重要。
近年来,国内外研究人员在关键词提取技术领域展开了大量的研究工作,同时也提出了很多关键词提取算法。其中主要算法有基于隐含主题模型的关键词抽取(LDA)[1]、基于TF-IDF词频统计的关键词抽取[2]和基于词图模型的关键词抽取(TextRank)[3]。上述三种算法因其简单易行而应用广泛。
其中,基于隐含主题模型的关键词抽取算法是根据文档和单词的主题分布相似度来计算单词的重要性,由于该方法一般依赖对语料库内容进行训练得到所需信息,因此,这种方法获取到的关键词的质量与训练语料库主题分布密切相关。基于TF-IDF算法的词频统计关键词提取(term frequency-inverse document frequency)主要通过对词语出现的频次来判断词语对文章的重要性,是一种成熟的基于统计的提取方法。该方法在关键词提取的过程中过度依赖词频特征,忽略了语义、上下文环境等其他特征。为此,往往会引入其他特征因子进行计算以此减少对词频的依赖。TextRank算法是基于图的排序算法,利用共现窗口实现部分词语之间的关系构建,对后续关键词进行排序,直接从文本本身中提取关键词。但是该方法没有分析词语重要性的不同是否会影响相邻节点权值转移的问题,并且没有利用文档语料库的整体信息,词语的权重信息并没有实际意义,不能区分连接上的强弱。
为了进一步提高关键词提取的效果与质量,许多学者对上述算法进行改进。郎冬冬等人[4]提出一种基于LDA和TextRank的文本关键短语抽取方法。顾益军等人[5]结合LDA与TextRank,使候选节点词语的重要性按文档集主题分布进行了非均匀转移。但是结果受训练语料库主题分布影响较大。张瑾等人[6]、谢晋等人[7]考虑了结合词语位置和词跨度的方法对TF-IDF权重进行改进,或者利用语义的连贯性,结合词频和词语位置特征进行加权分析[8]。另外也有部分学者引入信息熵[9]的方法。但这些方法在应用过程中都存在一定的问题,比如计算复杂度较高,或者在文章类型和语料规模上需要相当的规模。还有一些学者结合文章综合信息和引用新闻类别因子的方法[10-12],结合了其他特征信息进行加权,在一定程度上能够解决词频依赖问题。但这些方法未考虑关键词的词性以及关键词覆盖度不同所带来的影响。Biswas S K等人[13]、Yan Ying等人[14]提出了基于图的关键词提取方法,方法中分别考虑了词语的上下文环境,词语的位置,词语的中心性,词性等特征,修改词语的初始权重等,得到了不错的提取效果。
针对上述问题,基于文献[13-14]的启发,文中综合考虑词语对于单个文档与文档集的重要性来进行关键词抽取。选用TF-IDF与平均信息熵综合计算词语对于单文档与文档集的重要性,然后计算出词语的综合权重来改进TextRank词汇节点的初始权重以及概率转移矩阵。通过多组实验对比分析,经过改进后的方法能够更高效、准确地获取关键词信息。
1 相关技术
对在关键词提取过程中需要用到的相关算法进行介绍,主要有TF-IDF算法与平均信息熵算法。这两种算法主要用于词语对单个文档和文档集的重要性计算。
1.1 TF-IDF算法
TF-IDF算法的基本思想是:利用词语频次(term frequency,TF)和逆文档频率(inverse document frequency,IDF)相乘得到词语的权重值[15]。根据TF-IDF算法,词语权重WTF-IDF(i)的计算公式如下:
WTF-IDF(i)=TFi*IDFi
(1)
IDFi=log(N/DFi)
(2)
其中,TFi表示词语i在文档内容中出现的次数/文档内容的总词数,即词语i在文档中出现的频率,N表示语料库中文档总数,DFi表示包含词语i的文档数,IDFi表示词语i的主题表现能力。
根据上述公式可知,如果词语在某一篇文档中出现频率较高,但是在语料库中包含该词的文档数较低,则该词根据TF-IDF算法得到的权重值WTF-IDF(i)就越高,也就是说该词语可以在一定程度上表示文章的主题内容。反之,则说明该词语不是重要词语,不能表现文章的主要内容。
1.2 平均信息熵算法
平均信息熵的基本思想是:根据词频在不同文档中出现的频数,结合整体语料库计算所有词语对于单个文档和文档集的重要性,通过平均信息熵可以衡量词语在整个文档集中分布的均衡度。根据平均信息熵算法,词语权重WEntropy(i)的计算公式如下:
(3)
其中,fwk表示词w在文档k中出现的频次,nw表示词w在整个文档集中出现的频次,N表示语料库中文档的总数。
如果词i在各类别文档中出现频率相当,则其WEntropy(i)的值接近于最小值0,表示其并不能很好地表示文档的主题内容。反之,如果词语i在各类文档中出现频率差别很大,其WEntropy(i)的值接近于最大值1,表示其对文档主题有很好的表现力。
2 关键词提取算法
2.1 算法描述
传统的TextRank算法是将一篇文档转换成一张有向带权的词图模型,是将文本进行分割,分割成基本单元,即词语,每个基本单元看作是一个节点,每个节点之间的边由词节点之间的共现关系决定,而节点的重要性又由相邻节点指向数量决定。TextRank算法的计算方式如下所示。
(4)
构建TextRank关键词图G=(V,E),其中V为节点集合,E为节点之间的边集合;In(Vi)是节点Vi的入度点的集合,即指向节点Vi的节点集合;Out(Vj)是节点Vj的出度点集合,即节点Vj指向的所有节点的集合;Wji是节点Vj与节点Vi之间边的权重;d是阻尼系数,一般取值为0.85,其作用是表示当前节点向其他任意节点跳转的概率,同时能够保证让权重能够稳定的传递至收敛,最终计算每个词语的权重并进行排序,选取topN作为N个关键词并输出。
传统TextRank算法中,每个节点初始权重为1或1/N,即节点的初始权重相同,且节点权值均匀转移。但是通过研究发现,基于词语重要性加权词语转移概率的方法可以有效改进关键词提取的效果[16-17]。因此,文中选用TF-IDF和平均信息熵两个特征来计算词语的权重,用计算得到的综合特征信息来改进TextRank词汇节点的初始权重大小以及概率转移矩阵。
选取任意一个词i,定义词i的综合权重计算方式如下:
(5)
其中,WTF-IDF(i)是词语通过TF-IDF计算得到的权重值,WEntropy(i)是词语的平均信息熵权值。
根据TextRank算法,节点间的转移概率计算公式为:
(6)
根据式(6)可知,节点的权重迭代公式如下:
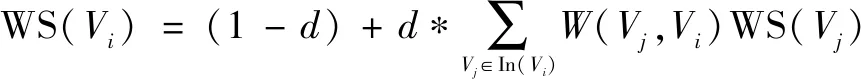
(7)
其中,W(Vj,Vi)表示节点Vj到节点Vi边的转移概率,即通过式(6)计算所得,WWeight(Vi)表示由式(5)得到的综合权重值。
2.2 关键词提取
基于改进的TextRank关键词提取算法的提取流程如图1所示。

图1 基于改进的TextRank关键词提取算法的提取流程
输入需要提取关键词信息的文本内容,关键词提取步骤如下:
第一步:文本预处理。对文本中的内容进行分词,词性标注,只保留名词、专有名词、动词、形容词和副词,并删除文本中的停用词。
第二步:权重计算。计算得到文本中每个词语的WTF-IDF,WEntropy,并计算综合权重WWeight。
第三步:关键词提取。构建基于词语综合权重的加权节点初始值及节点概率转移矩阵改进的TextRank模型,最终计算选择前N个权重比较大的词语作为关键词并输出。
3 实验结果及分析
文中的实验数据是在各大门户网站中随机抽取的包含多种主题的新闻数据、新闻内容字数、主题等信息。将每一篇新闻保存为一个文档,共500个文档组成语料库。对于数据集,采用多人人工交叉标注的形式提取关键词,每一个文档分别提取5,7,10个关键词。
对于相同的数据集,提取不同数量的关键词,实验中分别采用传统的TF-IDF算法、TextRank算法和改进的TextRank算法(共现窗口大小一个为5,一个为7)进行交叉对比。采用精度P(Precision)、召回率R(Recall)和F1值(F1-Measure)作为评价关键词提取的性能指标,指标计算公式如下:
(8)
(9)
(10)
3.1 实验结果
实验结果如表1所示。根据表1的实验结果分析可以发现,文中提出的方法在关键词提取方面优于传统的TF-IDF和TextRank算法。

表1 实验结果对比 %
3.2 实验分析
实验结果交叉对比如图2所示。
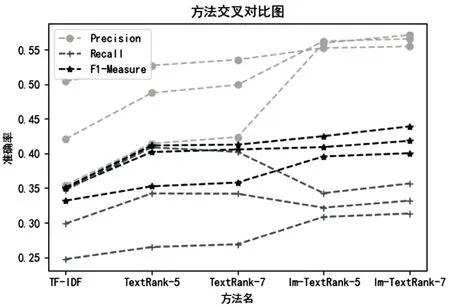
图2 实验结果交叉对比
观察对比图可以发现,随着提取的关键词数量的增加,传统的TF-IDF算法与TextRank算法的准确率呈现下降的趋势;而文中提出的改进的TextRank算法,随着关键词提取的数量变化,准确率相对稳定。因为根据词语的综合权重进行计算,关键词相对较为集中突出,权重相对较大。
此外,可以发现,传统的TextRank算法的共现窗口大小对准确率也有影响。因为共现窗口的大小决定可权重转移概率矩阵的稠密,从而影响关键词的提取结果。当共现窗口为7的时候,提取的关键词准确度要比共现窗口为5时高一些。
总之,文中提出的改进方法,在精度P(Precision)和F1值(F1-Measure)方面均高于传统方法,召回率(Recall)基本相当。这个基本可以证明,该方法在关键词信息获取方面较传统的TF-IDF和TextRank算法更加高效、准确。
4 结束语
一篇文章的关键词不但可以概括文章的主题,还能反映整篇文章所表达的主要内容与情感倾向,所以对于提取的关键词信息的准确率有较高的要求,这样才能够相对准确地表达文本的主题内容。因此,高效、准确地提取关键词信息,对于文本分类、自动摘要和文本检索至关重要。
提出了一种基于TextRank的改进算法。针对传统TextRank算法没有考虑词语本身的重要性,以及文档整体信息等不足之处,该算法选用TF-IDF算法与平均信息熵算法计算词语的重要性,通过计算词语的重要性对不同词语赋予不同的权重,根据计算得到的词语权重改进TextRank算法词汇节点的初始权重以及概率转移矩阵。该算法提高了关键词提取的准确度,并且操作简单,无须进行训练和人工干预,具有较强的通用性,能够满足对于一般文章的关键词提取需求。同时,可以结合更多的词语特征、词语上下文的语义环境等对该算法进行完善,这也是接下来研究的主要方向。
