基于WOSAPI辅助准确检索学者论文程序的设计与实现
2020-04-07高营
高营

摘要:如何准确识别学者的研究成果是科研人员、管理人员、图书馆员等亟待解决的问题,WOS等数据库本身的作者检索功能难以准确检索出学者所发文献。本文利用Python语言编写程序,通过WOS API接口获取数据,并利用正则表达式进行作者和地址的匹配筛选。研究表明,该方法能准确匹配作者及地址信息,提高检索效率。
关键词:文献检索;Web of Science数据库; Python;正则表达式
中图分类号:G254 文献标识码:A
1 引言
深圳大学城图书馆与利益相关方合作建设的深圳学者知识库,学者论文采用自动采集和人工提交相结合的数据采集模式[1]。数据建设第一阶段是纯手工阶段,需要根据学者简历人工检索学者当前及以前工作机构的科研成果。此外,科研人员在研究工作中需要追踪相关专家发表的文献,学校或机构管理人员对学者进行评价考核等需要了解学者的发文准确情况,图书馆员在学者评估、情报研究或学者库建设等工作中也需要准确获取学者的所有文献。如何准确识别某位学者的研究成果是科研人员、管理人员、图书馆员等面临的问题。虽然在Web of Science(WOS)、Ei Village(EI)、Scopus等数据库检索时均具有作者检索功能,其作者检索是根据作者姓名和机构或地址字段组合进行检索,会因为作者重名或英文姓名类似等导致检索结果不够准确,需要进行大量的筛选检查工作[2]。中文作者姓名由于重名、同音字、缩写名相同等会带来更多重复现象,给查准查全学者论文带来很大困扰。尤其是在WOS数据库中进行作者检索时可以组合检索作者姓名和地址,但是其匹配的是所有作者的地址,在检索结果中会出现很多在其他机构的同名或同音作者,仍然需要逐篇进行检查筛选。
如何消除姓名拼写歧义,准确对应学者和其研究成果,已经有很多学者在不同方法上进行了很多工作,但是目前一直没有很完美的解决方案。其中一个研究方向是利用智能算法、机器学习、作者合作网络等进行姓名消歧,该方向仍然在发展过程中,离完全替代人工还有一定差距[26]。另一个研究方向是以ResearcherID、 ORCID、 ThuRID等为代表的学者标识符,可以对应每位学者及其发表的文章,但需要作者本人进行维护,受到作者意愿等影响[79],并且过去发表的论文中并没有提供相应的作者标识符,目前仍很难适应于所有学者的检索。WOS、Scopus等数据库商也利用算法对作者数据进行了一些作者归并工作,部分作者数据能够比较准确,但很多的学者数据仍有较多的错误数据[2]。
2008年以后WOS数据库对每位作者都分别标注了对应的地址[10],但数据库中作者检索的方式分别匹配作者姓名和地址,丢失了作者和地址间的对应关系,也就是说文章合作者中包含所检索地址的其他机构中相同作者姓名拼写的文献也会出现在检索结果中,会出现作者姓名和地址错误搭配的情况,因此会带来很多不准确的检索结果,需要人工筛选检查。本文尝试在WOS检索过程中,利用程序对作者和相应地址进行匹配筛选,精确匹配所限定的作者姓名及地址,筛选去掉其他机构中同名作者的情况,研究显示可以显著提高检索效率和准确率。
2 设计与实现
2.1 设计思路
利用Python编写程序通过WOS API获取作者检索结果,按照自定义的正则表达式进行作者和地址匹配筛选,筛选出作者及地址均满足筛选条件的文献,再进行人工检查确认,可根据筛选情况对检索式和筛选正则表达式进行修改并再次进行筛选,最后完成筛选并得到准确的学者论文列表。
2.2 编程语言Python
Python由荷兰人Guido van Rossum创造,第一版发布于1991年,是近年来最热门的编程语言之一。由于其有丰富的标准库和其他一些扩展库,比较接近自然语言,可以用较少的代码完成一些复杂的工作,现在广泛应用于Web开发、云计算、大数据等领域[11],我们选择Python作为开发语言。
2.3 WOS平台API
WOS Web Services[12]是基于SOAP (Simple Object Access Protocol,简单对象访问协议)的API,用于检索和获取Web of Science数据库订阅内容。可以通过程序接入该API接口进行WOS检索。该API有两个服务接口,授权接口WOKMWSAuthenticate是身份验证和会话管理服务,检索接口WokSearch提供数据检索服务。可以在学校或机构IP范围内通过授权接口获取授权信息,然后通过WokSearch检索接口进行检索和获取数据。通过该API可以获取到格式规范的XML数据,便于后续处理工作。同时由于仅获取所需要的数据,不需要打开整个网页,可避免受到网页读取速度或网站改版等的影响。
2.4 正则表达式及作者匹配规则
我们采用正则表达式来精确匹配作者姓名和地址。正则表达式由一系列ASCII码字符构成,可以精确匹配一组满足条件的字符串[13]。其中一部分字符作为元字符,与普通ASCII码字符不同,用来表示特殊的含义。常用的元字符[9]有点号(.)、星号(*)等,具体含义及示例见表1。
(2) 三个字姓名可能的拼写形式有:Sun Shuqing, Sun Shu-Qing, Sun, s.-q, Sun SQ, Shuqing S, ShuQing Sun或Shu-Qing, Sun等。筛选正则表达式如下: 同前一个正则表达式类似,该正则表达式也可以精确匹配我们需要的作者姓名的各种不同的拼写形式,而排除不符合我们需求的作者,从而可以筛选得到符合条件作者的准确数据。
2.5 地址匹配规则
例如我们想检索清华大学深圳研究生院的作者发表文献的地址所需要的正则表达式为:tsing[,\s\W]*?hua.*?univ.*?shenzhen。该表达式可以匹配包含“Tsinghua univ”或者“Tsing hua univ”并且含有“shenzhen”的所有地址。如果想具体限定到某个学院的学者还可以加入更多的限定词,使检索更加准确。比如想限定到材料學院,可以加入其中的一个单词Material 的缩写部分“mat”。限定词要根据筛选情况调整使用,避免范围过大增加不准确结果,也要避免范围太窄漏掉需要的结果。
2.6 实现过程
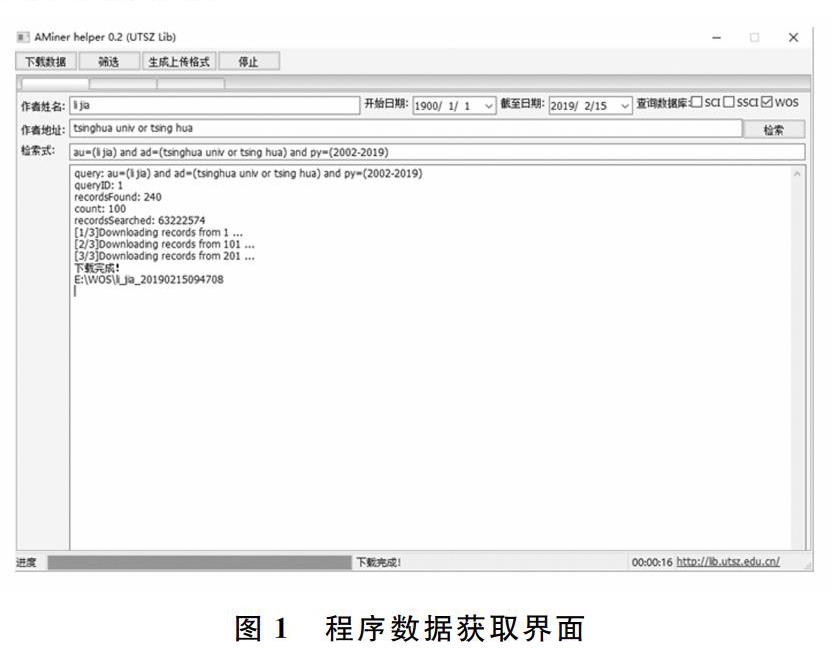
程序共有两个步骤,第一步是数据获取,第二步是数据筛选。数据获取过程首先利用Python的suds库访问WOS API来获取数据,通过授权接口的authenticate来获取授权会话session SID,并将获得的授权信息加入搜索进程,见图1。
然后利用WokSearch服务的search、retrieve接口来获取数据,并保存到本地文件。其中Search操作可以提交搜索并返回结果,该结果与网页界面高级检索功能返回结果一致;retrieve可以获取检索结果内容。程序根据我们输入的作者姓名和地址信息生成相应的检索式进行检索、获取数据,并保存为本地文件。考虑到有可能已经优化过检索式的情况,我们也可以直接在程序界面输入检索式进行数据下载。
第二个步骤是数据筛选。程序自动导入上一步骤下载的数据,对每篇文献进行处理,进行作者和地址的对应筛选。程序可以根据上一步输入的作者姓名自动生成相应的正则表达式,根据作者地址信息修改相应的正则表达式并进行筛选。查看筛选结果界面可以显示筛选匹配出的作者姓名和对应地址,在程序界面可以快速查看筛选情况,并可以删除一些明显错误的数据,并可以重新生成WOS的检索式,返回WOS网站进行详细确认或进行其他分析工作。
3 应用分析
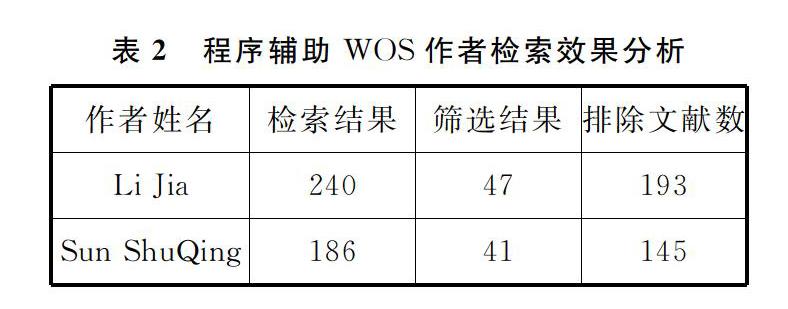
以检索清华大学深圳研究生院李佳老师发文为例,我们输入姓名Li jia,地址tsinghua univ or tsing hua,程序会自动生成检索式au=(li jia or li j or jia li or j li) and ad=(tsinghua univ or tsing hua) and py=(1900-2019),并开始下载数据。由于这个姓名拼写非常简单,并且包含缩写li j的姓名有非常多的其他可能姓名拼写,所以检索结果非常多,该检索式有6 477条检索结果。这种情况我们一般需要对检索式进行修改,避免下载太多数据。其中最常用的修改方式是仅保留li jia的姓名全称拼写形式,之所以可以仅使用作者全名进行检索是因为2006年及以后出版的论文记录中,会包含作者全称和简称两种形式的作者姓名[10],所以对一些比较年轻的学者我们可以仅采用姓名全称进行检索,以增加准确度。另外也可以根据学者简历,修改地址增加更多限定,还可以修改检索时间范围,缩小检索范围,以方便更快速的数据下载。本例中我们修改检索式为au=(li jia) and ad=(tsinghua univ or tsing hua) and py=(2002-2019)后,检索结果为240条,可以大大节省下载时间。
通过该例子我们可以看到,程序可以帮助我们过滤清华大学其他院系的相同姓名拼写Li Jia老师的论文,也可以过滤合作者中包含清华大学学者的其他机构的姓名拼写为Li Jia老师的论文,以及过滤筛选姓名的一部分为Li Jia的学者的论文,经仔细验证检查所排除的论文均为错误数据,我们仅需要核对筛选出47篇文献姓名准确为Li Jia 并且相应地址为清华深圳的学者的论文,而不需要再去确认全部的240篇文献。可以明显节省人工检查的时间,提高效率。
在检索和筛选过程中,必须紧密结合学者履历情况,制定检索式和筛选条件。以检索清华大学深圳研究生院生命与健康学部孙树清老师论文为例,孙老师2006年以前也有很多论文发表,检索时编辑检索式姓名需要采用全拼和缩写形式共同检索,检索结果会包含清华大学北京本部化学系姓名拼写SUN Suqin (Sun SQ 姓名简写相同)老师的文章,利用本程序的筛选可以较好地排除这种情况,见表2。
4 结语
笔者作为深圳学者库建设的主要参与人员,建设过程中由于要手工检索大量学者的发文,并且需要尽量准确全面检索学者的所有论文,筛选过程中需要大量的精力,并且容易出错,时间紧任务重,为了提高效率和准确率,编写了本文的辅助工具。本程序可以精确匹配作者姓名拼写全称及简称,避免检索结果中部分包含所检索作者全称及简称的其他姓名的情况,并且可以进行作者和地址的对应,筛选去掉其他机构中与所检索作者姓名拼写相同的情况,可以减少需要检查筛选的文献数量,能在一定程度上辅助检索结果的筛选,提高检索效率和准确性,希望能给有类似需求的同行提供借鉴。
参考文献
[1] 闫伟东.学者知识库建设探究——以深圳学者知识库为例[J].图书馆建设,2018(12):57-62.
[2] 范午攸.一种针对已知作者的姓名消歧方法[J].图书馆杂志,2018(12):56-63.
[3] 翟晓瑞,韩红旗,张运良,等.基于稀疏分布式表征的英文著者姓名消歧研究[J].计算机应用研究,2018(12):1-7.
[4] 付媛,朱礼军,韩红旗.姓名消歧方法研究进展[J].情报工程,2016(1):53-58.
[5] 侯海东,洪腾龙,徐建良.SCI论文作者自动识别方法研究[J].软件导刊,2018(8): 57-60.
[6] 郑威杰.科技文献作者消歧方法研究[D];杭州:杭州电子科技大学,2017.
[7] 窦天芳,张成昱,张蓓,等.ResearcherID现状分析及应用启发[J].图书情报工作,2014(4):40-45.
[8] 魏中青.ORCID国际学术身份证在我国科技期刊中的应用[J].科技与出版,2015(5):101-104.
[9] 谢华玲,郑菲,陈朝晖.ISI Web of Knowledge平台新增功能在科研中的利用分析[J].现代图书情报技术,2009(9):82-85.
[10] CLARIVATE.Web of Science Core Collection Help[EB/OL].[2019-09-20].https://images.webofknowledge.com/data/WOKRS515B5/help/WOS/hp_full_record.html.
[11] 姜安印,冯龙飞.基于Python的长文本比较研究——以《管子》与《国富论》经济思想比较为例[J].图书与情报,2018(2):67-73.
[12] CLARIVATE. Web of Science Web Services Expanded HELP[EB/OL].[2019-09-20].http://ipscience-help.thomsonreuters.com/wosWebServicesExpanded/WebServicesExpandedOverviewGroup/Introduction.html.
[13] 付哲,李軍.高性能正则表达式匹配算法综述[J].计算机工程与应用,2018(20):1-13.
