针对不平衡数据的改进的近邻分类算法
2020-04-07王彩文杨有龙
王彩文,杨有龙
西安电子科技大学 数学与统计学院,西安710126
1 引言
分类是预测建模中最重要也是应用最广泛的一项技术,它已被应用于商务[1-2]、医学[3-4]、工程[5]等各个领域[6]。比较经典的分类方法如决策树分类法[7]、最近邻分类法、神经网络[8]、支持向量机[9]和朴素贝叶斯[10-11]等。这些算法在数据集类别相对平衡时分类性能非常好,但类别分布不平衡时,它们的分类效果差强人意。现实生活中几乎所有的数据都存在类别分布不平衡的情况。例如,某银行欺诈检测系统中欺诈用户信息,地震监测中心存储的极少量的地震信息,某航空公司近十年的飞机失事事件信息等。对这些数据的正确分类具有重要的实用价值。
由于不平衡数据的复杂分布不易捕获,导致目前关于此方面的技术依然存在很多不足。因此,研究一种有效的不平衡数据分类技术十分有意义。
本文提出一种基于密度的近邻算法,用于处理不平衡数据分类问题,主要贡献为:
(1)用核密度估计方法计算数据的各个类别的密度并完成对数据的密度定位,此策略敏锐地捕捉了数据的局部分布特征。据所知,目前没有文献用核密度估计方法求数据的类别密度,并且将其与K 近邻结合应用于不平衡数据分类问题;
(2)动态近邻选择算法综合了数据的类密度信息和距离信息,成功地区分了与查询实例距离相等的实例;
(3)本文提出的DNN 算法既可用于二元不平衡数据分类,也可用于多元不平衡数据分类。DNN 算法提高了传统K 近邻算法(KNN)的分类性能,并且对不平衡数据的分类性能良好。
2 相关工作
近年来,不平衡数据分类问题已经取得了诸多有效成果[12-20]。这些成果大致可以分为两类:数据层面和算法层面。
数据层面的方法旨在降低类别与类别之间实例数量的不平衡程度。一般通过数据重采样的方法,使原本不平衡的数据变得相对平衡,从而使采样后的数据可以应用传统的平衡数据的学习算法进行准确分类。它包括过采样[12-15]、欠采样[16-17]和混合采样[18]。SMOTE[13]算法是一种经典的过采样技术,在少数类实例的连线上随机生成少数类实例,由此生成无重复的新的少数类实例,从而组成新的平衡数据集。SMOTE算法虽然平衡了数据集的类别,但同时也可能造成过生成、过泛化,或者改变原始数据分布的问题[21]。相反的,欠采样方法通过舍弃部分多数类实例平衡训练集。这种方法的缺陷,是舍弃多数类实例具有很大的不确定性,可能会丢弃对分类有用的实例,这些实例作为构建决策边界的重要信息,可能会导致决策边界失真。混合采样是过采样和欠采样的结合体。以上这些方法通过调整类的不平衡程度,增加算法对少数类的敏感度,从而达到提升分类性能的目的。
算法层面的方法是指,改进传统的分类器,使之适应不平衡数据环境,其主要目的是减缓分类器对多数类的偏向。代价敏感学习是算法层面中一种常用的技巧,它为实际属于少数类但被错分成多数类的实例赋予更大的错分代价,避免产生过多的假负错误,它也常与数据层面的一些方法结合。Meta-Cost[22]是代价敏感学习中的一种广泛应用的经典策略。
尽管重采样和代价敏感学习可以增加少数类的先验概率,但是它们不能改变查询实例的局部不平衡,而这种局部的不平衡才是算法真正需要捕捉的信息。KNN 作为一种局部性分类器,可以有效捕捉数据的局部分布信息。从这个角度来讲,它是处理类别不平衡问题的一个好的选择。
以K 近邻为基础的不平衡数据分类方法有很多,如代价敏感的K 近邻方法[23]、类置信度加权的KNN 算法(CCW)[24]、偏向正类的最近邻算法(PNN)[25]、用于处理稀有类的最近邻分类算法(KRNN)[26]等。这些方法都是用数据的观测频率或估计频率捕捉数据的局部分布特征,且采用加权的方式增加少数类实例的学习敏感度。除此之外,这些方法在选择查询实例的邻居时,都是根据原始空间中的实例与查询实例的相似性(例如,欧氏距离)将所有实例映射到一维空间。因此,与查询实例距离相等的两个实例无法在这些算法中进行区分。
基于它们的不足,本文提出DNN算法,它是一个属于算法层面的方法。首先,用核密度估计计算所有数据的类密度,以此对查询实例进行密度定位。其次,将查询实例和原始空间中的所有数据映射到由类别密度和距离构成的空间。最后,在映射空间中动态地选择查询实例的近邻并进行分类。为了进一步解释DNN 算法,用如图1所示的示意图展示算法的核心思想。
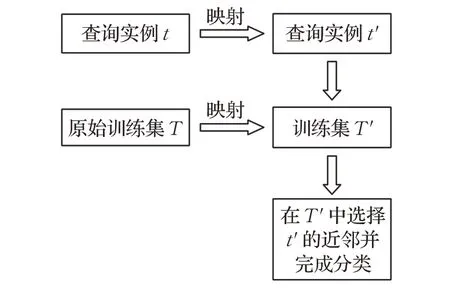
图1 DNN算法的核心思想的示意图
DNN 算法利用核密度估计方法计算数据的类密度,并且将其与距离信息结合。这使DNN 算法能够精确地捕捉数据的局部分布特征。此外,DNN 算法的近邻选择规则不仅考虑到邻居的距离相近性,还考虑到邻居的类密度相似性。这使DNN算法能够成功地区分与查询实例距离相等的两个实例。
3 预备知识
3.1 K近邻算法
K近邻[27]是一个简单有效的分类算法。给定邻居数量K 后,训练集中距离查询实例t 最近的K 个实例被选定为它的邻居。然后采用多数表决机制获得分类决策。这一决策过程可以表示为:
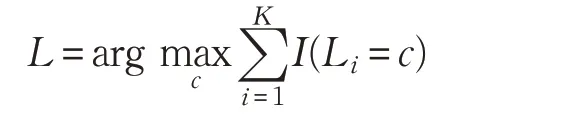
其中,I(A)是示性函数,当条件A 为真时,它的值为1,否则为0,Li为第i 个实例的标签。c 的取值为标签集合中的任何一个标签。
3.2 核密度估计
核密度估计方法可以估计出一个实例的周围实例的密度。若不对密度的类型做任何假设,且避免人为主观的代入先验知识,往往采用非参数的多元核密度估计方法估计实例的密度。关于非参数核密度估计已有大量文献,其中,变宽核密度估计[28]是性能最好的非参数密度估计方法之一。
假设D={x1,x2,…,xn}是d 维空间上数据集,它的实例量为n,那么它们的分布密度可以被估计为:
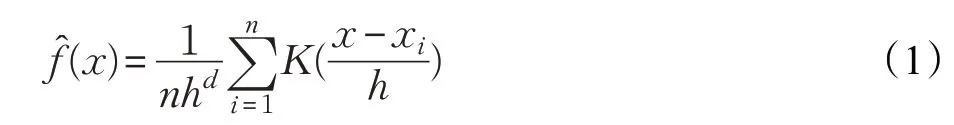
其中,K(x)是一个核函数,它满足下面的三个条件:
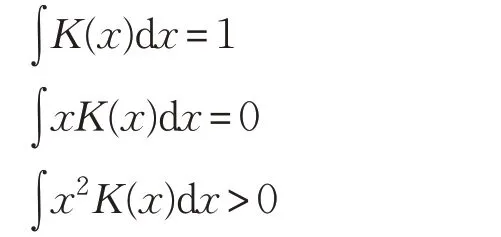
多元高斯核函数是最常用的核函数之一,由下面公式给出:
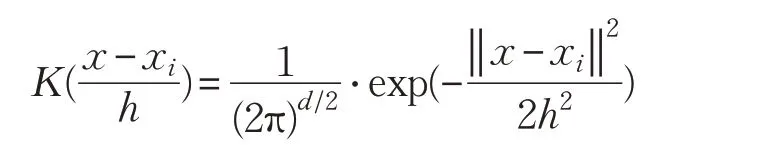
其中,‖ x- xi‖表示x 和xi的欧氏距离。h 为带宽,当维度为d,数据量为n 时,最优的带宽h 可以被计算为:
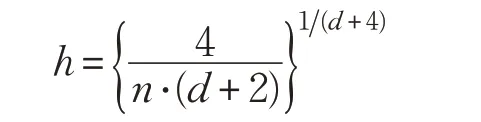
详细的推导可以参考文献[28]。
公式(1)是密度的一个渐进无偏估计量,利用这个公式不仅可以估计一个区域内实例的分布函数,还可以估计某一个实例周围的实例的分布函数。
4 基于密度的近邻算法
本章对提出的基于密度的近邻算法进行详细介绍。首先,给出算法涉及的一些理论知识,包括实例的类密度估计和查询实例的邻居的选择;其次,详细介绍算法的具体流程;最后,分析算法的时间复杂度。
4.1 实例的类密度估计
一维或者二维空间中的点的密度可以通过绘制图像的方式形象地表示。实际问题中数据的维度往往大于三维甚至是更高维,采用绘图的方式挖掘密度信息变得非常困难,多元核密度估计就可以解决这一难题。给定一个数据集,可以由核密度估计求出每一个实例周围的各个类的实例的密度。如果两个实例的各个类密度分别相等,说明这两个实例处于相似的类别密度环境中,可以合理地认为这两个实例存在某种联系。
受此启发,将其运用到不平衡数据的分类中。在有监督分类问题中,数据往往带有标签也就是类别,在密度估计的时候,必须对各个类别的数据加以区分。例如,在二元不平衡数据分类中,必须分别对正类(少数类)实例和负类(多数类)实例进行密度估计,否则,得到的无类别区分的密度是无意义的。利用多元核密度估计,可以得到一个实例的周围的每个类的实例密度。
对具有多个类别的数据集D={x1,x2,…,xn},设其标签集为Y={c1,c2,…,cy},其中类别ci(i=1,2,…,y)中的实例个数为Nci,则实例xi关于类别ci的密度计算如下:
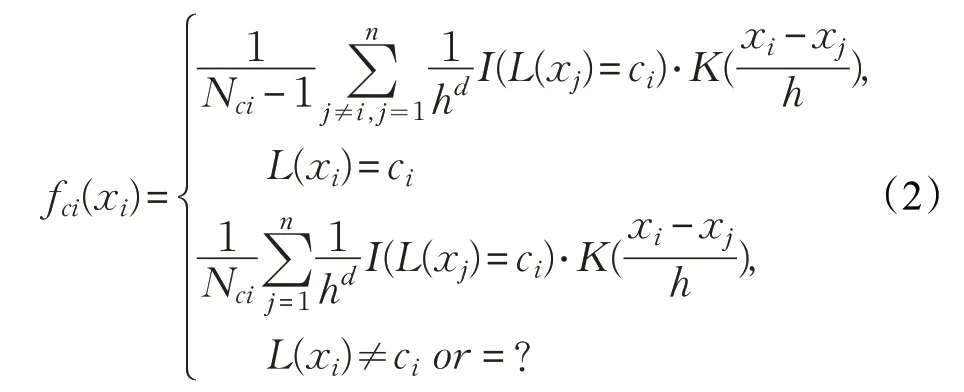
其中,L(xi)表示实例xi的标签,“?”表示实例的类别未知。
特别地,对于二元不平衡数据集,假设数据集中正类实例的个数为P,负类实例的个数为N,标签集为Y={c+,c-},那么实例xi的正类密度和负类密度分别计算如下:
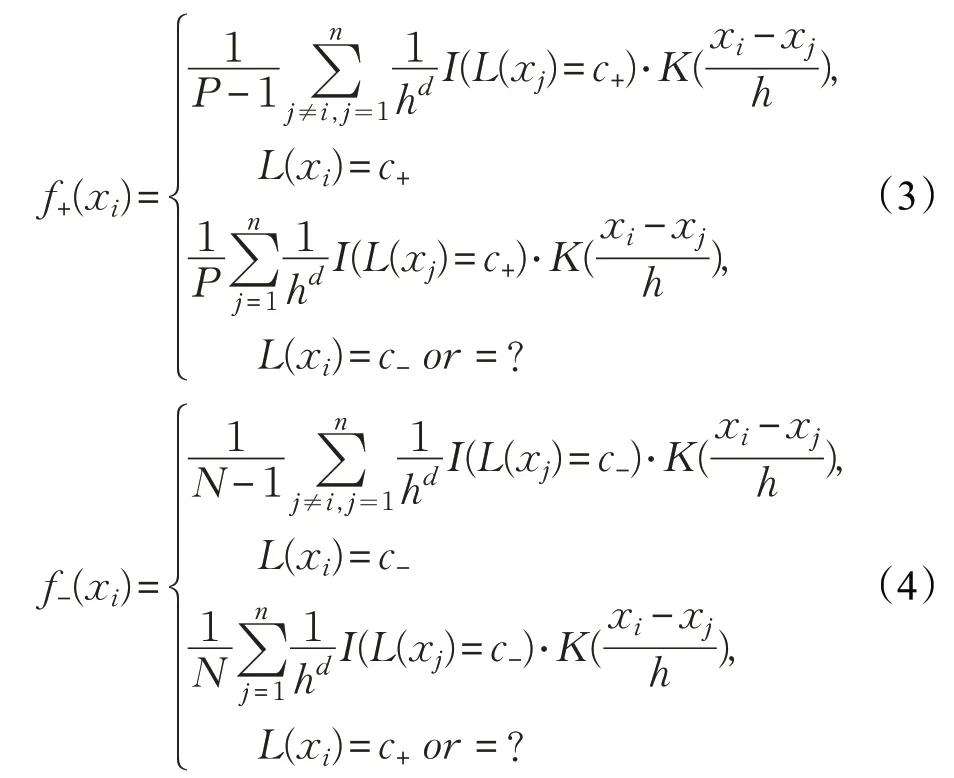
本文算法选择均值为0,标准差为1 的多元高斯核函数作为算法中的核函数:
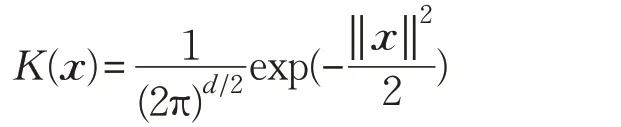
其中,‖ x ‖为数据向量x 的范数。
4.2 近邻的选择
本节提出一种新的近邻选择规则,利用训练集中所有实例的正、负类密度信息和距离信息动态地选择查询实例的近邻。总体思想是:先将待标记的查询实例t 和训练集中的所有实例映射到由正负类密度和距离构成的空间,然后在这个空间中动态选择查询实例t的近邻。
设T={x1,x2,…,xn}是有n 个实例的d 维训练集,标签集为Y={c+,c-},查询实例为t。对于训练集中的每一个实例xi,它的正、负类密度可以根据公式(3)和公式(4)计算,其中P=Ptrain为训练集中所有正类实例的个数,N=Ntrain为训练集中所有负类实例的个数。
训练集中实例xi与查询实例t 的相似度采用欧氏距离度量:

下面,将所有数据映射到由密度信息和距离信息构成新的空间。训练集中的实例xi=(xi1,xi2,…,xid)映射后的坐标为x′i=(f+(xi),f-(xi),d(xi,t)),t 映射后的坐标为t′=(f+(t),f-(t),0)。映射算法步骤如下所示。
算法1 映射算法
输入:训练集T,核函数K(x),查询实例t。
输出:映射后的训练集T′。
For xi∈T 执行以下操作:
1.由公式(3)和(4)计算f+(xi)和f-(xi);
2.由公式(5)计算xi到t 的距离d(xi,t);
3.得到xi在映射后的坐标为xi′=(f+(xi),f-(xi),d(xi,t));
End for
4.对得到的新的训练集按照属性归一化;
5.返回T′。
算法1 完成了原始数据空间的映射。第1 步到第3步求出所有数据映射后的坐标;第4步进行映射空间中的数据预处理;第5步输出映射后的训练集。
由于该映射算法需计算实例与查询实例t 的欧式距离,所以当t 改变时,需要将原始数据空间重新映射,这样会产生非常高的时间代价。为了降低时间复杂度,可以先求出整个训练集T 中每个实例的前两个坐标并保存,之后当查询实例t 改变时只需要求第三个坐标,以此避免大量的重复计算。
接下来在的三维映射空间中的训练集T′中选择查询实例t 的近邻。为了减少算法对负类实例的偏向,本文采用动态近邻选择的方法选择查询实例的邻居。动态近邻选择算法的步骤如下所示。
算法2 动态近邻选择算法
输入:映射后的训练集T′,查询实例t′。
输出:查询实例t′的近邻R(t)′。
1.将T′中的所有实例按其到查询实例t′的欧式距离由近到远排序;
2.遍历排序后的实例的标签,选择第一个“正-负”类分界线作为t′的邻域边界,所有距离小于这个边界的实例构成t′的近邻R(t)′;
3.返回R(t)′。
算法2 是一个动态近邻选择算法,T′中的“距离”蕴含密度相似性和欧式距离相近性。算法第1 步进行实例综合相似度排序;第2步选择近邻。当查询实例周围类别分布不确定时,邻居的个数也不确定,因此它是一个动态选取过程。需要进一步说明的是,算法2仅给出了二元分类时的近邻选择方法。事实上,多元问题与二元问题类似,在一定条件下可以将其转化为二元问题处理。
4.3 基于密度的近邻算法的过程
下面给出DNN算法的具体步骤。
算法3 基于密度的近邻算法(DNN)
输入:训练集T,查询实例t,核函数K(x)。
输出:t 的标签L(t)。
1.利用映射算法将查询实例t 和训练集T 中的所有数据映射到新的空间,T 映射后为T′,t 映射后为t′;
2.利用动态近邻选择算法在T′中选择t′的近邻R(t)′;
3.返回t 的标签:

其中|R(t)′|表示R(t)′中邻居的数量,|T |表示训练集中的实例个数。
基于密度的近邻算法大致分为两个过程:密度定位和分类决策。算法3 的第1 步和第2 步完成了对查询实例的密度定位,找到了与查询实例密度环境相似且距离相近的实例作为近邻;第3 步进行了分类决策。当邻域内某一类实例特别稀少甚至没有时,就会产生一种极端的决策。为了避免这种情况,本文在最终决策的时候采用了拉普拉斯平滑估计[29],即分子加1/| T |,分母加2/| T |。DNN 算法应用于多类不平衡数据集的步骤与二类不平衡数据基本一致。对于多类不平衡数据集时,首先利用公式(2)计算每个类别的类别密度,同时利用公式(5)计算实例之间的距离,然后将原始数据集进行映射,最终在映射空间选择近邻并完成分类。
下面用一个具体的例子解释DNN算法。
例1 预测鸢尾花的类型:从著名的鸢尾花数据集Iris(可在UCI 数据库[30]中下载)中选取20 个实例,构成一个维度为4 的训练集。每个实例的属性如表1 所示。下面根据DNN算法预测一朵萼片长、萼片宽、花瓣长和花瓣宽分别为5.5、4.2、1.4、0.2的花的类型。
查询实例t=(5.5,4.2,1.4,0.2),根据DNN算法的步骤,首先分别计算这20 个实例和t 在映射空间中的坐标。以x1为例,记x1映射后的坐标为x1′=(fv(x1),fs(x1),d(x1,t)),其中fv(x1)是x1关于versicolor 类的密度,fs(x1)是x1关于setosa类的密度。根据映射算法,x1′的坐标分量分别计算如下:
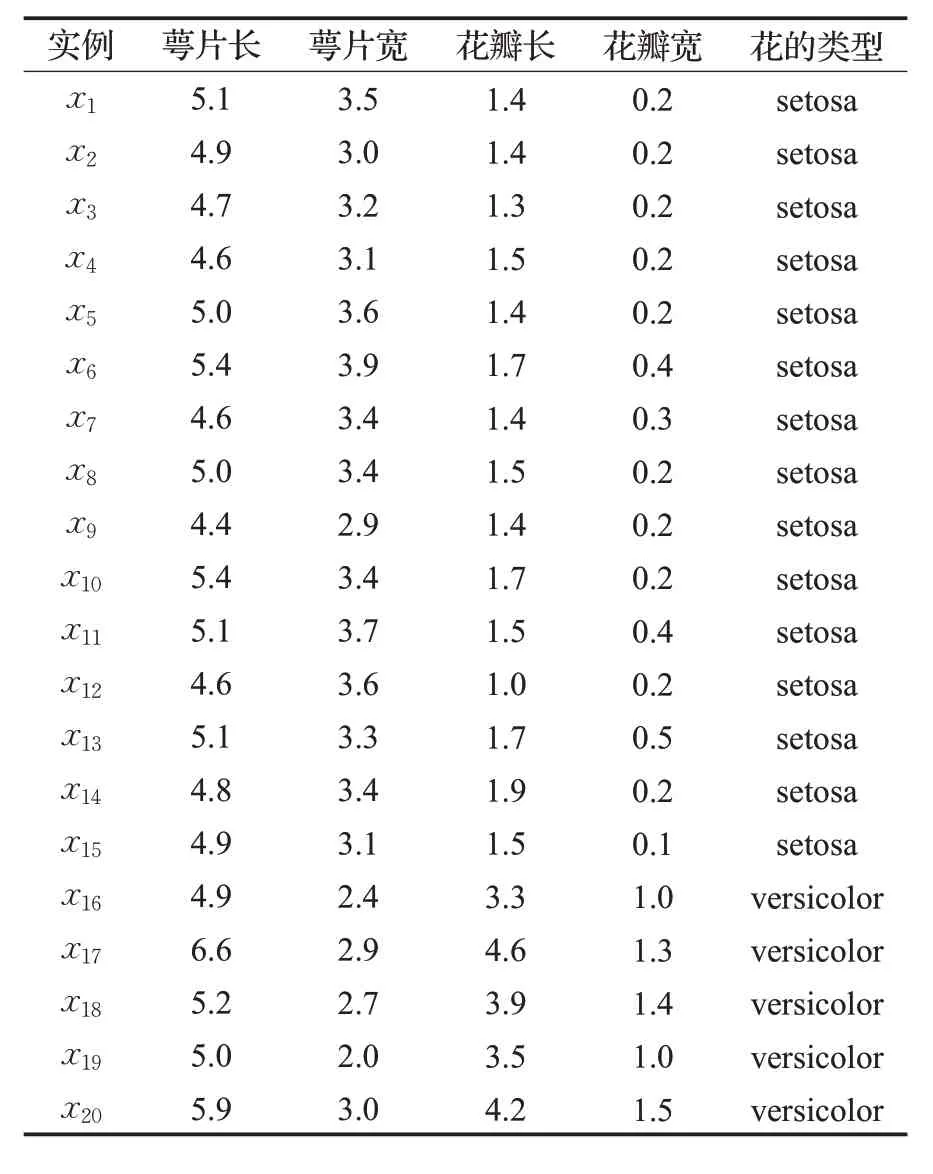
表1 实验选取的20个实例
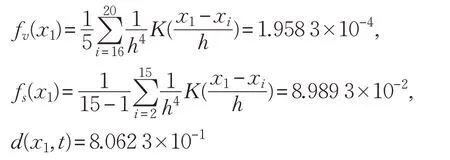
因此,x1映射后的坐标为:
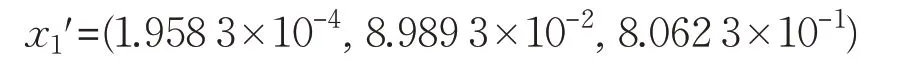
类似地,可以分别求出这20个实例映射后的坐标,按列归一化后组成新的数据集。t 关于两个类的密度的求法与上面方法类似,它映射后的坐标为:
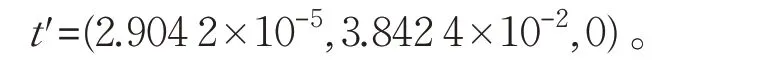
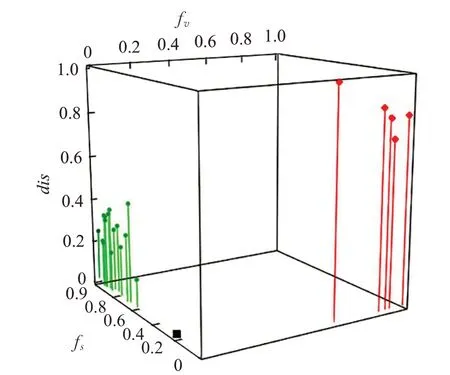
图2 所有数据映射后的三维图
根据得到的坐标值将所有数据映射到新的特征空间中,映射后的数据分布如图2 所示。其中,圆点表示setosa 类数据,小菱形表示versicolor 类数据,小矩形表示t′。3个坐标轴分别表示每个实例关于setosa类的密度、versicolor类的密度和与t 距离。
如图2所示,原始特征空间中的点被映射到一个新的三维特征空间中。下面,将图2中的点根据其到t′的距离排序后,由动态近邻选择算法选择t′的邻居R(t)′,可得:
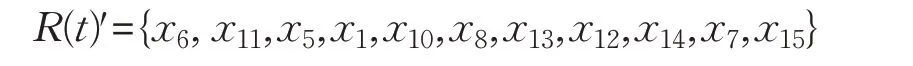
最终,t 的标签为:

其中c={setosa,versicolor}。因此,这朵萼片长、萼片宽、花瓣长、花瓣宽分别为5.5、4.2、1.4 和0.2 的花的类型为setosa。
4.4 算法时间复杂度分析
DNN算法主要由映射算法和动态近邻选择算法构成。对于映射算法,求出每个实例的新坐标需要的常数时间复杂度,遍历训练集T 中的每一个实例需要的时间复杂度为O(|T|),因此映射算法的时间复杂度为O(|T|)。对于动态近邻选择算法,时间复杂度主要在于将训练中的实例按照其到查询实例t 的欧式距离由近到远排序,使用最快的排序算法[31]需要的时间复杂度为O(|T|·lb(|T|)),在寻找邻域边界的过程中只需要将训练集遍历一次。因此,对于规模为m 的测试集,动态近邻选择的时间复杂度为O(m·|T|·lb(|T|))。综上,本文提出的基于密度的近邻算法的时间复杂度为O(m·|T|·lb(|T|))。
5 实验与分析
在15 个真实数据集上验证DNN 算法的有效性,并且将DNN算法与一些相关算法进行对比。算法由R语言实现,所有实验均采用了五折交叉验证。
5.1 实验环境与评价指标
在R环境下,与DNN算法进行比较的6种算法分别是:KRNN、PNN、SMOTE-KNN、SMOTE-J48、MetaCost-KNN 和MetaCost-J48,其中J48 算法即C4.5 决策树算法。这6 种算法中,以SMOTE 为前缀的算法属于数据层面的算法,以MetaCost为前缀的算法属于算法层面中的代价敏感算法。实验中,它们的参数取值保证了这些算法在大多数数据集上具有良好的性能,具体参数选择如下:
(1)对于KRNN,K=1;对于KNN家族中的其他算法,K=3。
(2)J48 设置“-M”选项(对于不进行修剪的叶子节点,至少允许有一个实例)。
(3)设置SMOTE 和MetaCost 不平衡的学习策略:SMOTE 中数据进行3 倍过采样。Meta-cost 中,代价设置为正负类实例数量比。
实验数据集是来自各个领域的15个真实数据集,这些数据集的规模、维数和不平衡程度均不同。其中,4个数据集(clean1、wine、glass 和user knowledge modeling)来自UCI 数据库,其余的数据集均来自KEEL[32]。这些数据集中的数据类别分布从低度不平衡(1.30)到高度不平衡(30.57)。为了便于分析并且提高实验效率,本文只在二类不平衡数据集上进行实验,对于具有多个类别的数据集本文人为的将其设置为两个类别。详细信息如表2所示。
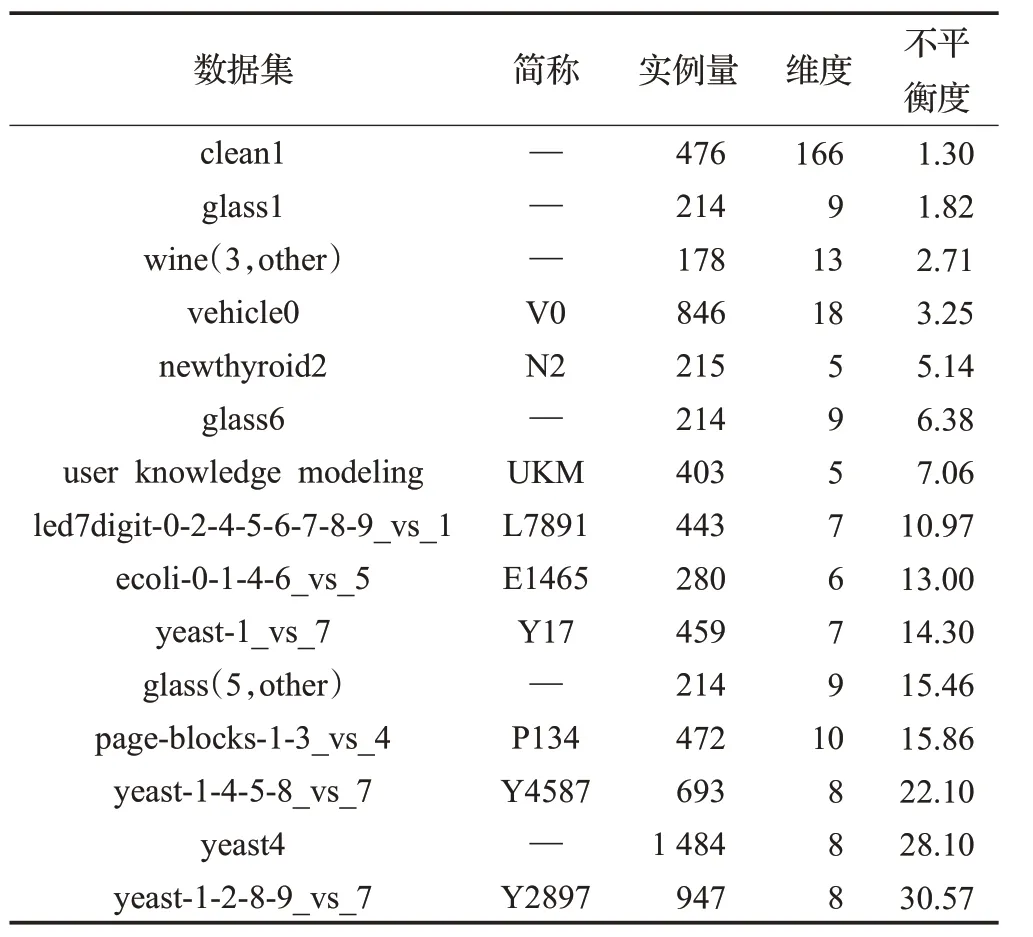
表2 实验数据集的收集与统计
本文采用3个评价指标对分类性能进行定量评价,分别是受试者工作特征曲线(ROC)[33]下面积(AUC)、F1度量(F1)和准确度(Acc)[34-36]。F1的计算公式如下:
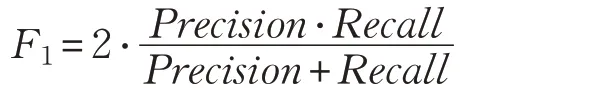
其中,Recall为召回率,Precision为准确率,计算公式为:
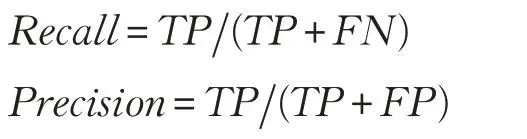
Acc给出了分类器正确预测的概率的估计,通过以下公式得出:
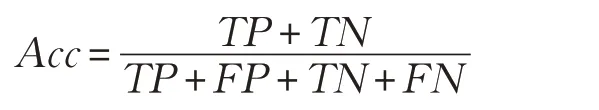
其中,TP、FP、TN 和FN 分别表示真阳性、假阳性、真阴性和假阴性的数量。
以上3 个指标均在0 和1 之间取值,并且值越大表示分类器的性能越好。
5.2 算法有效性实验
DNN 算法和其比较算法在15 个数据集上的AUC值、F1值和Acc值分别如表3、表4和表5所示。为了便于观察和分析,每个数值都被放大了100 倍,并且每个数据集对应的最优值用黑体表示。

表3 各算法在实验数据集上的AUC值

表4 各算法在实验数据集上的F1值
由实验结果可知,DNN 算法的AUC 值在12 个数据集上明显高于其他6 种算法;在其中的13 个数据集上,DNN 算法的F1值明显高于其他算法;在其中的14个数据集上,DNN算法的Acc值明显高于其他算法。总体上,DNN算法的平均AUC值、F1值和Acc值分别为:92.35、70.31 和94.36,均优于其他算法。由此可知,算法在尽可能分对少数类的情况下,并没有造成更多的假负错误。因此,DNN 算法对处理不平衡数据分类十分有效。

表5 各算法在实验数据集上的Acc值
为更加直观地展示算法的鲁棒性和性能优势,绘制7个算法在这3个指标下的箱线图,如图3所示。在各指标中,DNN算法对应的箱子的上四分位线、中位线和下四分位线都高于其他算法的相应分位线,并且DNN 算法的中位线十分靠上,也就是说DNN 算法的较大的值偏多。且各指标中DNN算法对应的箱子体积小于其余算法,这说明DNN算法具有良好的鲁棒性,同时也再一次说明了算法对各种不平衡程度的数据集均具有很好的分类性能。
最后,通过统计学的方法,进一步验证前文得到的结论,进行非参数的Friedmans检验和Holms后续处理,选择AUC 作为检验指标。首先,计算15个数据集上每种算法获得的平均排名(排名1 是最好的),如表6 所示。由此表可知,DNN算法获得了最高排名,并且它的排名比较其他算法具有明显差异。其次,使用Friedmans检验这几种算法的性能是否具有显著不同。Friedmans检验的原假设是这些算法的性能没有显著性差异。通过实验分析可得,Friedmans 统计值为63.64,服从自由度为6的卡方分布。检验的α=0.05,P 值小于8.172×10-12,这表明原假设应该被拒绝,即DNN 算法在AUC指标上的确优于其他比较算法。

表6 各算法在实验数据集上获得的排名
Holms 后续过程的实验结果如表7 所示,原假设被拒绝。这说明DNN 算法与其余算法有显著性差异,并在统计学有效。因此,从统计学的角度来看,本文算法对不平衡数据分类性能良好。
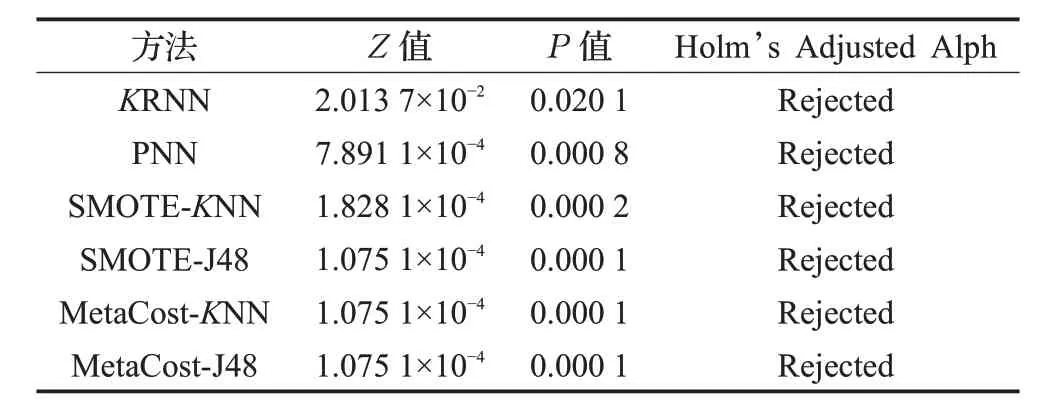
表7 各算法的Holms后续过程的实验结果
综合以上分析结果,DNN 算法的确对处理不平衡数据的分类非常有效,且具有很好的鲁棒性。
6 方法评价与改进

图3 各算法在3个评价指标下的箱线图
针对不平衡数据分类问题,本文提出了基于密度的近邻分类算法(DNN)。该算法既可用于二元不平衡数据分类,也可用于多元不平衡数据分类。算法使用改进的核密度估计方法计算各个类别的密度,以此捕捉数据的局部分布特征,并且采取了映射的方式巧妙地将类密度信息和距离信息进行结合,最终在映射空间选取近邻并分类。这些策略使本文算法具有很好的分类性能和良好的鲁棒性。
尽管本文算法对不平衡数据的分类性能良好,但是仍然存在一些不足:在DNN 算法处理多元不平衡数据分类问题时,需将原始数据映射到一个新的空间中,若此时原始数据集的类别较多,则会产生一个高维度的映射空间,对分类造成困难,同时也会对算法的性能产生影响。针对这个问题,考虑将原始空间中的一些相关性较高的类合并,使用这些合并类进行分类,然后对这些合并类进行单独分类,最终得到分类结果,这将是下一步需要深入研究的内容。
7 结束语
现实生活中,存在大量的不平衡数据分类场景,传统分类器在数据类别分布不平衡的环境下分类性能会降低,而导致这个问题的根本原因在于不平衡数据的复杂分布。针对这个原因,已提出一些改进算法,但是由于不能准确捕捉不平衡数据的复杂分布以及未能提出相应的调整策略,导致它们的分类性能依然有待提高。本文在已有研究的基础上,对传统最近邻分类进行了改进,提出了基于密度的近邻分类算法。实验表明,本文改进的近邻算法在处理不平衡数据分类问题时的性能较其他算法有明显提升。
