基于机器学习的端口扫描入侵检测*
2020-03-26郭楚栩
郭楚栩,施 勇,薛 质
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
在第三次工业革命——计算机及信息技术革命发展了50年的今天,第四次工业革命带着人工智能、清洁能源、机器人技术、量子信息技术、可控核聚变、虚拟现实以及生物技术等新兴技术,已经渐渐渗透到了人们的生活。无论是第三次还是第四次工业革命,都是依托于互联网进行信息交互与交流,可见不管现在还是未来,对互联网的研究都不会停止。在程序员积极为这个信息世界构建一砖一瓦的同时,有一部分人利用网络漏洞对他人的计算机信息系统、基础设施、计算机网络或个人计算机设备进行攻击。在计算机和计算机网络中,破坏、揭露、修改、使软件或服务失去功能、在没有得到授权的情况下偷取或访问任何一计算机的数据,都被视为对计算机和计算机网络的攻击[1]。常见的网络攻击可以分为4种类型:拒绝服务攻击、利用型攻击、信息收集型攻击和假消息攻击[2]。其中,信息收集型攻击并不对目标本身造成危害,但往往被用来进一步入侵提供有用的信息。所以,信息收集型攻击一般是网络攻击的初始步骤。信息收集型攻击中最常见的是端口扫描。通常使用一些软件向大范围的主机连接一系列的TCP端口,扫描软件报告它成功与主机所开放的端口进行连接。有网络攻击的存在时,会有其采取对应的防御措施。端口扫描的防御措施十分简单,即检测到哪个端口被端口扫描所攻击,就关闭该端口来阻断后续攻击的继续实行。但是,如何检测是否被端口扫描,如何在一系列流量中区分攻击流量和一般流量,成为一个值得研究的问题,即需要建立一个端口扫描的入侵检测系统。
入侵检测(Intrusion Detection),顾名思义是对入侵行为的发觉。它通过对计算机网络或计算机系统中若干关键点收集信息并对其进行分析,从中发现网络或系统中是否有违反安全策略的行为和被攻击的迹象。入侵检测在网络防御过程中发挥着至关重要的作用,旨在帮助安全管理员预先了解入侵、攻击和恶意软件等恶意行为。拥有入侵检测系统是保护关键网络免受不断增加的侵入性活动问题的强制性防线。
第四次工业革命的悄然发展,带来了一项新兴技术——人工智能。在人工智能技术发展的同时,使AI不断学习的方法称作机器学习。它最基本的做法是使用算法解析数据、从中学习,然后对真实数据集中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。如何在一系列流量中区分攻击流量和一般流量,可以使用机器学习的方法。简单来说,就是从训练集中提取端口扫描攻击的流量特征,再让计算机对真实数据集中的各种流量进行匹配,判断其是否符合特定特征,进而判断该流量是否为端口扫描攻击。
1 端口扫描基本知识
1.1 端口扫描的分类
按照不同的分类标准,端口扫描可以有不同的分类方法[1]。
1.1.1 水平扫描
水平扫描是指对某一端口有一定目的性的扫描,对不同计算机的同一端口进行多次扫描,如图1所示。

图1 水平扫描
1.1.2 垂直扫描
垂直扫描是指对某一计算机有一定目的性的扫描,对同一计算机的不同端口进行多次扫描,如图2所示。

图2 垂直扫描
1.2 端口扫描检测方法
端口扫描大体上可以分为水平扫描与垂直扫描两种,而这两种扫描方式都有明显的特征,所以能依照这些特征检测这两类端口扫描。
对于水平扫描,由于是对不同主机的同一端口进行扫描,所以在扫描过程中目的主机IP数与目的端口数的比值远大于1,即:

对于水平扫描,由于是对同一主机的不同端口进行扫描,所以在扫描过程中目的主机IP数与目的端口数的比值远小于1,即:

以这两种扫描检测的思路为基础,延伸出了多种检测方法,如基于阈值的扫描检测、算法类型扫描检测、基于规则的扫描检测以及可视化手段的扫描检测等[2]。
2 基于机器学习的端口扫描检测
常规检测方法均依赖于人工对算法的调参或者是对图像的观察,费时费力,而兴起的机器学习算法能解决该问题。2018年,Daniel Fraunholz等人提出了如图3所示的模型[3]。

图3 Daniel Fraunholz等人提出的入侵检测模型
该入侵检测模型主要分为嗅探器和分类器两个大模块。其中,分类器就是使用机器学习算法对嗅探器处理好的流量进行入侵检测,该检测包括端口扫描以及其他异常流量如DDos攻击等。该模型将正常流量和异常流量整合为序列进行训练与测试,而本文仅在流量中检测端口扫描的异常流量,所以只需要简单地对流量包本身进行训练与测试即可。建立端口扫描检测系统流程,如图4所示。

图4 端口扫描检测系统流程
2.1 pcap数据包生成
目前,对入侵检测系统的研究已经比较全面且广泛,相关算法也较为齐全,但是绝大部分研究仅仅是对从pcap文件提取的特征进行分析分类,如对KDD Cup 99数据集进行分类[4],而基于原始pcap文件进行检测的研究甚少。为了实现对流量进行分析的功能,需要收集PortScan流量和正常流量,并基于此进行分析。
但是,尽管现有的入侵流量的特征数据集数量很多,但是这些数据集中的数据仅仅是已提取好的特征,却无法获得其原始pcap文件。通过调研找到CICIDS2017数据集[5],此数据集为加拿大信息安全研究所于2017年收集所得,其中记录了5天内各种入侵行为的流量包,并以pcap文件形式呈现。它的端口扫描以NMAP进行实施,包括多种端口扫描形式,涵盖项目要求的端口扫描类型。
在CICIDS2017中,端口扫描流量集中于周五,且在特定的两个IP间进行端口扫描(攻击源IP为172.16.0.1,攻击目标IP为192.168.10.50)。提取CICIDS2017文件中的端口扫描时间段的流量,此流量中包括了正常流量和端口扫描流量。但是,鉴于端口扫描仅存在于两个固定IP间的通信中,且此两IP在此期间的全部通信均为端口扫描,因此提取端口扫描流量较为容易。
2.2 tshark指令过滤数据
考虑到pcap文件为二进制文件,机器学习算法对此文件很难进行直接处理。借鉴大多数入侵检测及其相关研究,大多入侵检测系统处理对象为不同特征组成的流量序列,而非pcap文件。因此,对于端口扫描流量和正常流量的最初处理为从pcap文件中提取相应特征。
利用wireshark及其命令行操作,可提取pcap流量文件中各条流量包的基本特征,包括IP、端口和协议等。因此,利用wireshark对流量的基本特征进行提取,命令行命令如下:
tshark -r PortScan.pcap -T fields -e ip.src -e ip.dst -e tcp.srcport -e tcp.dstport -e udp.srcport-e udp.dstport -e ip.proto -e frame.time -e frame.time_epoch -e _ws.col.Length -e frame.time_delta >PortScan.csv
命令行中提取特征的中英对照表如表1所示。

表1 命令行中特征提取中英对照表
2.3 对数据处理
2.3.1 特征初步处理
考虑到pcap文件的流量协议不同,提取出的特征集存在特征缺失的情况,十分不利于后续的分析。因此,对于从pcap转换而来的特征序列,需要对数据进行清洗。
清洗主要包括两个方面:
(1)根据流量的协议,确定相应的IP端口;
(2)提出特征存在缺失的流量,特别是IP缺失的流量。
2.3.2 流量的整合
由于某两IP及其相应端口间的通信往往是连续的且多次的,因此将单个流量包作为一次通信行为是不可取的。本系统将间隔不超过某一时间段的两个相同IP和端口组合的主机之间的流量视为同一通信行为。此时间段(time_epoch)可根据实际情况进行限制(代码中time_epoch=1.2)。
2.3.3 ICMP协议分析
由于TCP、UDP均工作在传输层,而ICMP工作在网络层,因此将是否有ICMP协议工作视为一种特征加以考虑。
2.3.4 基于主机和时间的统计特征
主要根据一般端口扫描行为的特点,即同一源IP持续对同一目的IP的不同端口进行访问。据此,检查某一经过整合的目标流量包,对此目标流量包之前的1 000个(单位个数)流量包进行检查分析,检测是否具有相同的源IP和目的IP,并检查端口和协议情况,从而得到统计特征。同时,由于IDS仅防卫某一主机的安全,因此仅对目标包的目的IP为此主机IP的目标包进行检测,具体特征如下。
line_same_src:单位数量的流量包中,目的IP为此主机IP的流量数量;
line_same_src_not_protocol:与目标包有相同的目的IP、不同的目的端口、相同的源IP、不同的协议的包的数量(且目的端口不可重复);
line_same_src_not_protocol_repeat:与目标包有相同的目的IP、不同的目的端口、相同的源IP、不同的协议的包的数量(且目的端口可重复);
line_same_src_same_protocol:与目标包有相同的目的IP、不同的目的端口、相同的源IP、相同的协议的包的数量(目的端口不可重复);
line_same_src_same_protocol_repeat:与目标包有相同的目的IP、不同的目的端口、相同的来源IP、相同的协议的包的数量(目的端口可重复)。
为了进一步检查目标流量与之前流量间的统计关系,并且考虑慢扫描情况,再对目标流量前2 s内(单位时间)的流量包进行检测。其他具体内容和规则与单位个数内的检测一致,具体特征如下。
second_same_src:单位时间的流量包中,目的IP为此主机IP的流量数量;
second_same_src_not_protocol:与目标包有相同的目的IP、不同的目的端口、相同的源IP、不同的协议的包的数量(且目的端口不可重复);
second_same_src_not_protocol_repeat:与目标包有相同的目的IP、不同的目的端口、相同的源IP、不同的协议的包的数量(且目的端口可重复);
second_same_src_same_protocol:与目标包有相同的目的IP、不同的目的端口、相同的源IP、相同的协议的包的数量(目的端口不可重复);
second_same_src_same_protocol_repeat:与目标包有相同的目的IP、不同的目的端口、相同的来源IP、相同的协议的包的数量(目的端口可重复)。
综上,目前提取的特征共15个,如表2所示。

表2 整合后的特征中英对照
2.4 训练模型
基于以上所得特征,利用机器学习算法对以上特征形成的特征向量进行分类。本代码生成的特征数量有限,特征总数为15。考虑到深度学习主要适用于图像语音等单个大型文件的分类。对于特征较少的单一文件,使用传统机器学习方法即可。因此,整理统计数据并送入分类模型中进行检测,其中模型包括朴素贝叶斯、决策树、随机森林和逻辑回归。
将70%的数据作为训练数据,30%的数据作为测试数据。分类测试效果如表3所示,其中Decision Tree较好,所以之后的测试均使用该机器学习算法。

表3 各种机器学习模型的测试效果表
需要注意,本次模型训练使用的是一小部分CICIDS2017数据,之后进行测试时使用的是完整CICIDS2017数据所建立的模型。
2.5 测试数据
使用两台均为Ubuntu18.04 64位虚拟机,其中一台作为攻击主机使用Nmap工具对另一台被攻击主机进行端口扫描(采用各种不同的攻击方式),被攻击主机使用wireshark工具采集流量,同时打开网页观看视频与文章,以此产生正常流量来作端口扫描流量的背景流量。对于采集好的流量,放入之前训练好的机器学习模型中进行测试,测试结果如表4所示。
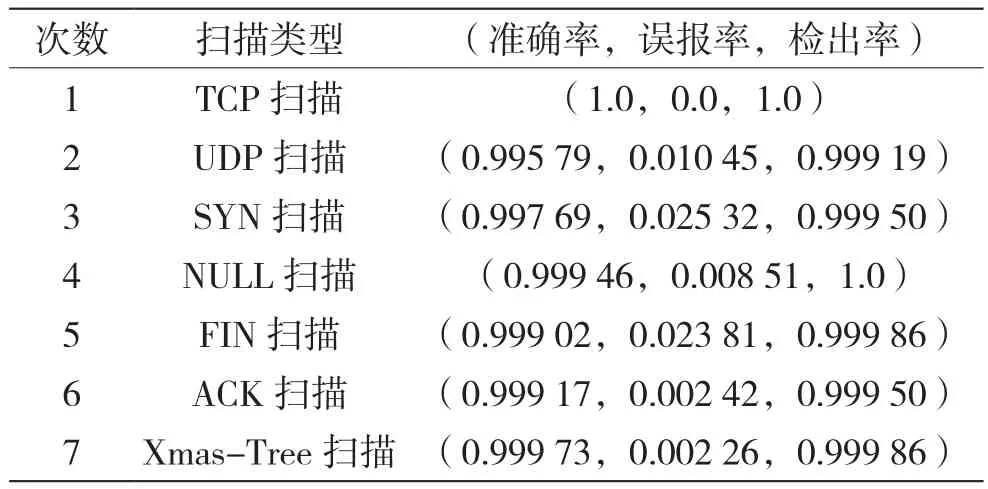
表4 对于各种扫描类型的测试效果
可见,不管是何种扫描类型,该模型检测能力均表现优良。
3 结 语
近年来,互联网领域中机器学习日益火热,而端口扫描检测为基本的信息安全防御手段,将两者相结合是未来发展的必然趋势。本文基于2018年Daniel Fraunholz等人提出了的入侵检测模型,提出了一种基于机器学习的端口扫描检测系统。系统的特征提取参考了KDD Cup 99数据集中数据的特征提取,其中的模型训练集基于CICIDS2017数据集,最后模型测试结果优良,能够广泛运用到多种不同类型的扫描检测中。然而,对慢扫描[8]与分布式扫描等在短时间内无大流量的扫描方式还缺乏检测手段,将会是一下阶段尝试攻克的课题。
