LTE 系统上行链路调度算法研究*
2020-03-22王晓明王志强缑鹏超
王晓明,王 晨,王志强,缑鹏超
(国网陕西省电力公司信息通信公司,陕西 西安 710004)
0 引言
近几年,移动通信取得了飞速进展。移动用户对高数据速率的需求,进一步推动了移动网络的出现。第三代合作计划(3rd Generation Partnership Project,3GPP)的长期演进(Long Term Evolution,LTE)技术是新移动技术之一。早在2004 年底,3GPP 就启动了LTE 技术的标准化工作,并在2009年3 月发布了R8 版本的FDD-LTE 和TDD-LTE 标准,标志着LTE 标准草案研究完成,LTE 进入实质研发阶段。R9 版本中进一步提出了LTE-Advanced(Long Term Evolution-Advanced,LTE-A)的概念。LTE-A 于2010 年6 月通过ITU 的评估,于2010 年10 月正式成为IMT-A 的主要技术之一,是在R8 版本基础上的演进和增强。R10 版本对其加以完善,是LTE-A 的关键版本。LTE-A 的目的是满足无线通信市场的需求,满足和超过IMT-Advanced 的需求,同时保持对LTE 较好的后向兼容性。LTE-A主要采用载波聚合、多点协作传输、中继等关键技术。这些技术增强了LTE-A 小区的系统容量与信息的传输速率,同时极大地改善了小区边缘用户的性能。LTE 可以提供每秒兆比特级的数据速率[1],具有高频谱效率、高峰值速率、高移动性和网络架构扁平化等多种优势。LTE 可以提供语音、视频和数据的无缝融合,与LTE-Advanced 已成为最有前景的无线接入技术。
LTE 本质上与之前的移动无线接入技术不同。LTE 系统在其下行链路中使用正交频分多址(Orthogonal Frequency Division Multiple Access,OFDMA)技术,在其上行链路中使用单载波频分多址(Single Carrier Frequency Division Multiple Access,SC-FDMA)技 术。OFDMA 技 术 和SC-FDMA 技术通过提供更好的干扰控制来提高数据速率[1]。OFDMA 技术和SC-FDMA 技术都是将信道分成多个子载波,然而将子载波调度给不同的用户,以使系统利用率最大,并不是一件简单的事情。目前,下行链路调度已经被大多数研究人员关注,而上行链路调度仍是研究相对较少的领域[2-6]。
在LTE 系统中,基站(Evolved Node B,eNodeB)执行分组调度任务。分组调度指的是为传输分组分配某组子载波。子载波分配在12 个15 kHz 的子载波组中进行,在时域上持续时间为1 ms。1 ms 的持续时间为传输时间间隔(Transit Time Interval,TTI),用于执行分配任务的单元称为物理资源块(Physical Resource Block,PRB),预计每个用户在不同的PRB 中经历频率选择性衰落。此外,由于不同的空间位置,不同的用户在某个PRB 上经历互不相同的信道条件,而信道条件会影响调制和编码方案(Modulation and Coding Scheme,MCS)。因此,eNodeB 必须将多个PRB 分配给多个用户,以最大化每个TTI 中比特传输的可能性。在TEL 系统中,调度在下行链路和上行链路完成。其中,下行链路允许进行PRB 的分布式分配[7]。而在上行链路中,由于SC-FDMA 技术的限制,PRB 的连续分配更为恰当,而PRB 的连续分配会使分配问题成为NP-Hard 问题[8]。
此外,当调度具有服务质量(Quality of Service,QoS)约束的实时业务分组时,调度方案需要考虑延迟期限和分组丢弃约束。为了满足延迟期限要求,文献[9-10]提出了包含两个阶段的调度方案:第一个阶段为时域分组调度(Time-Domain Packet Scheduling,TDPS),第二个阶段为频域调度(Frequency Domain Scheduling,FDPS)。TDPS基于头(head of the line,HoL)分组延迟将用户列入名单,再将PRB 分配给名单中的用户[9],用于在比特传输方面最大化系统吞吐量,但是考虑最终分配的用户子集会导致次优解决方案。为了计算最优解,研究应该遍历所有可能的选项,同时保持一定的计算复杂度。
文献[8-9,11-14]提出的用于下行链路和上行链路的调度算法仅进行了信道感知调度,认为分组始终在用户设备(User Equipment,UE)缓冲区中传输。这些算法会将PRB 分配给具有信道增益高的UE,即使该UE 在其缓冲区中没有足够的数据来使用分配的PRB。由于没有考虑缓冲区状态,MAC层吞吐量(即实际发送的比特数)较低[15]。
本文研究了LTE 系统上行链路调度优化算法,eNodeB 通过考虑实时业务的延迟约束条件来保证分组能在延迟期限内传输。调度时eNodeB 考虑UE面临丢弃风险的分组数,能最小化由调度引起的丢弃分组数,确保具有紧急要求的UE 总能被优先调度,提高公平性。
1 上行链路调度
基于延迟感知实时业务,对文献[15]中的改进动态匈牙利算法(Dynamic Hungarian Algorithm with modification,DHAM)进行优化。表1 示出了本文所使用的多个符号及其含义。

表1 符号及其含义
对于尽力服务型(best-effort traffic)业务,DHAM可以以最优方式工作。然而,当具有延迟约束的业务即实时业务时,DHAM 可能会降低QoS。典型的实时业务包括语音和视频。由于DHAM 是CA 与缓冲器共同感知的,因此可能以更好的信道质量调度UE,即使信道质量差的用户缓冲区被建立,它们也可能无法获得传输机会。此外,对于实时业务,如果分组没有在其期限内传输,则该分组被丢弃,最终导致QoS 进一步恶化。基于此,本文对DHMA进行优化,以确保其适用于实时业务。
使用和DHMA 相同的流量矩阵W进行计算。W由wi,j组成,wi,j为第i个UE 通过第j个资源块(Resource Chunk,RC)发送数据时产生的流量。首先建立目标整数线性规划模型,该目标整数线性规划模型包括目标函数、实时业务的延迟约束条件、第一约束条件和第二约束条件。
目标函数为:

式中,αi,j为二进制变量。当第i个UE 被分配第j个RC 时,αi,j为1;当第i个UE 没有被分配第j个RC 时,αi,j为0。
实时业务的延迟约束条件为:

式中,δi为第i个UE 的HoL 分组的延迟。当第i个UE 在当前TTI 被调度时,;当第i个UE 在当前TTI 未被调度时,。此外,Dth为实时业务的延迟期限,其中t为当前TTI 的长度。
实时业务的延迟约束条件用于表示当第i个UE 的HoL 分组超过延迟期限时,eNodeB 强制对第i个UE 进行调度。

第一约束条件为:第一约束条件用于表示如果将某个RC 分配给所有UE,则只能将该RC 分配给至多一个UE。第二约束条件为:

第二约束条件用于表示如果给某个UE 分配RC,则只能给该UE 分配至多一个RC。
实时业务的延迟约束条件、第一约束条件和第二约束条件为不等式,以便适用于不同数量的RC和UE。
消除可能的不可行性为ND>M;当ND<M,即延迟违规用户数量小于RC 数量时,可以采用式(1)~式(4);当ND>M时,只能列出延迟违规用户集合Ω中的用户,然后对其执行DHAM,不涉及延迟约束。但是,若在当前TTI 中未调度w∈Ω,仅在Ω执行DHAM,将得不到丢弃的分组数。如表2 所示,UE2 具有相对较好的信道条件,但较少的分组面临丢弃风险;而UE1 具有相对较差的信道条件,但在其缓冲区中将丢弃大量的分组。因此,为了实现公平性,应该优先调度UE1。然而,采用DHAM 时得到的结果相反。

表2 调度实例一
此外,还需要最小化由此调度引起的分组丢弃数量。表3 的例子中,可以得到调度UE 导致丢弃的字节数大于调度UE2 导致丢弃的字节数。显然,调度UE2 时公平性较差,但系统会更完善。因为调度UE2 能减少未来分组丢弃,从而间接控制长期系统吞吐量。

表3 调度实例二
为了确保公平性并最小化分组丢弃,本文建立如下目标函数:
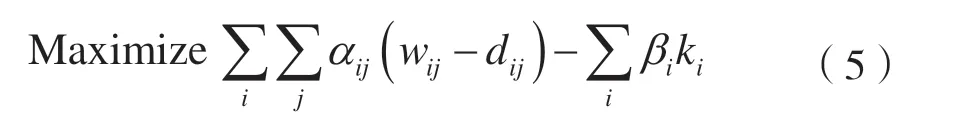
式中,ki为如果第i个UE 未在当前TTI 中调度,将被丢弃的字节数;dij为如果第i个UE 分配到第j个RC 时,第i个UE 将丢弃的字节数。
关于式(5)的约束条件为:
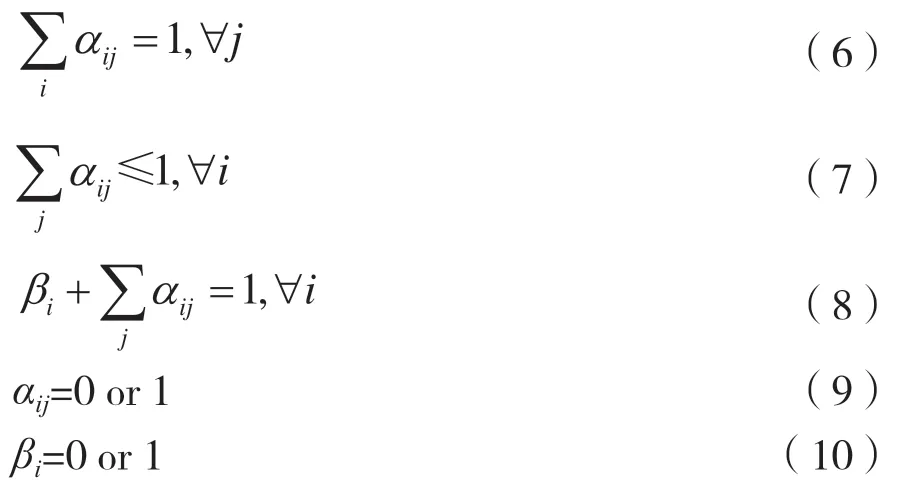
2 仿真和结果
为了验证本文算法的有效性,在OMNeT++网络模拟器中开发的系统级模拟器上进行仿真。仿真所用的实施环境如图1 所示,一个小区被6 个一级小区所包围,中心小区为服务小区,一级小区提供干扰信号功率。本文以中心小区为研究对象,所有仿真结果均被记录在中心小区。

图1 仿真模型
本文将UE 按照泊松分布方式部署在小区中,UE 是静止的(虽然仿真中UE 静止,但对于移动用户,该算法也是有效的),并假设所有UE 都与其服务eNodeB 直连,且上行链路传输功率控制和MCS 参考文献[16]。参考文献[17-18]使用块衰落信道模型(若基站和用户设备之间几乎没有相对移动,则认为一定时间内信道基本保持不变,在这段时间内的连续符号遭受的衰落是相同的,即为块衰落模型),信道条件在一个TTI 上保持不变。此外,本文还假设eNodeB 在获取调度决策时知道所有UE的CQI、缓冲长度和关键分组。
本文将提出的上行链路调度算法和DHAM 的性能进行对比,对比参数包括公平性、MAC 层吞吐量、最差信道条件的用户传送的分组量以及延迟等参数。公平性结果对比如图2 所示。使用本文提出的调度算法时,公平性得到改善,因为不管在什么时候,当用户在相当长时间内遭受不良信道条件时,本文调度算法能为其提供占用信道的机会,而DHAM 仅提高MAC 层吞吐量,所以常常会选择具有更高信道质量的用户。但是,采用本文调度算法减少了因延迟而产生的分组丢弃,所以在改善公平性的同时并没有牺牲MAC 层吞吐量,如图3 所示。
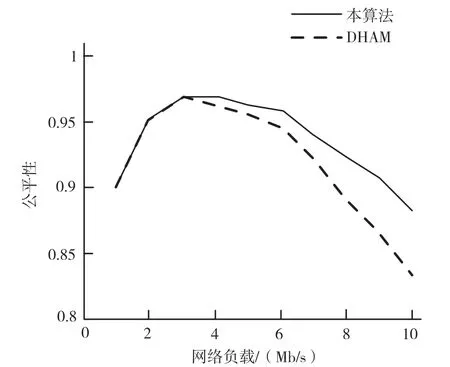
图2 公平性对比
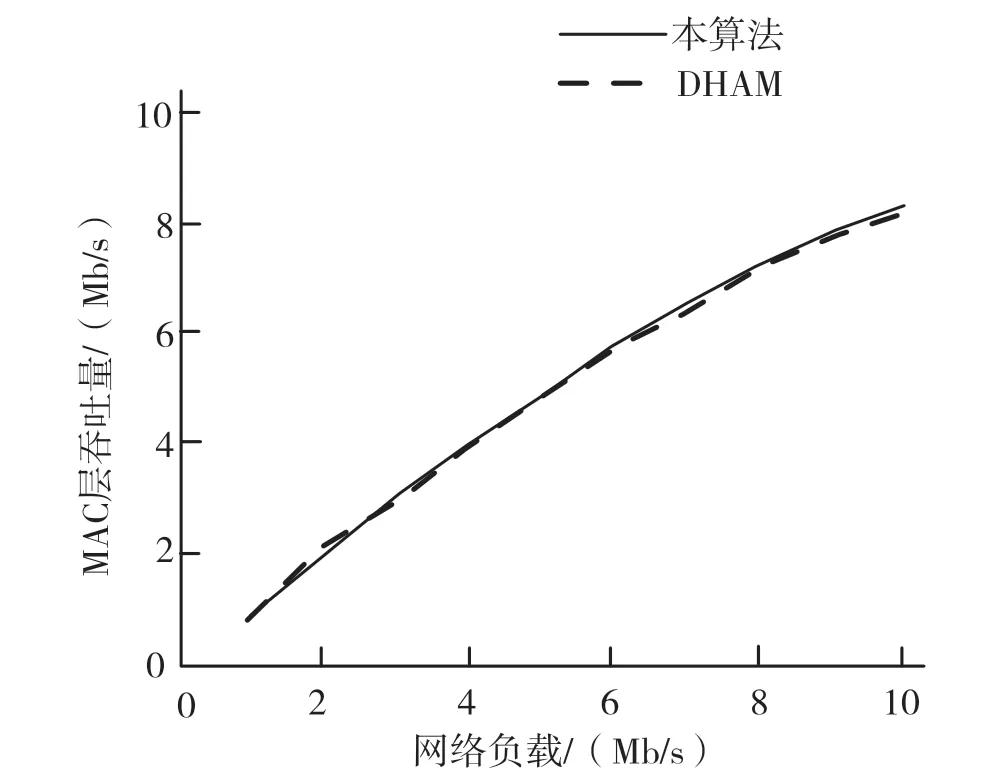
图3 MAC 层吞吐量对比
采用本文提出的调度算法,能优先处理分组,即将违反延迟约束的用户。如果所有用户的输入速率相似,那么信道质量差的用户通常会受到最严重的打击。采用本文调度算法能增强最差信道条件的用户分组传送效果。图4 示出了在本文调度算法的延迟感知调度下,具有最差信道条件的用户的分组传送的增强效果。
如图5 所示,为了优先选择具有更多延迟分组的用户,采用本文提出的调度算法会推迟具有更高信道质量的用户分组的传输,因此增加了平均延迟,但其能保证实际延迟在业务分组延迟限制内。
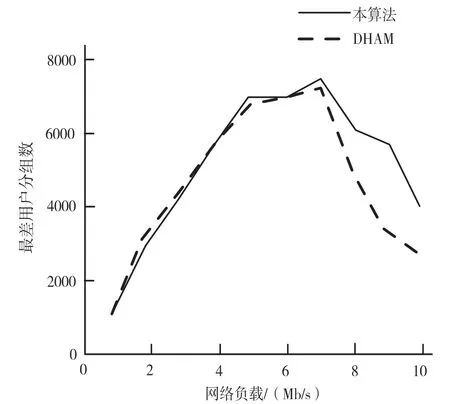
图4 最差用户分组传送效果
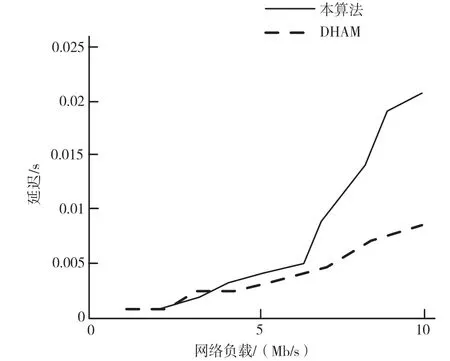
图5 语音业务平均延迟影响
3 结语
针对实时业务,本文提出了一种新的上行链路调度算法,考虑了实时业务的延迟约束,能够保证实时业务分组在延迟期限内传输,适用于实时业务。在调度时,eNodeB 能考虑UE 面临丢弃风险的分组数,能最小化由调度引起的丢弃分组数,确保具有紧急要求的UE 总能被优先调度,改善公平性。仿真结果表明,在LTE eNodeB 上采用该调度算法,能显著改善LTE 上行链路性能。
