具有环境自学习机制的鲁棒说话人识别算法*
2020-03-22俞一彪
张 靖,俞一彪
(苏州大学 电子信息学院,江苏 苏州 215000)
0 引言
现阶段,说话人识别任务在实验室环境下已经取得很好的效果,但实际应用场景中常常会存在环境噪声,尤其当这种噪声还在发生变化时,说话人识别系统的性能会急剧下降。因此,如何减少环境失配造成的影响成为一个亟需解决的问题。而对于环境噪声的处理,在说话人识别领域一般有3 种解决方案。第一种是在预处理阶段,在信号域中有很多经典的语音增强的方法用来去除语音信号中的加性噪声。第二种是在特征提取阶段,或提取更加鲁棒的特征来减小环境噪声的影响,或根据噪声特性在特征参数上对噪声进行补偿,恢复出纯净的说话人语音特征。第三种是在后端实现的噪声补偿,如对说话人模型的补偿或者对得分域的处理。
在预处理阶段,早期的处理方法主要包括谱减法(Spectral Subtraction,SS)[1]、小波变换、维纳滤波等。但是,这些信号域中的处理一般是先计算出语音和噪声的功率谱,然后对噪声进行补偿,处理后的结果再变换成语音特征。由于不是直接对语音特征或者模型进行补偿,这样的变换补偿效果有限。而提取更加鲁棒的特征如GFCC 特征[2]等,当面临多变的环境噪声时,同样无法满足实际应用的需要。因此,必须要在特征或者模型上直接能够得到噪声和纯净语音之间的关系,从而消除环境噪声引起的失配。
在特征提取阶段,基于滤波的特征补偿算法主要有倒谱均值减(Cepstral Mean Subtraction,CMS)[3]、相对谱(Relative Spectral,RASTA)[4]、特征弯折(Feature Warping,FW)[5]等。而矢量泰勒级数(Vector Taylor Series,VTS)[6-9]是基于模型的特征补偿算法中最成功的鲁棒说话人识别方法之一。矢量泰勒级数最早被应用于鲁棒语音识别,后来被应用于鲁棒说话人识别也取得了很大成功。VTS 方法在倒谱域中利用VTS 展开式逼近失配语音的非线性模型,可从含噪语音中估计噪声模型。在文献[10]中将矢量泰勒级数特征补偿算法应用于说话人识别,给出了卷积噪声方差的近似闭式解。文献[11]中将VTS 方法与i-vector 框架相结合,显著提升了识别效果。
而在模型域,并行模型联合(Parallel Model Combination,PMC)[12-13]是比较早期的模型补偿方法。PMC 方法提取含噪测试语音的静音段建立噪声模型,然后将干净的说话人模型映射成含噪模型,最后将含噪语音和含噪模型进行匹配。但是,由于PMC 模型映射过程中需要多次近似变换,会带来额外的误差。VTS 方法同样可以应用到模型域,从含噪测试语句中估计出噪声模型后,可以根据噪声和语音的非线性映射关系得到含噪说话人模型。由于VTS 算法需要近似的次数比PMC 少,因而可以认为VTS 方法得到的补偿模型精度更高。
本文提出了一种具有环境自学习能力的鲁棒说话人识别算法,并在算法中引入环境自学习和自适应的思想。首先从当前的环境中学习得到环境噪声的模型参数,然后根据噪声和纯净语音的关系建立噪声补偿模型。当环境变化时,根据当前环境将噪声补偿模型更新为新的补偿模型,并从特征域或模型域对环境噪声进行自适应补偿,从而克服环境失配带来的影响。在自学习阶段,认为在每一次测试时环境噪声有可能发生变化,但在一次测试过程中环境噪声是平稳的。测试开始前的先验噪声和测试过程中的环境噪声特性保持一致,因此可以采集测试开始前的一段先验噪声来估计当前测试环境下的噪声模型。在自适应阶段,提出了改进的矢量泰勒级数(Vector Taylor Series,VTS)方法来刻画环境噪声和纯净说话人语音特征和模型间的统计关系,利用学习到的环境噪声模型,分别在特征域和模型域对环境噪声进行补偿。在特征域中将含噪测试语音特征自适应为纯净语音特征,而在模型域中将纯净说话人模型自适应到应用环境得到含噪说话人模型。
1 矢量泰勒级数特征补偿
基于矢量泰勒级数(Vector Taylor Series,VTS)的补偿算法是基于失配语音的非线性模型提出的,具有比线性模型更好的建模精度,且可以直接从含噪语音中估计加性噪声的参数,对先验信息要求较少。
在倒谱域,加性噪声对纯净语音的影响可以用倒谱域中失配语音特征参数的非线性模型来描述[14]:

其中,y、x、n分别为失配语音、纯净语音和加性噪声的倒谱特征向量,C和C-1分别为离散余弦变换(Discrete Cosine Transform,DCT)矩阵及其逆矩阵。
假设x、n独立,则可将式(1)在(μx,m,μn0)处做一阶VTS 展开,得到y和x的近似关系式:
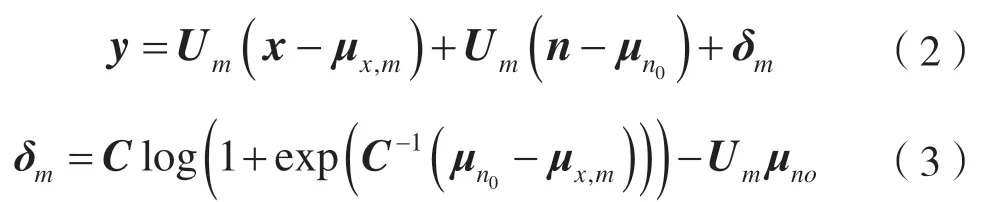

其中μx,m为纯净语音模型λx{GMM}的第m个高斯分量的均值,μn0为加性噪声的均值初值,Um为失配语音y关于加性噪声n的偏导数,δm为失配语音在(μx,m,μn0)处的初值,μy,m和σy,m分别为含噪语音第m个高斯分量上的均值和方差,μn和σn分别为加性噪声的均值和方差。这样可以将式(1)的噪声和含噪语音的非线性关系近似为式(2)的线性关系,从而实现特征层次上噪声与纯净语音的分离。
噪声参数μn和σn可以通过EM 算法和最大似然准则从含噪测试语音中估计。

其中ot=yt-μy,m,符号·表示两个同维度矩阵的对应元素分别相乘。
2 基于改进矢量泰勒级数补偿的环境自学习与自适应方法
2.1 改进的矢量泰勒级数
为了能够实现自适应特征补偿和模型补偿,在环境噪声的自学习阶段需要学习到自适应需要的噪声模型参数,因而需要对进传统的VTS 方法。将经典VTS 方法中噪声的单高斯模型用高斯混合模型代替,并加入先验噪声估计的步骤,同时利用当前的环境噪声模型参数更新噪声补偿模型,并在特征域和模型域对噪声进行补偿。
2.2 噪声模型自学习
由于VTS 方法使用EM 算法[15]估计出的噪声模型可能不够精确,假设一次测试过程中环境噪声是平稳的,可以采集测试开始前的一段先验噪声来估计当前测试环境下的噪声模型。其中,噪声模型用和说话人模型相同混合度的高斯混合模型(Gaussian Mixture Model,GMM)来表示。
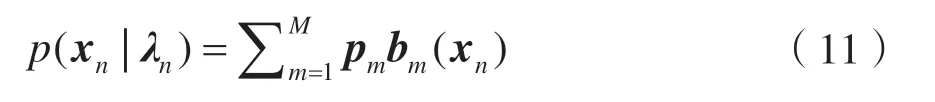
式中xn为先验噪声的D维倒谱特征矢量;M是模型的阶数,即需求加权和的高斯分布的数目;pm为加权系数且满足条件为具有均值矢量μnm和协方差阵∑nm的高斯分布的概率密度函数。
应用EM 算法,可得到先验噪声的模型参数集λn={pnm,μnm,∑nm}m=1,2,…,M。
2.3 特征域自适应补偿
在得到先验噪声模型λn后,可以通过式(6)和式(7)结合UBM 模型自适应得到噪声补偿模型参数μy,m和σy,m。纯净语音特征向量根据式(12)MMSE 准则估计得到,能够在环境变化时根据新的噪声模型对含噪测试语音特征进行自适应补偿。
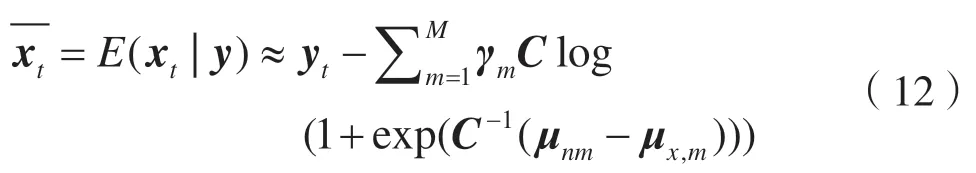
特征域补偿算法框图如图1 所示。

图1 环境自适应VTS 特征域补偿算法系统
特征域补偿具体的算法流程如下:
(1)对所有说话人语音进行划分,用大部分说话人语音提取特征训练UBM 通用背景模型λUBM{GMM},其余说话人语音进一步分成训练语音和测试语音,去除静音段提取训练语音特征MAP 自适应得到每个说话人模型λx{GMM}。
(2)对含噪测试语音和先验噪声段分别去除静音段提取特征参数,根据噪声特征建立噪声模型λn{GMM}。
(3)根据式(3)、式(4)、式(5),计算δm、Um以及Vm。
(4)对于每个说话人,根据式(6)和式(7)计算补偿模型λy{GMM}的均值μy,m和协方差σy,m。
(5)根据式(12),结合MMSE 准则,利用含噪测试语音和补偿模型λy{GMM},估计出纯净测试语音特征。
(6)最终将得到的纯净测试语音特征和说话人模型λx{GMM}进行匹配,得到结果。
2.4 模型域自适应补偿
在特征补偿算法中,可以对静态分量的估值做差分,从而求出MFCC 的动态分量。但是,在模型自适应算法中,动态分量不能用直接差分的方式得到,所以模型自适应算法也需要对动态分量进行更新。模型参数的静态分量同样通过式(6)和式(7)计算。动态分量使用式(13)和式(14)得到:
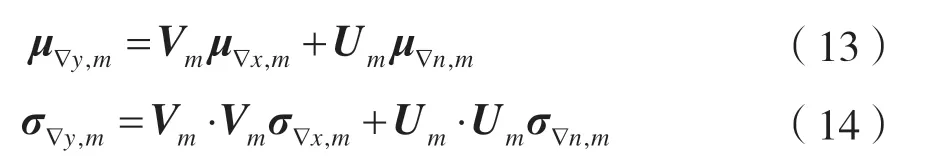
在得到先验噪声模型λn后,利用式(6)、式(7)、式(13)、式(14)对纯净说话人模型进行调整得到每个人对应的含噪说话人模型,然后用含噪测试语音和含噪说话人模型进行匹配得到识别结果,这样就能够在环境变化时根据新的噪声模型对训练时的说话人模型进行自适应补偿。
模型域补偿算法框图如图2 所示。

图2 环境自适应VTS 模型域补偿算法系统
3 实验结果及分析
3.1 实验数据
实验中采用的MFCC 特征矢量为24 维,包括12 维的静态特征和12 维的动态特征。为了说明实验的有效性,实验使用了两个语料库分别进行实验。一个是语音库SD2002[16],共有40 个说话人,每人7 段语音,每段语音长度为12 s,其中20 个人用来训练UBM 模型,20 人用来测试。另一个是400 h的AISHELL-1 中文普通话语料库[17],使用70 个说话人的语音数据来完成实验,其中30 人训练UBM模型,40 人用来测试。本实验采用GMM-UBM 框架,UBM 模型阶数为256。其中,UBM 语音以及训练集语音都是干净的,而测试时对每条测试语音叠加不同种类的噪声进行实验,预处理阶段去除了每条语音的静音段。本实验中,从NOISEX-92 噪声库中选择了3 种不同类型的噪声babble、f-16 和white。考虑5 种不同的信噪比(Noise Signal Ratio,SNR)0 dB、5 dB、10 dB、15 dB 和20 dB,将3 种噪声分别叠加到测试集中进行实验。
3.2 先验环境噪声
对于每条测试语句,选取和测试语句同等长度的NOISEX-92 数据库中的噪声叠加到测试语句上得到含噪测试语句。为了获得先验环境噪声,需要在当前测试结束后和下一次测试开始前的间隙采集噪声数据。因此,在每个测试语音前需要另外拼接一段相同类型的噪声片段。
3.3 特征域补偿
表1 显示了与基线系统和传统VTS 方法相比,改进的VTS 方法(Vector Taylor Series-Feature Improved,VTS-F)在特征域中的性能,其中选取的先验噪声时长为10 s。可以在SD2002 和AISHELL-1 数据库上看到,提出的方法在低SNR条件下比VTS 表现更好,但它在高SNR 条件下表现不佳。这可以被理解为当信噪比很低时,先验噪声得到的GMM 噪声模型比VTS 方法估计出的单高斯噪声模型更能够精确刻画噪声的分布。而当信噪比很高时,由于此时先验噪声很小,由此得出的噪声模型可能会不精确,导致系统识别性能下降。

表1 设定先验环境噪声为10 s 时,在SD2002 和AISHELL-1 下基线系统、传统VTS 方法和VTS-F 方法在混有不同信噪比的3 种噪声下的正确识别率
3.4 模型域补偿
将提出的方法应用到模型域,可以得到改进的模型域VTS 方法(Vector Taylor Series-Model Improved,VTS-M)。从表2 可以发现,VTS-M 相比于特征域方法VTS-F,在低SNR 下识别率有了进一步提高,但在高SNR 下的下降更为明显。这是因为VTS-F方法中只用了噪声模型的均值进行MMSE 估计得到干净的特征,而VTS-M 方法分别使用了噪声模型的均值和方差对纯净说话人模型进行调整。当SNR比较高时,VTS-M 方法由噪声模型不精确带来的影响更大。同样,当SNR 比较低时,VTS-M 方法补偿的效果更好。为了补偿VTS-M 方法在高SNR 下的识别率急剧下降的问题,本文使用了一种自适应方法对VTS-M 方法进行调整,得到了新的改进的模型域VTS 方法(VTS-M-N)。
首先计算测试语音特征与纯净说话人模型中的每个高斯分量的匹配似然度。

其中nm是测试语音特征中属于第m个高斯分量的帧数;r是一个常数,这里取2。
VTS-M-N 模型域补偿算法流程:
(1)对所有说话人语音进行划分,用大部分说话人语音提取特征训练UBM 通用背景模型λUBM{GMM},其余说话人语音进一步分成训练语音和测试语音,去除静音段提取训练语音特征MAP 自适应得到每个说话人模型λx{GMM}。
(2)对含噪测试语音和先验噪声段分别去除静音段提取特征参数,根据噪声特征建立噪声模型λn{GMM}。
(3)根据式(3)、式(4)、式(5)计算δm、Um以及Vm。
(4)对于每个说话人,根据式(6)、式(7)计算含噪模型静态分量的均值μy,m和协方差σy,m。
(5)根据式(13)、式(14)计算含噪模型动态分量的均值μ∇y,m和协方差σ∇y,m。其中含噪模型的权重和纯净模型权重保持一致,将静态分量和动态分量合并得到完整的含噪模型λy{GMM}。
(6)将含噪模型λy{GMM}的均值进行自适应,得到新的含噪模型。
从表2 中可以发现,新提出的VTS-M-N 方法能够有效补偿VTS-M 方法在高SNR 时识别率的急剧下降,并且在低SNR 时某些情况下能够进一步提高识别率,表明这种自适应是有效的。
从表3 可以发现,对于3 种噪声,VTS-M 方法的识别率随着噪声时间的变长而变高,而VTSM-N 方法的识别率随着噪声时间变长没有太大的变化,在噪声时间为10 s 时有很好的表现。
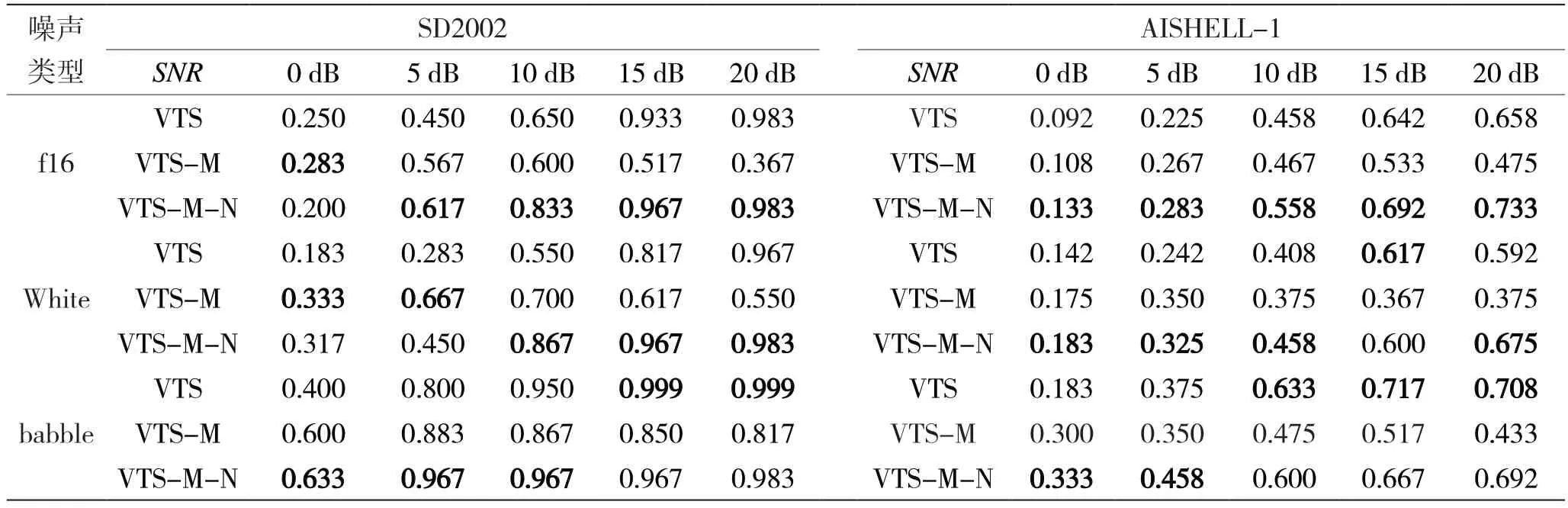
表2 设定先验环境噪声为10 s 时,在SD2002 和AISHELL-1 下传统VTS 方法、VTS-M 和VTS-M-N 方法在混有不同信噪比的3 种噪声下的正确识别率

表3 AISHELL-1 语料库下先验环境噪声时长对VTS-M 方法和VTS-M-N 方法正确识别率的影响(SNR=10 dB)
4 结语
现实中当应用环境与训练环境不一致时,如何根据变化的环境噪声来调整特征与模型参数来减少环境失配带来的影响,是说话人识别系统面向实际应用迫切需要解决的问题。文章提出了自学习和自适应的思想,从先验环境噪声中自学习到当前测试语音中噪声的参数,然后利用学习到的噪声参数自适应调整噪声补偿模型,并分别应用到特征域和模型域中进行相应的补偿。
在GMM-UBM 框架下,当信噪比较低时,提出的特征域和模型域补偿方法均能有效提升识别性能。而在高信噪比下,当运用到模型域时,识别率会急剧下降,为此使用了一种自适应方法对VTS-M 方法进行改进。结果发现,新的VTS-M-N 方法在高信噪比下也能取得较好的效果,同时在低信噪比下也能进一步提高识别率。此外,从表3 中可以看出,只需要在测试开始前获得10 s 的先验环境噪声,就能很好地减小环境噪声的影响,这在实际应用中可以接受。
