基于多模型融合的工业工件剩余寿命预测*
2020-03-20王建成蔡延光
王建成 蔡延光
(广东工业大学自动化学院,广东 广州 510006)
关键字:LightGBM;ridge;GBDT;XGBoost;模型融合;工件剩余寿命预测
0 引言
预测性维护在工业互联网的应用中被称为“皇冠上的明珠”,实现预测性维护的关键是对设备系统或核心部件的寿命进行有效预测。对设备系统或核心耗损性部件的剩余寿命进行预测,并据此对相关部件进行提前维护或更换,可减少整套设备非计划停机时间避免整个生产现场其他正常配套设备因等待故障设备部件修复[1-2],而造成经济损失。
工业上采集的数据集中存在较多干扰数据,而传统线性模型的抗干扰能力弱,预测精度较低,增加了工业设备维护的成本。为此,本文提出一种双模型的加权融合方法进行工业工件剩余寿命预测,通过4种机器学习算法及3种双模型融合的方法,建立工业工件的剩余寿命预测模型,并进行比较分析。在一定程度上,提供了设备提前维护的数据支持,同时挖掘影响机器设备寿命的关键因素。
1 相关算法
1.1 ridge算法
线性回归的损失函数J(w)通常定义为
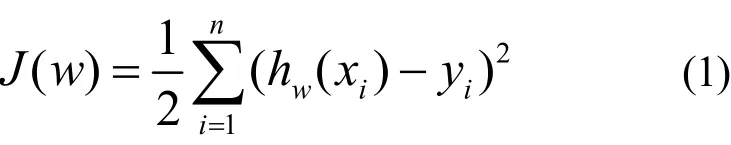
式中,xi是具有m个特征的样本;yi为真实值;为预测值。
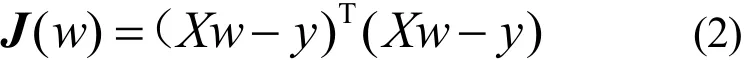
对式(2)w求偏导,并令可得到
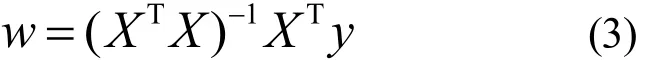
为防止过拟合,学者对线性回归进行优化,产生了ridge回归[3]。ridge回归在线性回归损失函数的基础上增加一个正则项则有
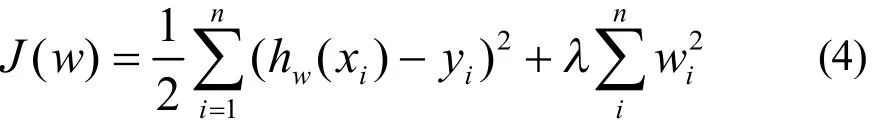
同样对式(4)中w求偏导,并令可得到

出现过拟合时,模型几乎完全匹配训练集,但在测试集上效果较差,说明该模型具有低偏差高方差的特点,可能在较小的区间内波动性较大,即模型的导数值较大。模型阶数和自变量值对导数影响较小,只有自变量系数较大才可能导致过拟合,所以增加正则项对大系数进行惩罚,使系数更为平滑,可缓解模型过拟合。
本文工件预测寿命样本达90维以上,为防止模型出现过拟合,采用ridge模型作为实验仿真对象。
1.2 GBDT 算法
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法[4,10-11],又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱学习器(树),并把多棵决策树的结果累加起来作为最终预测输出。该算法将决策树与集成思想有效结合。设数据集D= {(xi,yi) :i= 1,2,… ,n,xi∈Rq,yi∈R} ,其中n为数据样本数量,每个数据样本有q个特征。设损失函数为L(y,f(x) ),输出回归树x),GBDT算法实施具体步骤如下:
1) 初始化弱分类器,估计使损失函数极小化的一个常数值,此时树仅有一个根结点;
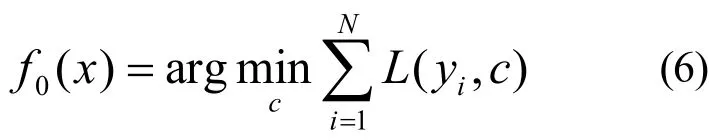
2) 对迭代次数i= 1 ,2,… ,N,计算损失函数的负梯度值在当前模型的值,并将它作为残差估计,即
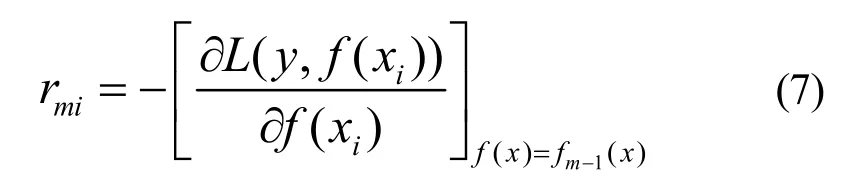
对于平方损失函数,是通常所说的残差;对于一般损失函数,是残差的近似值。
对rmi拟合一个回归树,得到第m棵树的叶节点区域Rmj,j= 1 ,2,… ,J,计算
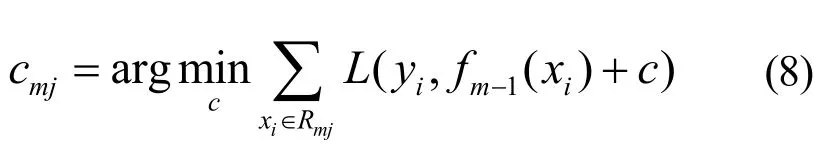
即利用线性搜索估计叶节点区域的值,使损失函数极小化。
3) 更新回归树
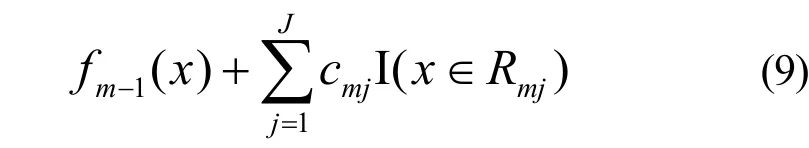
得到输出的最终模型为
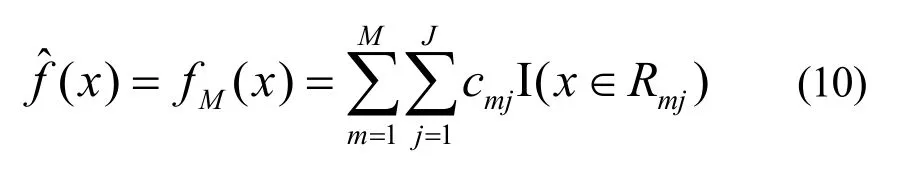
1.3 XGBoost 算法
华盛顿大学陈天奇博士开发的 XGBoost(eXtreme Gradient Boosting)基于C++通过多线程实现了回归树的并行构建,并在原有Gradient Boosting算法的基础上加以改进,较大地提升了模型训练速度和预测精度。传统的GBDT算法只利用一阶的导数信息,XGBoost[5]则对损失函数做了二阶的泰勒展开,并在目标函数之外加入正则项,整体求最优解,避免过拟合,提高了模型的求解效率,其步骤如下:
1)数据集D = {(xi,yi) :i= 1,2,… ,n,xi∈Rq,yi∈R} ,假定k(k= 1 ,2,… ,K)个回归树;xi为第i个数据点的特征向量;fk为一个回归树,F为回归树的集合空间,则可把一个迭代后集成的模型表示为
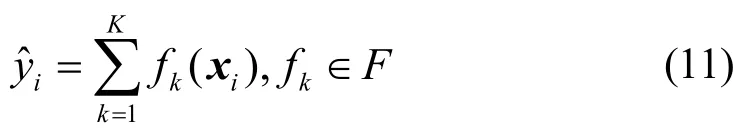
2) 目标函数为
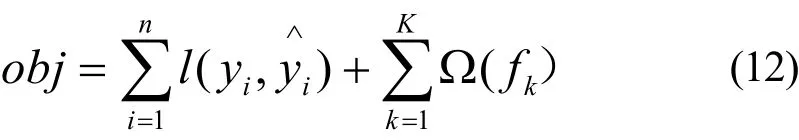
式中,yi表示真实值;表示预测值;第一部分是训练损失,如平方损失或Logistic Loss等;第二部分是每棵树的复杂度之和;第k棵树的复杂度用 Ω (fk)表示,其中T和w分别为树叶子节点数目和叶子权重值,γ为叶子惩罚系数,λ为叶子权重惩罚系数。
3) 采用additive training方式,即每次迭代生成一棵新的回归树,从而使预测值不断逼近真实值。每次保留原来的模型不变,加入一个新的函数f到模型里,XGBoost迭代方式如下:

4) 将式(12)代入式(11),可得

泰勒展开一般表达式为
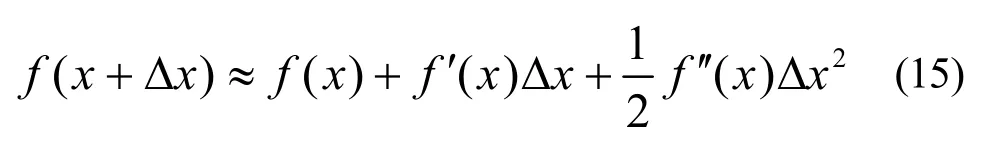
用泰勒展开式近似目标函数(式(14)),首先定义

那么,式(14)可得到

由式(16)可知,若移除常数项,该目标函数仅依赖每个数据点在误差函数上的一阶导数和二阶导数。
1.4 LightGBM算法
LightGBM算法是微软2015年提出的boosting框架模型[6-7],其基于传统的GBDT引入了梯度单边采样和独立特征合并技术(exclusive feature bundling,EFB)。数据通常是几十万维的稀疏数据,对不同维度的数据合并使一个稀疏矩阵变成稠密矩阵,独立特征合并技术实现了互斥特征捆绑,以减少特征数量。LightGBM算法对于树的生长采用了Leaf-wise,而不是Level-wise。Leaf-wise能够追求更高的精度,让更高精度的节点分裂,这样可能产生过拟合,因此利用max_depth来控制其最大高度。LightGBM 做数据合并、Histogram Algorithm和GOSS等操作时,都有正则化作用,所以使用Leaf-wise提高精度是一个较好的选择[11-12]。LightGBM使用histogram直方图算法[15]替换Pre-Sorted,减少了内存消耗。
2 建模流程
2.1 工件剩余寿命预测建模流程
工件剩余寿命预测建模流程如图1所示,采用的训练数据集是工件的全寿命数据。
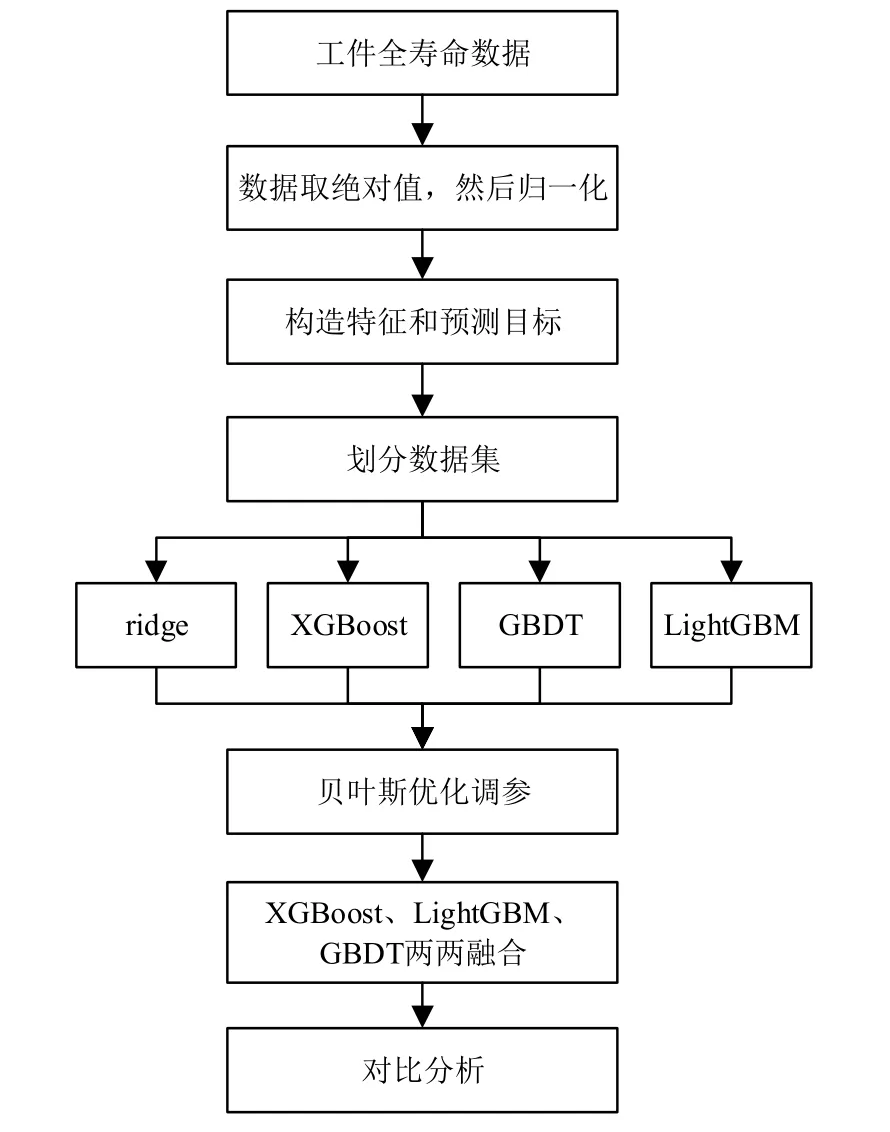
图1 工件剩余寿命预测建模流程
首先对工件全寿命数据进行预处理,包括异常数据删除、缺失值数据处理和数据归一化等;然后通过切分训练数据集构建训练集和测试集;最后使用python语言建立ridge模型、GBDT模型、XGBoost模型和LightGBM模型,并采用贝叶斯优化[8]进行参数自动寻优,再对XGBoost模型,LightGBM模型和GBDT模型两两融合,对比预测精度RMSE,确定最优预测模型。
2.2 工件全寿命数据描述及预处理
本文采用的数据源于2019工程机械核心部件寿命预测挑战赛的数据集,其中每个文件对应一个该类部件的全寿命物联网采样数据,即部件从安装到更换这段时间采样的对应指标数据,形式为多维时间序列。字段“部件工作时长”的最大值(通常为最后一行记录)即为该部件的实际寿命。具体特征如下:
1) 数值型字段包括:部件工作时长、累积量参数1、累积量参数2、转速信号1、转速信号2、压力信号1、压力信号2、温度信号、流量信号和电流信号;
2) 开关量字段(0或1)包括:开关1信号、开关2信号和告警信号1;
3) 字符串型字段:设备类型。
基于一个该类部件一段时间内的物联网采样数据,预测该部件此后的剩余寿命。
首先对数据集的负值采用绝对值处理,删掉具有数值极度跳跃的数据样本;然后通过数据集切分构造特征和预测目标,本文数据集共有916个数据样本,采用数据集切分比例依次为0.25,0.36,0.42,0.46,0.55,0.63,0.77,0.86和0.91;其次对切分得到的数据进行统计,如均值、中位数、最大值、最小值、一阶差分和二阶差分等;最后通过划分和统计特征,得到94个特征和8244个数据样本,部分特征如表1所示。

表1 数据集部分特征
训练集的寿命分布图如图2所示;归一化的寿命分布图如图3所示。
由图2、图3可知,归一化处理后,寿命分布图更接近正太分布,数据分布更加合理,有利于提高模型的预测精度。
特征间的相关性可用相关系数来评估[9],相关系数的绝对值大于0.6,则确定这2个特征具有强线性相关性。将强线性相关性的特征,只保留一个特征,即可保证模型的精度和运行速度。因特征数量较多,无法全部显示,部分特征的相关系数如表2所示。
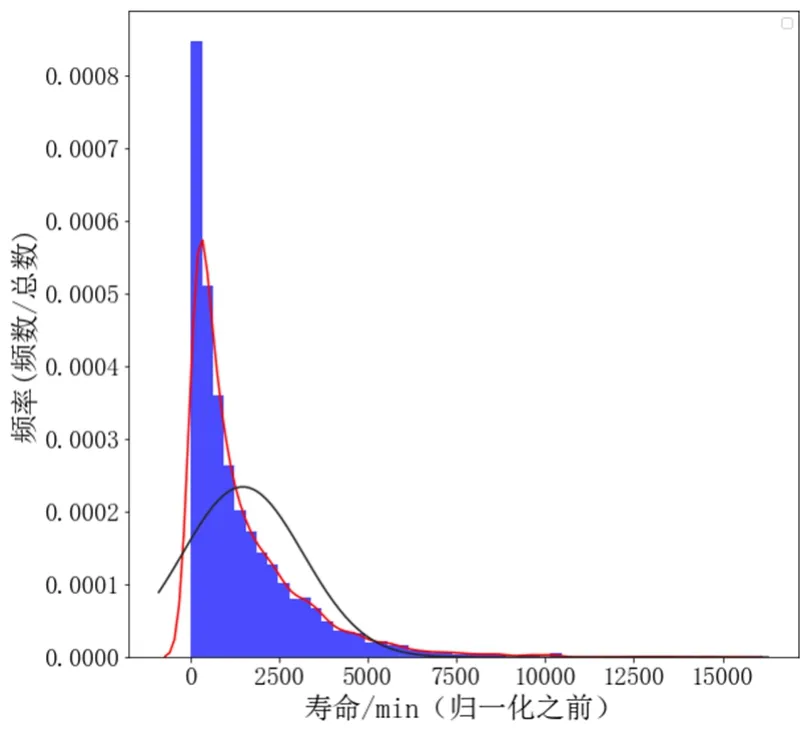
图2 归一化之前的寿命分布图

表2 部分特征的相关系数
2.3 模型评价标准
实验仿真采用均方根误差[14](root mean square error, RMSE)度量预测模型的精确度。RMSE值越小,表明预测越精准。

式中,n为样本个数;为第i个样本预测值;yi为第i个样本真实值。
2.4 建模过程和结果分析
本文仿真环境为Intel 酷睿i7 8700 CPU,16 GB内存;操作系统为Ubuntu 16.04;采用python3.6编程语言进行建模分析;建模过程中主要使用的机器学习库有pandas,numpy,matplotlib,joblib,tsfresh,sklearn,Multiprogressing,XGBoost和 LightGBM 等。
进行ridge模型、GBDT模型、XGBoost模型和LightGBM模型建模分析时,参数的选择对模型预测结果有较大影响,因此需要对模型参数进行一定程度的调优。ridge模型回归只需对正则项的λ进行调优;GBDT模型主要对迭代次数、学习率和树的最大深度及最大叶子节点数4个参数进行调优[15];LightGBM模型和XGBoost模型主要对学习率、叶节点数、迭代次数以及树的最大深度4个主要参数进行调优。本文利用贝叶斯优化进行参数调优,相比于传统的网格搜索法,具有精度高、速度快的特点。
利用ridge模型、GBDT模型、LightGBM模型和XGBoost模型拟合数据,可得到各模型的特征重要性排序。ridge模型通过模型内置函数coef_输出特征重要性;GBDT模型、LightGBM模型和XGBoost模型通过模型内置函数feature_ importances输出特征重要性[16],如图4所示。

图4(a) ridge模型重要性前十的特征
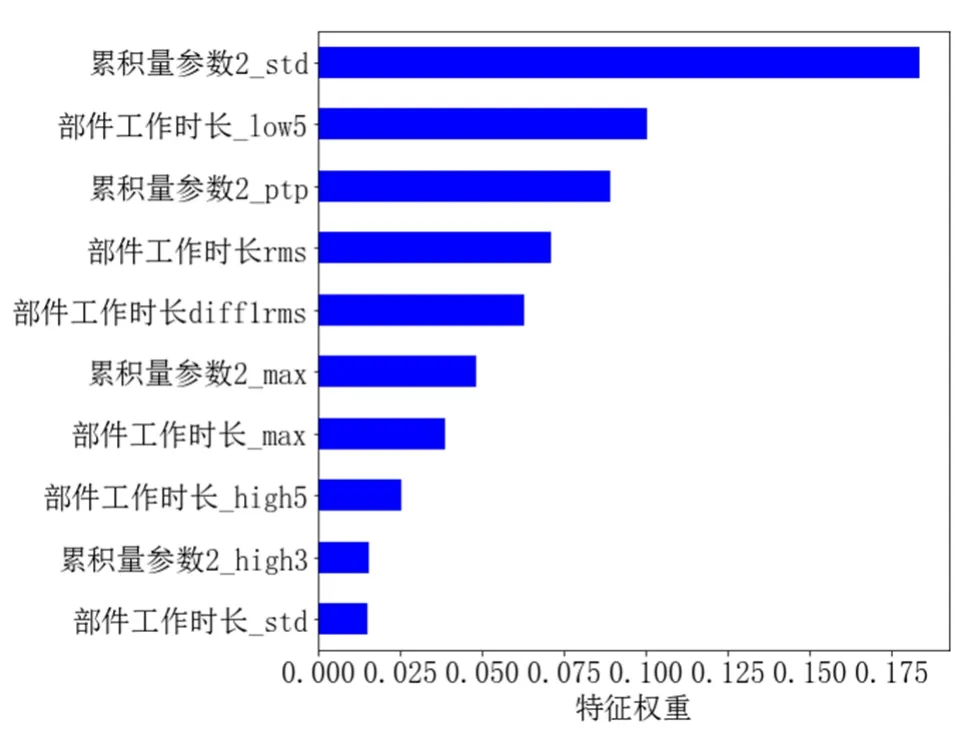
图4(b) GBDT模型重要性前十的特征
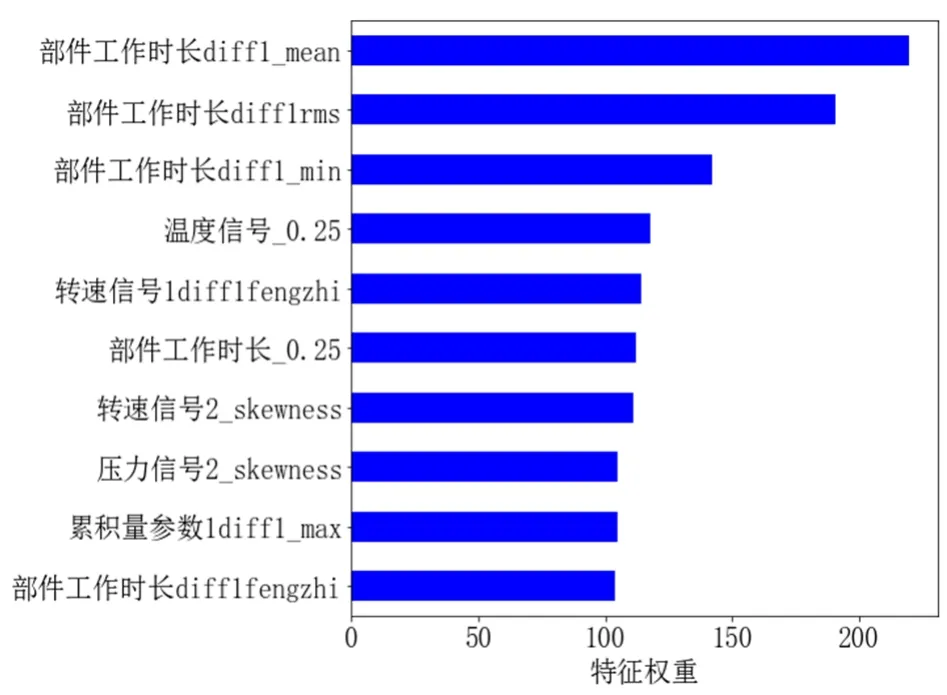
图4(c) LightGBM模型重要性前十的特征
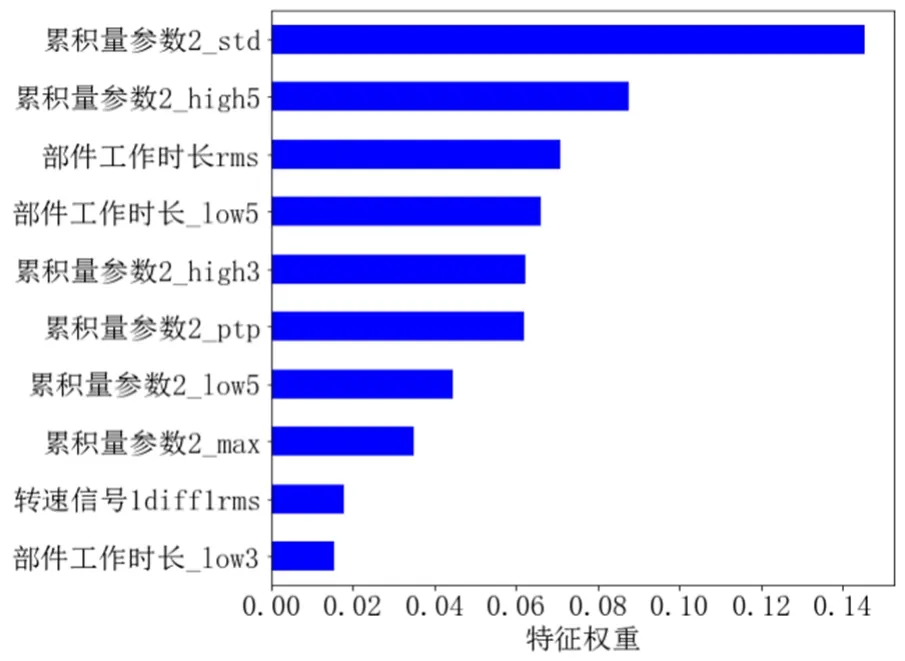
图4(d) XGBoost模型重要性前十的特征
由图5可知,4种模型选出的重要性前十的特征有一定差异,且同一模型的不同特征相对权重也有一定差异性,这种差异性体现了各个模型学习的特征具有不同的趋势,为提高模型融合精度提供了一定依据。
利用贝叶斯优化进行参数调优时,输入值是连续的,得到的最优参数需根据参数的物理含义进行取整,4种模型的最优参数如表3所示。
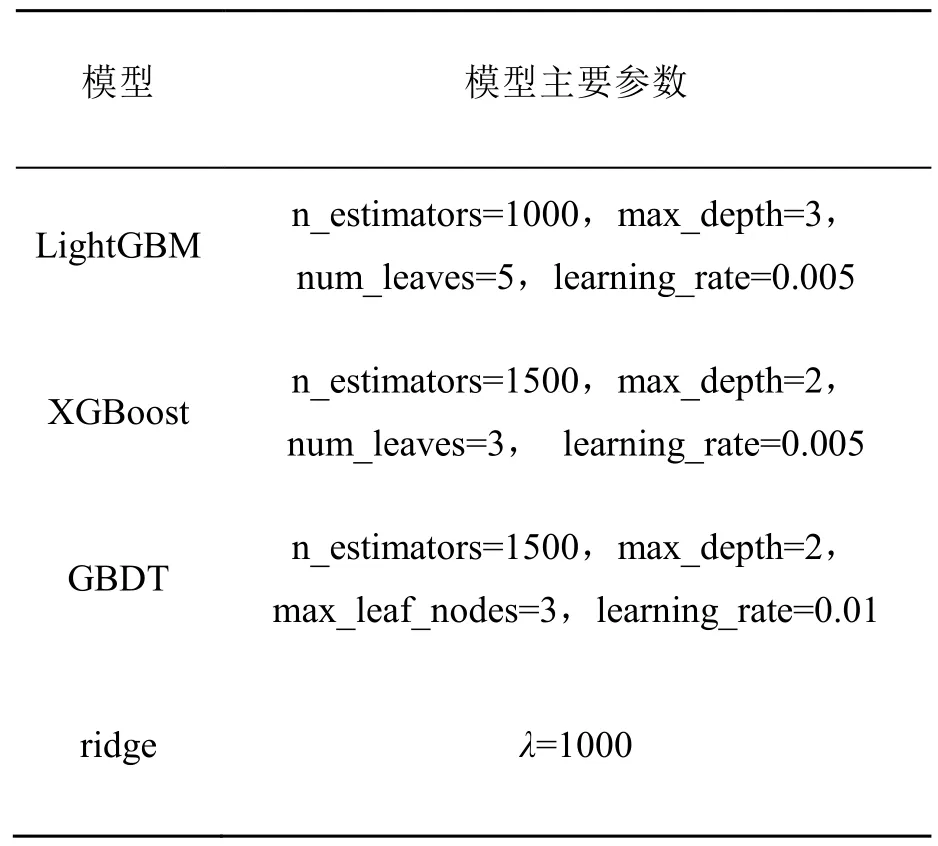
表3 模型主要参数的最优值
为保证算法的泛化性和实验的可移植性,将数据集随机抽样5对训练集和测试集,分别放入模型中进行训练;然后在测试集进行预测;最后用预测值和真实值计算RMSE,训练集和测试集的RMSE如图5所示。

图5(a) ridge模型预测精度RMSE
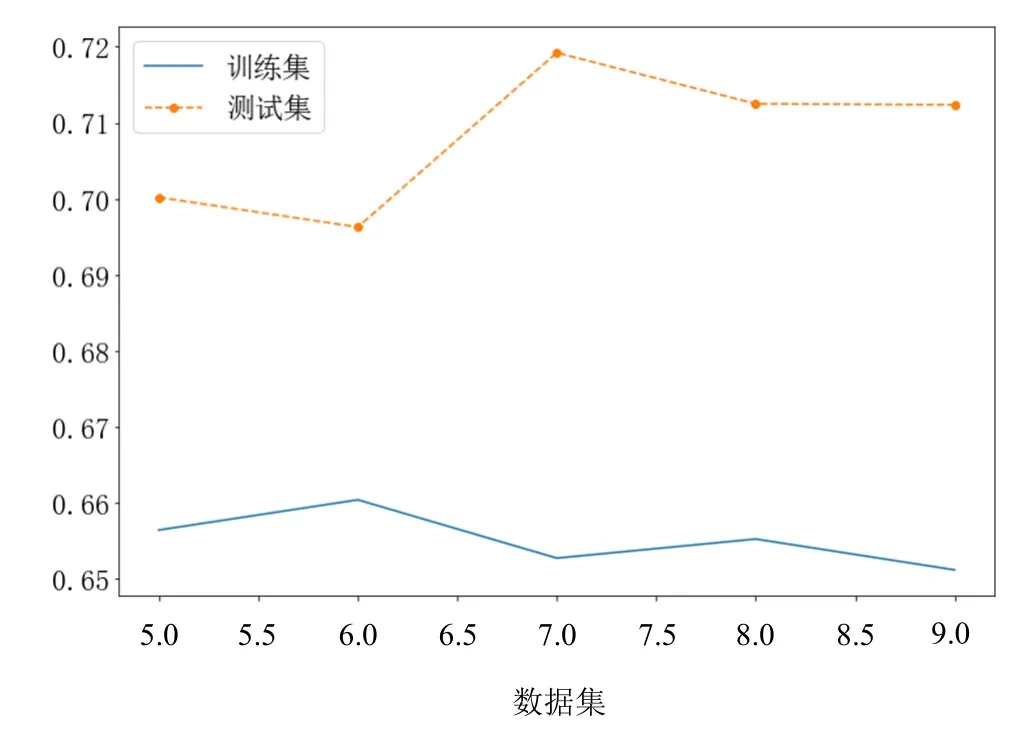
图5(b) GBDT模型预测精度RMSE
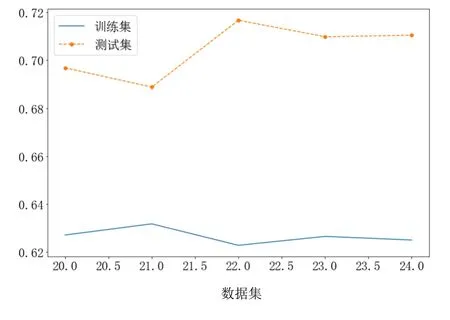
图5(e) XGBoost和LightGBM模型平均加权融合预测精度RMSE

图5(c) LightGBM模型预测精度RMSE
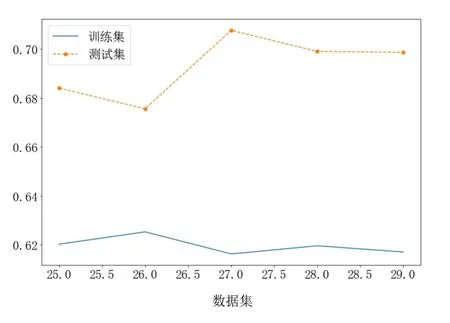
图5(f) XGBoost和GBDT模型平均加权融合预测精度RMSE
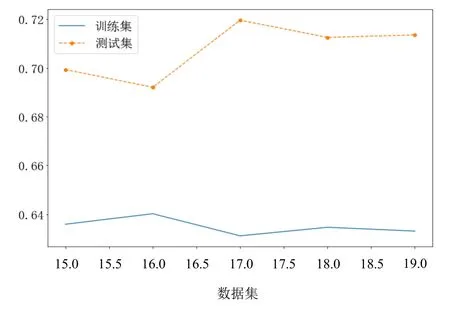
图5(d) XGBoost模型预测精度RMSE
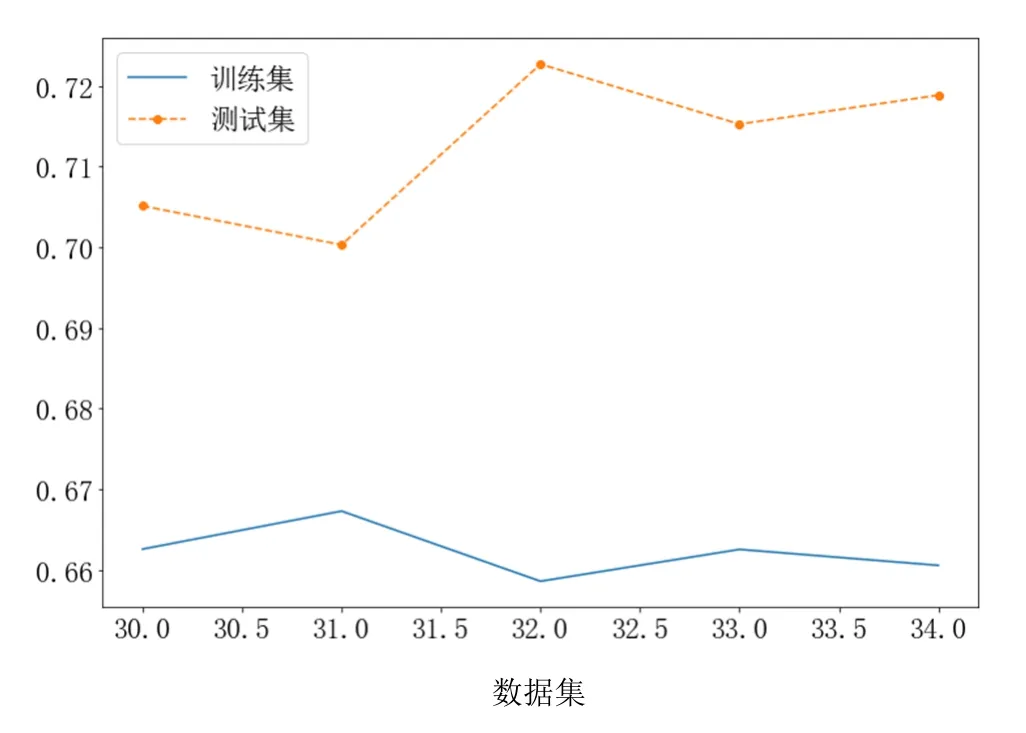
图5(g) LightGBM和GBDT模型平均加权融合预测精度RMSE
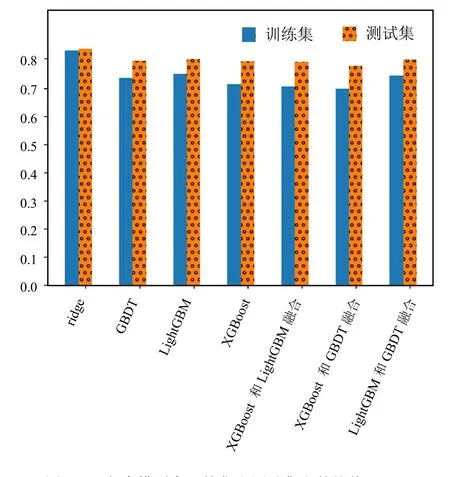
图5(h) 各个模型在训练集和测试集上的均值RMSE
由表3中模型输出特征的重要性可知,不同特征对不同模型的重要性有一定差异,如LightGBM模型最重要特征是流量信号0.25;XGBoost模型最重要特征是累积量参数 2_std;GBDT模型最重要特征是累积量参数2_std;ridge模型最重要特征是部件工作时长_std。另外,在重要性前十的特征里,LightGBM模型学习了告警1_sum,而其他模型没有。模型学习特征上的差异性,也为提高模型融合预测精度提供了依据。
从图5(a)、图5(b)、图5(c)和图5(d)可以看出,在高噪声环境下,3种树模型(GBDT模型、XGBoost模型和LightGBM模型)的抗干扰性比线性模型ridge好。从RMSE评估性能上看,XGBoost模型和GBDT模型在数据集 1~数据集 5,RMSE相差不多;LightGBM模型和ridge模型的RMSE比树模型差很多,因此本文不对ridge模型和树模型进行融合。从图5(e)、图5(f)、图5(g)和图5(h)可以看出,树模型的加权平均融合,可提升预测精度。在本文数据集上,XGBoost模型和GBDT模型的加权平均融合,提升效果最佳,相比于最佳单模型的XGBoost和GBDT的RMSE降低1%,这样可较大提升设备的使用效率;XGBoost模型和LightGBM模型的加权平均融合,相比于最佳单模型的 XGBoost模型和 GBDT模型的RMSE降低了0.3%;LightGBM模型和GBDT模型的加权模型融合,相比于最佳单模型的XGBoost模型和GBDT模型的RMSE降低了0.5%,相比于单模型的LightGBM模型降低了0.2%,相比于单模型的GBDT模型降低了0.5%。
3 结语
本文使用ridge模型、XGBoost模型、LightGBM模型和GBDT模型及同时将3种树模型进行两两加权平均融合预测工件的剩余寿命。从实验仿真的效果来看,树模型比线性ridge模型的预测精度高,可以看出树模型的抗干扰性较强。在树模型中,XGBoost模型和GBDT模型预测精度差不多,但比LightGBM模型预测精度高。采用模型加权平均融合的方式,对单模型来说,可提高模型的预测精度。本文XGBoost模型和 GBDT模型的融合效果较好,RMSE降低了1%;XGBoost模型和LightGBM模型融合RMSE降低了0.3%,但LightGBM模型和GBDT模型融合,RMSE降低了0.5%。因此,LightGBM模型、GBDT模型和XGBoost模型两两加权平均融合时,可提高工业工件剩余寿命的预测精度。
