基于Bagging算法的盾构机故障诊断方法*
2020-03-20史步海许家祥蒋通
史步海 许家祥 蒋通
(华南理工大学自动化科学与工程学院,广东 广州 510641)
0 引言
盾构机是一种大型综合性隧道挖掘设备,是现代地下掘进施工的重要装备。盾构机常在地下运行,工作环境复杂多变,易发生故障。常见的盾构机故障有刀盘结泥饼、刀具损坏、排泥管堵塞、塌陷和地质异常等,这些故障会影响施工进度。因此,通过盾构机的运行数据提前预知和诊断故障,对其安全高效施工具有重大现实意义。目前,盾构机故障诊断主要依靠施工人员根据经验进行判断,不仅效率低且浪费人力资源。一些学者对盾构机故障诊断做了相关研究:李贵红等[1]提出用经验模态分解和冲击脉冲法对盾构机的轴承进行故障诊断;郝用兴等[2]用差分进化算法和BP神经网络相结合的方法进行盾构机推进液压系统的故障诊断;李笑等[3]采用神经网络信息融合的方法对盾构机故障进行诊断;Shi B H等[4]利用LMBP神经网络对盾构机的常见故障进行预测和诊断。以上研究大多假设可获取数量相当的故障数据,但与实际数据不平衡的情况有所偏差;且多数研究仅采用单一的分类器进行故障诊断,影响模型的泛化能力。
采用传统分类器处理数据不平衡分类问题时,训练结果往往偏向于含有多数样本的类别,从而导致少数样本类别的正确率偏低[5]。数据不平衡问题的解决方案大致可分为2种:算法层面和数据层面[6]。算法层面主要对已有分类算法进行改进或提出新算法[7],使其在不平衡数据集上也能具有良好的分类效果,如王彩文等[8]提出的针对不平衡数据的改进近邻分类算法等。数据层面主要通过调整不同类别数据的比例,使样本类别数据大致均衡。常用方法有欠采样算法[9]、过采样算法[10]等,如付彬等[11]将合成少数类过采样技术(synthetic minority over-sampling technique,SMOTE)算法应用于不同人群的分类问题。
本文采用SMOTE算法合成人工样本以改善数据不平衡问题;针对模型单一的问题,利用Bagging算法在集成多个基分类器[12]的同时丰富基分类器的种类,提高模型的泛化能力。
1 算法介绍
1.1 SMOTE算法
SMOTE算法[13]主要思想是:少数类样本及其近邻的k个同类样本通过线性插值的方式合成新样本数据。采用SMOTE算法合成数据的过程:对属于每个少数类p的样本xi,采用近邻算法找到距离xi最近的k个近邻样本;然后在k个近邻样本中选择n个近邻样本[14],按式(1)合成新样本。

式中,为新合成样本;xi为属于每个少数类p的样本;rand( 0,1)为区间(0,1)的一个随机数;xij为距离xi最近的第j个属于p类的近邻样本。
1.2 集成学习算法
集成学习算法可融合多个分类器的分类效果,相比于单个分类器,集成学习算法可有效提高故障预测的准确性和模型的泛化能力。常用集成学习算法有Boosting算法[15]和Bagging算法[16]。这两种算法通过对多个弱分类器按一定的方式组合,得到一个具有更优性能的强分类器。
本文采用Bagging算法将多个不稳定的基分类器集成,并通过分类投票机制[17]构成一个具有更好分类效果的强分类器[18]。Bagging算法通过对训练样本进行可放回地随机采样,获得多个样本数量相当且相互有一定差异的样本集合;用每一个样本集合分别训练一个基分类器;每一个基分类器的决策结果通过投票方式得出样本的分类属性,从而提高不稳定分类模型的泛化能力。
2 分类模型构建与性能指标
采用SMOTE算法和Bagging算法实现不平衡故障数据的诊断;选择CART决策树算法、BP神经网络算法和k近邻算法为基本分类器算法。首先采用Bagging算法对 3种基本算法的T个分类器进行集成,得到 3个集成分类器;再采用投票输出方式对3个集成分类器投票组合,得到集成分类器H(x),其结构如图1所示。

图1 分类模型结构图
训练分类器的主要步骤:
1) 采集盾构机的故障数据Xall和标签Yall,按一定比例划分为训练集Xtrain,Ytrain和测试集Xtest,Ytest;
2) 统计训练集中各类别的样本数量,并采用SMOTE算法对少数类样本人工合成新数据,使得各类别的样本量均等于原训练集中样本数最多的类别,得到新训练集
4) 取每一个子集合训练一个基分类器,将各类别的T个基分类器用 Bagging算法组合成3个集成分类器;
5) 将3个集成分类器采用投票机制组合,并根据实际情况调整各分类器的投票权重,得到最终集成分类器H(x)。
对于一般分类问题,常用测试集的准确率作为评价分类器的性能指标。但为了更合理地评价不平衡分类器的性能,还需考虑少数类分类的正确率与多数类分类的准确率之间的均衡性。本文选用分类器的G-mean值[19]作为性能指标,该值为各类别召回率的几何平均值,可以较好地平衡各类别准确率,计算公式为

式中,K为分类器类别数;Ri为第i类样本的召回率,计算公式为

式中nii为第i类样本被分类器分为类别j的数量。
3 仿真与对比
仿真实验采用的数据来源于广州某施工单位的泥水平衡盾构机的施工数据。实验数据包括刀具磨损数据1657组、结泥饼数据767组、排泥管堵塞数据76组、地质异常数据75组和正常数据2198组。施工专家通过对不同地质情况主要变量如何操作及变量相互关联情况的分析,选择刀盘扭矩、千斤顶推力、千斤顶速度、切削面水压和土砂密封冷却水温度5个参数组成输入向量x。类别标签y在各种情况的取值如表1所示。
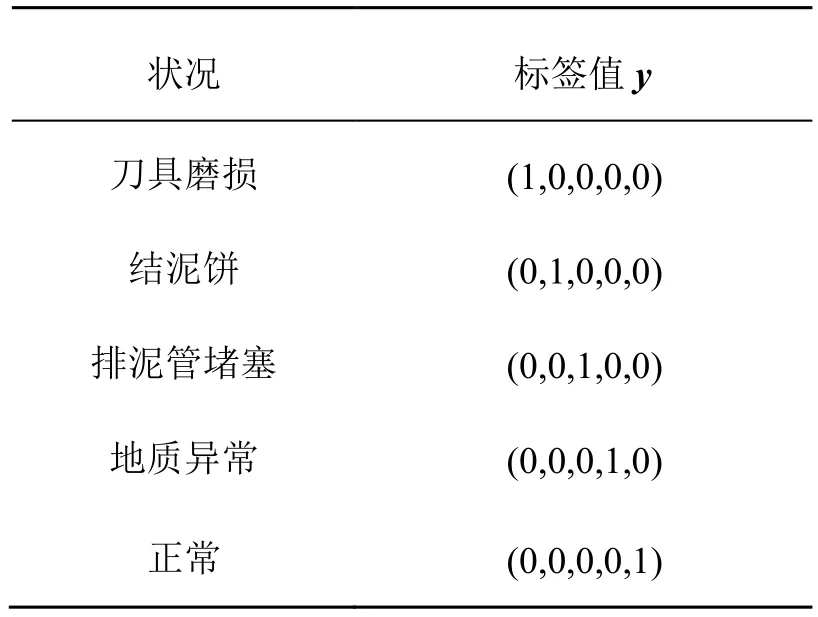
表1 各种情况的标签值y
将原始数据按每种类型1:1的比例随机分成训练集和测试集。训练集中各类别的数据量及经过取近邻数k=5的SMOTE算法插值后的数据量如表2所示。在进行训练之前,先对训练数据进行归一化处理,将所有数据映射到[0, 1]区间内,从而加快模型的收敛速度,归一化公式为

式中,x为训练样本数据;xmin为训练样本中最小值;xmax为训练样本中最大值。

表2 SMOTE前后训练集数量
经调试,选择算法中的参数值T= 5,决策树选用CART算法,BP神经网络选用一层隐含层,隐含层网络单元为48个,学习率为0.01,k= 5;采用投票权重为最终得到分类器H(x)的G-mean= 95.28%。本实验选择常用机器学习分类算法进行对比,包括CART决策树、BP神经网络分类和KNN分类3种模型。由于SMOTE算法和Bagging算法具有一定的随机性,导致结果不稳定,本实验在同等情况下运行20次求各分类器性能指标的平均值进行对比,结果如表3所示。

表3 模型结果对比
由表3可知,采用SMOTE人工合成样本在一定程度上提高了G-mean值,这是因为增加的少数类样本可以代表少数类的分布情况,改善了数据不平衡对分类器造成的影响。采用多个分类器进行Bagging算法的集成在多数情况下有利于提高分类器的多样性,也可有效提高模型的泛化能力。本文采用SMOTE人工合成算法、Bagging算法和投票机制组成的分类器G-mean值高于Bagging_SMOTE_CART,Bagging_SMOTE_BPNN和Bagging_SMOTE_KNN 3种算法,这是因为通过投票机制集成的最终分类器和传统Bagging算法相比,进一步提高基分类器的多样性,使G-mean值更高,对不平衡数据集具有更强的分类能力。
4 结论
盾构机在运行过程中发生各种故障的频率不同等原因,导致采集到的各种故障数据数量难以达到平衡。本文结合实际情况,针对盾构机故障诊断数据不平衡的问题,采用SMOTE算法合成样本数据,并针对故障诊断采用单一分类器泛化能力不足的问题,采用基于多种基分类器的 Bagging算法加权投票方式,提高分类器的多样性,从而提高故障诊断预测模型的泛化能力。仿真实验结果表明,本文算法用于盾构机故障种类诊断,准确率较高。
