测量误差分析及数据处理若干要点系列论文(一)
——现代数据处理基本观念与四字要诀
2020-03-20林洪桦
林洪桦
(北京理工大学,北京 100081)
1 现代数据处理基本观念
现代数据处理范围广阔,本文研究仅限于测量误差分析方面的数据处理。随着科技不断发展,在当前信息化时代,数据成为科技发展的重要信息资源,数据处理的基本观念也将随之而作必要的适应性转变。
1.1 数据处理目标
数据处理的目标是待求现实问题符合实际的解答。在此应用现实问题较之以往所用的实际问题是为了强调其所含有的物理本质信息。
1.2 数据处理依据
数据处理的依据是有效的样本数据和有用的先验信息。若要解答待求的现实问题,对样本容量n有一定的要求。如在概率分布估计中n<100;对于参数估计 n<30~50;广义而言,函数估计中 n/dVC<20(dVC为函数VC维数)称为小样本,超过上述界限多视为大样本,这些均属经验积累结果[1]。小样本并未明确定义,其容量n也无确切界限。实际上所能得到的有限数据多未能全面体现现实问题的总体规律,也不满足极限定理与大数定律的条件。可见,大多数现实数据只能属于小样本。小样本自身具有随机性,其样本特征量也具有随机性,难以体现其总体分布规律,尤其是对称性,需有识别与拓展总体信息之对策。
至于先验信息,涉及来源可靠性、主观概率和运用方法,如贝叶斯方法等,常易被忽视。
1.3 数据处理实质
数据处理实质是对现实的模拟,以数学模型模拟现有数据及先验信息所体现的总体规律性。故数据处理所评估与预测的结果应能够准确地显示最本质的总体规律。还需强调指出,实际上只要解答待求总体规律中的某种特性即可,无需求得全面的总体规律。
1.4 现实问题的性质
非线性、非平稳和非高斯/非正态统称三非性。实质上,现实问题均具有三非性。然而,对三非性问题的处理较难且复杂,而数据处理则要求尽量简捷,于是运用够准的线性化、平稳化方法。唯独现实的非高斯分布不可简化,只能够准地模拟,构成重点难题。
1.5 随机性分布
随机性分布以非高斯性分布为常态,运用统示法处理。
现代数据处理对于概率分布模式的处理,在观念上需作相应的变化。如对于测量误差有界性、相消性(相对期望而言)还具有普适性意义,而单峰性、对称性则并非普适性分布规律;非高斯性/非正态性为常态(现代多称非高斯性,下同),而高斯性只是特例;对于随机性变量不宜说为××理论概率分布,只能说可按××分布处理;可见,为有别于具有严格定义的概率分布而以随机性分布模拟之。
在现实问题中,高斯分布随机影响因素未必占大多数,而非高斯分布的随机影响客观存在,随处可见;且对非高斯分布随机影响的统计处理方法较高斯分布复杂又难处理。非高斯分布不仅在理论分析上较难,即使在统计处理的特征量分析上,也比高斯分布仅需前二阶矩要多,至少需多考虑表示偏态和峰态的三阶和四阶矩,甚至更高阶矩。随着数字计算机及最优化技术的广泛应用,对非高斯分布随机影响的统计处理不仅可实现,并已研究出许多有效而实用的统计处理方法。以往之所以多按正态分布处理主要依据中心极限定理及渐近性理论(却难满足其理论的条件),而更重要的还在于其简便实用。况且,需考虑必然会存在某些重要的非高斯性先验影响因素。总之,宜建立非高斯性应为常态的观念。
一个值得注意的总观念:从特殊到特殊的转导推理[2-3],即按所掌握的有限信息直接估计和预测出某一待求现实问题的结果,不必按传统的从特殊到一般再到特殊的归纳演绎推理方法。如目标只是估计某一函数在某个待求点的值,就不必去估计出整个函数或其全域值;应尽量降低求解的要求,以获得更为准确、更合乎实际的解。应用在误差评估中,若目标只是估计误差范围就无需估计其理论概率分布,尤其对于小样本很难估计出其实际总体分布。
2 数据处理对策的四字要诀
概言之,数据处理的基本任务不外乎分离其所含有的信息,即按待解答现实问题的需求,识别并提取出其中有用的本质信息,分离并摈弃其无用的无关信息(如误差、噪声等)。然而,不同的现实问题,其相应的数据含有信息的复杂性各异,所要求的分离技术和方法存在很大差别。显然数据处理对策各异,对于现代数据处理可归结出四字要诀:实、佳、智、验,且大体上对应着数据处理的四要素:模型、准则、算法、验证。
2.1 实——兼有真实性与实用性,尤其指模型化应合乎实际
综观现代数据处理无不先行模型化,即首先按所要求的准确度建立反映现实问题的数学模型。多将建模要求归结为:实——反映现实问题所含有的本质信息;准——准确度;易——易算性;省——节省性[1]。其中实与准密切关联,诸要求相互制约。显然,应以实为主,若建立的数学模型不合乎实际或欠准确,其后的数据处理结果必然无效。可见,实——模型化具有真实性与实用性应为现代数据处理中最具决定性的关键环节,又是居首位之难点。
严格地说,合乎实际的模型化并非一家所能,宜由各有关专家共同建模为好。熟知,一些有用信息甚至是显著的主要信息未必含于多次重复测量数据之中,如高准确性测量中的基准件误差就属于先验信息。即仅靠数据处理还不能完整地得到实际问题含有的所有信息。然而对模型化则要求应完整地反映出实际问题所含有的本质信息,这正是模型化的主要难点。
显然,要做到实所涉及的面广、专业性强,非一纸可尽述。
还需强调,在数据处理全过程均需考虑做到实。经验表明,做好以下两点将有助于模型化合乎实际。
2.1.1 预处理
预处理目的和作用在于分析数据特性、汇集先验信息、初定数据处理方案。
建议:1) 观察数据图,如坐标图、直方图等;2) 分析特征量,如前四阶矩、分位数等;3) 检验异常值;检验对称性,如中位值与均值重合性或零偏态性检验等;4) 检验趋势性和周期性;5) 搜集先验信息,通过理论分析、实验结果、技术资料以及主观经验等,汇集后便可初步拟定出数据处理方案。
2.1.2 模型化具有普适性
通常可依据的可靠信息常不足以使模型化合乎实际。
建议:选用普适性模型通过适当的数据处理使之合乎实际。如对于概率分布模式采用统示法pi(x)=p(x,θi)[1];用广义多项式做模型化,采用逐步回归、调整回归、递推回归等可选显著变量的方法拟合最终所用的模型[4]。
例如
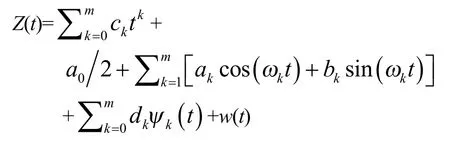
式中,Ψ(*)为特定函数;w(t)为白噪声。
又如,数字滤波中的状态模型
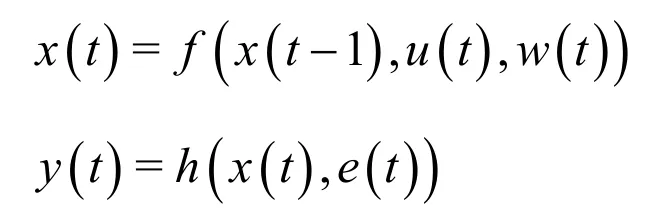
2.2 佳——数据处理应遵从最佳性原则
众所周知,如何最终体现出数据处理具有最佳性则未必都能思考得周全。评价佳应为处理结果最逼近于现实问题或其间的误差最小。这就涉及逼近度或误差的量化。不同形式的量化生成各种类型的最佳准则及其相应的算法。
最小误差类:参数估计的最小二乘、最小均方等准则,归纳为最小范数
最小风险类:Bayers统计分析的各种风险准则,如结构风险最小化准则等;
信息论方法类:基于信息熵的各种信息论方法含最大熵、最小互熵、AIC和MDL等准则。
各种最佳准则具有各自生成的理论条件,而现实问题未必完全满足甚至不满足这种条件,相应数据处理的最佳性就将削弱甚至失去。有些现实问题专用其最佳准则,如形位误差评定标准规定为最小区域也即最大最小准则。可见,佳具有条件性和相对性。如均值在无粗大误差和变量系统误差影响下可作为测量结果的最佳估计。否则,采用其他稳健估计(如中位值或截尾均值等)则更佳[1]。
对数据处理的要求不同,佳的体现也各异。如对数据处理常有预测性要求,则其最佳性原则中就应含有泛化性或推广性,即预测误差要小,并非只计及对数据的拟合误差最小。如结构风险最小原则中含VC置信范围、验证拟合模型的最小描述长度(MDL)准则中含数据量约束项等[1]。
2.3 智——处理方法智能化
现代数据处理中多见不适定的逆问题,且为非线性度较强、非凸性的现实问题。传统处理方法多在求极值点原则下,算法以逐步迭代逼近为主。有诸多缺陷,如要求连续可微性;易受初始化影响;无通用性等,尤其难有全局优化性,其处理结果就未必具有最佳型。然而,多数智能化处理方法实质上是按适应度要求进行智能性全域随机搜索,使之对优化对象无特殊限制,具有普适性;适应度可直接取实际优化目标值;智能性策略全域搜索出全局最优解;始于一组可行解,初始化影响小等。这些特点可用于解决许多难题,扩展了应用领域。
实质上,人类智能才是智能化之源泉。自上世纪中叶智能化命名以来,智能化算法就层出不穷地接连提出,名目繁多,在选用上首要考虑其全局优化性能,这也是各种智能化算法改进的重点。对于其余的性能要求无异于一般算法,如收敛性、简捷性等,只需提醒一点,停机条件按够准即止原则。
智还可从2方面理解:运用合适的智能化算法解决复杂难题只是其一;从当前机器学习观念上看,进一步得出对现实问题的性能改进策略,是不可忽视的另一面。
2.4 验——验证处理结果的准确性
评价数据处理方法及处理结果,如模型实用性和简约性、算法准确性和简捷性等,均需予以验证。验证项目及其指标与被测量及其测量方法有关,其中最主要又是最难以验证的应为准确度。尤其高准确度测量中常含有未引起数据变动的系统误差因素,且多为主要成分。验证方法颇多(以往多用理论解析、物理方法和实验方法等),推荐采用基于MonteCarlo方法的给定误差的数据仿真验证方法。给定误差的等级应与实际问题所要求的准确度相当或略高些,数据形式与所测的实际数据类同,并依据先验信息设置已知误差值的各种类型的系统误差和某种概率分布的随机误差。对这种已知其误差值的仿真数据也通过所拟定的数据处理方法即可验证出处理结果的准确性。
验证处理结果的仿真模型可拟定如下:以某一平面度测量为例
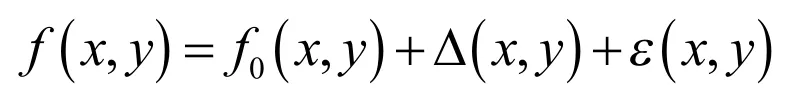
式中,f(x,y)为含已知误差的仿真数据;f0(x,y)为理想形状,如理想平面真值;Δ (x,y)为系统误差,这是仿真之主项,多依先验信息来设置,且需给定与实际问题相适应的误差值;ε(x,y)为某种概率分布的(如β分布)随机误差。且可按所得先验信息设值
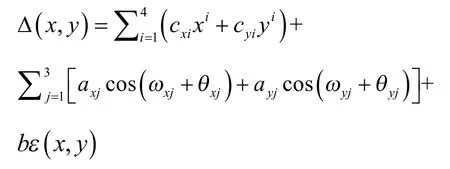
式中,cxi,cyi,axj,ayj,b及ε(x,y)宜按略高于形位误差的准确度设定。对于已有MZ判别准则者,还可特设合乎该准则的等值最高点和最低点,并可改变其位置更利于验证。总之,依据待求的现实问题而做具体的设置。
3 结语
“实、佳、智、验”四字互抑;取主舍次;均衡择优;够准为限。
本文主要概述当前测量误差分析及数据处理所应建立的一些主要观念与需要作全面思考的数据处理策略。至于解决现实问题的具体方法及示例等将在此后的系列论文中陆续阐述。欢迎读者们提出宝贵意见和建议。
