深度学习下融合不同模型的小样本表情识别*
2020-03-19林克正白婧轩李昊天
林克正,白婧轩,李昊天,李 骜
哈尔滨理工大学 计算机科学与技术学院,哈尔滨150080
1 引言
人脸表情识别一直是富有挑战性的研究课题,在检测精神障碍、人机交互等方面有着广泛的应用。它有助于创造出更多具有识别人类情绪能力的智能机器人。许多现实生活中的应用程序,如疲劳驾驶检测和互动游戏开发,也得益于这种技术。目前表情识别领域运用多种特征提取和机器学习算法。
早期的人脸表情识别研究大多基于手工制作的特征[1]。在ImageNet 大型视觉识别竞赛(ImageNet large scale visual recognition challenge,ILSVRC)[2],AlexNet[3]深度卷积神经网络模型取得成功后,深度学习在计算机视觉领域中开始得到广泛的应用。人脸表情识别(facial expression recognition,FER)挑战[4]或许是最早提出表情识别运用深度学习方法的作品之一。之后在2013年FER 挑战赛中得分最高的系统是深度卷积神经网络[5],而手工特征的最佳模型仅排在第四位[6]。除了少数例外[7-8],最近关于人脸表情识别的研究大多基于深度学习[9-14]。最近的研究[15]提出训练卷积神经网络级联从而提高性能。在大多数情况下,CNN(convolutional neural network)的训练依赖大量的数据,然而在模型训练中,样本的大小会直接影响模型和网络,故当样本有限时,模型很容易发生过拟合现象,因此在样本有限时,希望防止过拟合并且不影响性能甚至提高性能。目前通常采用的方法是,样本的旋转、对比度分析、光亮度变化来进行样本扩充。虽然这样可以在一定程度上增加样本数量,但更容易产生过拟合现象。Kaya 等人[16]则将深层特征与HOG(histogram of oriented gradient)、局部Gabor 二元模式的手工制作的特征结合起来使用,从而提高性能。黄凯奇等人[17]利用迁移学习得到很好的泛化模型,但是识别准确率不是特别理想。Zhang等人[18]的生成对抗网络与迁移学习的集合模型在小样本中达到较高的识别准确率。
因此本文提出了深度学习下融合不同模型的小样本表情识别方法。首先对单个CNN 模型进行比较,筛选相对合适的CNN,然后SIFT(scale-invariant feature transformation)提取局部特征,最后将所有模型进行汇总,得到CNN-SIFT-AVG(convolutional neural network and scale-invariant feature transformation average)模型。虽然尺度不变特征变换[19]和其他传统局部特征提取方法的结果不如CNN 准确,但它们不需要大量的数据集就可以得出结果。模型分别在FER2013、CK+和JAFFE 三个数据集上进行实验。
本文的主要贡献:(1)研究了SIFT 特征与CNN结合对小数据性能的影响。(2)设计了一种新的基于CNN 和SIFT 模型的人脸表情识别分类器,在FER2013、CK+和JAFFE 三个数据集上都得到了更好的识别效果。(3)可以降低在人脸表情识别过程中训练样本的成本。
2 深度学习与特征提取
2.1 卷积神经网络
(1)卷积层
对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏置项。卷积层内每个神经元都与前一层中位置接近的区域的多个神经元相连,区域的大小取决于卷积核的大小。卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量,计算方式如式(1)所示:

式中的求和部分等价于求解一次交叉相关。b为偏差量,Zl和Zl+1表示第l+1 层的卷积输入和输出,也被称为特征图,Ll+1为Zl+1的尺寸,这里假设特征图长宽相同。Z(i,j)对应特征图的像素,k为特征图的通道数,f、s0和p是卷积层参数,对应卷积核大小、卷积步长(stride)和填充(padding)层数。
(2)dropout正则化方法
dropout 层是通过遍历神经网络每一层的节点,然后通过对该层的神经网络设置一个节点保留概率p,即该层的节点有p的概率被保留,p的取值范围在0 到1 之间。通过设置该层神经网络的节点保留概率,使得神经网络不会偏向于某一个节点(因为该节点有可能被删除),从而使得每一个节点的权重不会过大,来减轻神经网络的过拟合。标准网络如图1所示,带有dropout网络的如图2 所示。
Fig.1 Standard neural network图1 标准的神经网络

Fig.2 Part of temporarily deleted neurons图2 部分临时被删除的神经元
在训练模型阶段,训练网络的每个单元都要添加一道概率流程。没有采用dropout 方法的如式(2)。预测的时候,每一个单元的参数要预乘以p。

采用dropout网络的如式(3)。
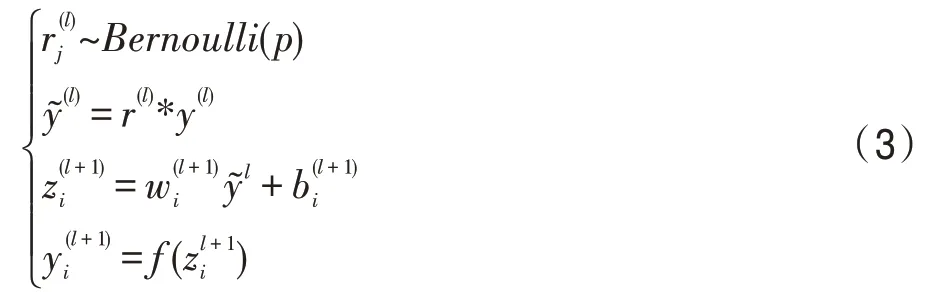
(3)激活函数
ReLU 函数如式(4),当x<0 时,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。故针对x<0 的硬饱和问题,采用Leaky ReLU 函数,函数如式(5)。
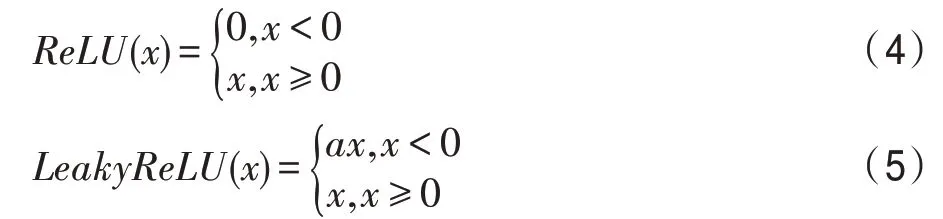
使用Leaky ReLU 优于ReLU 的优点是:ReLU 是将所有的负值都设为零,相反Leaky ReLU 中,a是一个很小的常数,这样保留了一些负轴的值,使得负轴的信息不会全部丢失。这就解决了ReLU 函数进入负值区间后,导致神经元不学习的问题。
2.2 局部特征提取
SIFT 特征在旋转、尺度缩放、亮度等情况下可以保持不变性,因此对于每个图像,采用尺度不变特征变换(SIFT)从人脸图像中提取关键点。定位关键点后,利用关键点相邻的像素点计算网格的方向和大小。为了识别主方向,建立梯度直方图。最后,SIFT描述符通过将图像分割成4×4个正方形来确定。对于每一个正方形中的16个方块,采用一个长度为8的向量来表示。通过合并所有的向量,得到每个关键点的大小为4×4×8=128 的特征向量,最后进行归一化处理。如式(6)所示。

3 CNN-SIFT-AVG 模型
3.1 CNN 网络模型结构
本文的网络模型结构的输入层是像素为48×48的灰度图像,即为1 的单通道图像,故输入的图像维度用48×48×1 来表示。卷积层是一个3×3 的过滤器(filter),为了保持输入输出规格的空间大小不变,在边框周围添加了零填充padding。过滤器处理的矩阵深度和当前神经网络节点矩阵的深度是一致的,故为1。通过一个filter 与输入图像的卷积可以得到一个48×48×1 的特征图,连续用32个filter 得到了32个特征图。卷积过后输入图像的像素位置再进行滑动,滑动步长stride等于1。
然后采用最大池对卷积结果进行了整合,它是一种非线性下采样。此处采用2×2 过滤器,对每一个2×2 的区域进行一次最大池化操作。同时每添加一次最大池化层,下一层卷积核的数量就会翻倍。因此卷积滤波器的数目分别为64、128 和256。
卷积层输出之后,完成flatten,再输入给全连接层,全连接层由2 048个神经元组成。在每个最大池化层之后引入一个dropout 层,来降低网络过拟合的风险。最后,在网络的最后一个阶段放置一个softmax 层,该层有7个输出。
为了给CNN 引入非线性,使用了Leaky ReLU 作为激活函数,函数图像如图3。具体参数如式(7)。最后,损失函数用分类交叉熵的方法,采用自适应梯度优化方法Adam 进行优化。

Fig.3 Leaky ReLU functional image图3 Leaky ReLU 函数图像

为了获得更好的分类性能,使用了多个CNN 模型。算法中采用dropout正则化方式,很好地解决了由于训练样本较少,学习到的特征不足而产生的过拟合问题。其中dropout的概率p会影响模型的效果。通常情况下概率p∈[0,0.5]之间,因为如果比例p太小则起不到效果,太大则会导致模型欠拟合。故在{0,0.05,0.10,…,0.45,0.50}范围内确定相对合适的p值。
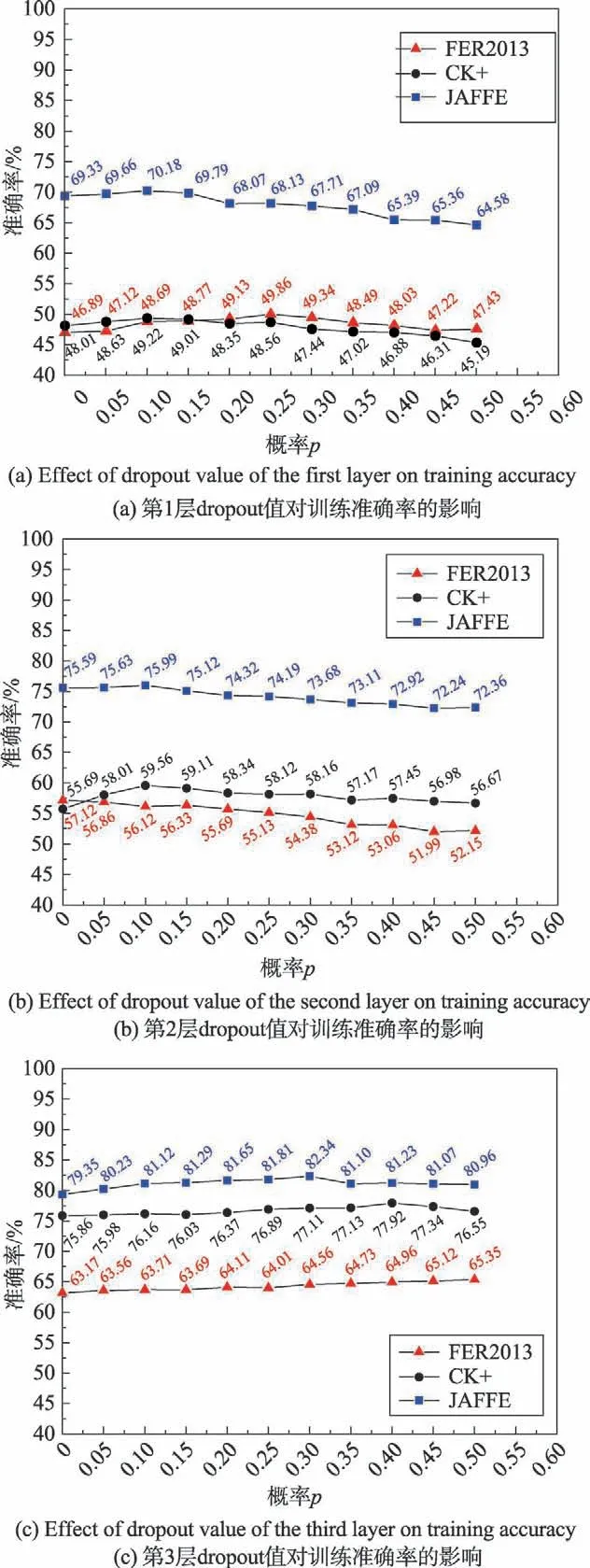
Fig.4 Effect of different dropout values in different layers on training accuracy图4 不同层中不同的dropout值对训练准确率的影响
由图4中可以看出,CNN模型的结果会因为概率p的变化而随之变化,由图4(a)~图4(c)可知:FER2013数据集中第1 层的p=0.25,第2 层的p=0,第3 层的p=0.5 时效果最好;CK+数据集中第1 层的p=0.1,第2 层的p=0.1,第3 层的p=0.4 时效果最好;JAFFE数据集中第1 层的p=0.1,第2 层的p=0.1,第3 层的p=0.3 时效果最好。因此建立了3种不同的dropout概率的模型,即C1、C2和C3。改变dropout概率是为了增加模型的多样性。在C1时,dropout1=0.25,dropout2=0,dropout3=0.5。C2时,dropout1=0.1,dropout2=0.1,dropout3=0.4。C3时,dropout1=0.1,dropout2=0.1,dropout3=0.3,dropout4恒为0.5。整体CNN 模型如图5 所示。

Fig.5 Adopted CNN model图5 采用的CNN 模型
3.2 不同特征融合模型
为了在分类中使用SIFT 中的关键点描述符,需要一个固定大小的向量。为此,K-means 用于将描述符分组到一些集群中。然后通过计算每个集群中包含的描述符的数量形成一袋关键点,得到的特征向量的大小为K。
K向量通过4 096 全连接层,以及dropout 层。全连通层的权值采用L2 范数正则化,取值为0.01。3 种不同的模式S1、S2、S3都已经做过实验,每个模型的K值分别为K1=256、K2=512 和K3=1 024。最后与C2模式合并,如图6 所示。
为了提高模型的准确性,使用简单平均的方法对CNN-ONLY、CNN-SIFT 和CNN-SIFT-AVG 输出进行模型融合。如图7 所示。其中CNN-ONLY 仅为C1、C2、C3的普通平均值,如式(8)。CNN-SIFT为S1、S2、S3的普通平均,如式(9)。最后,将6个模型普通平均到CNN-SIFT-AVG 模型中,如式(10)。
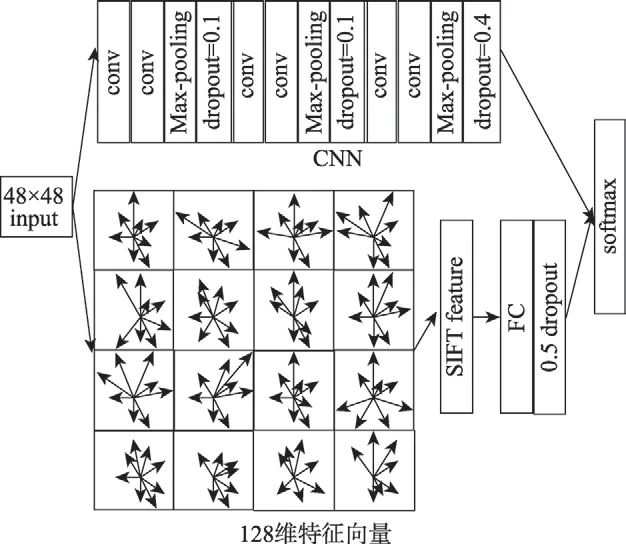
Fig.6 Fusion of CNN and SIFT model图6 CNN 与SIFT 模型融合
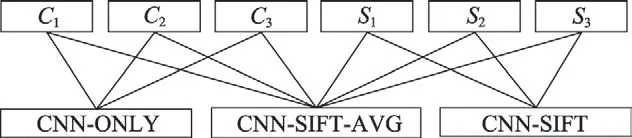
Fig.7 Aggregating all models into CNN-ONLY,CNN-SIFT and CNN-SIFT-AVG图7 将所有模型融合为CNN-ONLY、CNN-SIFT和CNN-SIFT-AVG

xCi表示在Ci模型下的输入,C(e|xCi)表示在Ci模型下判定为某一表情的概率。xSi表示输入在Si模式下,由上文可知,S1时K=256,S2时K=512,S3时K=1 024,S(e|xSi)表示在Si模式下判定为某一表情的概率。P1(e|x)表示CNN-ONLY 模型下判定为某一表情的概率;P2(e|x)表示CNN-SIFT 模型下判定为某一表情的概率;P3(e|x)表示CNN-SIFT-AVG 模型下判定为某一表情的概率。由于每个模型都有一个softmax层作为最后一层,因此输出限制在0 到1 之间。
3.3 算法步骤
根据前面的推倒和分析,以本文模型为例,阐述该方法的具体操作步骤。
步骤1将训练样本和测试样本里的人脸表情图像大小统一为48×48,并将所有图像归一化为零均值和单位方差的向量。
步骤2构造CNN 网络模型,输入数据{xi},利用公式ai=f(e)=f(w*xi+h)计算卷积层的特征向量,w表示卷积层的权重矩阵;h为偏置量;f(∙)表示激活函数。再根据式b=max(b1,b2,…,bt),bi为卷积特征向量,t表示有t个卷积核,得到池化层的输出B=(b1′,b2′,…,bt′)。之后分别以C1、C2、C3为dropout概率值p,利用式(3),隐藏层节点个数为y1,y2,…,yi,经过dropout 后,i个节点中有随机p×i个被置0。得到输出的特征值后,多个特征值组成一维特征向量D。
步骤3对数据库中的样本进行SIFT 特征提取,根据式(6),得到每个关键点描述符,大小为128 的向量S=(s1,s2,…,s128)。再采用K-means 算法针对聚类得簇划分C={C1,C2,…,Cj},通过计算每个簇中包含的描述符的数量形成一袋关键点,得到的特征向量的大小为K(S1时K=256,S2时K=512,S3时K=1 024)。
步骤4将步骤3 得到特征向量K与CNN 网络的dropout=C2模型提取的特征向量D,利用式F=K∘D合并为F,其中∘表示以串联形式合并两个特征向量,送入全连接层,将输出映射到(0,1)的区间上,利用式q=f(y)=f(WF+B),q表示输出;W和B表示softmax层的参数。选出概率最大的类别,作为预测的类别。
步骤5利用式(8)~式(10),将步骤1 中得到的3个dropout模型与步骤4 得到的模型结果普通平均。
4 结果与分析
4.1 实验环境及数据预处理
为了验证本文提出方法的有效性,实验采用3个数据集FER-2013、CK+和JAFFE 来评估本文方法的性能。表1 为FER2013、CK+和JAFFE 数据集中每种表情的数量分布。在实验之前,将图像的大小统一为48×48,并将所有图像归一化为零均值和单位方差的向量。
本文以Tensorflow 深度学习框架为实验基础,使用Python3.6 的编程语言,在Windows 10 的操作系统上进行相关实验。硬件平台为:第七代Intel 酷睿i5,Nvidia Geforce GTX 1070Ti GPU,显存8 GB。

Table 1 Expression quantity distribution of FER2013,CK+and JAFFE dataset表1 FER2013、CK+和JAFFE 数据集的表情数量
4.2 数据集介绍与分析
图像大小为48×48 像素,共有7种表情分别用0~6数字进行标注处理,分别为angry、disgust、fear、happy、sad、surprise、neutral。包含训练集和测试集,其中训练集共含有28 709 张图像,测试集含有3 589 张图像。图8展示了FER2013数据库中7种表情的示例图像。

Fig.8 Sample images of 7 expressions in FER2013 database图8 FER2013 数据库中7 种表情的示例图像
CK+数据集包含327个表情。属于小样本数据集(愤怒Angry、轻蔑Contempt、厌恶Disgust、恐惧Fear、快乐Happy、悲伤Sad 和惊讶Surprise)。
为了使实验与其他实验和FER2013 的数据兼容,删除了蔑视的表情。用剩下的6个表情中的309张图片来训练模型。图9 展示了CK+数据库中的样本。
JAFFE 数据集是日本ATR(Advanced Telecommunication Research Institute International)的专门用于表情识别研究的基本表情数据库,该数据库中包含了213 幅日本女性的脸。表情库中共有10个人,每位女性的每种表情有3、4 张,每个人有7 种表情(包含愤怒Angry、中性脸Normal、厌恶Disgust、恐惧Fear、快乐Happy、悲伤Sad 和惊讶Surprise)。图10展示了JAFFE 数据库中的样本。

Fig.9 Sample images of 6 expressions in CK+database图9 CK+数据库中6 种表情的示例图像

Fig.10 Sample image of 7 expressions in JAFFE database图10 JAFFE 数据库中7 种表情的示例图像
4.3 实验结果与分析
对于FER2013 数据集,所有的模型都经过了28 709个样本的训练。其中28 709 张作为训练集,而3 589 张用作测试集。每个网络训练300个epoch,批处理大小为128。CK+数据集中使用所有的309 张图像进行训练,每项实验均按照十折交叉验证的方法重复10 次。为了防止过拟合,所有网络只训练了20个epoch。JAFFE 数据集也采用交叉验证法,将数据集中的表情图片分成5 份,每次用其中的4 份作为训练集,剩余的1 份作为测试集。
在训练过程中均采用随机初始化权重和偏置,初始学习率为0.01,最小学习率设定为0.000 1,记录训练的网络参数和每个epoch 的损失。如果验证损失增加了10%以上,则学习率降低了1/10,并且重新加载之前具有最佳验证损失的网络。将验证损失最低的模型作为最终的训练模型。
在本文中,共提出3个模型CNN-ONLY、CNNSIFT和CNN-SIFT-AVG。每一种模型在每一个数据集下都进行实验。表2、表3 和表4 分别为CNN-ONLY模型、CNN-SIFT 模型和CNN-SIFT-AVG 模型下的不同数据集于不同表情的识别准确率。

Table 2 Facial expression recognition accuracy of CNN-ONLY model in different data sets表2 CNN-ONLY 模型在不同数据集下表情识别准确率 %
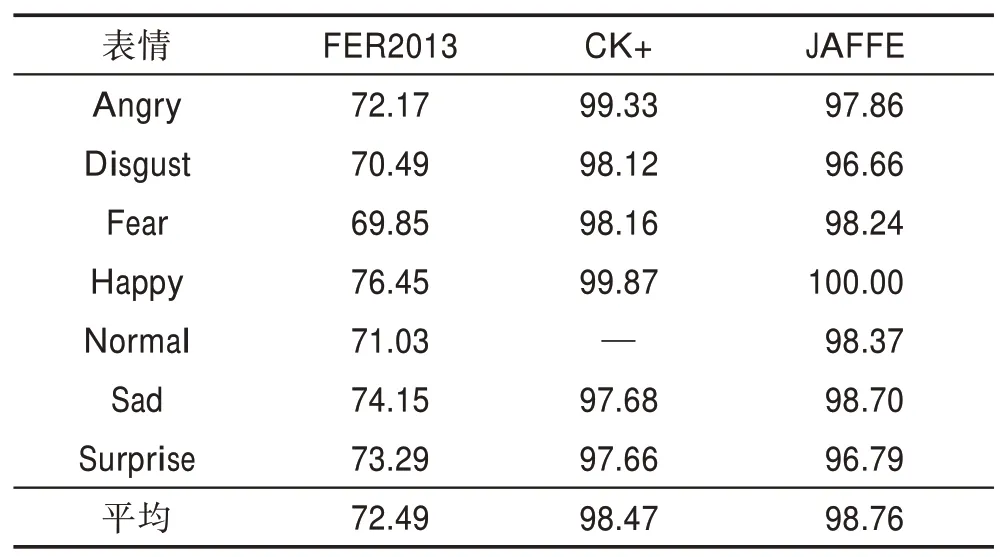
Table 3 Facial expression recognition accuracy of CNN-SIFT model in different data sets表3 CNN-SIFT 模型在不同数据集下表情识别准确率 %
在FER2013 数据库中,本文的3个模型中识别率最高的一直是Happy(高兴),由以上数据集分析可知,Happy(高兴)的特征比其他表情特征更加明显。由实验结果可知,集成模型对个体有显著的改进效果,CNN-SIFT 和CNN-SIFT-AVG 模型均优于CNNONLY 模型,特别是CNN-SIFT-AVG 模型比其他两个模型提高了1%左右的精确率,且两种方法的使用都极大地提高了性能。
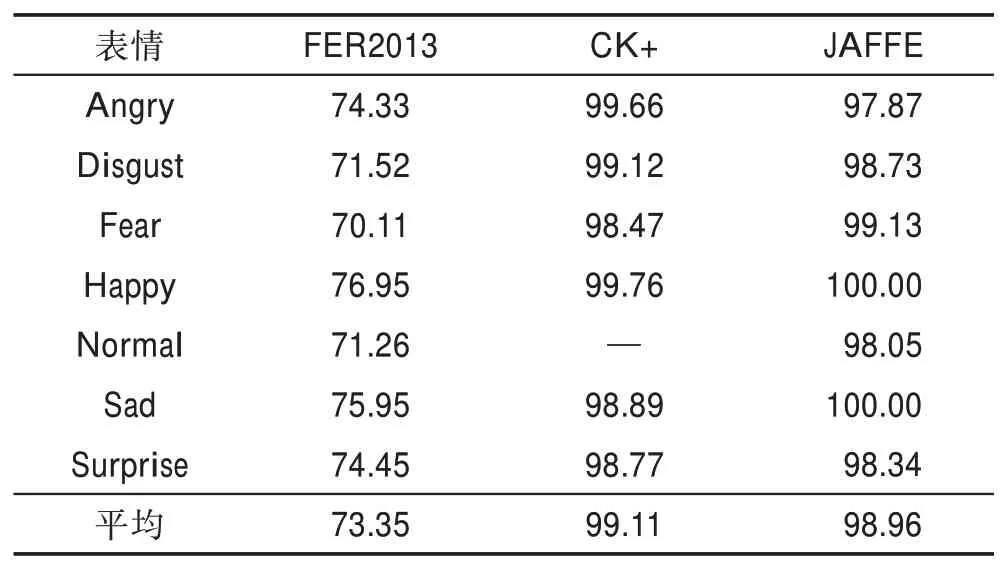
Table 4 Facial expression recognition accuracy of CNN-SIFT-AVG model in different data sets表4 CNN-SIFT-AVG 模型不同数据集下表情识别准确率 %
本文模型与其他先进模型进行了人脸表情识别的准确率对比,如图11 所示。可以看出,本文模型较稳定,虽然某些表情的识别率略低,但整体识别的准确率略高于其他模型。如表5 所示,对比实验的Multi-scale CNNs[20]参数设置:学习率0.001 并且采用了训练自动停止策略,当出现过拟合现象时,训练经过100个epoch 后,自动停止并保存模型。Subnet3[21]参数设置:batch 为100,动量为0.9,网络的权重采用正态分布中的随机数字初始化,学习率设置为0.01,逐渐减少到0.001 为止,epoch 的数量在20 到100 之间。DNNRL[22](deep neural networks with relativity learning)参数设置:初始学习率设定为0.01,最小学习率设定为0.000 1,每个epoch 都有100个batch,从训练集中随机选择训练样本,如果验证损失增加了10%以上,则学习率降低10%。
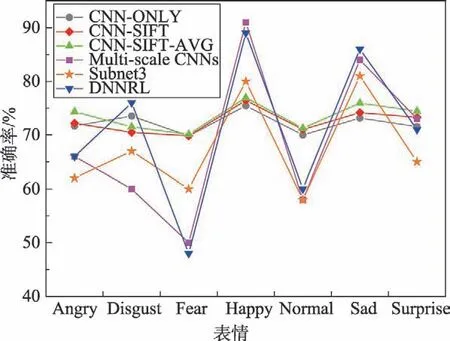
Fig.11 Recognition accuracy of models in FER2013 data set图11 FER2013 数据集下几种模型识别的准确率

Table 5 Comparison of overall accuracy in FER2013 data set with other methods表5 FER2013 数据集上与其他方法整体准确率的对比 %
在CK+数据集的实验中发现,随着表情样本数量的减少,CNN-SIFT 和CNN-SIFT-AVG 的性能比CNN-ONLY 模型的准确率和性能有所提高,且CNNSIFT-AVG 模型的性能相对更优。图12 为CK+数据集在CNN-SIFT-AVG 模型上实验的混淆矩阵。由图可看出,Angry、Fear、Sad 会被轻微混淆,在识别中会导致错误,相比其他表情,Happy 表情比其他表情更容易识别。但随着数据集的减少,SIFT 的优势体现出明显的效果,相比FER2013 数据库,在CK+数据库中,识别的准确率大幅度提高了。图13 为CK+数据集下不同模型识别的准确率比较。表6 为CK+数据集上与其他方法整体准确率的对比。

Fig.12 Confusion matrix of CK+data set on CNN-SIFT-AVG model图12 CK+数据集在CNN-SIFT-AVG模型上的混淆矩阵
对比实验Xu 等[23]的参数设置:学习率0.000 01,迭代次数200,权值衰减0.000 5,batch 为20。传统卷积神经网络的参数设置:学习率0.001,最大迭代次数1 001,batch 为128。Zhang 等[24]的参数设置:学习率0.001,迭代次数100,batch 为30。由实验结果可知,本文的模型均优于另外几种模型,不论是每种表情的识别准确率还是整体的识别率,本文识别的准确率相比其他方法至少提高3个百分点,且CNN-SIFTAVG 模型相对更优。
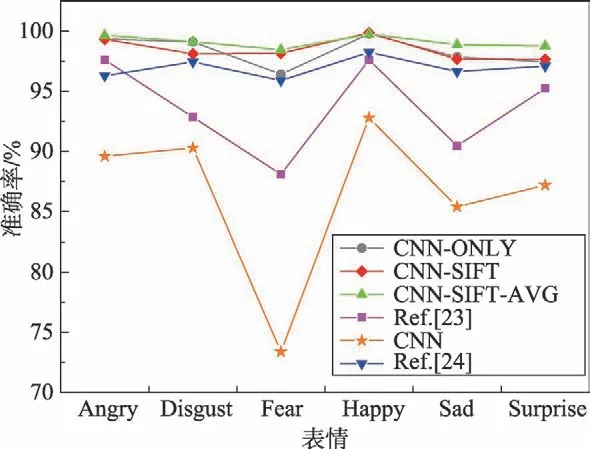
Fig.13 Recognition accuracy of models in CK+data set图13 CK+数据集下几种模型识别的准确率
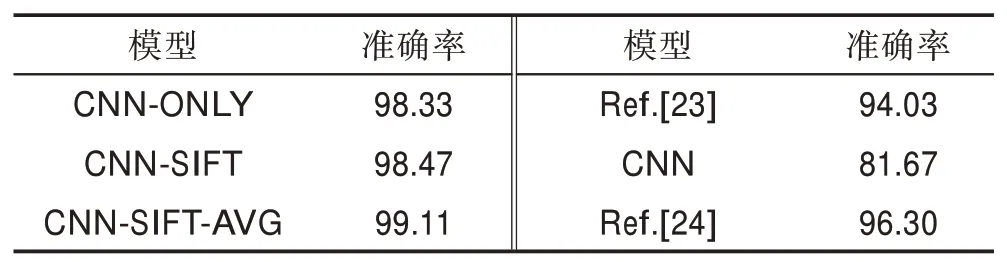
Table 6 Comparison of overall accuracy with other methods in CK+data set表6 CK+数据集上与其他方法整体准确率对比 %
在JAFFE 数据集上,本文模型达到了较好的准确率,其中Happy 与Sad 两种表情识别达到了无差错的结果。图14 为JAFFE 数据集在CNN-SIFT-AVG 模型上的混淆矩阵。其中每一行都表示真实的类别,每一列对应的则是预测的类别的概率。图15 为JAFFE 数据集下不同模型识别的准确率比较。表7为JAFFE 数据集上与其他方法整体准确率的对比。其中对比实验中Zhang等[24]的参数设置:学习率0.001,迭代次数100,batch 为30。Yao 等[25]的参数设置:最大迭代次数为2 000,识别率阈值为95%。Lajevardi等[26]则是结合不同特征如Gabor、LBP(local binary patterns)和HLAC(higher-order local auto correlation)的表情识别。
结果表明,CNN-SIFT 模型和CNN-SIFT-AVG 模型均优于现有模型。特别是CNN-SIFT-AVG 模型在JAFFE 数据库中的识别率达到了98.96%的准确率,与其他方法相比,准确率提高了2 到6个百分点。
4.4 不同模型的差异分析

Fig.14 Confusion matrix of JAFFE data set on CNN-SIFT-AVG model图14 JAFFE 数据集在CNN-SIFT-AVG模型上的混淆矩阵
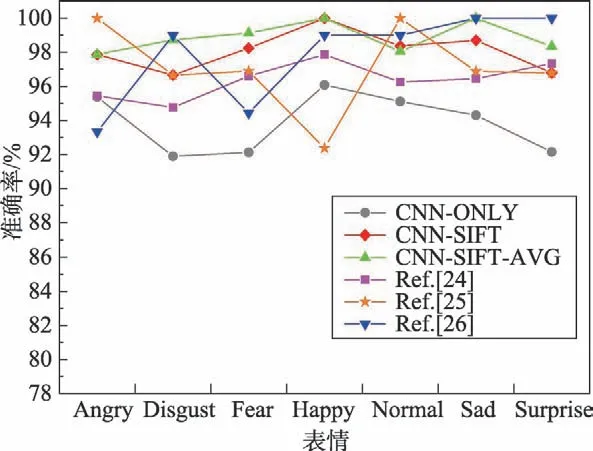
Fig.15 Comparison of recognition accuracy of models in JAFFE dataset图15 JAFFE 数据集下几种模型识别准确率比较图
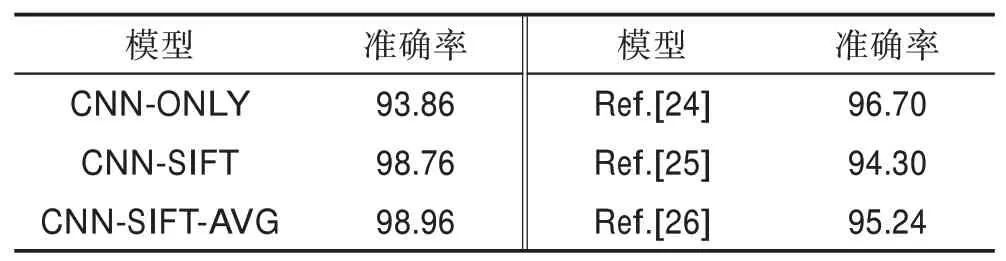
Table 7 Comparison of overall accuracy with other methods in JAFFE data set表7 JAFFE 数据集上不同方法整体准确率对比 %
由以上实验结果可以看出,3个模型的识别率略有不同。对于模型,由式(8)可知,仅仅将C1、C2、C3不同dropout值的卷积神经网络模型进行简单平均融合,对于表情的特征提取可能存在一定局限,当训练数据减少时,可能会产生过拟合现象,导致训练的模型不是特别理想。对于CNN-SIFT 模型,由式(9)可知,将dropout 为C2的网络与S1、S2、S3模型得到的结果进行平均,进而得到结果。根据实验结果可知,不仅在大数据集中的识别率相对较高,当数据集减小时,识别率没有因为训练数据的减少而降低,反而有了更好的效果。这是因为加入了SIFT 提取特征,提高了小数据的性能,将SIFT 特征与卷积特征结合,更增加了输入特征的多样性。对于CNN-SIFT-AVG模型,由式(10)可知,是将6个模型采用普通平均模型融合的方法。由于个体学习器准确性越高,多样性越大,则融合效果越好。因此,CNN-SIFT-AVG 模型对于大数据集和小数据集的识别率相比其他方法更优,数据集较大时,训练数据足够,CNN 网络模型更加准确,加上SIFT 特征,识别率更高;当数据集较小时,SIFT 能够很好地在小数据集上提取特征,将CNN 特征与SIFT 特征融合进行训练分类,弥补了CNN 网络由于训练数据不够而过拟合的问题,因此在提高了小样本性能的同时,获得了较高的识别率。
5 结束语
本文针对提高小样本数据集下表情识别率等问题,提出了一种深度学习下融合不同模型的小样本表情识别方法。文中已经展示了SIFT 特征和卷积神经网络是如何协同工作的,这种混合方法综合了这两种方法的优点。一方面,充分利用了SIFT 不需要大量数据提取特征,提高小数据的性能的优势;另一方面,不同模型的融合,不仅在大数据中表情的识别率有一定提高,同时也解决了CNN 需要大量数据训练的问题,提高了小样本下表情识别的准确率。由实验结果可知,本文的CNN-SIFT-AVG 模型有明显优势,在很大程度上发挥了小样本中SIFT 的作用,数据越小,改善效果越明显。
