基于R语言的学生成绩分析
2020-03-18杨超
杨 超
(辽宁民族师范高等专科学校 民族文化与职业教育系,辽宁 沈阳 110032)
0 引言
学生成绩作为检验教师教学效果的产物,直接反映学生对知识的掌握情况及教师的教学水平.近些年,有关教学的探索更多关注于新的教学手段,针对教学效果的分析,尤其是有关分析方法的研究较少.随着人工智能和大数据时代的到来,为教师利用数据统计分析手段,从大量的学生成绩中提取重要数据,发现成绩中隐藏的问题,提高学生成绩,提供了新的思路.本文中尝试引入R语言对学生成绩进行统计分析[1-3],为教学人员探索新的统计方法提供参考.
1 R语言特点
数据分析是指采用合适方法对从海量数据中收集的大量数据进行分析、整理、归纳,抽取有价值的信息的过程.R语言作为一种强大的编程语言,不仅可提供大量多样的数据统计分析方式,还可生成图例,其主要特点有:
(1)开源免费的软件可从官网下载,安装简单快捷,而且其强大的R语言包均可根据需要从网上下载,支持多操作系统环境;
(2)具有强大可自定义样式的绘图功能,可利用函数将统计分析的计算数据生成想要的图,并根据修改函数中的参数,自定义图样式;
(3)操作流程简单,无需编写大量代码,用户只要了解所需函数的参数意义,即可生成对应图例.
2 R语言数据处理
数据源是R语言进行统计分析的核心资源.考虑到大学课程成绩存在一定主观性,相比之下小学期末考试更严格、更真实,成绩趋于客观,因此本研究选择沈阳市某小学四年级期末考试成绩作为数据源进行统计分析.
2.1 数据收集
根据教学人员的需要,从众多列成绩中选取主要数据信息,包括序号(num)、姓名(name)、班级(class)、数学(math)、语文(chn)、英语(eng),将收集的数据存为.xls文件或.csv文件.收集数据时,出现的缺失值可删除或按空缺值等方式处理.
2.2 数据读入
R语言支持.xls、.csv和.txt等多种文件类型导入.导入文件前需要加载对应的R语言包,编写代码时需将导入文件赋值给变量,导入的变量类型以数据框形式存在.本文以导入.xls文件为例,利用R语言read_excel()函数实现导入代码如下:
library(read_excel)
scores<- read_excel(scoresdata.xlsx)
导入后查看数据,见图1.
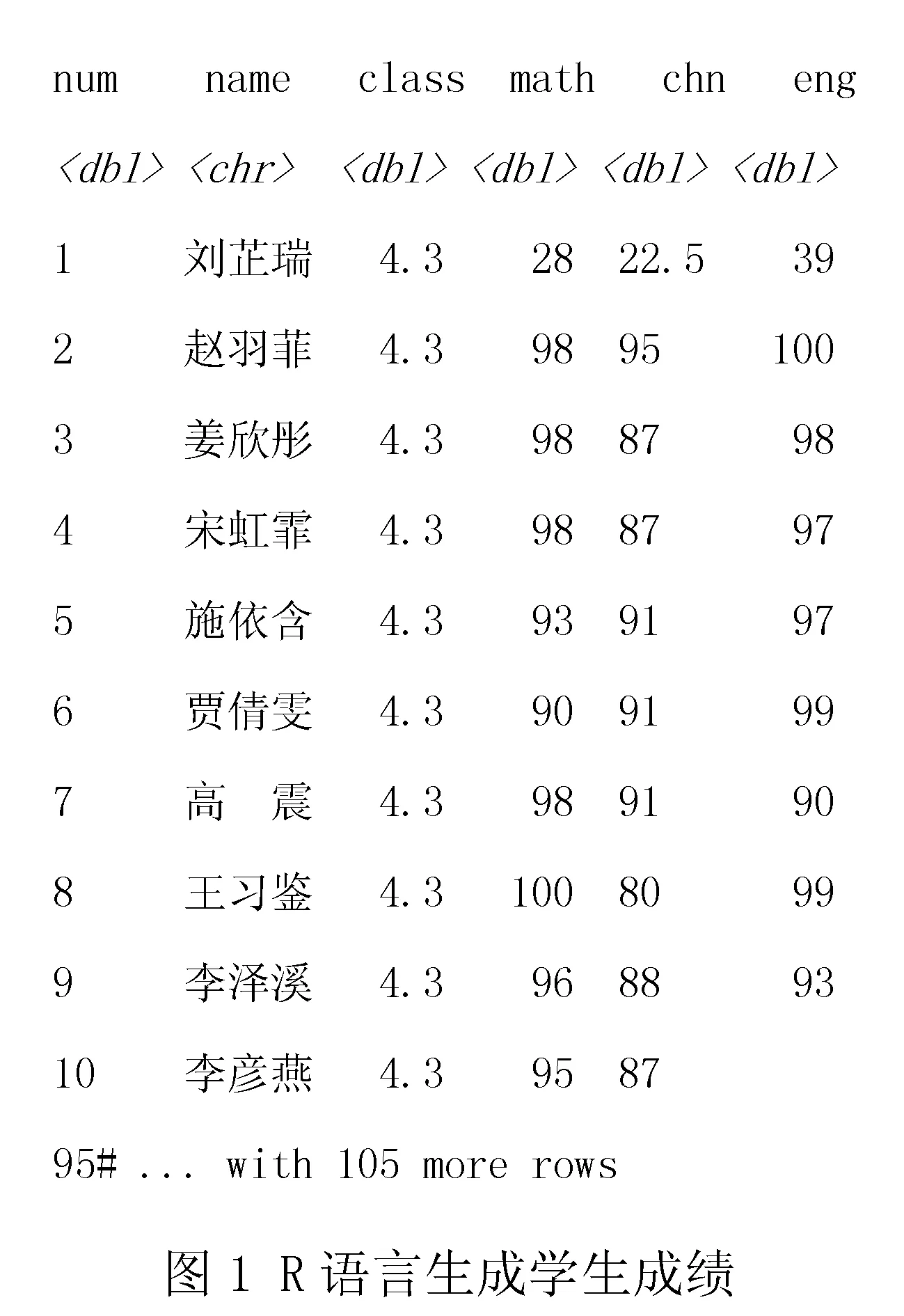
数据共105行,查看变量内容时R语言仅显示10行,隐藏95行.每列除显示导入数据时填写的列名外,还显示属性类型,其中name为字符型,其余均为数据框.
2.3 数据提取
读入数据后,需对有用数据进行提取运算.例如,在统计分析成绩时,姓名、序号、班级等属性不应参加统计分析,但无这些属性就无法进行归类统计分析,在众多数据中提取所要数据,可应用R语言中c()函数将所需数据连接在一起,通过如下代码提取数据:
> scores.data <- scores[c(4:6)]
> scores.data
“scores[c(4:6)]”表示提取scores变量中4~6列的数据赋值给变量scores.data.
3 R语言成绩分析与图形绘制
学生成绩是反映教学成果的客观数据.目前,大多数学校采取Excel录入、汇总、计算的方式管理与分析学生成绩,虽能计算出需要的最终数据,但是缺乏对成绩的客观分析与直观反映.针对这一问题,本文提出了基于R语言的统计分析方法以提高教学效果[4-6].
3.1 各科成绩描述性分析
3.1.1 统计成绩信息
传统数据计算一般通过Excel表格分列对各科进行求和、求平均值、求最大值和最小值的分类计算,工作略显繁琐.这里以沈阳某小学四年级成绩为例,将43名学生成绩导入R语言环境中,导入的数据变量以数据框的形式存在.R语言可通过summary()函数完成各科成绩的初步计算,实现代码如下:
summary(scores[c(4:6)])
生成的计算数据见图2.
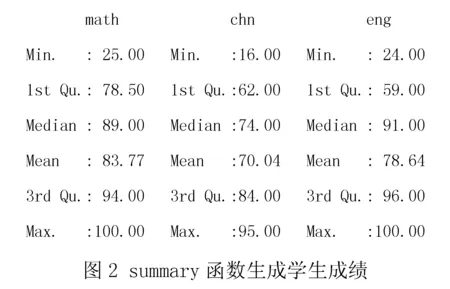
通过生成数据可直观看到,在整个四年级数学、语文和英语三科考试成绩中,除最大值、最小值和平均值外,还计算出科目成绩的中间值(Median)、1/4位数(1st Qu.)和3/4位数(3st Qu.),为分析、了解学生整体情况提供了便捷的数据计算服务,提高了教学决策的准确性.
3.1.2 绘制成绩箱形图
为更加直观地向决策者提供数据依据,R语言boxplot()函数可根据导入的成绩数据生成箱形图,即根据数据的分布情况生成统计图.上述通过summary()函数计算出各科成绩的重要属性值,生成的箱形图如图3所示,实现运行代码如下:
boxplot(math~ class, data=scores)
boxplot(chn ~ class, data=scores)
boxplot(eng~ class, data=scores)
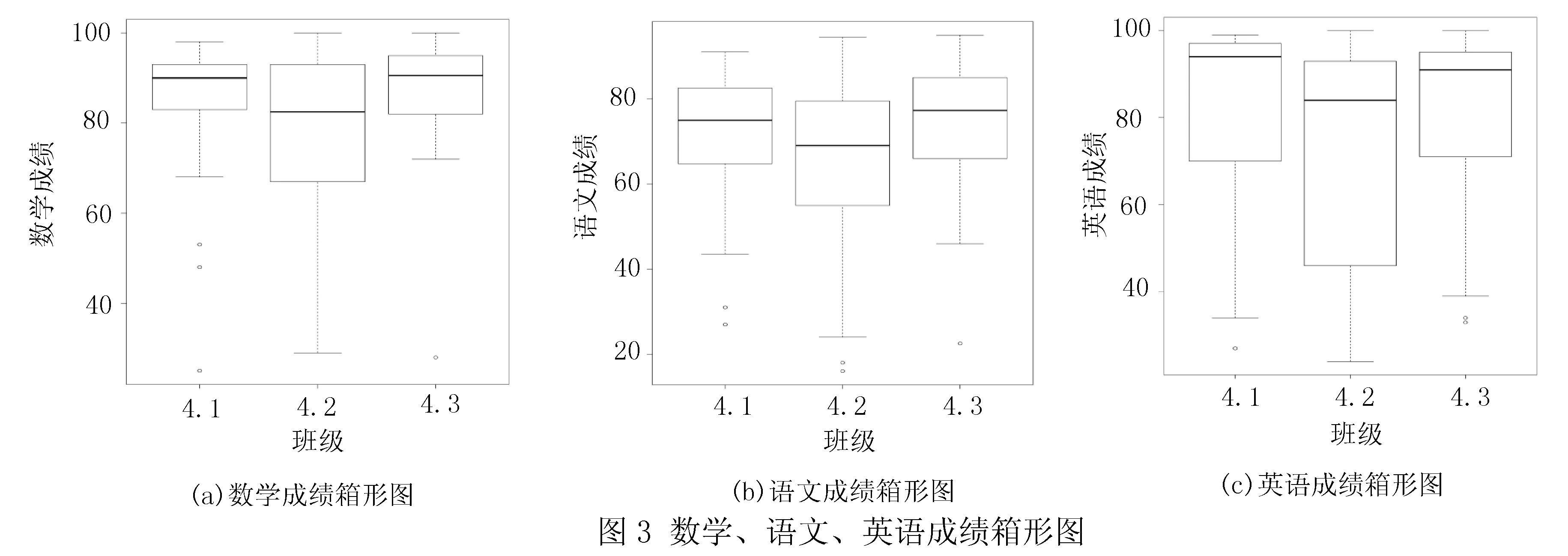
箱形图将计算得到的描述性统计量进行更直观地展示.图3中分别显示各班级数学、语文、英语成绩与班级的信息:长方形外部的上下两条横线分别表示该班级的最高分和最低分,长方形的上下边框分别表示该班级成绩的1/4位数(1st Qu.)和3/4位数(3st Qu.),长方形内部黑横线表示该班级成绩的中间数,图形中的空心白圆点表示异常数据.除箱形图规定的线形和图形含义外,还可从图形中看到隐藏的信息,例如长方形的面积大小决定该班级本科目成绩是否在某成绩段集中,如果面积过大表示成绩涉及范围较大.
3.1.3 绘制成绩直方图
R语言的强大不仅体现在便捷的数据计算,还体现在可依据频数生成可视的直方图[7].根据导入的数学、语文和英语成绩,利用R语言的hist()函数、lines()函数和rug()函数生成整体成绩直方图,如图4所示,运行代码如下:
hist(math, freq=FALSE)
lines(density(math), col='blue')
rug(jitter(math))

通过成绩直方图可直观看出,横坐标为成绩段,纵坐标为密度,各科成绩图形及密度曲线由分数段人数决定.数学成绩除个别学生,大部分均已及格,并且在及格人数中很多学生的成绩集中在85分以上,90分以上偏多;语文成绩虽呈正态分布趋势,但是存在一些成绩不及格的学生,大部分学生在65~90分之间,80分以上偏多;英语成绩分布呈现两极化,成绩不及格和90分以上的均偏多,60~80分之间学生较少.
3.2 成绩相关性分析
成绩是检验教学成果的重要指标.有效利用技术手段从大量的成绩中发现科目之间的关联,挖掘隐藏信息,是提升成绩、提高教学效果的重要方式.利用R语言cor()函数,可从导入的数据中发现科目之间的相关性,为决策者提供分析依据.运行代码如下:
cor(scores[,subjects])
生成的相关性数据见图5.
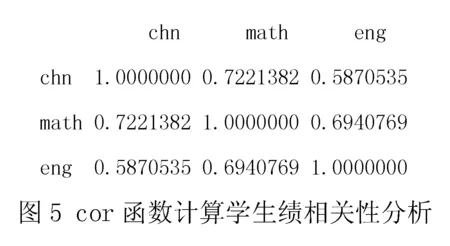
通常认为,数学成绩好的小学生语文和英语的成绩都不会很差.通过R语言各科成绩的相关性分析看出,数学与语文、数学与英语的相关系数均超过了0.6,根据统计学的规定,相关系数区域0.6~0.8属于有很强的相关性,说明在该年级中数学学得好的学生,其数学成绩与语文成绩、英语成绩存在一定的相关性.通过R语言生成的成绩相关性如图6所示,运行代码如下:
pairs(scores[,subjects])
3.3 成绩差异分析
利用starts()函数可根据学生的成绩生成星图,教学人员通过星图可直观了解学生是否偏科、是否优秀.本文中生成的星图如图7所示,运行代码如下:
stars(scores)
星图一般表示多个相互独立的变量个体,每个连接角与中心点的轴线越长,数值就越大,生成的星图就越大,各科成绩分别对着数据的维度.图7中,第一排第二个学生、第二排第二个学生,以及第八排第二个到第七个学生,这些学生成绩相对优异;第三排第五个和最后一排第一个学生存在偏科问题.

4 结语
R语言是对数据进行统计分析的技术手段,从文中小学四年级成绩统计分析结果来看,软件的应用既可满足教学人员对数据的计算需求,也可生成直观视图为教学人员提供参考依据,同时所生成的视图还显示了数据中的隐藏信息.从应用与实际需求的角度来看,采用R语言统计分析学生成绩的应用策略可行,对教学未来发展方向起到一定指导作用.
