拉曼光谱结合UVE-SVR算法预测加热食用油反式脂肪酸的含量
2020-03-17于慧春付晓雅刘云宏白喜婷
于慧春 付晓雅 殷 勇 刘云宏 白喜婷
(河南科技大学食品与生物工程学院,河南 洛阳 471003)
反式脂肪酸(trans fatty acids,TFAs)是顺式脂肪酸在一定条件下发生异构化所形成的至少含有一个反式构型双键的不饱和脂肪酸的总称,被称为“餐桌上的定时炸弹”[1-2],存在于高温煎炸后的食用植物油、氢化产品、速溶产品、反刍动物的肉脂肪组织及乳脂中[3]。TFAs是食用油高温加热过程中不可忽视的产物,其对健康的危害可能比氢化产品中的TFAs 更大[4]。因此,开展食用油TFAs的检测研究,对食品安全及制定油品的行业标准有着积极的意义。
目前,食用油中TFAs的常规检测方法主要包括气相色谱法[5]、液相色谱[6]和红外吸收光谱法[7]等,这些分析方法检测精度较高,但预处理过程复杂,耗时较长[8],且预处理过程直接影响最终检测结果,难以满足实际生产及市场监管的需求[9],而拉曼光谱技术(raman spectrocscopy technology,RAMAN)采用非弹性散射对样品进行分析,无需前处理,简单方便。近年来,RAMAN 在农产品、食品品质检测及真伪鉴定方面引起越来越多的关注。在食用油检测方面,主要是通过提取拉曼光谱的特征峰,建立食用油中与其品质相关的某些组分的预测模型,如饱和脂肪酸、油酸、亚油酸[10]及其他单不饱和脂肪酸(monounsaturated fatty acids,MUFA)和多不饱和脂肪酸(polyunsaturated fatty acids,PUFA)[11-12]等,通过对组分的预测,从而实现对食用油品质的快速检测及鉴别。此外,运用激光拉曼检测时,由于样品的性质通常是由各组成成分联合影响所决定,所以只对个别峰进行分析不足以体现样品的性质,因此,需要综合考虑一些峰的峰面积、形状或移频等特征[13],但当被测样品光谱数据量较大,峰值较多时,直接对所有光谱的峰值特征进行分析建模,会增加模型的复杂性,影响模型的稳定性[14]。所以,在建立模型时需要对拉曼光谱的有效信息进行准确的提取,而关于这方面的研究报道较少。目前,有关激光拉曼技术对食用油中TFAS含量的检测研究报道较少,尤其是针对长时间加热后食用油中TFAS含量变化方面的检测研究更少。因此,本研究尝试采用无信息变量消除法(uninformative variable elimination,UVE)对拉曼光谱信息进行变量筛选,剔除对模型没有贡献的光谱,然后使用Fisher 判别分析(fisher discriminant analysis,FDA)方法对其进行定性判别分析,随后运用支持向量回归机(support vector regression,SVR)、BP神经网络(back propagation neural network,BPNN)、偏最小二乘回归(partial least-squares regression analysis,PLSR)方法分别建立基于筛选变量和全谱数据的不同食用油和不同加热时间的TFAS含量的预测模型,并对结果进行对比分析,以期为长时间使用的煎炸油中TFAS含量的定性及定量研究提供借鉴。
1 材料与方法
1.1 食用油样品制备
福临门菜籽油、道道全大豆油和福临门玉米油均购于大张超市,规格900 mL 瓶装。检测时取30 mL 油样,倒入陶瓷坩埚中,在电炉上加热,用水银温度计测量其温度。当温度达到190℃时,开始计时并调节电路电压,使温度波动不超过±5℃。分别在加热时间为0、30、60、90、120、150 min时,取油样5 mL 并冷却至室温,于-20℃条件下保存备用。
1.2 食用油中反式脂肪酸含量的测定
参考GB 5009.257-2016[15]的测定方法。
1.3 拉曼光谱采集
采用XploRA ONE 共焦显微拉曼光谱仪(法国),激光光源波长785 nm,功率375 mW,光谱采集范围200~3 500 cm-1,激光功率50%,扫描点数36个,于室温(20~25℃)条件下测定样品的拉曼光谱图。6个加热时间段的样品,每个样品设3 次重复。为了尽可能全面的获取样品信息,每个样品分别均匀采集36个点,即每个样品得到36 条拉曼光谱,进而使用激光拉曼仪器自带的LabSpec 6 数据处理软件对光谱基线进行多项式拟合,以去除荧光背景。
1.4 数据处理
1.4.1 无信息变量消除 UVE是基于分析PLSR 系数的算法,能够有效去除无关波长变量。在PLSR 模型中,拉曼光谱矩阵变量X和TFAS含量矩阵Y存在如下关系[16]:Y=Xb+e,其中,b为回归系数向量,e为误差向量。将与拉曼光谱矩阵变量数目相同的随机变量矩阵加入到光谱矩阵中,通过PLSR 交叉验证剔除无关变量,得到回归系数矩阵,利用回归系数向量的平均值与其对应的标准差相除,进而确定筛选变量阈值,大于阈值的筛选变量即为优选特征变量[17]。
1.4.2 Fisher 判别分析 为了说明筛选变量能够有效提高拉曼光谱对加热食用油的鉴别能力,选用FDA方法作为模式判别工具[18],并用FDA对不同加热时间的3种食用油样品进行判别分析,通过对其训练集及其预测集鉴别正确率的分析与对比,来表明变量筛选的必要性。
1.4.3 支持向量机回归 SVR是一种较新的多元统计分析方法,最初用于解决模式识别中的分类问题[19],随着VAPNIK对ε 不敏感损失函数的引入,支持向量机已被推广到非线性系统的回归估计,通过核函数的选择进一步提高其学习性能[20]。分别以筛选后的3种食用油的拉曼光谱作为输入,以样品中TFAS含量为输出,建立SVR 预测模型,对样品中TFAS含量进行预测。
1.4.4 偏最小二乘回归 PLSR分析在建模过程中集中了主成分分析、典型相关分析和线性回归分析的特点,预测能力强且模型简单[21]。采用PLSR方法,对样品的拉曼光谱矩阵X和TFAS含量矩阵Y同时进行分解,有效消除多个变量之间的共线性,从而获得最佳的校正模型[22]。
1.4.5 BP 神经网络 BPNN 模型结构包括输入层、隐层和输出层,是对人脑活动的抽象、简化和模拟,能学习和存贮输入信号与输出信号之间的非线性映射关系[23]。BPNN 输入层的神经元数等于每种食用油筛选出的拉曼光谱数,输出层的神经元数为1,而隐层需采用试凑法进行多次尝试,建立基于BPNN的TFAS含量预测模型。
2 结果与分析
2.1 食用油加热样品的TFAS含量
在进行TFAS含量检测时,以反式亚油酸含量、反式亚麻酸含量和反式油酸含量的总和表示总TFAS含量。由表1可知,随着加热时间的延长,菜籽油、大豆油、玉米油中TFAS含量均逐渐增加。食用油中不同的TFAs的形成和含量的改变与其脂肪酸组成有关[24]。顺式脂肪酸含量较多的食用油经过加热后对
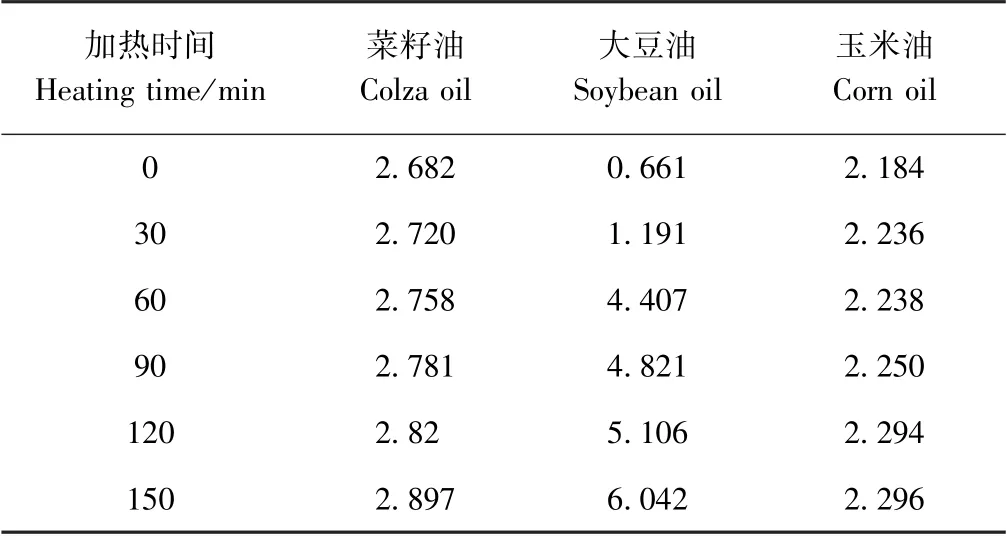
表1 3种食用油中的反式脂肪酸含量Table1 TFAs content in three vegetable oils/(g·100g-1)
应的TFAs含量也会变多[25]。而大豆油中含有丰富的油酸、亚油酸与少量的亚麻酸,其中亚油酸的含量超过总脂肪含量的50%,且在加热过程中生成TFAs的难易程度(从易到难)依次为反式亚麻酸>反式亚油酸>反式油酸[26],因此大豆油中TFAS含量增加明显。
2.2 食用油加热样品的拉曼光谱
由图1可知,食用油拉曼光谱存在较强的荧光背景,为了去除荧光背景的干扰,使用激光拉曼仪器自带的软件处理系统,采用迭代多项式拟合基线矫正方法对光谱基线进行拟合、去除荧光背景,再使用MATLAB(R2014a)软件进行标准正态变量变换(standard normal variable,SNV)。由图2可知,SNV 有效消除了背景信息的干扰,增强了光谱与TFAs 成分相关的光谱信息。
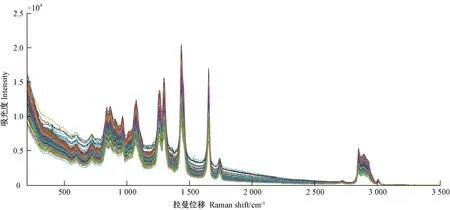
图1 激光拉曼采集的648 条原始图谱Fig.1 Laser raman acquisition of 648 original spectra

图2 预处理后的648 条拉曼图谱Fig.2 648 raman spectra after pretreatment
表2为图2中食用油各谱峰所代表组分的官能团信息。其中,969 cm-1与trans(C=C)的弯曲振动相关[27],870 cm-1和1 080 cm-1是-CH2长链骨架的伸缩振动峰,1 302 cm-1是-CH2的卷曲振动,1 438 cm-1代表-CH2的剪式振动,1 263 cm-1和1 656 cm-1分别是不饱和脂肪酸cis(=C-H)和cis(C=C)的基团振动峰,1 745 cm-1谱峰是酯键羰基的伸缩振动峰[28]。上述几个特征峰几乎是所有食用油拉曼谱图的共同特征,不同油脂的拉曼谱图只是在1 656、1 263、969 cm-1处的谱峰相对强度有细微变化。由于TFAs中含有大量C-C 化学键,因此,在拉曼光谱中有较强的吸收信息。此外,反式双键的存在,使得TFAs 在分子结构上与饱和脂肪酸、顺势不饱和脂肪酸等存在不同[29]。分子结构的变化会在吸收光谱中表现出来,相关研究表明,油脂中的TFAs和顺式脂肪酸的拉曼位移不同[30]。

表2 拉曼位移信息Table2 Raman shift information
2.3 UVE 筛选变量分析结果
为优化预测模型,增加预测模型的稳定性,采用UVE方法对预处理后的全谱数据进行变量筛选,将无信息的变量去除,针对菜籽油、大豆油和玉米油分别从全部波长中筛选出75、153和23个波长变量作为特征变量进行定性和定量分析。
图3-A为菜籽油筛选出的75个变量(特征波长)。研究表明,菜籽油中TFAs 主要由反式亚麻酸与少量的反式亚油酸组成,在加热过程中二者的含量均明显增加,所以变量主要集中在969、1 263、1 302、1 656 cm-1附近。图3-B为大豆油筛选出的153个变量。新鲜的大豆油中不含有反式油酸,仅含有少量的反式亚油酸与反式亚麻酸,在加热过程中TFAs 主要由反式亚油酸与反式亚麻酸组成,随着加热时间的延长也会出现少量的反式油酸,所以变量主要集中在969、1 263、1 302、1 438、1 656 cm-1附近。图3-C为玉米油所筛选的23个变量。玉米油中TFAs 主要为反式油酸、反式亚油酸和反式亚麻酸3种,随着加热时间的延长,反式亚油酸与反式亚麻酸的含量明显增加,所以变量主要集中在969、1 263、1 302、1 656 cm-1附近。此外,969 cm-1为trans RHC=CHR 弯曲振动的特征峰,可以作为反式脂肪的特征峰;1 263 cm-1为Cis c-HR 伸缩振动的特征峰;1 302 cm-1为-CH2扭曲振动的特征峰;1 438 cm-1为-CH2剪式弯曲振动的特征峰;1 656 cm-1为Cis RHC=CHR 伸缩振动的特征峰。
2.4 UVE-FDA 定性鉴别模型建立
将通过UVA 筛选出的变量,分别作为FDA的输入变量,进行分析,其中,每个样品的36 条拉曼光谱中24 条作为训练集,12 条作为测试集,结果见图4-A-2、-B-2、-C-2。为对比分析,将全波段(200~3 500 cm-1)激光拉曼光谱作为FDA的输入变量,进行分析,结果见图4-A-1、-B-1、-C-1。通过对比可知,不同加热时间(0、30、60、90、120、150 min)下,采用全谱信息,菜籽油、大豆油、玉米油3种油不同加热时间的样品重叠严重,而经UVA方法变量筛选后,3种食用油的样品均有较好的分类效果,同类间聚集度较高,表明分类效果有所提高。由表3可知,不同加热时间下,经变量筛选后,大豆油、玉米油和菜籽油的FDA 判别平均正确率均在90%以上,明显高于基于全谱的FDA 判别平均正确率。
2.5 定量预测模型分析结果
分别应用SVR、BPNN和PLSR方法建立基于全部变量及特征变量对菜籽油样品中TFAs含量的预测模型,其最优模型见图5。对于BPNN,其训练函数为trainscg 函数,隐层神经元函数为logsig 函数,输出层神经元函数为tansig 函数,隐层神经元的个数为10时,训练结果较好。由表4可知,基于全部变量信息菜籽油中TFAs的预测模型,训练集R2与测试集R2相差较大,存在过拟合现象。使用UVE 筛选的75个变量建立SVR、BPNN与PLSR 预测模型,测试集R2较全部变量模型均有不同程度的提高。其中,UVE-SVR 预测模型的测试集R2相对最高,且RMSEC和RMSEP 更低,其预测模型性能优于其他2个预测模型。
同样建立大豆油不同加热时间后TFAs含量的预测模型,最优预测模型见图6。由表5可知,采用全部变量建模时,3种预测模型均达到了较好的预测效果,其中SVR与PLSR 预测结果均达到90%以上,SVR 模型和PLSR 模型的预测相关系数相近,但前者测试集的RMSEP (0.004 8) 小于后者测试集的RMSEP(0.008 1),说明SVR 预测精度高于PLSR 模型。采用UVE 筛选过后的153个变量建模时,SVR 模型测试集的R2(0.954 8)高于PLSR 模型的R2(0.920 2)和BPNN 模型的R2(0.906 0),且SVR的RMSEP(0.001 9)远低于其他2种模型。表明基于特征变量的SVR模型预测效果优于PLSR 模型与BPNN 模型。
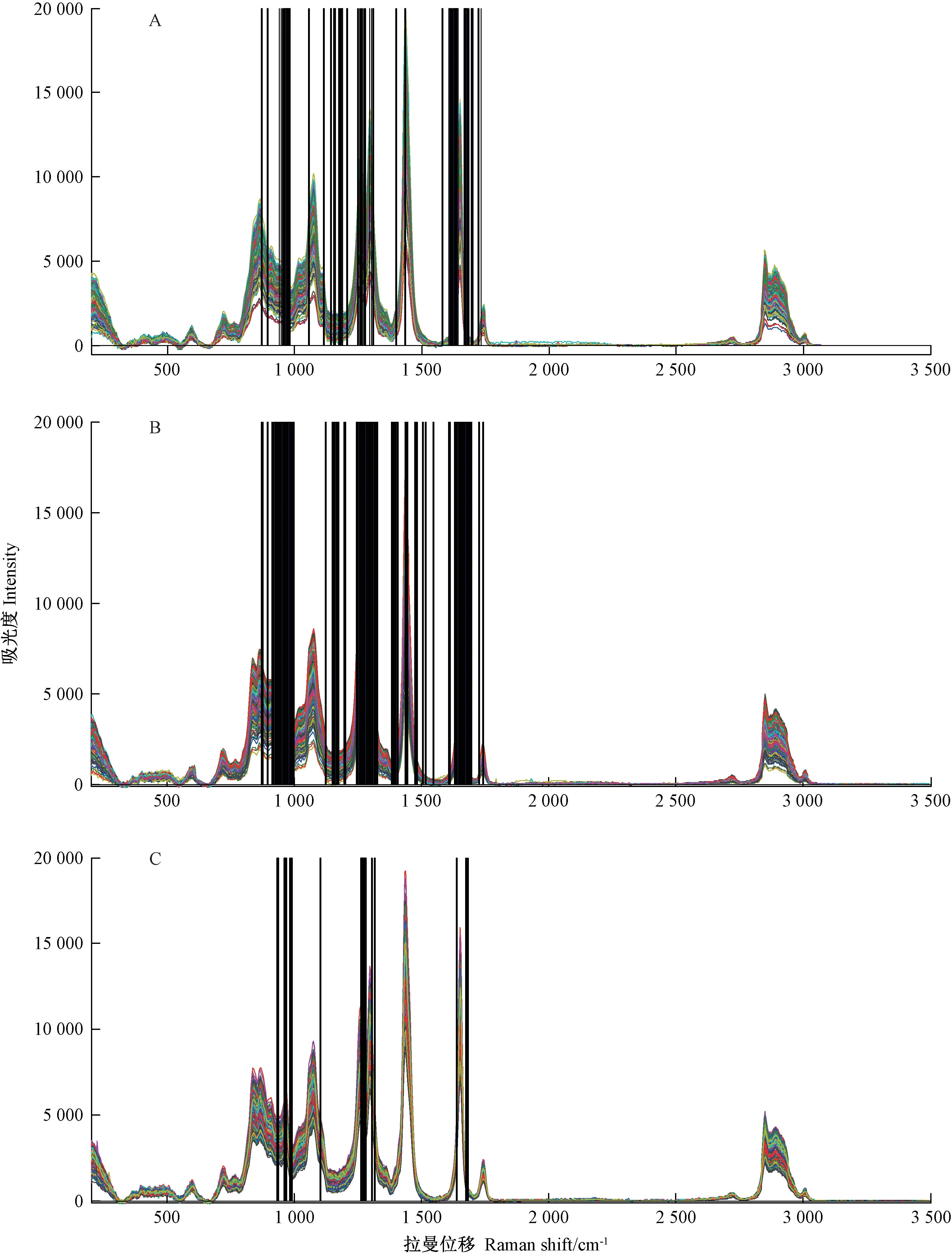
图3 食用油筛选出的特征波长Fig.3 Characteristic wavelength of edible oil screening
玉米油中反式脂肪酸最优建模结果见图7。结合表6可知,在全部特征变量下,训练集的R2较高,但测试集的R2较低,说明试验建立的模型存在过拟合现象,而3种预测模型的RMSEP 均较大,说明模型的稳定性有待进一步提高。采用筛选的23个特征变量建模时,SVR与BPNN 预测模型的R2相近,但SVR 模型测试集的RMSEP(0.014 5)小于BPNN 模型测试集的RMSEP(0.080 2),其预测精度高于BPNN,说明基于特征变量的SVR 模型预测效果优于PLSR 模型与BPNN 模型。

图4 食用油全部变量筛选变量后FDA 预测集Fig.4 Prediction set of FDA after all variables and selected variables of edible oil

表3 3种食用油FDA 判别正确率Table3 Three edible oil FDA classification results /%

表4 菜籽油预测模型结果Table4 Results of rapeseed oil prediction model

表5 大豆油预测模型结果Table5 Results of soybean oil prediction model

图6 大豆油UVE-SVR 训练集与预测集结果Fig.6 Soybean oil UVE-SVR training set and prediction set results
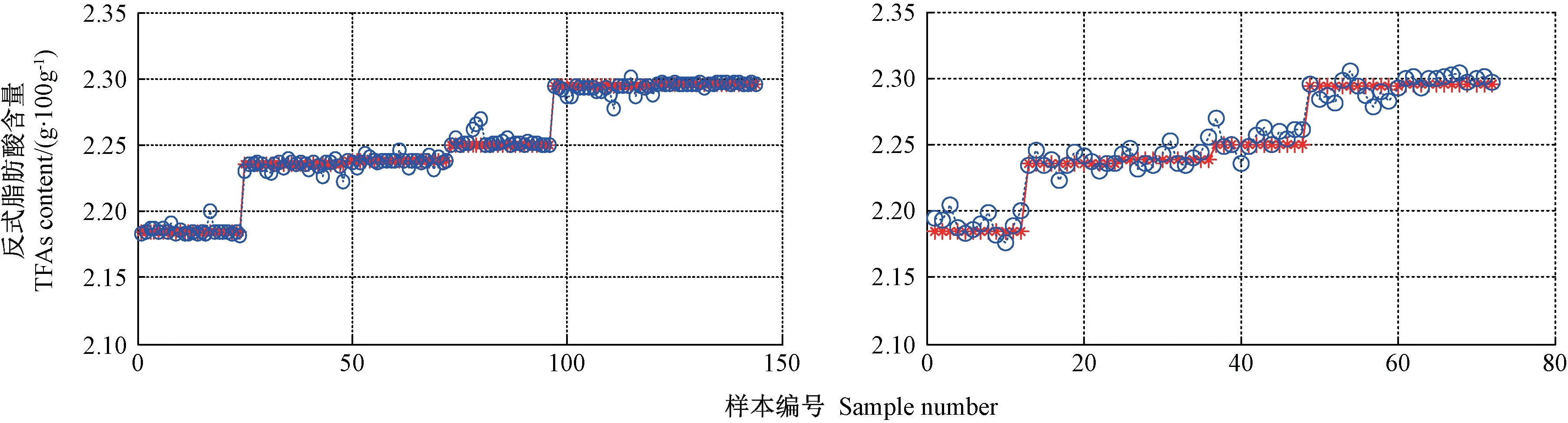
图7 玉米油UVE-SVR 训练集与预测集结果Fig.7 Corn oil UVE-SVR training set and prediction set results

表6 玉米油的预测模型结果Table6 Results of corn oil prediction model
3 讨论
本研究将激光拉曼技术应用于不同加热时间下食用油TFAs含量的检测,为食用油TFAs的快速检测方法研究提供借鉴。本试验结果表明,随着加热时间的延长,食用油(菜籽油、大豆油、玉米油)中TFAs含量也随之增加,尤其顺式脂肪酸含量较多的食用油,经加热后其TFAs含量增加更明显。与玉米油和菜籽油相比,大豆油含有丰富的油酸、亚油酸及少量的亚麻酸,其中亚油酸含量超过总脂肪含量的50%,因此,大豆油中TFAs含量增加明显,这与苏德森等[31]的研究结论一致。在检测方法上,Li 等[32]和董晶晶等[33]分别采用近红外光谱对食品油中TFAs含量进行检测,并且分别基于全光谱或部分光谱信息建立TFAs含量的预测模型,但未对有效光谱信息进行筛选,故数据量大,计算繁琐。孙通等[34]利用UVE对全波段光谱进行变量筛选,建立食用植物油中腐霉利含量的分类模型,判别正确率提高至98.7%,取得了良好的分类效果。因此,本研究尝试将UVE与SVR 相结合的方法,进行食用油中TFAS含量的预测。为提高模型的稳健性,将UVE 用于拉曼光谱信息的分析处理,对3种食用油的拉曼光谱信息进行特征筛选,不仅简化了计算,还明显提高了模型的定性与定量分析能力。
本研究仅对不同种类食用油不同加热时间后的激光拉曼光谱特征进行了分析,未对其特征峰所生成的映射图进行考查,其映射图可能还含有丰富的有用信息,可对其作进一步研究。如,先融合样品的拉曼光谱和图像信息,再结合适合的建模方法,以达到进一步提高模型精度和稳健性的目的。
4 结论
本研究利用激光拉曼技术对不同加热时间下食用油TFAs含量进行快速定性和定量检测分析,并通过光谱预处理、变量选择及建模方法对预测模型进行优化。结果表明,在定性分析中,采用UVE 分别筛选菜籽油、大豆油和玉米油的特征变量,基于筛选特征变量的3种油的FDA 判别平均正确率均在90%以上,明显高于基于全谱数据的FDA 判别平均正确率,表明了对拉曼光谱所采集信息进行优化筛选的必要性。在定量预测中,基于筛选变量的菜籽油、大豆油和玉米油最优预测模型(SVR)的训练集R2分别为0.990 3、0.992 4和0.988 4,测试集R2分别为0.952 6、0.954 8和0.958 5,进一步证实,去除冗余信息可以有效提高模型的稳健性和精度。本研究为不同加热时间食用植物油中TFAs含量的快速无损定量检测研究提供了参考。
