基于多元岭回归估计小麦种植密度
2020-03-15刘哲乌伟张善文崔倩倩李瑞洋
刘哲, 乌伟, 张善文, 崔倩倩, 李瑞洋
(西京学院信息工程学院, 西安 710123)
种植密度影响小麦生长的许多方面,包括产量、水和肥料需求以及对病原体的易感性等。小麦的最佳种植密度提供了最佳的小麦冠层结构,对其籽粒产量和品质有重要的影响,及时准确对田间苗数进行计算对于指导生产具有积极意义[1-3]。在传统测产过程中,首先要人工获得单位面积内的小麦穗数和穗粒数,然后根据籽粒的千粒质量计算得到小麦的产量,这种估产方法往往耗时耗力,效率低下。近年来,随着图像处理技术和人工智能技术的发展,逐步被应用于农作物生长管理中,对改善传统农业操作方式和实现农业智慧化等方面做了有意义地探索工作。在小麦育种和生长管理过程中,图像处理技术和人工智能的应用主要体现在病害诊断[4-6]、品种分类[7-9]、不完善籽粒检测[10-12]、产量预测[13-16]、小麦籽粒形态测量[17-20]等方面。
在农作物测产方面,龚红菊[21]基于彩色摄像机拍摄成熟期水稻群体图像,运用分形理论和图像纹理分析方法分析水稻群体图像的分形特征,完成水稻穗头计数,用多元线性回归方法建立单位面积水稻穗头与水稻产量的数学模型,模型估产精度为92.57%。Reza等[22]提出了一种基于形态运算和连通边界的水稻植株数自动图像处理计数方法,其计数精度达到了89%~93%。刘涛等[14]利用图像的颜色特征和纹理特征对大田环境下麦穗图像进行分割,通过对撒播和条播各35 幅样本图像进行计数实验,准确率分别为95.77%和96.89%,该方法在麦穗图像没有粘连时计数精度较高,当麦穗粘连时该方法精度较差。范梦扬等[15]采用支持向量机学习方法精确提取小麦麦穗轮廓,同时构建麦穗特征数据库对麦穗进行计数,平均识别精度高于93%。杜世伟等[23]提出了一种基于图像处理技术的小麦小穗抛物线分割方法,实现了小穗数及麦粒数的同步识别计数,使用3 个品种小麦穗图像对麦粒数计数方法进行验证,结果表明,麦粒数计数的平均绝对误差为2.11%,平均相对误差为5.62%。Fernandez-Gallego等[24]提出选择拉普拉斯频率滤波器去除图像中出现的低频和高频元素,使用中值滤波器减少存在于麦穗周围的噪声,最后通过查找最大值分割局部峰值并确定图像中的麦穗数目,其算法识别精度达到了90%。Zhu等[25]提出了一种粗检测和细检测相结合的两步小麦穗检测方法,在粗检测步骤中密集提取SIFT尺度不变特征作为低层视觉描述符,选取候选的麦穗区域;在细检测步骤中使用Fisher向量(FV)编码生成中层表示,去除非麦穗区域,结果表明,与人工观测相比,自动检测麦穗计数法是可以接受的。Li 等[26]利用麦穗植株图像中穗头的颜色和纹理等特征参数,并结合神经网络来检测小麦穗头,检测正确率在80%左右,但是该研究是在基于实验室环境下所培养的盆栽小麦上进行的,并未应用到实际田间测产中。李毅念等[27]基于凹点检测匹配连线方法实现粘连麦穗的分割,进而识别出图像中的麦穗数量,通过计算图像中每个麦穗的面积像素点数得到每个麦穗的籽粒数,该方法在识别3个品种田间麦穗单幅图像中麦穗数量的平均识别精度为91.63%,籽粒数的平均预测精度为90.73%;对3 个品种穗数、籽粒数及产量预测的平均精度为93.83%、93.43%、93.49%。在作物种植密度估计方面,Liu等[28]在超绿色空间利用OTSU方法从背景中提取小麦幼苗信息,通过分析田间重叠区域的特征参数,建立了基于链码的骨架优化方法和相应的方程,用于重叠区域小麦幼苗的自动计数,结果表明,该方法可以有效地计算小麦苗数,平均准确率为89.94%,最高准确率为99.21%。Nasim等[29]通过低空无人机获取地面水稻植株图像,基于形态学操作和连通成分边界的自动图像处理方法对获取的图像进行自动处理,计算移栽后的水稻植株数量,结果表明,该算法平均准确率为87%。Liu等[30]使用图像分析技术提取幼苗,计算幼苗的覆盖度和重叠叶的角点数,利用多元回归分析构建小麦幼苗数量估算模型,当该模型应用于不同品种时,决定系数R2始终大于0.85,表明该模型适用于不同品种,随着叶片阶段或密度的增加,模型的准确性下降,但最小决定系数R2仍然大于0.83,表明该模型对不同叶龄和密度的幼苗具有良好的适应性。Liu等[31]从地面沿行方向拍摄得到麦苗RGB高分辨率图像,统计表明,沿行方向的相邻麦苗之间的间距是独立的,并且在经历行距变化条件下遵循伽马分布,然后导出伽马计数模型以估计麦苗密度,估计精度达到了90%。
综上所述,目前运用图像处理技术对田间小麦种植密度进行估计主要是通过图像分析的方法对小麦幼苗(幼苗的1叶至3叶期)进行识别和计数,从而得到小麦的种植密度。但是复杂环境对小麦的出苗率和成活率会造成很大的影响,需要持续对小麦各个生长阶段进行监测,通过小麦生长密度的变化来评估小麦的长势,这就需要一种比较通用的小麦种植密度估计方法。为此,本文提出一种基于多元岭回归模型估算小麦种植密度的方法,该方法以麦苗的边缘像素总和、麦苗面积像素总和、麦苗局部纹理特征作为输入参数,麦苗密度作为输出参数,得到麦苗密度与特征参数间的多远回归方程,具有一定的通用性且估计精度较高。
1 材料与方法
1.1 图像获取
麦苗图像拍摄地点在陕西省宝鸡市农业科学研究院试验场,位于宝鸡市岐山县凤鸣镇,拍摄时间为2018年10月30日至11月05日下午,小麦正处于分蘖期,生长态势良好,品种分别为西农529、西农511、西农583、陕农33,获取图像样本分别为100、100、150、150幅。拍摄器材选用陕西维视MV-E工业相机,采用千兆以太网络进行传输,相机功耗低、散热良好,具有图像质量清晰、色彩还原性好和工作稳定等特点,支持IO信号输入输出,图像分辨率为2 560×1 920像素,图像格式为JPG,相机拍摄视场大小为0.75 m×0.40 m。在晴天微风条件下进行垂直拍摄,拍摄高度距离地面80 cm,拍照时间15:30~16:30。
1.2 图像算法处理
对采集地麦苗图像进行处理,首先,将采集的彩色麦苗图像从RGB颜色空间转到Lab颜色空间,基于改进的K-means算法在Lab空间对麦苗进行分割;其次,对训练图像进行标准化,求得图像的面积特征、轮廓特征和LBP纹理特征,将其特征值和麦苗数作为输入参数,利用多元岭回归得到麦苗图像特征值与麦苗数间的函数关系;最后,将测试图像特征值代入函数,计算麦苗密度值。
1.3 基于Lab空间的改进K-means聚类彩色麦苗图像分割
RGB颜色空间无法直接转换成Lab,需要先转换成为XYZ颜色空间,再转换到Lab颜色空间,再通过式(2)转换到Lab颜色空间。
(1)
(2)
(3)
式中,Xn、Yn、Zn一般默认是95.047、100.000、108.883。
K-means算法中K个聚类中心是事先给定的,由于无法确定数据集的的合适类别个数,可能导致无法得到有效的聚类结果。为此,本文对K-means算法进行改进。
在此定义2个参数ρi和δi,ρi表示第i个数据点的局部密度,δi表示第i个数据点与最近邻类间距离。首先,求出数据xi与数据集中其他数据点xj之间的距离dij。
(4)
式中,dc为截断距离。

(5)
根据式(4)得到所有数据点的局部密度后,按照密度值由大到小排序,取前k个密度值较大的数据点,于是得到δi。
(6)
式中,l代表密度值最大的k个数据点。
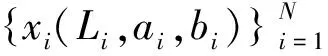
(7)
计算出每个像素点的(ρi,δi)值,设ti=ρiδi,依据麦苗图像由麦苗和土壤2部分构成,选取ti值最大的2个像素点作为麦苗图像的2个聚类中心,然后依据欧氏距离相近原则,将所有像素点进行聚类。
针对麦苗彩色图像像素的三颜色分量之间存在的高度相关性特点,本文采用基于Lab 颜色空间改进的K-means算法进行彩色图像分割。
1.4 基于多元岭回归估算麦苗密度
为了对获取的麦苗图像进行密度估计,首先对麦苗图像进行标准化。文中获取的麦苗图像分辨率为2 560×1 920像素,把每幅图像裁剪成100个256×192像素的标准块图像。每种小麦分别选取5 000个标准块图像作为训练图像,100幅标准块图像作为测试图像。
对于训练图像,分别提取图像的面积特征、轮廓特征、LBP纹理特征作为输入。
①面积特征定义为:麦苗在图像中的像素数,用a来表示。
②轮廓特征定义为:麦苗边缘在图像中的像素数,用c来表示。
③LBP纹理特征定义为:LBP麦苗纹理特征图像的直方图,用b来表示。
对于给定的训练图像Ii,i=1,2,…,N,N为输入训练图像的总数,分别提取Ii的面积特征ai、轮廓特征ci、LBP纹理特征bi作为训练输入向量,xi=[ai,bi,ci],Ii中的麦苗密度yi作为训练输出,于是{xi,yi}作为训练对式(8)训练输入和输出映射函数的参数。
(8)
对于{xi,yi},多元岭回归模型如式(9)所示。
(9)
这里W∈1×3和b∈1×1分别表示权矩阵和偏置向量,称为弗罗贝尼乌斯范数(简称F-范数),λ是一个控制惩罚和拟合之间权衡的参数。求解(9)式等效于对式(10)进行求解。
(10)
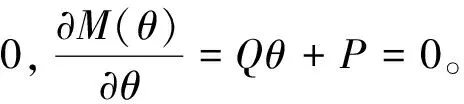
θ=-(QTQ)-1QTP
(11)
多元岭回归估算麦苗密度算法流程如图1所示。
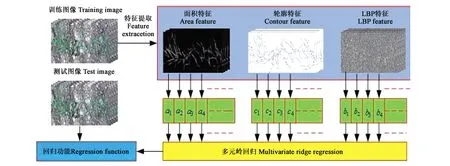
图1 多元岭回归估算麦苗密度算法流程
1.5 指标参数设计
为了验证本文方法的性能,采用决定系数R2、统计误差Pe和统计精度Pa三个指标参数进行评价,这3个指标参数计算公式分别如式(12)~(14)所示。
(12)
(13)
(14)
式中,M代表总共要估计的麦苗密度图像数,i代表第i个麦苗图像,Yi代表本文算法对第i个麦苗图像的麦苗密度估计结果,Xi代表人工对第i个麦苗图像的麦苗密度计数结果。
2 结果与分析
2.1 图像处理结果分析
对采集的原始麦苗图像用本文所提的方法进行处理,分别得到麦苗图像的分割图像、轮廓图像、纹理图像,结果如图2所示。可以看出,用改进K-means算法对麦苗图像进行分割,能很好的把麦苗从背景中分割出来;在麦苗分割图像的基础上,运用图像边缘提取方法得到轮廓图像,再经LBP方法获得纹理图像。LBP是一种用来描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性等显著的优点。基于麦苗LBP纹理图像统计直方图获得麦苗训练图像块的面积特征、轮廓特征和纹理统计直方图特征(图3),用这些特征参数就能够训练和计算麦苗的种植密度。

图2 麦苗图像处理结果比较
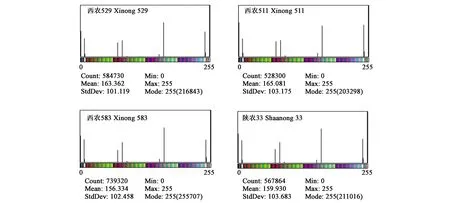
图3 麦苗LBP纹理图像的统计直方图
2.2 麦苗计数分析
图4给出了4种品种小麦人工测量麦苗密度与算法估计麦苗密度间的线性相关关系。由图4可知,4个品种利用图像处理算法估测的麦苗密度与人工实测麦苗密度具有极其显著的线性相关性,所有品种的计数预测值与实测值的决定系数R2都大于0.85。根据算法估计的麦苗密度分别是“西农529”是318.6万株·hm-2、“西农511”是307.95万株·hm-2、“西农583”是297.9万株·hm-2、“陕农33”是311.25万株·hm-2。
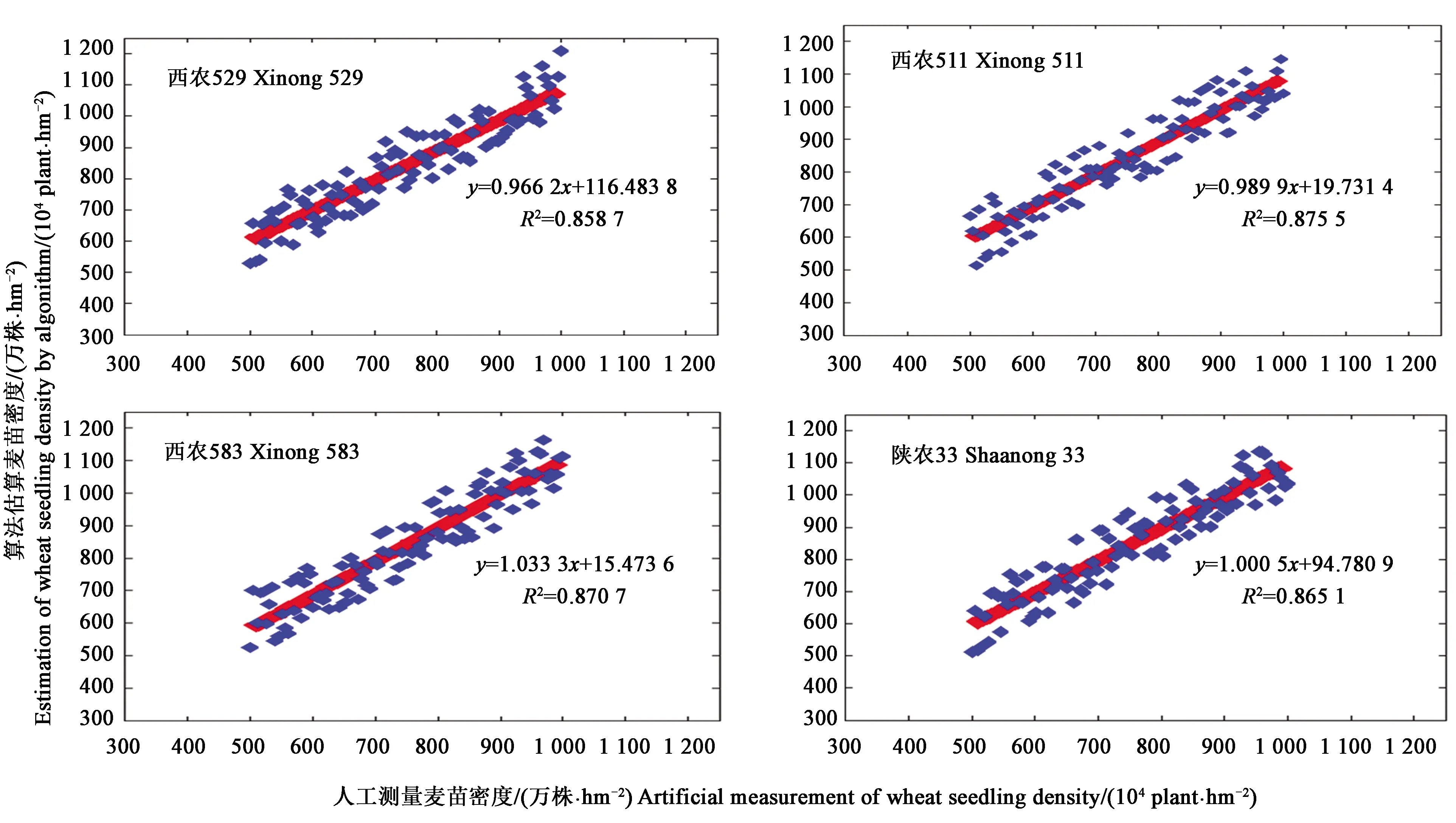
图4 4个品种小麦人工测量麦苗密度与算法估计麦苗密度间的线性相关关系
2.3 麦苗密度分析
人工实测麦苗密度和算法估计麦苗密度的统计分析比较结果如表1所示。可以看出,4个小麦品种的麦苗密度平均统计误差是6.01%,平均统计精度是93.99%,比人工实测的结果偏小。
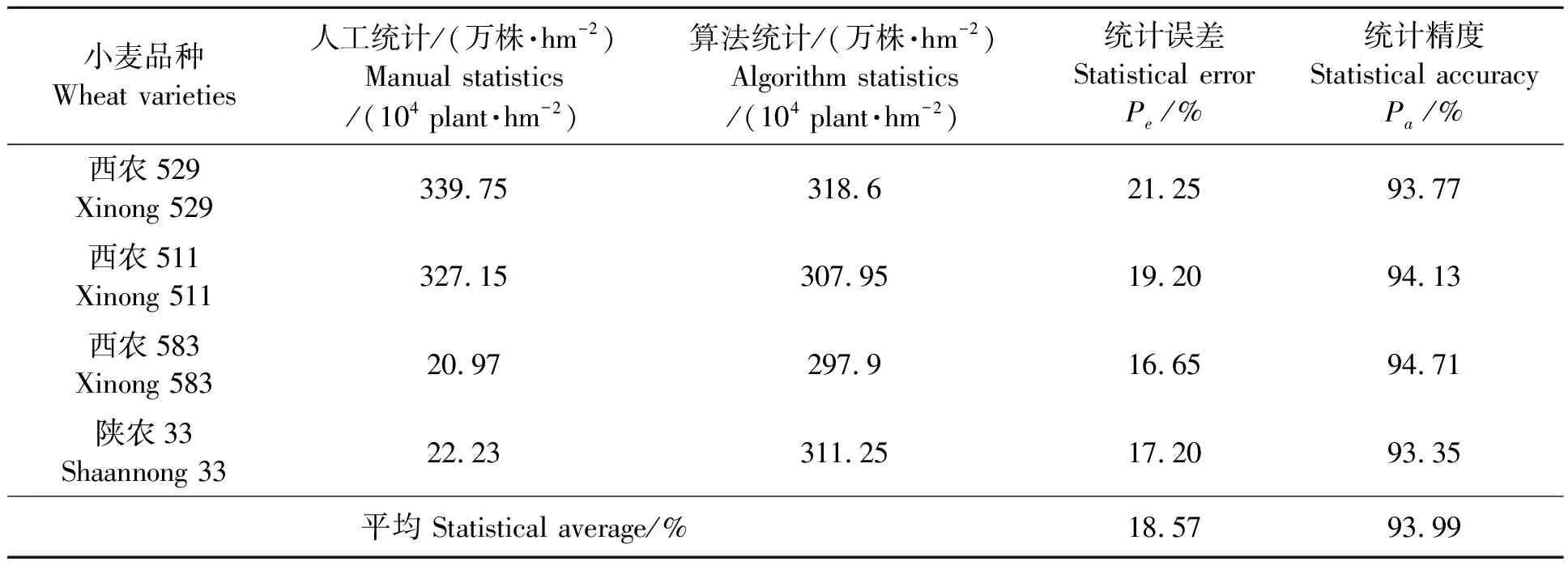
表1 人工计数与算法计数统计比较
2.4 不同颜色空间分割效果
图5给出了同一幅麦苗图像在RGB颜色空间和Lab颜色空间的图像颜色分量变化特征,可以看出,R颜色值、G颜色值和B颜色值变化趋势比较一致,具有很强的相关性,由麦苗向土壤过度时或者由土壤向麦苗过度时,各颜色值没有明显的变化,所以在RGB颜色空间很难精确地表示麦苗颜色和土壤颜色之间明显的差距。同时,由图5可以看出,Lab颜色空间的a和b颜色值在由麦苗向土壤过度时或者由土壤向麦苗过度时变化非常明显,可以区分出麦苗和土壤。所以在Lab颜色空间运用改进的K-means聚类算法能够分割出麦苗。
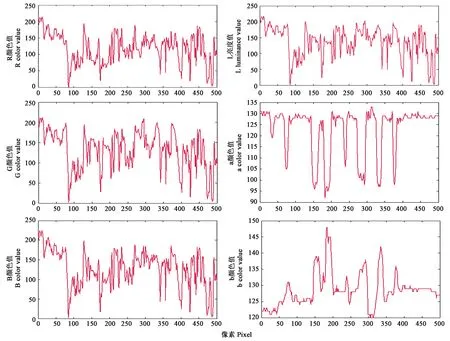
图5 不同颜色空间的颜色值
3 讨论
本文提出了一种不借助于特制仪器,直接用数码相机获取自然生长条件下的麦苗图像。RGB 颜色空间是面向设备的颜色空间,其用欧几里德距离表示三颜色距离,三颜色分量之间存在高度相关性和非线性,导致在RGB颜色空间进行图像分割结果的鲁棒性不佳。Lab 颜色空间是与设备无关的最均匀的颜色空间,其用欧氏距离来表示色差。用欧氏距离表示色差既能满足人眼对图像的敏感性,又能较精确地测量颜色之间微小的差距,在彩色图像分割中使用欧氏距离来表示人类对颜色的差别感知。分割时,K-means算法基于样本之间的距离大小将给定的样本集划分为K个簇。为了使簇内的点尽量紧密的连在一起,簇间的距离尽量大,由于无法确定数据集的的合适类别个数,可能导致无法得到有效的聚类结果。为此,对K-means算法进行了改进。本研究在Lab 颜色空间能较精确地测量麦苗颜色和背景颜色之间微小的差距,进而运用改进的K-means聚类算法将麦苗从背景中分割出来。
利用本文提出的算法对麦苗图像进行处理分析可得到麦苗密度的估计值,但比实测值偏小,主要有两点原因:①由于本文算法在进行估算时,麦苗的叶子会交叠在一起,从而造成麦苗真实面积会有所减小,造成估计误差;②利用图像分析求麦苗轮廓长度时,由于麦苗的叶子交叠在一起,从而造成麦苗真实轮廓长度会有所减小,造成估计误差。
总体来说,本文提出的麦苗密度估算方法能够适用于麦苗的不同生长阶段,而且是一种非接触式测量方法,不需要采集麦苗样本,在田间直接操作可以获取测量参数,快速便捷。
