场景字符识别综述
2020-03-15罗昱成
罗昱成
(四川大学计算机学院,成都 610065)
0 引言
文字是人从日常交流中语音中演化出来,用来记录信息的重要工具。文字对于人类意义非凡,以中国为例,中国地大物博,各个地方的口音都不统一,但是人们使用同一套书写体系,使得即使远隔千里,我们依然能够通过文字进行无障碍的沟通。文字也能够跨越时空,给予了我们了解古人的通道。随着计算机的诞生,文字也进行了数字化的进程,但是不同于人类,让计算机能够正确地进行字符识别是一个复杂又艰巨但意义重大的工作。从计算机诞生开始,无数的研究者在这方面做了很多工作与尝试,但面临的困难艰巨。
主要面临的困难是:(1)场景复杂变化很大;(2)字体形态颜色多变;(3)光照条件变化大;(4)文字排列方式不确定;(5)文本行与文本行之间的距离,大小格式,字体变化大。
近年来,深度学习的引入,使得在我们在复杂场景下进行字符识别都达到了更高的水平。本文希望对场景文字识别的成果进行梳理、分类和对比,进而分析领域发展趋势。
1 方法综述
首先,我们将识别问题定义为,将原始图片中只包含一个单词或者只包含一行单词的文本的部分切割出来,接着将这个切割的小图片中的字符通过设计的算法提取出来。
传统的方法将这个问题又切割为三部分,预处理、字符分割和字符识别。对于背景比较复杂的场景,字符切割是一个很艰巨的任务。为了避免将字符进行切割,主要通过两个技术来进行改进,一个是CTC[13],一个是基于注意力机制的序列到序列模型[1,18]。
深度学习为文本行识别带来了端到端方法,无须像传统方法那样进行大量预处理和手工设计特征。我们主要将深度学习文本行识别的方法分为三个部分,一是矫正部分,二是特征提取部分,三是序列转化部分。
1.1 图像校正
矫正部分主要源于STN[4],STN通过预测图像的形变矩阵,再在原图上进行重采样的方式,可以在无须额外标注数据的情况下,对输入图片进行矫正。而在文本检测任务中,更常使用的是TPS-STN[6,8]。TPS-STN包括三个步骤。一是定位网络定位控制点,二是计算形变矩阵计算出重采样栅格,三是在原图上重采样。
(1)定位网络
首先使用定位网络定位K个控制点,预测字符串出现在原图中中的位置。定位网络是一个独立的网络模块,包括卷积层和全连接层,最后的全连接层的输出通道为2*K,对应输出K个控制点的坐标。同时最后一层的激活函数为tanh,将输出坐标的值映射到到-1到1之间。
(2)栅格获取
接着根据预测到的k个控制点,计算变形后的栅格与原图对应位置之间的关系,得到一个映射矩阵,根据映射矩阵将变形后栅格中的点对应到原图。最后使用双线性插值在构造新的变形图片。
(3)重采样
最后,在已知采样栅格的情况下,在原始图片上进行双线性插值,用以计算,栅格中对应位置的像素值,最后重采样得到经过矫正后的图像。经过TPS-STN模块可以使一些弯曲,或发生透视形变的文本得到比较好的矫正。将矫正模块独立分出,能够有效提高整个端到端系统的精确度。
1.2 特征提取
特征提取方法主要分为两个部分,第一部分是图像特征提取,第二部分是序列特征提取。
图像特征提取通常使用卷积神经网络进行特征学习,由于字符识别相较于物体分类的不同,通常不会完全照搬分类网络来直接进行图形特征提取,会在分类网络的基础上为了适应目标任务的改进。文献[5]提出了使用类似VGG[15]网络的多个堆叠卷积来进行特征提取。文献[9]提出使用GRCNN来进行特征提取,GRCNN从GRU[18]中获得灵感,减少参数的同时使得CNN拥有类似RNN的能力。文献[8]提出使用了更先进的ResNet[16]来对图像进行特征提取,ResNet能够很好地提取图像中的特征信息。最新的论文通常都为卷积核配备了BN模块,BN模块在使用少量参数的情况下,能够有效地解决梯度消失和提供正则化的效果。
由于卷积神经网络会受到感受野的限制,因此提出了需要使用序列特征提取模型对特征进行建模,学习卷积神经网络提取到的图像特征之间的上下文关系。文献[5,8,9]使用了Bi-RNN[17]模块来学习序列特征,文献[14]提到由于RNN训练的困难性,以及RNN无法并行的问题,使用了多个堆叠的卷积核来对序列特征进行建模。
1.3 序列转化方法
序列转化的任务主要是将前面得到的特征序列转化为最后输出的字符串序列。主要使用的序列转化方法包括两种。一种是CTC[13],一种是基于注意力机制的seq2seq模型。CTC模型根据特整体输出的在词典中所有单词的概率分布序列定义了一种给定序列,是标签序列的条件概率,并忽略中每个标签的位置,避免为单独字符标注位置。而基于注意力机制的seq2seq模型是基于Encoder-Decoder的网络结构,包括Encoder和Decoder两个模块,Encoder将CNN提取出的特征序列转换为固定长度的语义向量,Decoder在将这个语义向量表示转化为输出序列,使得模型可以学习到在一个可变序列的条件下生成另一可变序列的转换,同时也定义对应的条件概率。
(1)CTC
CTC方法将输出改率分布序列y=(y1,y2,…,yn)解释为可能的标签序列上的条件概率。标签空间为所有可能输出字符(如阿拉伯数字和英文字母),以及引入的空白字符{blank}。通过引入空白空字符可以解决两个问题,第一个问题是则对于序列π对应的条件概率为:

其中,t表示第t个神经网络输出的序列,n表示共有n个输出步骤。表示在步骤t中出现标签πt的概率。为了计算给定x的条件下输出Y的概率,CTC会枚举所有可能的对齐方式然后把这些概率累积起来。然后多对一映射到B,以将序列π转换为更短的序列,作为最终的预测。将重复的连续标签合并为单个标签,然后删除空白标签。例如,序列“-hhe-l-ll-o”映射为“ hello”,其中“-”代表空白。

一般而言,对于给定的序列,存在大量的映射路径。因此,公式中的和的计算是耗时的。为了解决这个问题,通常使用基于动态规划的前向算法来高效地计算条件概率。
(2)基于注意力机制的序列到序列方法
基于注意力机制的序列到序列方法首先基于序列到序列的方法,序列到序列方法是一种将一串序列输入转化成另一种规则的序列输出的方法,被广泛使用在语音识别,自然语言处理,特别是机器翻译中。序列到序列方法包括两个结构,一个是Encoder模块,一个是Decoder模块。Encoder模块通常由LSTM[17]或者GRU[18]实现,将序列的输入O(o1,o2,…,on)转化为一个包含上下文信息的张量c。而Decoder模块接受张量c,并输出目标序列T(t1,t2,…,tm)。
基于注意力机制的序列到序列方法,在Encoder-Decoder方法的基础上增加了注意力模块。在Encoder对数据进行编码的过程中,接受序列s输入O(o1,o2,…,on),输出序列H(h1,h2,…,hn),同时输出编码上下文信息后的张量c。注意力模块结构出每一个步骤的注意力分布α,使用注意力分布从输出序列H(h1,h2,…,hn)中得到一个新的信息张量g,将信息张量g送入Decoder模块进行解码,通过softmax函数得到预测标签,并重复使用注意力模块和Decoder模块进行解码操作,直到输出完毕。
2 方法对比、数据集和评价标准
2.1 方法对比
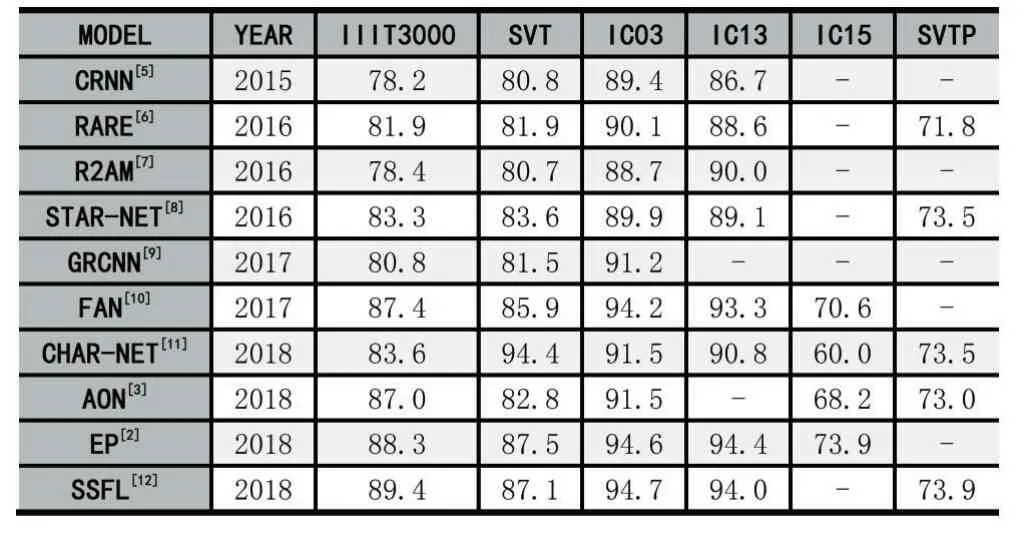
表1
2.2 数据集
IIIT5000K[19]:该数据集具有从互联网收集的3000个裁剪的测试词图像和2000个裁剪的训练图像。每个图像具有50个单词的词典和1000个单词的词典。
SVT[20]:包含从Google街景收集的户外街景图像。这些图像中有些是嘈杂的、模糊的或低分辨率的。SVT由257张训练图像和647张评估图像组成。
ICDAR 2003(IC03)[21]:IC03包含用于训练的1,156张图像和用于评估的1,110张图像。忽略所有太短(少于3个字符)或包含非字母数字字符的单词,会将1,110张图像减少到867张。
ICDAR2013(IC13)[22]:继承了IC03的大部分图像,也是为ICDAR 2013比赛而创建的。它包含848幅用于训练的图像和1,095幅用于评估的图像,其中具有非字母数字字符的修剪词可生成1,015幅图像。
ICDAR2015(IC15)[23]:是为 ICDAR 2015 比赛而创建的,其中包含4,468张用于训练的图像和2,077张用于评估的图像。这些图像是在佩戴者自然运动的情况下由Google眼镜捕获的。因此,许多噪声,模糊和旋转,还有一些分辨率较低。
SVTP[24]:SVTP中的图像是从Google街景视图中的侧视图图像中拾取的。它们中的许多由于非正面视角而严重变形。数据集包含639张裁剪的图像进行测试,每个图像都带有从SVT数据集中继承的50个单词的词典。
2.3 评价标准
文本行识别评价标准主要有两种方法,一种是基于字符级别的正确率,对于一段字符串,会计算预测字符串和标签字符串的编辑距离,用以计算字符级别的正确率。一种是文本行级的正确率,只有整行文本行都预测正确,才会将该样本算作正例,目前的算法通常采用文本行的正确率作为评估标准。
性能评估上,主要考虑预测模型对于单张图像的平均预测时间。当然,网络模型的参数量也是一项重要的性能评估标准。
3 结语
近年来,由于深度学习的引入,使得场景字符识别问题用更简单直接的方式得到了更好的解决,但是对于很多特殊场景(如:曲线场景等)还不能完美的解决,最新的方法也在往这些方向努力。同时深度学习的可解释性也是困扰学术界和工业界的巨大难题,如果不能够合理合适的解释深度学习技术,我们就没有办法很好地将这项技术应用到安全要求极高的场景中,因为目前的方法很容易通过细微的修改图像个别像素值而对整个方法的结果造成干扰。
