基于锚框密集化与度量学习的多尺度人脸检测研究
2020-03-13陆生礼
孙 杰,陆生礼
(1.东南大学国家专用集成电路系统工程技术研究中心,江苏 南京210096;2.博西华电器(江苏)有限公司,江苏 南京210046)
0 引言
人脸检测可以看作是通用对象检测的一种特殊情况[1,2]。随着深度学习方法在卷积神经网络(Convolutional Neural Networks,CNN)上的广泛使用,近年来人脸检测取得了很多进展,基于CNN的人脸检测方法即使在遮挡、姿势变化和大的光照变化的情况下也取得了卓越的性能。目前开放的问题是如何有效检测尺度大范围变化的人脸。大多数基于CNN的方法通过两种策略解决尺度不变性问题:第一是将图像分解为不同的金字塔等级,比如得到广泛使用的多任务级联卷积神经网络MTCNN(Multi-task Convolutional Neural Network),随后将图像金字塔馈送到网络,例如参考文献[3],尽管Zhang[9]等使用全局和局部人脸特征减少图像金字塔数量,但将图像输入到网络多次的这种方法非常耗时,因为必须多次放大和缩小输入图像,推理必须在所有重新缩放的图像上执行;第二是建立一个更深、更大的网络,利用不同层次的特征图来实现尺度不变性,例如SSD(Single Shot Multi Box Detector)[4]使用VGG16[5]作为骨干网络,而YOLO((You Only Look Once)[6]使用具有更多层的类似骨干网络,尽管此解决方案在单个输入图像比例上表现良好,但它需要更大的模型尺寸且计算量大。
最先进的人脸检测器大致可分为两类:第一类主要基于Faster R-CNN[2]中采用的区域提议网络(Region Proposal Network,RPN),并采用两阶段检测方案。RPN端到端训练并生成高质量区域提议,然后通过快速R-CNN检测器进一步细化。另一类是基于单镜头检测器(SSD)[4]的一阶段方法,它不需要RPN,并直接预测了边界框和人脸置信度[4,26,27]。最近,一阶段人脸检测框架由于其更高的推理效率和简单的系统部署而引起了更多的关注。SSH(Single Stage Headless Face Detector)[17]和S3FD(Single Shot Scale-invariant Face Detector)[11]开发了规模不变的网络,单个网络中不同层的特征图负责不同大小的人脸,包括R-CNN[1]、SSD[4]、YOLO[6]、Focal Loss[12]及其扩展。受益于强大的深度学习方法和端到端优化,基于CNN的人脸检测器取得了更好的性能,并为以后的方法提供了新的基线。
当前人脸检测技术的主流是基于锚框(Anchor)[14]的。然而,基于Anchor的检测器严重依赖于非常大的基础网络,训练和推理的效率不高。S3FD也具有SSD样式检测框架的类似缺点,对大尺度变化的人脸检测性能不佳。随着对象尺寸的减小,基于Anchor的目标检测器的准确性急剧下降,而基于Anchor的人脸检测器更是如此。我们认为这个问题与三个方面有关:模型的架构、锚框匹配策略以及度量函数。本文将从这三个方面入手,解决当前模型的问题,并在具有挑战性的WIDER FACE数据集上验证所提出的算法。作为总结,本文的主要贡献包括:
第一,首次提出了一种有效的基于多网络统一的训练方案,以端到端的方式对提议的互补特征增强网络模型(Complementy Feature Augmentation Network,CFANet)进行训练,从而为人脸检测提供了更多的鉴别性特征。
第二,补充特征增强:我们使用轻量不同的辅助CNN产生“互补”的不同的特征,促进了针对小脸的上下文的特征增强网络(CFANet)的特征学习能力,不仅增强了小脸检测所依赖的高分辨率浅层特征,也能促进低分辨率的高层的高维特征,从而使网络具有更多的鉴别性特征。
第三,在几个公开的人脸检测基准上进行了全面实验,证明了所提出的CFANet框架的优越性。实验表明,我们的CFANet检测器不仅可以实现最先进的检测性能,而且执行效率较高。
1 当前人脸检测模型的问题分析
当前的人脸检测模型和算法不具备良好的多尺度检测能力,我们认为可以从以下三个方面来分析。
1.1 模型的架构
特征提取部分对于人脸检测器至关重要。目前,特征金字塔网络(Feature Pyramid Networks,FPN)[13]被广泛用于最先进的人脸检测器中,以获得丰富的人脸特征。但是,FPN只聚合高层和低层输出层之间的层次特征映射,它不考虑当前层的信息,并且忽略Anchor之间的上下文关系。在本文中,受Xiong[15]等成功应用异构网络完成最先进的人脸识别模型的启发,我们设计了异构的主网络与辅助网络一起训练的方案,让主网络在训练时获得辅助网络的帮助,得到更多的鉴别性特征,但是在推理时只需主网络,无需辅助网络的参与,这样的方案是高效的。同时,该方案的主网络不是简单与辅助网络进行特征的拼接,而是一起训练,一起学习到促进主网络获得更多的特征。Zhang[10]等人提出的聚集网络,将同一个网络堆叠3次,以获得更多的人脸特征,和我们利用异构网络的思路不一样。据我们所知,目前的多网络的融合方案,还没有人提出类似方法。
1.2 锚框密集化匹配策略
基于Anchor的检测方法中,Anchor比例是离散的(例如在S3FD方法中,使用16,32,64,128,256和512的比例),而真实场景中人脸的比例是连续的。检测架构很难直接应用当前基于锚的通用对象检测方法来检测中小型人脸,因为最低层上相关联的Anchor的步幅太大,无法检测到小脸(例如小于20×20像素),使得与那些小脸相对应的区域在卷积层上的尺寸很小,几乎没有检测特征。同时,人脸尺寸、锚定比例和相应的接收场不匹配或者匹配不足,比如Faceboxes[22]设计的最小的Anchor为32×32,对于20×20以下的分辨率基本上不能保证匹配,因此无法有效使用人脸的检测特征,导致出现漏检测(False Negative)。基于此,我们提出了锚框密集化的方案以解决此问题。
1.3 基于度量学习的特征融合与增强
在距离度量学习中,适当距离算法的选择至关重要,寻找合适的距离是在距离度量学习中执行的任务。度量学习是学习对象上的距离函数的任务,度量或距离函数必须服从四个公理:非负性、不可分与同一性、对称性和次可加性(或三角形不等式)。不可分与同一性指实体x与实体y是同一的、不可区分的,全部性质都相同。在实践中,度量学习算法会忽略不可分与同一性(伪度量),即如果断言对x成立的,那么断言对y同样成立(反之亦然)。人脸的检测与人脸的识别不同,人脸检测本身不需要测量人脸之间的距离或人脸与背景之间的距离。本文在人脸检测中引入距离度量函数,并在端到端的学习过程中学习适当的距离,其目的是在异构网络的同样大小的特征图之间度量其特征值之间的差异。只有在一定距离阈值范围内的异构网络之间的特征才能得到融合与增强。通过我们的度量学习算法,解决了特征融合的冗余与异常值问题,从而为多尺度的鲁棒人脸检测提供良好的鉴别性特征。
2 基于异构网络的人脸检测模型
在本节中,我们将描述模型架构、锚框密集化匹配和基于辅助网络的上下文建模及基于度量学习的互补特征增强。
2.1 模型的建立
基于CFANet的人脸检测模型如图1所示,体系结构包括三个部分:(a)是ResNet-18[20]的变体,具有6层特征图,从第一层的160×160到第六层的5×5;(b)可以是自建的典型的CNN,也可以是VGG-16等其他模型,同样具有与(a)相同大小的6层特征图;(c)是从(a)和(b)的特征图生成的最终检测网络,从左到右分别是FA1到FA6。
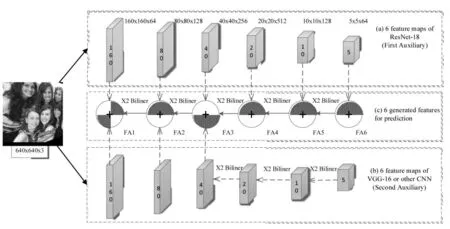
图1 基于CFANet的人脸检测模型架构图Fig.1 Architecture of face detection model based on CFANet
我们的目标是创建具有丰富语义的有效特征表示,在各个层级上实现强大的多尺度检测。与使用VGG-16[5]作为骨干网并在分类层截断的Pyramid Box[14]和S3FD[11]不同,它们需要添加一些辅助结构,最终构成完整的检测网络,训练和推理本质上只有同一个网络。我们的架构在建立两个轻量级的CNN作为辅助网络的基础上,帮助主网络的特征提取和边界框回归。第一个使用类似于ResNet-18[20]的残差块的变体,而第二个使用VGG-16或任何典型的CNN(即INPUT-CONV-RELU-POOL)。两个辅助网络是全卷积网络(Fully Convolutional Network,FCN),只需添加检测层,可以面对面地进行端到端训练检测,即每个辅助网络可以独立工作。
利用两个不同网络的互补功能,构建了CFANet最终用于检测的6个增强功能模块。CFANet可以使用固定大小的图像(即640×640)进行训练,并可以使用任意大小的图像进行测试。给定输入图像X,CFANet可以表示为:

其中,F(·|Θ)是非线性函数的情况下,每个互补特征增强操作;FAl(·|θl)均指生成的检测卷积层中的一层,这些层经过训练以学习参数Θ。最终的人脸检测包括一个预测卷积层和一个多任务丢失层,该层位于我们提出的体系结构中的6个FA之后,每一层包括卷积层、ReLU和Pooling层等。
2.2 特征增强模块
特征增强模块能够增强原始特征,以使其对小脸或严重遮挡的脸部更具区分性和鲁棒性,简称FAM。FAM是由两个原始ResNet和VGG的不同功能生成的。具体而言,建议的FAM可以通过以下数学公式表示:

其中,θlk表示l层的第k个辅助CNN的特征图,l∈{1,…,6},k∈{1,2}。具体来说,对于k=1,即第一个ResNet-18变体。是诸如S3FD之类的原始特征图,而Fl是从l+1层到l层的非线性映射。由特征增强函数Al形成,该函数用于合成每个相邻层的特征图。Al对于提高CFANet的性能至关重要,它包括特征图上的多项操作,例如归一化、级联、维数转换、求和、像素积、膨胀卷积和上采样等。最后,由乘积运算组合的6个FAM在检测微小脸部方面发挥高分辨率浅层特征的主要作用,而深层特征具有足够的语义,并在特征提取中利用不同CNN网络的互补性。显然,我们构建的FAM与Guo[21]等人使用编码器构建的特征金字塔有所不同。
如图2所示为特征增强模块,以FA1的生成为例,我们首先对两个辅助网络的每个第一特征图(160×160)进行逐乘积运算,然后进行逐元素乘积运算。接着对第二个特征图(80×80)执行相同的操作,并添加双线性上采样以提供上下文信息。最后,两个相邻的层逐元素相乘,并发送到初始模块以丰富感受野。

图2 特征增强模块Fig.2 Feature enhancement module
SSD类检测器的默认锚框与单个CNN中的多尺度特征图相关联。不同的是,我们沿着两个不同网络的深度和宽度维度设计多尺度特征图。第一,首先使用1×1卷积核对两个辅助CNN的相同维数的特征图进行归一化,然后将其作为元素乘积。其次,我们对上层执行相同的操作(1×1卷积,像素乘积),并添加双线性上采样以将大小调整为与下一个乘积操作的下层一致,从而提供更多上下文信息。第三,我们对相邻层进行逐元素乘积。通过上述非线性操作,我们充分利用了异构网络特征提取的互补特性。最后,是类似初始的模块,其中包含不同数量的膨胀卷积层以丰富感受野。
2.3 锚框密集化设计
预定义锚的平铺间隔由相关检测层的步幅大小确定。具体来说,每个辅助网络遵循S3FD[11]的等比例间隔原理设计,即在图1中,每个辅助网络的6个检测层的步长为{4,8,16,32,64,128}。但是,我们采用了改进的锚框密集化策略。作为基于锚点的检测器,我们使用三组复合锚框来匹配人脸或背景,以获得比单一网络更多的匹配。如表1所示,有两组辅助特征图和一组生成的FAM,每组都有其锚框大小。

表1 Anchor匹配策略Table 1 Anchor matching strategy
Hu等[7]指出,由于感受野太大或太小而引起的失配会损害准确性。为了解决这个问题,我们的CFANet使用了三组不同的锚定尺度。因此,通过互补的异构网络设计,我们可以获得更多的匹配可能性。此外,与S3FD[11]相同的补偿锚框匹配策略用在Jaccard重叠度大于0.1的较小人脸上执行更多匹配。
2.4 上下文辅助建模
受SSD[4]和FPN[13]的启发,我们的体系结构将具有低分辨率和高语义信息的高级功能从上到下集成到每个低级功能中。不同区域的上下文信息有助于更准确地区分面部和非面部,为了使CFANet包含不同比例的面部特征,可通过FAM将高级特征添加到低级特征中。然而,我们考虑了来自不同CNN的锚之间的互补上下文关系,FAM堆叠了不同分支的扩张卷积层以获得更大的接收场。
SSH[17]和Faceboxes[22]使用初始模块的思想来创建上下文模块。在我们的CFANet中,除了类似于初始模式的上下文模块之外,我们还通过特征增强方式并入了相邻层的语义。SSH和Faceboxes已向浅层功能添加了初始模块,以增强其特征表示。在我们的CFANet中,除了创建具有多个卷积分支和不同内核的类似inception[18]的上下文模块外,我们还通过FAM组合了来自相邻层的语义。我们的人脸上下文模块如图3所示。

图3 上下文模块Fig.3 Context module
在图3中,通过在特征空间的自下而上的连接,以及与横向连接的配合,我们获得了与特征金字塔网络类似的多尺度能力。由于我们采用了两个不同的异构网络,通过度量学习进行了特征的融合后,可以构建多尺度的特征增强的人脸特征。我们在训练时采用了固定大小的图像。但在推理时,由于网络本身是全卷积的,对于输入图像的大小没有限制。
2.5 多任务损失函数
建议的CFANet包括人脸框的回归损失和用于识别是否检测到人脸的分类损失的加权总和。回归损失用于四个坐标的回归参数化,分类损失基于Jaccard系数与参考标准Ground-truth的重叠。通常,损失函数包括2个任务,一个是用于对象分类的,常用Softmax;另一个任务是用于人脸框的回归函数(例如L2损失)。分类也可以用Lin等[12]提出的Focal Loss来解决人脸类较少而背景类太多的类的不平衡问题。
CFANet包含三个独立的卷积网络(其中主要的检测网络由两个辅助网络生成),每个卷积都有其损失函数以优化网络来检测不同比例的人脸。这三个网络的学习目标是相同的。人脸与背景的二分类问题被形式化为交叉熵损失,而人脸框被形式化为回归问题。因此,损失函数定义为:
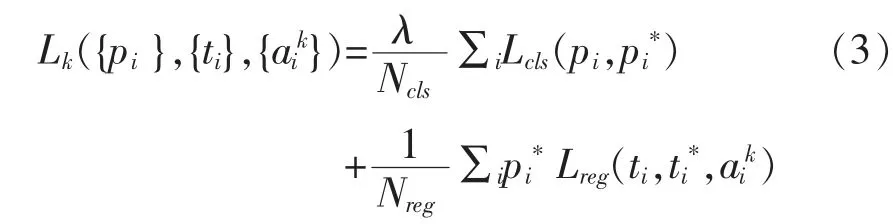
其中,k∈{1,2,3}是网络的索引,Ncls和Nreg分别表示锚的数量和正锚的数量,Lcls是分类损失,pi是锚包含人脸的置信度分数,pi*表示真实标签。Lreg是回归目标框ti和与当前锚点ai相关的地面真实坐标ti*的平滑l1损失。λ是平衡两个损耗项的超参数。
2.6 基于距离度量学习的特征融合与增强算法
马氏距离(Mahalanobis Distance)由马哈拉诺比斯(P.C.Mahalanobis)所提出,表示数据的协方差距离。它是尺度无关的,考虑各种特征之间的联系,而欧氏距离不考虑特性之间的联系。方差是标准差的平方,标准差是数据集中各个点到均值点距离的平均值,描述的是数据的离散程度。标准差和方差是描述一维数据的,当存在多维数据时,需要知道每个维度之间的变量中间是否关联。协方差是衡量多维数据集中变量之间相关性的统计量。
用Md'×d(R)作为维度为d'×d的矩阵集合,Sd(R)0+作为维度为d的半正定矩阵。实对称矩阵S称为半正定的,如果二次型X'SX半正定,即对于任意不为0的实列向量X→,都有X'SX≥0。令d∈N和M∈Sd(R)0+,对应于多维协方差矩阵M的马氏距离是:
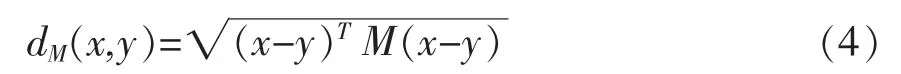
其中x,y∈Rd。马氏距离来自正半定矩阵M定义的Rd中的(半)点积。当M为满秩时,马氏距离是适当的距离;否则,它们是伪距离。当M是单位矩阵I时,欧几里德距离是马氏距离的一个特定示例,即各维度独立且同分布,只有同分布才会方差相同。马氏距离要求样本数大于维数,否则无法计算协方差矩阵。马氏距离具有规范空间上的距离所特有的其他性质,即:
第一,均质性(homogeneousness):d(ax,ay)=|a|d(x,y),其中a∈R;x,y∈Rd。
第二,平移不变性:d(x,y)=d(x+z,y+z),其中x,y,z∈Rd。
由于马氏距离的良好的尺度无关度量能力,在端到端训练时,我们计算两个辅助网络相同大小的特征图之间的马氏距离,只有在一定阈值范围内的特征才进行如式2所表示的非线性运算,将两个辅助网络的特征融合到主网络的特征图中。特征融合与增强的流程图如图4所示。
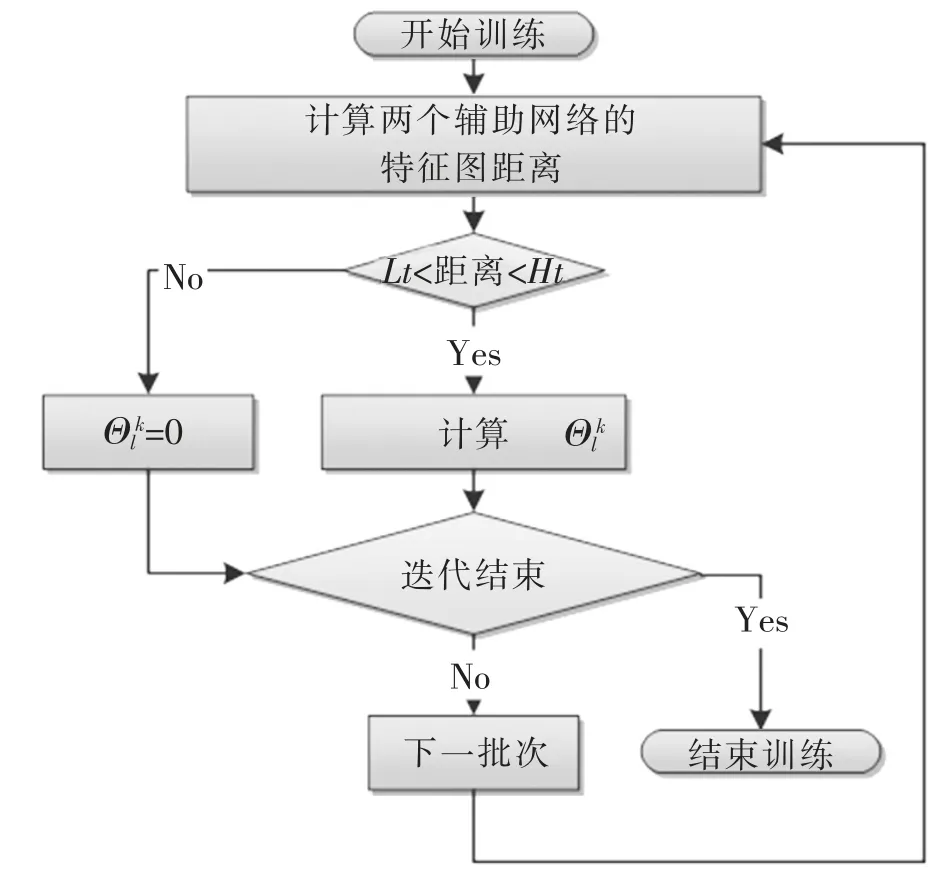
图4 基于距离度量的特征融合与增强流程图Fig.4 Flow chart of feature fusion and enhancement based on distance measurement
图4中的Lt与Ht是距离阈值的下限与上限,Θlk是需要融合的原始特征图,在规定范围外时,直接将Θlk置0,即不参与特征的融合。
3 实验验证与分析
我们在WIDER FACE[23]上进行了实验,其中每个子网络的输入采用与文献[19]一样的参数设计,以评估检测精度并验证FDDB等其他数据集的泛化性能。我们使用Pytorch库实现CFANet。训练仅使用WIDER FACE的训练子集,而验证子集的实验结果如图5所示。
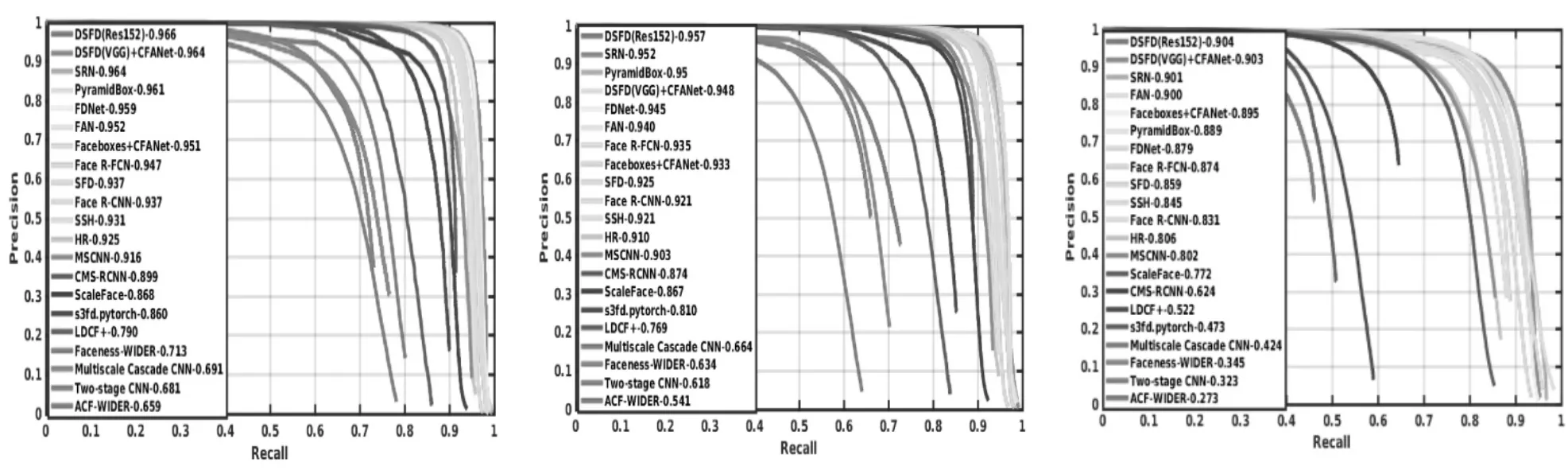
图5 WIDER FACE验证子集中的各种最新方法的精度-召回率曲线Fig.5 Accuracy-recall curve of various latest methods in the WIDER FACE validation subset
3.1 实施细节
辅助网络可以选择预先训练的VGG/ResNet,然后添加一些卷积层,或者创建一个新的CNN作为辅助网络。用于新卷积层和新网络的加权初始化方法是Xavie。我们使用SGD对模型进行优化,其动量为0.9,重量衰减为0.0005,学习率为10-3,总共迭代100次,最后20个学习率为10-4。
我们的CFANet采用的数据增强策略与SSD所使用数据增强策略类似,并遵循S3FD的设置。为了获得更多有效的微小人脸样本,从WIDER FACE的训练图像中随机选择了5个正方形补丁,一个是最大的正方形,其他的则在原始短边的[0.3,1]之间。然后,将补丁大小调整为640×640。
3.2 FDDB数据集实验
FDDB[24]包含2845张图像和5171张带标签的人脸。FDDB的人脸是椭圆形的,我们模型输出是方形的框,通过将预测的边界框转换为椭圆以进行公平比较。如图6所示,我们在不连续的ROC曲线上达到了预期的性能。

图6 在FDDB上的非连续ROC曲线Fig.6 Discontinuous ROC curve on FDDB
3.3 WIDER FACE数据集验证
WIDER FACE是全球权威的人脸检测基准之一,具有行业中更大的数据规模和更高的检测复杂性,它具有32203张图像和393703个标签,并根据检测的难度分为3个子集。我们还将进行对比研究,以评估我们方法的有效性。图7给出了两个测试示例,可以看出,图片中的人脸被全部检测到了。

图7 Wider Face测试集示例Fig.7 Example of Wider Face test set
3.4 在世界最大自拍照上验证
如图8所示,进一步验证了在全球最大的自拍照上检测大尺度人脸的性能。在图8中检测到904张人脸,大大超过了原始Faceboxes[25]和DSFD[26]的检测能力,证明了文中CFANet模型的优越性。

图8 在世界最大自拍图上的小脸检测效果Fig.8 Small face detection effect on the world's largest selfie picture
3.5 对比研究
进行对比实验以评估互补特征增强模块和复合锚匹配的有效性。根据Faceboxes[22]和DSFD[16]这两种流行模型的开源代码,我们通过添加助手ResNet-18构造了4个CFANet变体。特别是,我们没有为了公平比较而更改原始参数设置,只是对新组件进行了指定的更改。表2显示了使用WIDER FACE评估协议评估我们的方法的结果。
3.5.1 互补特征增强模块
高级语义特征与浅层特征充分融合,有助于增强易于分类的鉴别性特征。复杂人脸具有多种外观,存在各种不同的遮挡及光照的变化,有时候同一人的外观看上去可能区别很大,这意味着并非所有高级语义特征都对小目标有帮助。我们在特征金字塔网络(FPN)[13]的基础上,将辅助网络的语义合并到主网络的相应层,使得高级语义与浅层网络充分融合,有助于主网络的特征提取。
在表2中,随着FAM的两个组成部分的增加,原始模型的准确性得到了显著提高。我们的方法实现了检测的准确性,在困难子集中分别提高了39.1%和1.2%,这与我们的设计目标是一致的。
3.5.2 锚框密集化
通过使用复合Anchor比例,我们设计了三种不同的单阶段人脸检测网络的Anchor比例,其中两个充当辅助监督,从而提供更稳定和更好的训练来服务主网络的特征提取。
我们进一步基于FAM分量采用复合锚框密集化进行分类和回归。在我们的实验中,将度量学习与Lcal一起使用,可以改善3个子集的平均精度得分,即Facebox上分别为95.1%(容易),93.3%(中等)和89.5%(困难),DSFD(VGG)在我们方法的模块上,3个子集的平均精度得分分别为96.4%,94.8%和90.3%。
从表2中可以看出,我们的CFANet可以进一步使轻量级模型和最新模型受益。

表2 不同模块的对比研究Table 2 Comparative study of different modules
4 结语
异构网络如果符合多样性与互补性,融合后的模型的特征提取能力将有较大提升。我们提出了一种“互补特征增强网络”(CFANet)的新颖框架,以解决基于单次多盒的微小人脸检测模型的性能普遍不理想的问题。一方面,由不同网络生成的FAM集成了丰富的语义特征,从而迫使新的特征更加易于区分。另一方面,在异构网络中引入了距离度量学习,可以融合有效特征并丢弃冗余特征。通过在基准数据集上的广泛实验,证明了我们方法的优越性。
