基于条件随机场的中医临床医案症状命名实体抽取研究*
2020-03-13高佳奕谢佳东史话跃董海艳胡孔法
高佳奕,刘 震,杨 涛**,谢佳东,史话跃,董海艳,胡孔法
(1. 南京中医药大学人工智能与信息技术学院 南京 210023;2. 南京中医药大学第一临床医学院 南京 210023)
1 引言
中医临床信息抽取是从临床医案中自动抽取特定信息的计算机技术,是从海量中医临床数据中快速发现关键信息,并将其自动分类、提取和重构的过程[1],包括命名实体识别、事件抽取、关系抽取等[2]。医案是中医临床诊疗的记录,蕴含着中医专家丰富的学术思想与临床经验,深入挖掘其中的知识对中医的传承与发展至关重要。然而,临床上病情千变万化,专家表述各具特点,使得医案的文字表述极其复杂,这给从医案文本信息抽取带来挑战[3]。因此,如何从海量中医医案中有效地抽取关键信息,挖掘其中蕴藏的辨证规律和潜在的数据价值,已经成为中医药研究的热点之一。本文尝试从医案中最为复杂的症状入手,利用自然语言处理技术进行症状命名实体的识别和抽取,为中医临床文本医案自动化处理提供参考。
2 命名实体抽取研究现状
命名实体抽取是自然语言处理领域的重要研究内容,在机器翻译、知识问答等领域取得了良好效果,但在医药领域的研究尚处于初级阶段[4]。自2000年起有学者陆续将基于词典、规则的方法应用于医药实体的信息抽取,如徐梓豪等[5]利用医学专业词典设计相关统计模型,在中文临床病历的命名实体识别中取得了良好效果;包小源等[6]设计定制化的规则学习及信息抽取方法,通过抽样标注、模板重写以及自动验证等步骤,进一步探究了非结构化电子病例中信息抽取方法。Szekér S 等[7]提出基于文本挖掘的命名实体识别方法,实现了超声心动图检查中的信息提取。基于词典、规则的方法虽然可以提高命名实体识别率,但是在应用于特定领域时[8],现有的规则往往不可移植,仍需依靠人工编写,过长建设周期使得它们的可行性较低。
自动内容抽取(Automatic Content Extraction,ACE)评测会议从多种角度对信息抽取进行了探索,在ACE 会议的推动下,其研究深度和广度也在不断加强[9]。近年来,一些学者尝试利用统计学习方法进行命名实体抽取,如Liu 等[10]应用支持向量机(Support Vector Machines,SVM)的分类模型,将医学实体之间的语义关系分类为相应的语义关系类型并抽取出语义关系三元组;马民艳等[11]基于单分类器的生物医学命名实体识别,采用最大熵算法(Maximum Entropy,ME)和条件随机场算法(Conditional Random Field,CRF),对Yapex 语料中的蛋白质名称进行了识别;刘凯等[12]基于CRF 探究中医病历命名的实体抽取方法,提出利用Bubble-Bootstrapping 算法、前向最大匹配算法和手工标注相结合的方式构建中医语料库,其中表现最好的命名实体抽取的F1值为症状0.80,疾病名称0.74,诱因0.63;王世昆等[13]通过比较CRF、SVM 和ME算法在中医古代医案中的症状与发病机制上的实体识别表现,发现CRF 更具优势,其中CRF 的准确率87.16%,ME 的准确率为83.88%,SVM 的准确率仅为81.92%。袁玉虎等[14]应用CRFs 模型对中医现病史中的症状术语进行实体抽取,发现CRFs 模型在症状术语的序列标注任务中表现良好。上述研究在医药信息抽取上作出了有益探索,但在中医临床复杂症状的命名实体识别和处理的研究较少。从研究方法来看,基于CRF 及其改进方法的应用逐渐成为当前命名实体识别研究的重要方向。
条件随机场是用来标注和划分序列结构数据的概率化结构模型[15]。其通过隐含变量的马尔科夫链Y ={y1,y2,…,yn} 和可观测状态的隐含变量X ={x1,x2,…,xn}的条件概率P(Y|X)来描述模型[4]。测试集语料标签的类别标记即为隐含变量,训练集的语料特征即为可观测状态,条件随机场通过可观测的语料特征推断每个标签应有的类别标记。本文尝试将CRF应用到中医临床医案数据处理中,构建中医症状命名实体抽取模型,探究CRF 在中医症状命名实体识别上的效果,为中医临床复杂文本的信息抽取提供参考。

图1 CRF链式结构图
3 研究方法
3.1 中医医案CRF模型设计
设G = V,E 为一个无向图,V 表示症状结点集合,E 为症状与症状之间的无向边集合。V 中每个症状结点与对应一个随机变量Yv,设其取值范围为标识集合Y,即Y ={yv|v ∈V }。如果以观测序列X 为条件,每一个随机变量Yv都满足以下马尔可夫性[16]:

则(X,Y)构成一个条件随机场。其中n(v)表示结点v的所有相邻结点,即V{v} = V -{v},换而言之,yv仅与结点v 邻接的结点相关。其中X,Y 的CRF 链式结构图如图1所示。
在条件随机场中,我们定义一组关于观测序列{0,1}二值特征b(X,i)来表示训练样本中症状的分布特性,如:

转移函数定义为如下形式:

这样,特征函数可以统一表示为:
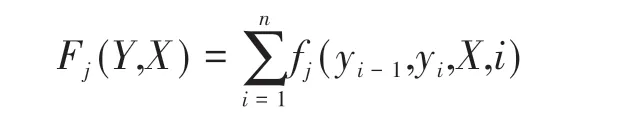
其中,每个局部特征函数fj(yi-1,yi,X,i)表示状态特征sk(yi-1,yi,X,i)或转移函数为tj(yi-1,yi,X,i)。
由此,中医临床医案CRF 的条件概率可以由下式给出,其中Z(X)为归一化参数:

3.2 中医医案CRF的训练流程
如图2 所示,模型训练需输入标注语料的模板序列。标注语料的模板序列存储了语料库中每一个语料标签的类别特征,其中语料标签可以采用基于字的标注方法,也可以基于词进行标注。考虑到中医临床术语大多按词出现,按字划分会损失中医术语本身包含的丰富信息特征[17],因此本文利用基于词的标注方法,采用BIO(B-begin,I-inside,O-outside)标注方法对数据进行标注处理[18],B-X 表示此元素所在的片段属于X 类型并且位于词首,I-X 表示此元素所在的片段属于X 类型并且位于非词首,O 表示此元不属于任何实体类型,其输入格式如下:

特征的选择是影响条件随机场模型训练结果的关键因素。训练语料的特征应囊括语料标签的词语特征、词位特征、上下文窗口特征等信息,本文选择词语标记、实体前后词语为主要特征,其输入格式如下:

4 实验及结果分析
4.1 数据来源
实验数据来源于江苏省中医院病案库和国医大师周仲瑛工作室,均为名老中医治疗肺癌的临床病案。设定病案纳入和排除标准,具体如下:
纳入标准:①病案中明确记载诊断为肺癌的患者;②就诊时的主诉辨治是以肺癌为主者;③数据完整,至少包含临床表现、病机分析和治法、用药等内容者。
排除标准:①其它系统癌症转移到肺脏患者,为非原发性肺癌如复发癌或者转移性肿瘤;②就诊时主诉辨治不是以肺癌为主者;③病案记录存在明确错误或缺失。
根据设定的病案纳入标准和排除标准对病案数据进行筛选,最终选择1000 份高质量病案进行研究,围绕病史进行症状命名实体识别。病史信息格式如下:“起病有胸闷,今年四月出现咳嗽,咳吐粘痰,痰色黄脓化疗后转为白粘,咳则胸痛,血象底下目前气短乏力,胸闷,纳差,大便1~2日一行,口干苦,饮水不多,体重下降8 斤,兼有低热,痰中血少,面色少华,贫血貌。”

图2 CRF命名实体识别流程

表1 命名实体标注方法
4.2 数据预处理
我们将数据集中的实体类型分为三类:症状(名)、(症状)程度、(症状发生)部位,代码分别为ZZ、CD、BW。利用BIO 三元集标注方法进行标注,具体的标注方法如表1所示。
依照BIO 标注方法,上述临床肺癌的原始病案可标注为:“起/O 病/O 有/O 胸/B-BW 闷/B-ZZ,今/O 年/O四/O 月/O 出/O 现/O 咳/B-ZZ 嗽/I-ZZ,/O 咳/B-ZZ 吐/IZZ 粘/I-ZZ 痰/I-ZZ,/O 痰/B-ZZ 色/I-ZZ 黄/I-ZZ 脓/IZZ,/O 化/O 疗/O 后/O 转/O 为/O 白/O 粘/O,/O 咳/B-ZZ则/O 胸/B-BW 痛/B-ZZ,/O 血/O 象/O 低/B-CD 下/ICD,/O 目/O 前/O 气/B-ZZ 短/I-ZZ 乏/B-ZZ 力/I-ZZ,/O胸/B-BW 闷/B-ZZ,/O 纳/B-ZZ 差I-ZZ,/O 大/O 便/O1/O~/O2/O 日/O 一/O 行/O,/O 口/B-BW 干/B-ZZ 苦/BZZ,/O 饮/O 水/O 不/B-CD 多/I-CD,/O 体/O 重/O 下/BCD降/I-CD8/I-CD斤/I-CD,/O兼/O有/O低/B-ZZ热/IZZ,/O 痰/B-ZZ 中/I-ZZ 血/I-ZZ 少/I-ZZ,/O 面/B-BW色/I-BW 少/B-ZZ 华/I-ZZ,/O 贫/B-ZZ 血/I-ZZ 貌/O。/O”。
4.3 模型构建
(1)提取1000条病历中80%的病历文本作为训练集,20%的病历文本作为测试集。
(2)根据语料特征构建特征模板。
(3)建立CRF 模型,采用十折交叉验证对模型效果进行测试。利用sklearn_crfsuite 开源包构建CRF模型。
(4)利用多分类评价指标对此模型进行评测。
模型建立的步骤如下:
条件随机场模型
输入:训练集T(800条病案)的特征序列及标注序列,测试样本t(200条病案)的标注序列。
输出:各标记标签的P、R、F1 值及Macro-averag‑ing、Micro-averaging值。
步骤1:根据T 的特征序列Tfea和标注序列Tsig,训练模型。

步骤2:根据测试样本t的标签特征序列预测标注序列tpre。
tpre= crf.predict(te_content)
步骤3:通过比较tpre与测试样本t 的标注序列tsig,得出多分类评测指标值。
4.4 模型评价
为了评估CRF 在中医临床医案中实现症状实体识别策略的可行性和其在症状实体抽取上的性能,本文使用准确率(Precision,简记为P),召回率(Recall,简记为R)和F1-测度值(F1-measure,简记为F1)3 个指标来衡量:

计算F 值时,一般取(β = 1),因此,以上公式可修改为:
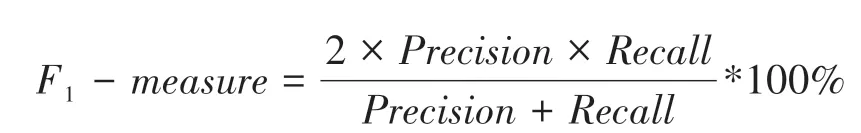
如图3 所示,准确率的实际意义为模型正确识别的标签数与模型识别的标签总数的比值,召回率的实际意义为模型正确识别的标签数与各类别中所有标签数的比值。
考虑到中医文本的分类并非单纯的二分类,需要在不同类别下综合考察分类器的优劣,此处引入宏平均(Macro-averaging)、微平均(Micro-averaging)对训练结果做出进一步评估。宏平均是计算每一个类别的评测指标值,再对所有类别的评测指标值取算术平均。宏平均定义式如下:

图3 评价指标

表2 十折交叉验证结果(均值± 标准差)

微平均是对数据集中的每一个标签不分类别进行统计建立全局混淆矩阵,进而计算相应的指标[19]。微平均定义式如下:

4.5 实验结果
本文采用十折交叉验证对模型进行训练和测试,观察模型对症状、程度、病位实体的识别情况,排除非命名实体组成部分,结果显示模型对症状词的识别精度最高,而对病位词的识别精度最低(详见表2)。
从十折交叉验证的结果来看,宏平均的三个评测指标(P,R,F1)为(0.8822,0.8322,0.8556),上下波动均小于0.022;微平均的三个评测指标为(0.9233,0.9222,0.9211),上下波动均小于0.007,微平均效果优于宏平均效果(详见表3)。每一折下各个评价指标的变化情况如图4~图6所示。

表3 十折交叉验证结果(均值± 标准差)

图4 评价指标折线图
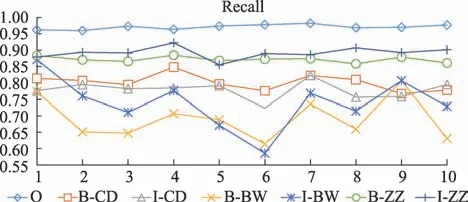
图5 评价指标折线图

图6 评价指标折线图

表4 实体标签中的可能传递方式
考虑到不同标签间的传递方式具有方向性,为了进一步查看模型内部的运行机制,本文将各实体标签的可能的传递方式以及标签传递权重进行了分析(详见表4~表5)。

表5 各实体标签传递方式的权重值
深入挖掘各实体标签和相应语料的关系,分析模型内部各个标签特征的权重,进而为模型解释提供支撑,本文对每个标签中权重较高的语料特征进行分析,分析结果详见表6。
为了增强类别特征,本文采用不同的窗口大小,对模型再次进行测试,不同窗口下的宏平均评测指标值如表7所示。
4.6 结果分析和讨论
本文提出了基于条件随机场的中医临床复杂症状的命名实体识别方法,对中医临床数据进行实验,模型宏平均的评测指标(P,R,F1)为(0.8822,0.8322,0.8556),上下波动小于0.022;微平均的评测指标为(0.9233,0.9222,0.9211),上下波动小于0.007(详见表2~表3、图4~图6),实验结果显示微平均的效果优于宏平均。从微平均和宏平均的实际意义进行分析,微平均实际反应的是预测正确的样本数与输入分类器的预测样本数的比值,而宏平均是将每个类别标记分开考虑,计算单独每个类别的正确率,反映的是每个类别标记正确率的算数平均值,因此小样本预测正确率低的情况对宏平均的影响较大。在本文采用的肺癌病例语料中,I-BW 和B-BW 均属于小样本,仅1119和1382 处,相比之下,B-ZZ 和I-ZZ 的样本数目较大,有7201 和11268 处,据图4~图6 也可以观察到I-BW和B-BW 的P、R、F1 值普遍偏低,这就对十折交叉验证的结果产生了影响,使得微平均的评测值优于宏平均;就标签的识别效果而言,症状词的识别效果较好,部位词的识别效果较差,因为症状词的训练样本数较多,类别特征相对明显,而部位词因为训练样本数过少,类别特征不明显,又常常和症状交叉混淆,如“胸闷胸痛”被识别为“B-ZZ/I-ZZ/B-ZZ/I-ZZ”,这就导致了二者识别效果差异较大。
通过深入挖掘不同标签间的传递方式,我们发现症状词与程度词间的关联度最高,即症状词前后出现程度词的可能性最大,其传递可能性高达0.9253。病位与其他标签间的关联性相对较弱,多呈现病位->症状,病位->程度这两种共现方式(详见表4~表5)。考虑到中医临床医案中往往以症状来描述部位的病变情况,以程度来形容部位的病变轻重,如“咯B-ZZ 痰I-ZZ 不B-CD 多I-CD”、“胸B-BW 不B-CD 闷BZZ”等,该分析结果与中医医案的陈述方式基本相符。深入分析实体标签和相应语料之间的权重,我们发现‘,’,‘、’等符号以及“但”、“仍”等语句连接词已被模型学习为非实体组成部分;病位多与“背”、“胸”、“口”、“腰”、“鼻”等词相关,其中“背”与病位的关联度最高;症状多与“咳”、“痛”、“痰”、“酸”、“闷”、“血”等词相关,其中“咳”与症状的关联度最高(详见表6)。从中医理论出发探寻数据背后的辨证知识,肺居胸中,左右各一,癌毒侵袭肺脏,往往出现 胸痛、背痛等症,正如《灵枢.邪气脏腑病形》所言:“肺脉……微热为肺寒热,怠惰,咳唾血,引腰背胸”;肺开窍于鼻,且肺为储痰之器,气机不利,外邪乘之,津聚为痰,痰瘀阻肺,则口鼻多痰;肺主气,司呼吸,肺失宣降,气滞于胸则出现咳嗽、胸闷等症。如《杂病源流犀烛》云:“邪居胸中,阻塞气道,气不得通,为痰,为食,为血,皆邪正相搏,邪胜,正不得制之,遂结成形而有块。”从上述结果可以看出,CRF 实体标签的学习结果与中医对肺癌的认识基本一致,因而可以将CRF 应用于中医临床复杂症状的命名实体识别。

表6 标签特征
通过改变窗口大小来进一步探索类别特征对于实验结果的影响。当窗口大小为5 时,宏平均的P、R、F1 值最高,较窗口大小为3 时分别提高了0.47%、1.35%和2.50%,较窗口大小为7时分别提高了2.56%、4.15%和2.65%(详见表7)。考虑到过大的训练窗口不仅使训练的复杂度增加,而且容易产生噪音影响最终的评测结果;较小的窗口难以反应上下文关系,会损失语料间的丰富信息,当窗口为5时,能够恰好反应上下文关系且不会产生过多噪音。从整体上观察,窗口大小对于评测指标的影响并不大,样本集中的标签分布不均衡对评测结果产生了决定性影响。因此,本研究后续将把重点将放在对样本集进行扩充和筛选,平衡各个类别,提高宏平均指标。

表7 窗口大小对宏平均评测指标的影响
5 结语
在中医临床的诊疗过程中,复杂多变的中医临床症状和表达形式独特的中医专业术语给中医临床的信息抽取带来了极大挑战。本文通过分析中医医案信息抽取的重要意义,对中医领域的信息抽取现状进行思考,提出了将CRF 模型应用于中医症状的命名实体抽取。从已标记过的肺癌病历语料库入手,构造基于CRF 的中医临床医案症状命名实体抽取模型,采用十折交叉验证对模型结果进行测试,利用多分类评价指标对模型进行评价,证实了CRF 模型在中医临床症状的命名实体识别中的性能较好,可以有效的实现中医文本的信息抽取。“中医之功,医案最著”,中医临床医案是辅助中医进行辨证用药的基础,抽取名老中医临床医案的有效信息,是中医药发展的基础,也是历史赋予我们的重任。将CRF 模型应用到中医临床症状的命名实体抽取领域,可以为中医临床工作者提供更便捷有效的信息抽取工具,提高中医临床医案的研究效率,为中医药信息抽取提供方法学参考。
