自然语言处理中的对抗攻击与防御研究综述
2020-03-08刘一廷宋珣
刘一廷,宋珣
(西安交通大学自动化系,西安710049)
自2014年以来,对抗样本在计算机视觉领域已经得到了广泛的应用,并取得巨大的成功。近几年,对抗样本在自然语言处理(NLP)中的应用引起广泛的研究兴趣。与图像领域相比,应用于NLP任务的对抗攻击方法既有相似的思路,也有其不同的特点。从多个角度综述应用于NLP的对抗攻防的最新进展,并探讨可能的研究方向。
对抗样本;安全;自然语言处理;深度学习;综述
0 引言
随着深度学习的发展[13],每年都会有大量更先进、更强大的模型被创造,用于解决计算机视觉(CV)和自然语言处理(NLP)任务。然而,尽管这些模型已经取得了巨大的成功,但是诸如文献[11]这样的研究表明,这些方法极易受到对抗样本的攻击。
对抗样本由输入数据加上细微的扰动形成,它能显著增加机器学习或深度学习模型的损失,并导致模型预测错误的输出[18]。原则是这样的扰动不能被人类轻易检测出,这在图像处理中相对容易实现。
然而,在NLP任务中,对抗攻击的目标变成了文本,则攻击模型还应满足两个额外的要求[4]:①语义相似性,根据人类判断,对抗样本不应改变原始样本的语义。②语言流畅,生成的语句应该是自然且可读的。这些要求导致了应用于图像的攻击方法无法直接用于文本。
此前,已有基于对抗样本在计算机视觉中的应用的综述工作(文献[1]),以及基于文本深层神经网的相关调研(文献[2])。与以往的调研相比,本文的贡献在于:①我们从攻防的角度进行了讨论,用一些典型的方法快速梳理了NLP任务中的对抗攻防相关概念;②介绍了近年来该领域的一些突破性工作,为感兴趣的研究者提供参考。
在接下来的章节中,我们将讨论近年来成功应用于NLP任务的几种突出且极具影响力的对抗攻击方法。之后我们将介绍几种有效地针对此类攻击的防御措施。
1 对抗攻击
对抗攻击的目的是使目标模型误判输入,产生错误的输出。这里我们使用最常用的分类方式,根据攻击者对模型的了解程度,将NLP中的对抗攻击方法分为两类:白盒攻击与黑盒攻击。
1.1 白盒攻击
白盒攻击假设攻击者对模型有完整的背景知识,包括模型的结构和参数。这种类型的攻击通常以启发式的方式产生对抗样本。
考虑到白盒攻击的严格条件,其应用范围并不如黑盒攻击广泛。本文介绍了基于FGSM的攻击方法的基本思想,以及一种很有前景的通用型攻击方法。
(1)基于FGSM的方法
快速梯度下降法(FGSM)是计算机视觉领域最早使用的白盒攻击方法之一[14]。与其他基于梯度的方法一样,它通过增加损失来攻击目标模型。
假设模型对输入的梯度方向如下:

其中θ是模型的参数,x是模型的输入,y是x对应的标签,L( )θ,x,y是用于训练模型的损失函数。理想扰动必定沿梯度方向一直到损失函数的最大值,因此我们可以通过以下公式得到样本的扰动η:

其中ϵ是学习率。
这种攻击方法起作用的根本原因在于,扰动在神经网络中的效应在前向传播过程中会如滚雪球一般,变得越来越强,对于线性模型尤其如此。
然而,计算机视觉中使用的FGSM算法并不能直接用于生成NLP任务的对抗样本。因为计算机视觉中使用的数据是连续的(图像),可以容忍微小的扰动。而在NLP任务中,数据是离散的(文本)。正如文献[14]所发现的,如果直接使用FGSM方法,文本将变得不可读。
为了解决这个问题,文献[14]仅利用FGSM查找最高频的短语(HTPs),并通过计算梯度来识别对当前分类(HSPs)有重要贡献的文本项,然后使用三种策略:插入、修改和删除来生成对抗样本。由此成功地将FGSM方法应用到文本分类任务中。

图1三种攻击策略的结合[14]
图1 为文献[14]中的一个攻击实例,通过移除高频短语(“historic”),插入伪造事实(“Some exhibitions of Navy aircrafts were held here.”)和修改重要贡献文本项(“cast1e”),可以成功地改变输出分类的结果(从83.7%的可能结果为建筑,到95.7%的可能结果为运输工具)。
这种方法的主要问题在于,在生成对抗样本时需要一定的人工,这对于一般攻击来说是可以接受的,但不适合更复杂的场景。
(2)通用型方法
典型的对抗攻击方法通常是针对特定类型的输入生成的,我们能否找到一种通用的方法,能够针对不同的输入,更加容易地将其移植到不同的模型中?
基于这一思想,文献[7]提出了攻击不同模型的通用型对抗触发器,它对文本分类、阅读理解、文本生成等许多常见的NLP任务都有很好的效果,并击败了著名的GPT-2等强大的模型。
作者假定能对特定模型进行白盒访问(在某些条件下也可转为黑盒模型)。目标是找到这样的触发器:当拼接到任何输入的前端或末尾时,可以引导模型做出错误决策的单词序列。受文献[8]的启发,作者通过更新触发器的每个单词的词嵌入向量(embedding)eadvi来搜索目标触发器,以最小化当前词嵌入向量的损失的一阶泰勒近似:

其中V是模型词汇表中所有词嵌入向量的集合,∇eadvi L是批处理中模型损失的平均梯度。而每个eadvi对应的单词正是目标所需的单词。

图2 触发器搜索算法示例[7]
以情绪分析任务为例。触发器搜索算法的示例如图2所示。作者试图使模型将积极情绪语句判断为消极情绪。经过多次迭代,找到了对判断负面情绪非常有利的zoning、tapping、fiennes组合。
结果是,无论使用何种的词嵌入方法(如ElMo[20]、GloVe[17]),或是何种网络模型(如self-attention[21]、Bi-LSTM[23]),所有这些模型都不能幸免。
1.2 黑盒攻击
另外,与白盒攻击的严苛条件不同,黑盒攻击只要求攻击者能够用提供的输入访问目标模型,并获得相应的输出。以下介绍两类不同思路的黑盒攻击方法。
(1)拼接式对抗
自动问答(QA)任务是从给定的文本段落p中得到问题q的答案a,则相应的数据结构为(p,q,a)。一个模型在QA任务中表现得很好,可能不是因为它理解了问题及其背后的深层现象,而是因为它能识别出一些恰好对大多数测试样本具有预测性的模式。
受此启发,文献[3]提出了一种拼接式对抗攻击,在样本中插入分散注意力的语句来欺骗阅读理解系统。这种攻击没有依赖于保持原始语义的扰动,而是通过使目标模型无法区分实际回答问题的语句和只有相同单词的语句来欺骗模型。
拼接式对抗攻击试图通过在段落末尾添加一个新句子s来创建对抗样本(p+s,q,a),即不改变问题与答案。
在文献[3]中,作者提出了一个名为ADDSENT的生成s的流程,如图3所示,将问题中一些特意抽取的名词和形容词替换为WordNet[16]中的对应的反义词,而命名实体和数字则被其在GloVe词向量空间中最近的单词替换[17]。
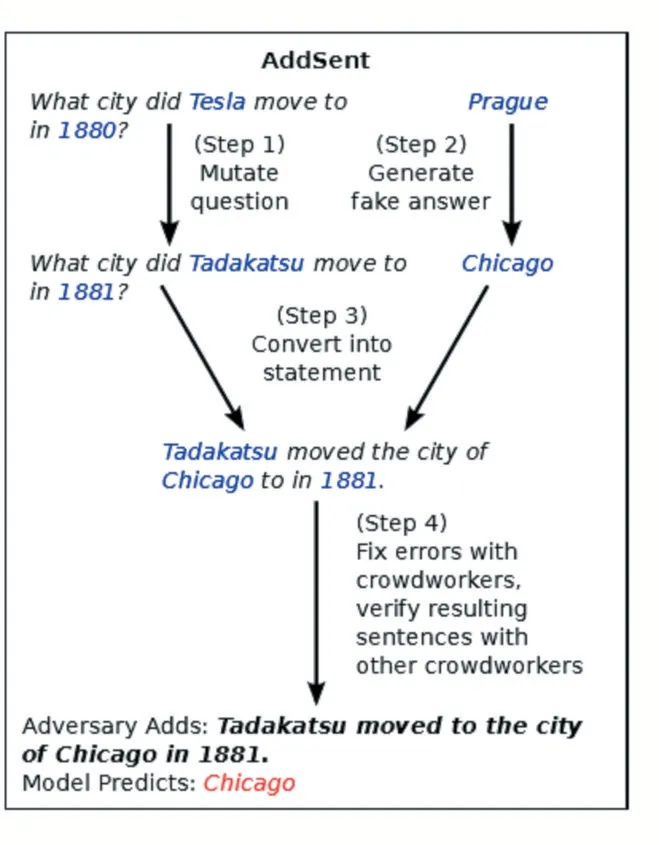
图3 一个ADDSENT对抗示例[3]
作者将这种方法应用于SQuAD QA数据集[22],发现还没有任何开源模型对这类对抗语句是鲁棒的,这表明这些看起来效果很好的模型其实并不能真正准确地理解问题。
(2)同义词转换攻击
尽管采取了各种缓解措施,但上述拼接对抗攻击仍会在对抗样本中生成明显不自然的句子。
在文献[4]中,作者基于近年来最具突破性的NLP模型之一BERT,提出了一种简单而有效的黑盒攻击TEXTFOOLER,以生成在文本分类任务中诱使目标模型做出错误决策的样本。
给定一段文本,只有其中最重要的词才能影响模型的判断。通过仅对这些词进行攻击,就能在达到攻击目的的前提下,实现最小的扰动并最大程度保留原文语义。基于这一思想,同义词转换攻击的过程相当清晰:首先得到单词的重要性排序,然后使用同义词抽取机制替换选中的单词。该方法的一个示例如图4所示。
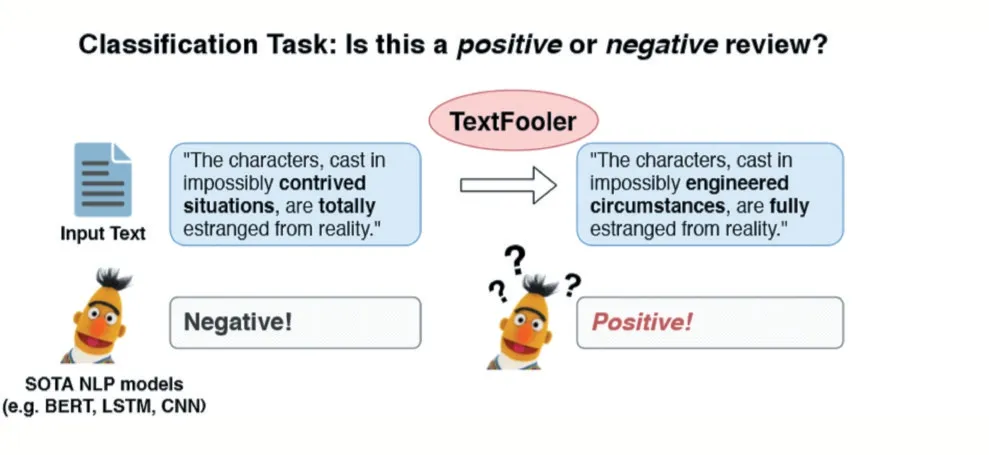
图4 TextFooler攻击的示例[4]
在文献[4]中,作者通过下式计算单词wi的重要性IWi:
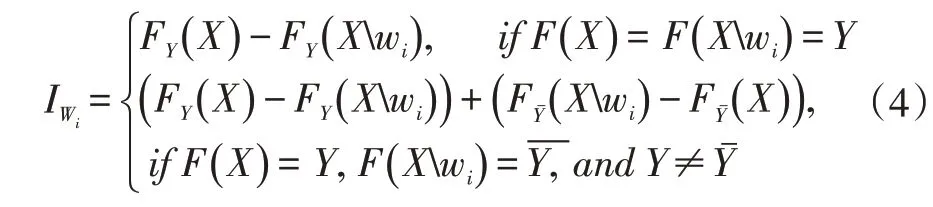
其中F是预测模型,X是给定的语句,Y是X对应的标签。
根据wi与词汇表中其他单词之间的余弦相似性,选取N个最接近的同义词初始化候选集。再通过计算原始语句与其经候选集中的单词替换wi之后的语句的相似度,可得到最终的候选集。
在不知道模型结构、参数或训练数据的情况下,该方法通过重要性计算和单词转换操作成功生成了对抗样本,同时保留了语义内容、语法正确性,并保持了人工分类结果不变。实验表明,该方法在攻击成功率上优于以往的攻击方法。
2 防御方法
研究对抗攻击的主要目的之一是提高模型的鲁棒性,防止恶意攻击。这也是为什么随着NLP中对抗性攻击模型的不断发展,相应的防御方法也不断涌现。
在本节中,我们将重点讨论一种名为对抗训练的常见防御方法以及最近提出的一种无特定结构防御模型。
2.1 对抗训练
对抗训练(AT)是一种正则化学习算法。它被广泛应用于图像领域的对抗攻击。AT的防御策略非常简单:通过在训练过程中对输入添加扰动,深度神经网络(或其他模型)可以获得容忍对抗样本影响的能力,从而能正确地将正常样本和对抗样本区分开来。文献[18]表明对抗训练可以在使用dropout操作的基础上额外提供一个正则化收益。
文献[9]是将AT应用到文本分类任务中的第一次尝试之一。其将扰动引入到模型输入的词嵌入向量中,并将生成的对抗样本进行训练以提高模型对攻击的鲁棒性。文献[6]则将相似的方法应用到文本理解任务中。结果表明,对抗样本的攻击成功率降低,而模型对原始输入的性能没有太大变化。
也有一些工作利用不同的机制扩展基本的对抗训练方法。文献[10]聚焦于机器阅读理解中的对抗攻击和防御。作者不仅在输入中引入了扰动,而且在模型的每一层都采用了AT。此外,考虑到阅读理解的关键是问题与相关段落之间的映射关系,作者还引入了多层注意力网络。通过消融实验,作者得出结论:与简单地用扰动输入进行训练相比,对深层变量进行AT更能提高模型的鲁棒性。
然而,使用AT的前提之一是要有足够的对抗样本,而要做到这一点,我们首先需要知道攻击策略。显然,期望攻击者公开自己的攻击策略通常是不现实的。因此,这种方法是相当局限的。
2.2 随机平滑
如前所述,对抗训练需要提前了解攻击策略。而其他诸如基于IBP的防御等方法也局限于特定的输入或模型结构。为了解决这个问题,文献[5]提出了一种无特定结构的防御机制,它适用于可以黑盒方式访问的任意模型。
该方法的主要思想是通过建立在同义网络上的随机单词替换来平滑原始模型。给定一个原始的文本分类器f,目标是找到一个满足以下条件的新模型fRS:
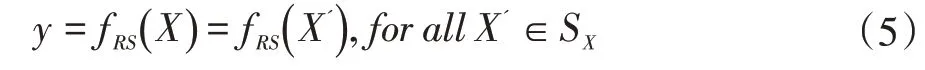
其中,SX是一个对抗样本集合,该集合中每个句子X'都是通过用同义词随机替换原句X中的几个单词而得到的。
文献[5]以无结构方式构建此模型,如下所示:
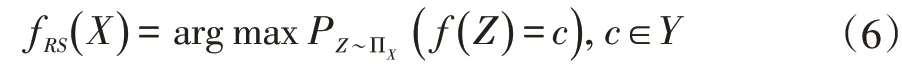
其中ΠX是X扰动的分布。
在这种随机平滑防御方法中,几乎所有可能的扰动都被以统计的方式考虑在内,则新模型理论上能够抵抗所有同类攻击。
这种方法的另一个显著优点是它没有特定的结构,这意味着它可以轻易地应用于任何预训练模型。在IMDB和其他数据集上的实验表明,该方法是相当有效的。
3 讨论
尽管近年来提出的大量新模型在文本分类、机器阅读理解、自动问答等自然语言处理任务上取得了重大突破,但它们的易受干扰性仍然不能忽视。显然,对抗样本所带来的模型安全问题的研究仍处于起步阶段。
正如文献[3]中提到的,当前许多工作中的一个共同问题是产生对抗性样本的过程对人工操作的要求。人力的介入不仅使攻击过程变得耗时,也让攻击本身不切实际。
另一个问题是对抗攻击及其防御方法的可解释性。尽管我们已经知道扰动会给模型带来严重的破坏,但仍然有一个问题需要我们回答:对抗样本背后的深层机制是什么。对这一问题进行更深入的研究,可能有助于我们从根本上解决对抗攻击的威胁。
最后,攻防手段的泛化能力也应该得到重点关注。理想模型的应用不应局限于某个任务或某个领域,这与模型的实用性息息相关。然而,现有的方法在实验中普遍存在泛化能力较差的问题。虽然一些黑盒方法已经成功地移植到了不同的模型和数据集上,但是它们的性能远远低于原始的模型和数据集。
因此,基于以下两个原因,一个可以预见的趋势是,对通用型攻击方法的研究将会显著增加:①通用型方法不需要攻击者掌握目标模型的结构和参数等关键信息;②该类攻击方法可以大大降低攻击者的专业门槛,从而使跨领域攻击变得更加容易。
4 总结与未来方向
本文提供了对抗攻击及其防御方法在自然语言处理领域的应用的概括性介绍。如前所述,考虑到文本的离散性及其语义不变性的要求,对文本对抗攻击与防御的研究比图像领域更具挑战性。
未来,类似文献[7]这样更具普适性和易迁移性的对抗攻击将成为研究热点。相应地,如文献[5]中所述可用于NLP多任务的通用防御方法也将成为主流。
更高的模型安全威胁可能迫使研究人员在设计模型时更多地重视其安全性能,而不是仅仅关注精确度提高了多少。从这个角度来看,NLP领域的对抗攻防还有很大的探索空间。
本文旨在为后续研究者提供相关参考。我们希望在不久的将来,更多足够健壮的模型能够被提出。因为这不仅关系到模型在实验中的性能,更重要的是其在实际应用过程中给用户带来了安全问题。
