基于Solr的商品搜索功能及其优化
2020-03-08许祥余立毅
许祥,余立毅
(景德镇陶瓷大学信息工程学院,景德镇333403)
Solr;Lucene;商品搜索;HanLP;布隆过滤器
0 引言
网络购物已经成为了人们日常的消费习惯,在这些购物应用中,产品搜索是它们的必备功能,搜索能够帮助用户更快更准确地找到自己需要的物品,保障购物体验。Solr是一个独立的企业级搜索引擎服务器,它是以Lucene全文检索技术为基础构建的Web应用,能够快速地提供检索服务。Lucene是一个成熟的信息检索程序库,它在全文检索领域、文本相似度计算领域以及构建搜索引擎方面都有广泛的应用。由于使用传统数据库的应用系统在商品搜索效率和结果上都无法满足日益增长的数据访问量,因此针对商品搜索所需要的快速、精准、高效的设计需求,通过对全文检索[1-4]尤其是垂直搜索技术[5-6]的研究,利用关键词过滤、中文分词器和改进商品默认排序,实现一个能够满足小型商品搜索的通用化引擎。
本文利用Solr将商品数据库中的数据进行索引,构建索引库,搭建初始Web应用系统。使用布隆过滤器减少直接查找索引库的索引词次数,优化索引效率。根据设计需求修改Lucene的排序[7-8]机制,简化内部搜索过程,自定义商品排序,进一步加快检索速度。在最后的实验环节,系统能够快速地提供商品搜索服务,取得了不错的效果。
1 全文检索技术的部分改进
1.1 关键词过滤
布隆过滤器(Bloom Filter)[9]是1970年由布隆提出的。它实际上是一个很长的二进制向量bitarray和一系列随机映射函数Hash,用于解决单个Hash的冲突问题。假设一种bitarray长度为m,有k个哈希函数,且每个哈希函数的输出范围都大于m,接着将输出值对m取余(%m),就会得到k个[0,m-1]的值,由于每个哈希函数之间相互独立,因此这k个数也相互独立,最后将这k个数对应到bitarray上并标记为1。等判断时,将输入对象经过这k个哈希函数计算得到k个值,然后判断对应bitarray的k个位置是否都为1,如果有一个不为1,那么这个输入对象则不在这个集合中;如果都是1,那说明在集合中,但有可能会误,由于当输入对象过多,而集合也就是bitarray过小,则会出现大部分为1的情况,那样就容易发生误判。所以它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
假设输入对象个数为n,bitarray大小(也就是布隆过滤器大小)为m,所容忍的误判率p和哈希函数的个数k。计算公式如下:

使用布隆过滤器预先判断单词是不是在该索引库里。在系统启动之后,读取Lucene索引库中的所有词条,将它们加载进布隆过滤器对象中,完成BloomFilter对象初始化。在每次搜索关键词时,都会先使用BloomFilter判断关键词是否在Lucene索引库中。
这里设定布隆过滤器的误判率p为0.01%,商品信息个数n为1100000,经过计算得出哈希函数个数k为14,布隆过滤器bitarray大小m为2574.11KB。
1.2 中文分词器
中文分词是中文文本处理的一个基础步骤,也是全文搜索技术的核心关键之一,分词效果的好坏以及效率直接关系到搜索引擎的综合表现。目前,常见的中文分词器[10]大致可归纳为:词典分词方法、理解分词方法、统计分词方法、组合分词方法。其中,组合分词方法[11]是利用各个方法的优点,弥补方法的不足,组合部分方法以更好地解决分词问题。
Lucene自带的中文分词器,包括StandardAnalyzer和CJKAnalyzer。前者是单字分词,就是按照中文一个字一个字地进行分词;后者是二分法分词,即按两个字进行切分。上边两个分词器无法满足对中文的需求。
HanLP中文分词器具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。默认模型训练自全世界最大规模的中文语料库,同时自带一些语料处理工具,帮助用户训练自己的模型。目前支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统。
1.3 商品排序
商品排序其实就是计算搜索关键词和所有物品的相关程度,关联程度计算就是排序,Lucene会对分词列的精确查询条件进行打分。打分排序[7-8]是搜索引擎重要一部分,能够评判查询条件和文档的匹配度,提高检索质量。打分过程会消耗额外I/O、需要更多CPU计算、加载整个倒排表,拖累了查询速度,特别是在文档数非常多的情况下。而在商品搜索的需求中,用户只关心那些和搜索关键词高度相关的商品信息,对于相似度低的商品并不需要显示出来,所以系统过滤掉低相似度的商品,减少参与排序的商品数量,降低时间复杂度。在系统查询开始阶段,设定相似度最低阈值score。
目前对于相似度最低阈值的设定没有可供参考的资料,而且相似度值会根据不同的关键词、关键词数量、文档长度、文档内容等因素得到0-1之间的任意数值,所以最低阈值score设定为固定值显然不合适,必须是一个动态的值。参考Lucene在计算相关度得分的算法BM25[12],算法公式如下,可以针对不同查询关键词利用该公式计算出得分的最大值和最小值,取20%作为相似度最低阈值score。

其中N为索引中的全部文档数,n(qi)为包含了qi的文档数,这两个值都是可以从索引库读取的;k1、b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,也就是关键词在商品名称中出现的次数,取值一般是0-3;dl为文档d的长度,avgdl为所有文档的平均长度,这两者商的取值区间如下公式所示,取值一般是在0.6-1.5。

其中m表示文档d长度的最大值,n表示文档d长度的最小值,根据分析,m大约是n的2倍左右。
2 系统设计与实现
2.1 数据库设计
数据库中的商品表products结构如表1所示,其中选取字段pid、name、catalog_name、price、description和picture映射为索引库字段id、prod_pname、prod_catalog_name、prod_price、prod_description和prod_picture,根据这6个字段将数据从数据库导入到索引库中。

表1 products表结构
2.2 数据准备
为了实现通过索引库加快商品搜索效率的需求,将关系数据库中的数据导入到Solr,从而构建起商品数据索引库,由查询数据库转变为检索索引库。构建索引库过程中,考虑到数据库搜索的结果就是“表”中若干“元组”的集合,可以把“元组”的集合看作是倒排表中的文件链表,这样通过关键词找出对应的文件集合,也就是过滤出符合关键词条件的“元组”集合。
使用Solr服务器的dataimport工具将MySQL数据库中的商品表products导入到索引库。一般来说,商品搜索关键词只出现在商品的名称信息当中,所以对“商品名称”字段进行索引。
2.3 系统结构与实现
商品搜索系统是基于Tomcat服务器、SpringMVC框架、MySQL数据库和Solr搜索引擎等。设计结构主要由数据层、业务层和客户层组成,数据层包括存储原始数据的MySQL数据库和存储索引文件的Lucene索引库;业务层主要是由Solr Core实现的索引和搜索两个功能,预先构建、更新索引库,搜索时先将查询关键词经过布隆过滤器的预判,然后查询索引库,获取商品信息;客户层也就是系统界面,接受用户的查询请求,并将查询结果展现在页面当中。整个系统的运行流程都由SpringMVC进行控制管理,构建索引库以及分析搜索语句都需要HanLP中文分词器的参与。
用户除了能够通过搜索框查询商品之外,还可以点击分类浏览特定类型商品,选择一定价格区间的商品,对商品价格排序等。
3 实验结果分析
为了分析比较基于Solr搜索服务器的本系统和基于MySQL数据库的传统SQL模糊查询的性能差异,预先准备了11万条商品记录的测试数据集,还有用于搜索的7个存在的商品词和1个不存在的商品词,针对这8个商品词分别使用本系统进行直接搜索和使用SQL语句“select*from products where pname like'%关键词%';”进行模糊查询,对比两者的检索时间和检索数量,实验硬件环境Intel Core i5 2.3GHz、8GB内存,得出如表2所示的实验数据。
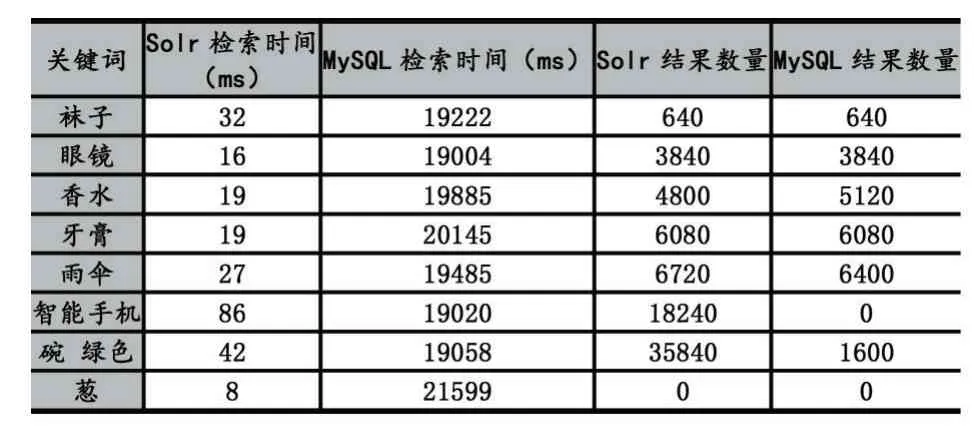
表2 基于Solr检索和数据库模糊检索的结果对比
对比基于Solr搜索和基于MySQL数据库模糊查询的实验结果,发现两者在检索时间方面差别较大,结果数量上差别较小。基于Solr搜索的时间基本在100毫秒以内,完全能满足用户对实时性的要求,而基于MySQL数据库模糊查询的时间大约在20000毫秒上下,两者在检索时间上相差200多倍,所以通过利用Lucene全文检索索引库技术,商品搜索效率得到了极大提高。观察实验结果,发现搜索关键词“袜子”、“眼镜”和“牙膏”,虽然两种方式的搜索结果数量一致,但是Solr检索速度快很多。通过对比各关键词的Solr检索时间,当检索词是最小分词时,其搜索时间会比较短;当检索词包含多个最小分词,如“智能手机”、“碗绿色”,其搜索时间相对会长些。而对比各关键词的模糊查询时间,其检索时间与检索词长短关系并不大,这其实是由于模糊查询是对数据库所有商品信息记录进行逐字匹配,所以耗时基本相差不大。最后,对于不存在的商品进行检索,两者的结果数量都为0,但是本系统采用了布隆过滤器,预先判断商品不存在,避免查询索引库,减少了检索时间。总的来说,基于Solr搜索服务器的检索性能比基于数据库的检索性能要高出很多。
4 结语
通过对Solr搜索引擎和底层的Lucene检索库的研究,并根据商品搜索的实际需求分别对排序、关键词过滤实现了优化,构建出较为完整的商品搜索系统。经过实验的对比分析,得出系统实现了正常运行,更为重要的是性能较传统数据库的查询性能提升非常明显,说明系统的设计达到了最初的目的。
