基于GoogLeNet Inception V3的迁移学习研究
2020-03-04薛晨兴邢家源
薛晨兴,张 军,邢家源
(天津职业技术师范大学 电子工程学院,天津 300222)
0 引言
随着计算机领域的迅速发展,机器学习在实际应用和理论探讨2个方面都取得了巨大进步[1-3]。为了保证分类模型的训练结果具有可信的分类效果,传统的机器学习方法一般假设数据的特征结构不随环境改变[4],即要求源域的数据和目标域的数据具有相同的分布。然而在实际应用领域中,如交通、人机交互、生物信息和自动控制等,这一假设通常由于严格的机制而不成立。迁移学习(Transfer Learning,TL)[5-8]的出现打破了这一局限,只要源领域和目标领域之间有一定相关性,分类模型训练时就可以借助从源领域的数据中提取的特征知识,实现已学习知识在相似或相关领域间的复用和迁移,使传统的从零开始学习变成可积累学习,不仅可以缩减训练模型的成本,而且可以高效地实现目标分类。本文主要基于Inception V3参数的迁移学习对图像分类,通过TensorFlow框架对Inception V3迁移学习的过程和结果分析
1 卷积神经网络与迁移学习
1.1 卷积神经网路的发展
1986年,反向传播算法(BP)算法[9]提出,几年后LeCun利用BP算法训练神经网络识别手写邮政代码,成为卷积神经网络(CNN)的开山之作,1998年LeNet5模型提出,CNN面世。2012年,AlexNet模型在ImageNet比赛中,取得第一的成绩,在此之后更多更深的CNN模型提出。2014年,GoogLeNet模型在2014年图像网络大型视觉识别比赛(ILSVRC)获得冠军,成为CNN 分类器发展史上的一个重要里程碑。本文主要基于此模型系列的Inception V3进行迁移学习 。
1.2 GoogLeNet
GoogLeNet的核心思想在于增加网络深度和宽度,来提高CNN网络性能。在增加神经网络宽度方面主要采用深度卷积网Inception,如图1所示,这一特色网络结构即保持网络结构的稀疏性,又利用了密集矩阵的高计算性能。

图1 Inception 结构图Fig.1 Structure diagram of Inception
Inception V1是Inception网络的第一个版本,作者提出的这深度卷积神经网络Inception,该架构的主要特点是更好地利用网络内部的计算资源,此外该设计允许增加网络的深度和宽度,同时保持计算预算不变。为了优化质量,架构决策基于赫布原则和多尺度处理[10]。
2015年作者通过一系列能增加准确度和减少计算复杂度的修正方法,在论文[11]提出了Inception V2 和 Inception V3。其中inception V2将5*5的卷积分解为2个3*3卷积运算提升计算速度,如图2所示。

图2 Inception2 结构图Fig.2 Structure diagram of Inception2
此外作者将n*n卷积核尺寸分解为1*n和n*1两个卷积,使滤波器的组变得更宽,已解决表征性瓶颈。
Inception V3整合了inception V2的所有优势,与V2对比,其最主要的不同就是提出了Batch Normalization,目的主要在于加快训练速度。Inception V3使用了RMSProp优化器,此优化器是Geoff Hinton 提出的一种自适应学习率的方法,参数更新方式如下所示,其中学习率η一般设为0.001。
梯度更新规则:
(1)
式中,E的计算公式为:
(2)
1.3 迁移学习
在文献[12]中,pan等人准确的定义迁移学习,如下:
2 基于GoogleNet Inception V3的参数迁移学习模型
2.1 Inception V3的模型简介
本文主要是在Inception V3的模型上进行参数迁移学习,其模型如图3所示,其中mixed模块就是Inception网络的结构。
本次实验基于Inception V3 的参数偏移学习是只替换训练分类层而保留源模型的全部特征提取能力。由于图像的底层纹理特征通用的特点,在进行迁移学习时可以相对保留卷积模块的参数与结构,并设置一些深度卷积层或者全连接层可训练状态。将数据放入目标域中的重构模型中进行再次训练时,由于可训练参数继承自源模型,因此模型在微调时并不是从随机初始值开始梯度下降,通常模型经过小幅度的步伐调整后就可以达到适用于重构模型的最优值,使重构模型可针对目标样本自适应地调整高层的参数从而提高目标检测能力[14]。

图3 Inception3 结构图Fig.3 Structure diagram of Inception3
2.2 模型改进方法
为了扩展网适用性,如图4所示。

图4 模型修改图Fig.4 Modified map of the model
本文加入了一个新的网络模型替换了原来的分类模块,这个新模型由前向传播和反向传播两部分组成。前向传播主要是将通过迁移学习的策略保留了pool_3及以下的卷积层和池化层参数等提取的特征传递给输入层,随后分类的值与标签(Label)差值求loss值,而反向传播主要是为了更新全连接层的参数,尽量减少loss值。其中本次模型将交叉熵代价函数[15]作为损失函数loss,其公式为:
(3)
式中,C为代价函数;x为样本;y为实际值,a为输出值;n为样本总数。在图像分类时,Softmax函数表示将图片识别为特定类的概率,其公式如下:
(4)
整体模型如图5所示,首先将数据喂入特征提取模块,该模块使用的是经过大量数据训练好的参数,随后将提取特征模块输送到分类层(重建网络模块),仅仅需要更新全连接层的参数进行分类。图5上半部分可压缩高度,下半部分那两行方框可左右对齐,这样图字就不挤了。
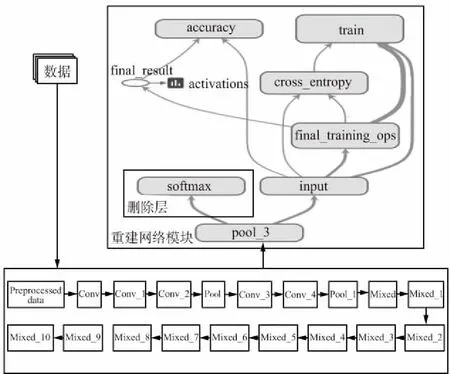
图5 整体流程图Fig.5 Overall flow chart
3 实验结果与分析
本文所有实验均在TensorFlow框架上实现,硬件平台为 Intel(R) Core(TM) i3-4010 cpu,主频为1.7 GHz,内存为6 GB。
3.1 实验数据集和参数设置
本文是在TensorFlow框架上实现基于Inception V3的参数迁移学习,实验所用数据集为飞机、狗、猫和吉他,其数量为每类各300张图片。选用RuLu作为激活函数,RMSProp作为模型优化器,初始学习率为0.001。
3.2 结果分析
由于实验数据较小且采用迁移学习策略,模型整体收敛较快,且在本实验的硬件配置下训练,说明不需要大算力的支持。模型参数评估图如6所示,图6中x轴为迭代步数,y轴为函数值,展示了训练过程中准确率和交叉熵损失函数随网络的迭代步数变化的趋势,可以看出,迭代次数还较小的时候,准确率已经达到了0.9以上,其loss值也是在前200次迭代过程中呈指数下降,最终loss值也是达到了0.080。此外,我们随机从网上找了一些图片来验证模型,部分结果如图7所示,每张图都有这四类的判断概率,我们的模型能够准确地分类,并有较高的识别率。

图6 模型参数评估图Fig.6 Model parameter evaluation diagram

图7 部分结果展示Fig.7 Partial results show
4 结束语
本文引入了迁移学习策略,以Inception V3 为基础框架,验证了迁移学习的优势。在实验中,实验硬件较差,训练数据集较小,训练次数仅为1 000,此模型就能快速地收敛。所以,对模型的迁移学习可以更快更好地帮助目标领域学习。随着深度学习的快速发展,各式各样的模型层出不穷,而针对这一现状,迁移学习作为一个新兴领域也必将成为未来研究的主题之一[16]。通过上述实验,分析了Inception V3的结构和迁移学习的优点,对于Inception V3迁移学习的模型实际应用是下一步研究的重点。
