基于实例分割的双目特征点匹配目标识别和定位研究
2020-03-04李山坤陈立伟
李山坤,陈立伟,李 爽
(1.哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001;2.卫星导航系统与装备技术国家重点实验室,河北 石家庄050081)
0 引言
近年来,随着科学技术的迅猛发展,图像作为现实生活中容易获取、包含丰富信息的一种数据,对图像信息的处理已经成为信息科学的一个重要研究领域。
双目视觉作为机器视觉的一个重要分支,具有效率高、精度合适、系统结构简单和成本低等优点,在虚拟现实、机器人导航及非接触式测量等许多方向均极具应用价值[1]。利用双目视觉来实现特定目标测距也已经成为了一个重要研究方向。WANG[2]等人提出了基于YOLO的双目特征点匹配和目标识别定位研究方法,他们首先通过YOLO进行目标检测和识别,并针对相同物体利用加速稳健特征匹配算法(SURF)特征点进行匹配,并且针对物体纹理少,不能实现有效定位的问题,提出了多特征点融合算法,将Canny边缘检测算法和FAST角点算进行结合,使得物体可以检测目标的边缘信息,从而提高纹理少物体的匹配点的数量。然而,由于YOLO检测网络属于目标检测模型,并且提取信息是基于边框内部的物体特征,会提取到与目标无关的特征点,从而影响定位精度。
为解决这样的问题,本文引入了Mask R-CNN(Mask Region with Convolution Neural Network Feature)网络模型[3],并通过SURF来实现双目视觉的物体识别和定位。Mask R-CNN是完成对图像的将目标检测与分割并行计算的神经网络模型,该检测网络能够快速确定图像中的目标位置,经网络训练选取出区域建议框,在此基础上进行像素级别的分割,具有较高的检测性能。实验结果证明,应用结合相较于单独的目标检测任务效果更好。
1 系统流程
双目视觉定位系统流程如图1所示。

图1 Mask R-CNN双目视觉定位系统流程Fig.1 Mask R-CNN binocular vision positioning system
基于Mask R-CNN的双目神经网络与双目视觉物体识别与定位的系统实现,通过双目相机采集双目左右图像,并且利用Matlab工具包对相机进行标定,获取相机内参和外参,然后根据获取的参数对图像去畸变和极线校正。以左相机图像为参考进行分割,然后利用SURF算法进行特征点匹配[4],根据特征点的视差值计算出物体相对相机的位置。但在对相机标定的过程中,受到相机标定精度、图像去畸变和极线校正精度的影响,在远距离情况下,计算距离会出现明显偏差,为此采用最小二乘法对相机参数和位置信息进行拟合校正,提高定位精度。
2 Mask R-CNN
2.1 网络架构
Mask R-CNN是REN等人在Faster R-CNN[5]基础上进行完善的深度神经网络模型,在对图像物体识别和分割任务上具有重大的开创性意义。该网络模型主要由5部分组成:特征提取网络、特征组合网络[6]、区域建议网络(Region Proposal Network,RPN)、感兴趣区域对齐操作(RoIAlign)和全连接网络(FCN)[7-8]。
Mask R-CNN继承了Faster R-CNN的网络结构,在Faster R-CNN网络架构的基础上进行了改进,采用了深度卷积神经网络进行图像底层特征提取得到特征映射,由区域建议网络计算得到感兴趣区域(RoI),并且使用ROIAlign替代了感兴趣池化操作(RoIPool),取消了量化操作,解决了输入输出像素不对齐的问题,并采用双线性插值的方法获得确定位置的像素,输出固定尺寸的特征图,在输出特征图后面连接全连接网络层进行分类和检测回归,另一分支连接FCN进行图像像素级别的语义分割,由此,实现了对图像的检测和分割,即实现了实例分割。Mask R-CNN网络流程如图2所示。

图2 Mask R-CNN网络流程Fig.2 Mask R-CNN network flow chart
2.2 RPN
RPN的产生需要在卷积的特征图上进行网格滑动,利用n*n的网格框与输入的卷积特征映射图进行全连接,将滑动窗口映射到低维的向量,通常映射的维度为256维或512维。利用2个全连接层分别对该向量进行分类和边框回归,为使输入图像的有效区域达到最大值,将n值设为3,将网络结构在图中表示出来,在全连接层中,为实现空间位置的权值共享,采用了滑动窗口的方式进行计算。该结构是由一个n*n的卷积层进行卷积变换,然后再由2个1*1的滑动卷积层进行处理。区域推荐网络结构如图3所示。

图3 区域推荐网络结构Fig.3 Region proposal network structure
在每个滑动窗口的位置上,可以同时预测k个推荐区域,区域回归层会产生k个框的4k个坐标编码。分类层会针对每个推荐区域统计的目标概率输出2k个评分。这些被参数化后的参考框点成为锚点。每个锚点都集中在识别问题的滑动窗口中间。通常使用3个尺度和3个长宽比。使用该方法的主要原因是在计算锚和其相关的函数时都具有平移不变形。这样可以保证在对图像预测时,当目标位置发生了变化时,推荐目标也随之发生变化,函数可以计算出任意位置的推荐目标区域。
最小化Fast R-CNN[9]的多任务损失函数,对于一张图片的损失函数定义为:
(1)
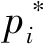
2.3 RoIAlign
在Faster R-CNN的检测网络中,分支RoIpool对生成的每个RoI提取小特征的映射。RoIPool首先将浮点数RoI量化为特征映射的离散粒度,然后将量化的RoI细分为自身量化的空间区间,最后聚合每个区间覆盖的特征值,在量化过程中将浮点数量化为整数,这样直接舍弃小数部分输出像素值就会导致像素偏差,被称为“不匹配问题”[10]。但是对于语义分割来说,对预测各个物体精确的像素掩码有较大影响,为了解决这个问题,便引入了RoIAlign层。
RoIAlign 从RoIpool的局限性源头出发,取消了对RoI边界和区间的严格量化操作,采用双线性插值[9]的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作,这样可以保证提取到的特征与输入是相互对齐的。RoIAlign原理如图4所示。

图4 RoIAlign原理Fig.4 Schematic diagram of RoIAlign
图4中,底部的虚线网格表示提取到的特征映射图,黑色线框表示ROI区域,区域大小为2×2,包含4个单元,在实验过程中,采样点设置为4会得到最佳结果。因此在每个单元中设置4个采样点,将每个单元划分为4个子单元,并且计算每个子单元中心点的像素值对应的概率值,但是该像素点大概率会是一个浮点数,但在图像上的浮点是没有像素值的,这个值由相邻最近的整数像素点通过双线性插值计算得到。然后进行最大池化或者均值池化操作得到固定维度的输出。
2.4 损失函数
整个网络任务包括识别[11]、检测和分割3个分支,因此损失函数包含分类误差、检测误差和分割误差,即:
L=Lcls+Lbox+Ls,
(2)
式中,Lcls,Lbox分别表示分类损失和回归损失,利用全连接预测出每个RoI的所属类别及其矩形框在图中的坐标位置。分割分支采用FCN对每个RoI有k×n×n(n表示RoIAlign特征图的大小,k表示类别数)维度的输出,对每一个像素应用sigmoid函数进行分类,然后取RoI上所有像素的交叉熵的平均值作为Ls[12]。
3 SURF算法
SURF算法是以尺度不变特征转换(SIFT)算法为基础提出的一种快速鲁棒性特征提取的配准算法。该算法不仅对图像旋转、缩放具有极强的适应性,而且图像在光照变化、视角变化和噪声的情况下也具有一定程度的稳定性能[13]。
3.1 特征点检测
SURF算法对特征点检测基于Hessian矩阵,图像上的每一个像素点都采用Hessian矩阵进行计算,对于给定积分图像上的一点f(x,y)在点f处[14],尺度为σ的Hessian矩阵H(x,σ)的函数表达式为:
(3)
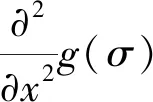
构建尺度空间的过程为在图像上下采样,然后将其与各尺度的二维高斯函数进行卷积操作。在进行卷积时,SURF算法使用盒子滤波器代替二阶高斯滤波,大大提高了卷积计算速度[15],从而降低了算法的运行时间,简化后的Hessian矩阵行列式为:
Δ(H)=Dxx*Dyy-(0.9*Dxy)2,
(4)
式中,Δ(H)为点I(x,y)周围邻域的盒子滤波器响应值;Dxx,Dxy,Dyy为模板与图像卷积的结果。特征点的判断通过比较极值点的邻域信息进行确定,在一个以某极值点为中心的3*3*3的立方体邻域内,与相邻的上下尺度和该尺度周围的26个邻域值进行比较,寻找极值点作为最终的特征点。盒子滤波高斯二阶微分模板简化模型如图5所示。

图5 盒子滤波高斯二阶微分模板简化模型Fig.5 Box-filter Gaussian second-order differential template simplified model
3.2 特征点描述
检测到特征点之后,以特征点为圆心,6σ为半径的区域内计算水平方向和垂直方向的加权Haar小波响应,然后采用60°的扇形区域遍历圆形区域,将由扇形模板内Haar小波在x,y方向响应的累计之和构成一个局部区域矢量,将最大的累加和对应的方向作为该特征点基准方向[16]。
选取基准方向后,以特征点为中心将坐标轴旋转至基准方向,沿基准方向选取长为20σ*20σ的正方形区域,将该正方形区域划分为4*4的子区域,每个子区域利用尺寸为2σ*2σ的Haar模板进行响应值计算,进行25次采样,分别得到沿基准方向的dy和垂直于基准方向的dx,统计每个子区域响应值,得到V=(∑dx,∑dy,∑|dx|,∑|dy|)特征矢量,即该子区域的描述符。所有子区域的向量构成该点的特征向量,得到维度为4*4*4=64维的特征向量。特征描述符的生成过程如图6所示。

图6 特征描述符的生成过程Fig.6 Feature descriptor generation process
4 双目视觉成像模型
同一场景下,由于目标远近原因会使同一物体在2张图像上的成像位置有所不同,这也就构成了物体的视差,利用视差可以计算出相机相对于相机模型的位置信息。双目相机经过标定之后,可以得到相机参数,经过图像校正和极线约束后,左右视图在同一平面上[17-18]。双目视图测距原理如图7所示。
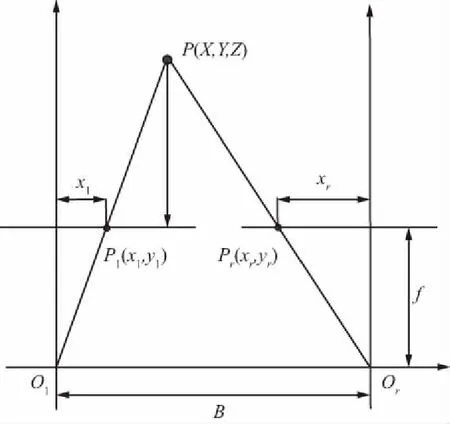
图7 双目视觉模型Fig.7 Binocular vision model
图7中,Ol,Or为两相机坐标系的原点,基线的距离为B,两相机在同一时刻拍摄特征点P(X,Y,Z),点P对应坐标系点的原点在左相机的光心Ol。P点在左相机的像素坐标系为Pl=(xl,yl),在右相机的坐标像素Pr=(xr,yr),视差值d=xl-xr,点P的三维坐标为:
(5)
但是在实际测量的过程,受到相机参数标定及相机硬件等因素的影响,测量值与真实值会存在一定偏差,通过实验观察,随着目标距离相机位置的距离和偏移量增加,误差会进一步扩大。为此,提出利用获取到的真实坐标值进行参数拟合,对相机进行二次校正[19],获取坐标计算模型:
X′=g(x,d)+X,
(6)
提高定位精度。
通过构造代价函数:
(7)
并且利用梯度下降法迭代运算,即寻求代价函数最小的时的参数值:
(8)
5 实验结果及分析
系统实验环境为Ubuntu 16.04系统,处理器型号为 Intel i7-7700,显卡型号为GeForce GTX1070,显存为8 GB,内存为16 GB,相机型号为STEREOLABS ZED双目摄像头,基于Python语言,在PyCharm平台,Tensorflow,Keras深度学习框架下实现系统整体流程。
5.1 双目定位实验
实例分割实验:目标实例分割结果如图8所示,图像中检测到目标的标签为‘person’,置信度为1.00,在图像分割区域进行掩码操作,填充上颜色。

图8 实例分割图Fig.8 Example segmentation diagram
特征点匹配实验:以左视图为基准,利用SURF算法提取左视图内的分割区域的特征点,并利用KNN算法与右视图进行特征点匹配,剔除部分误匹配特征点匹配结果如图9所示。

图9 SURF特征点匹配图Fig.9 SURF feature point matching
双目定位实验:特征点匹配后计算特征点视差,利用三角测量法计算得到目标相对相机位置。其中,x表示偏移量,z表示目标距离相机的深度值。双目视差计算结果如图10所示,目标距离相机2.678 m,偏移相机距离为0.707 m。

图10 双目视差计算结果Fig.10 Binocular parallax calculation results
5.2 定位精度实验
实验场地大小为4.8 m*4.8 m,由于相机视角的原因,将相机距离测试场景2.4 m,因此测试距离最远为7.2 m,以80 cm为间隔进行数据采集,在进行数据采集时以左相机为基准,将试验场地中心线呈现在图像的中心位置。在每个样本点位置采集大约100个特征点数。所选取的实验环境示意如图11所示。
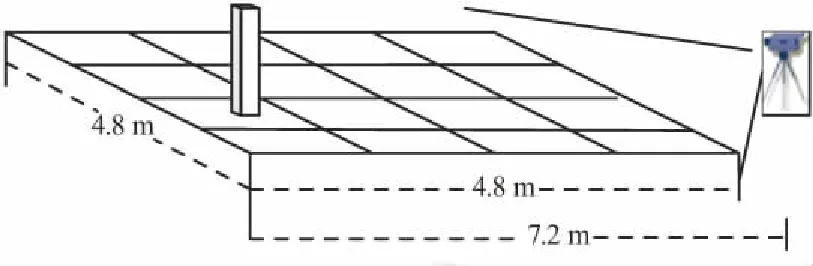
图11 实验环境示意Fig.11 Schematic diagram of the experimental environment
图12表示的是在实验环境内采集的各个样本点定位数据的均值。由图12可以看出,随着目标距离相机的深度值和偏移距离的逐渐增大,计算出来的位置偏离真实样本点值的距离也逐渐变大。经过视差拟合处理后的结果如图13所示。

图12 实验数据Fig.12 Experimental data

图13 拟合曲线对比Fig.13 Fitting curve comparison
将拟合后的数值与计算值相比较,无论在深度值方向上还是偏移量方向上,拟合后的计算值与样本点距离整体比原始计算值更近,尤其是在偏移量方向上,拟合后的曲线总体上与原始样本点在同一条直线上,表明经过拟合,拟合后的计算值准确度有了显著提高,将原始计算值、拟合后的值与样本点值的误差值分别做成距离误差图和误差分布累计图进行误差分析,如图14和图15所示。

图14 误差对比Fig.14 Error contrast

图15 误差累计分布曲线Fig.15 Error cumulative distribution curve
由图14可以看出,拟合后的误差值与原始误差值相比,幅度有了明显降低,误差分布较为均匀。由图15可以看出,拟合后的误差曲线收敛更加快速,表明误差范围缩小,最大误差由0.385 m降低到0.294 m,平均误差值由0.183 m降低到0.106 m,定位结果有了明显改善,满足了精准定位的需求。
6 结束语
针对双目视觉利用目标检测方法定位不准确问题,本文采用了Mask R-CNN实例分割网络,在检测目标的同时,对目标进行语义分割,提取左右图像分割区域的物体特征点计算视差值,进一步提高了提取物体特征点的准确性,并针对双目相机标定后的误差,对实验结果和相机参数进行拟合,提高物体定位精度。本文提出的双目定位系统,在定位精度上满足了实用性要求。在未来的工作,应该进一步优化网络,提高物体识别和分割速度,实现更高的计算速度和效率,实现在更多的使用场景中的应用。
