基于SVM的文本多选择分类系统的设计与实现*
2020-03-04丁世涛洪鸿辉郭致远
丁世涛 卢 军 洪鸿辉 黄 傲 郭致远
(武汉邮电科学研究院 武汉 430074)
1 引言
随着互联网的普及,网页信息也呈现出了爆发的的态势,截至2016年12月,中国网页数量[1]为2360亿个,年增长11.2%。目前对于网页文本分类[2~4]已经有很多建设性的成果,其绝大多数都是先使用机器学习[5~6]方法训练模型,再将网页文本信息向量化为特定的特征值,一般情况下,这个特征值的维度较高,计算量比较大,所以耗时比较长。这也造成了分类需求无差别的问题,无形中增加了处理负担,导致用户体验差的问题。
本文研究的方法充分利用了网页文本的特征,对于大部分网页内容本身,一般标题就代表了其所属分类,本文所述系统就充分利用这一特点利用标题进行分类,以达到快速分类的目的。该系统的快速分类功能不仅速度快而且其准确率也达到了人们可以接受的程度,如果你并不是最求快速的分类效果,可以使用系统中精准分类的功能,精准分类功能是将整个网页文本的数据全部全部作为特征值输入,这样能使文本分类达到更好的效果。相对于普通的文本分类快速分类所需时间降低了30%,准确度在接受范围之内,从而达到了快速处理的目的。
2 网页分类主要技术
2.1 获取网页文本数据
通过对网页的分割处理,将网页变成文本数据。
2.2 将文本信息预处理
文本的预处理包括几个方面,首先通过分词器将文本数据进行分词,把文本数据的句子变成常用的分词。然后将获取到的分词去停用词,把一些语气词,没有实际意义的词,还有一些标点符号等去除。完成这些之后文本信息的预处理工作就基本完成。
在NLP中常用的分词器[7]就有哈工大的分词器、清华大学THULAC、斯坦福分词器、结巴分词、字嵌入+Bi-LSTM+CRF分词器、等分词器。本系统使用的结巴分词器,其基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。通过分词器分词之后文本数据变成了分词。
在本文中所使用的停用词列表是常用符号和常用语气词的结合,自己也可以添加停用词。
2.3 分语向量化方法
自然语言处理的相关任务中,如果直接将自然语言交给机器学习中的算法处理,机器学习的算法将无法处理所提交的自然语言。机器不是人,机器只能识别特定的数学符号,所以我们要把输入的自然语言向量化,把它变成计算机可以理解的输入。分词向量化[8]主要有离散表示和分布式表示表示,其中每种方式都有自己的优缺点。
离散表示一般有如下几种方式:
1)One-Hot Representation
向量的分量与分词是一一对应的,如果该分词出现,向量中代表该分词的的分向量就为1。但其向量维度太高,容易造成维度灾难,导致计算量太大,无法快速完成。不能很好地刻画词与词之间的相似性,存在词汇鸿沟,就连医生跟大夫都会分为不同的类别。
2)Bag of Words[9]
选 用 TF-IDF[10~11](Term Frequency-Inverse Document Frequency),计算词权重。但其计算量比较大,处理速度慢。
3)Bi-gram 和 N-gram[12~13]
N-gram中的N表示N个分词联合,Bi-gram表示2个词联合,3-gram表示3个词联合,以此类推。但其无法区分向量之间的关联,语料库扩展麻烦,存储效率低。
分布式[14~15]表示(Distributed Representation)有以下几种:
1)共现矩阵(Cocurrence matrix)
用于主题模型,如LSA(Latent Semantic Analysis)、局域窗中的Word-Word共现矩阵可以挖掘语法和语义信息。将共现矩阵行(列)作为词向量:
(1)向量维数随着词典大小线性增长;
(2)存储整个词典的空间消耗非常大;
(3)一些模型如文本分类模型会面临稀疏性问题;
(4)模型会欠稳定。
2)Word2vec[16~19]
Word2vec是谷歌的Tomas Mikolov在2013年提出的快速处理词向量的方法,其包含两种模型,一 种 CBOW[20](Continuous Bag-of-Words Model),一种是Skip-gram[21]模型。其中CBOW的模式是已知上下文,估算当前词语的语言模型,而Skip-gram是已知当前词语估算上下文的语言模型。这两种语言模型如图1所示。

图1 Word2vec模型图
CBOW学习目标是最大化对数似然函数:

Skip-gram的概率模型可以写成:

其中C代表语料库,w代表语料库中任意一词,u表示w的上下文中的一个词语。
CBOW的特点是:
1)无隐层的神经网络。
2)使用双向上下文窗口。
3)上下文词序无关。
4)投影层简化为求和。
Skip-gram的特点是:
1)无隐层的神经网络。
2)投影层也简化省去。
3)每个词向量作为log-linear模型的输入。
一般在语料非常丰富的情况下选择Skip-gram模型,其他情况选择CBOW模型,其相对于以上几种表达方式有了很大的提高,最大的改进在于限制了向量的维度,可以识别相近词。
本论文选用word2vec训练词向量,其中的语料库选择全网新闻数据(SogouCA)完整版进行训练。
2.4 分类算法SVM理论
SVM(support vector machine)[22~23]是 Vapnik 在贝尔实验室提出的基于统计学习理论的机器学习方法。从本质上来说,它的基本的模型是特征空间上的间隔较大的线性分类器,学习的目的就是寻找类别间隔最大化的分类边界,最终可转化为一个凸二次规划问题的求解。SVM有可靠的理论依据,可解释型较强,相比于黑盒类型的神经网络有很多用处,其适用于中小规模下,目前最好的一类学习模型。
SVM中最重要的内容是:
1)寻找最大“间隔”的方法。
2)引入核函数解决现行不可分问题。
SVM的理解可以从Linear、Nonlinear两部分入手,这样可以更清楚地了解他的本质。
Linear SVM
假设存在训练样本(x1,y1),…,(xn,yn)其中 xi∈Rn,yi∈{-1,1} ,如果存在某个超平面 w·x-b=0可以将两个类别分开,并且使它们的距离足够大,其中距离最大的平面为最优超平面,如图2所示。

图2 SVM线性分类原理图
如图2所示,实心圆,空心圆分别代表两个类别,两个类别分类边界线分别为


将两公式合并为

该公式就是目标函数的约束条件,这样就将求最大间隔问题变成了二次规划问题。解决这种问题可以使用用现成的优化工具包直接求解,也可以Lagrange Duality找到一种更有效的方法求解。拉格朗日乘子法有如下优点:
1)更容易通过公式计算。
2)可以更好地挖掘公式背后的原理,近而自然而然的引进kernel函数,将分类拓展到非线性空间。
拉格朗日函数为

其中α不为0,对w,b求导,求解拉格朗日函数可得

最后结果分析,其中α为乘子,yi为+1或只取决于训练样本xTixj的两两点乘。所谓对模型的训练就是在已知x,y的情况下通过SMO求解方法求出求出边界线上的
对于新出现的样本u,就可以带入公式:
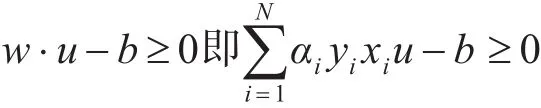
其中y=+1,否则可判定u对应的y=-1。
Nonlinear SVM
根据机器学习的理论,非线性问题可以通过映射到高维度后,变成一个线性问题。
SVM的处理方法就是选择一个核函数k()通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。一堆数据在二维空间无法划分,从而映射到三维空间里划分如图3所示。
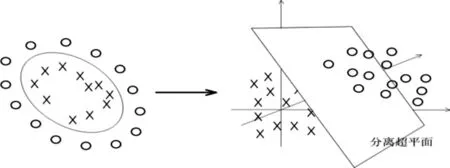
图3 SVM非线性分类原理图

带入分类公式:

其中k(x,xi)为核函数,常用的核函有RBF核函数、多项式核函数、高斯核核函数等。一般找到一个特定的核函数比较困难,所以都从以上核函数中寻找。
2.5 结果评测
对于结果的评测我们引入三个指标来对分类器进行评价:
1)精度(Precision),又称“精度”、“正确率”;
2)召回率(Recall),又称“查全率”;
3)F1-Score,准确率和召回率的综合指标。

其中TP(cj)表示属于cj的样本且被正确分为cj类的样本数;FN(cj)表示属于cj类的样本,但没有被正确分为cj类的样本数;FP(cj)表示不属于cj类的样本,但被分为cj类的样本数。
3 系统的实现流程多选择分类系统实现
该系统实验的流程为
1)将网页数据变为文本数据。
2)对文本数据进行分词,去停用词等处理。
3)快速分类跳到步骤4),普通分类跳到步骤5)。
4)检查类别队列里是否有对应的关键词,若没有则使用word2vec模型训练分词向量,并查找类别队列里是否有最相近的关键词,如果有就直接找出分类完成分类任务,如果没有就跳到步骤5)。
5)对文本正文数据进行分词,去停用词等处理,使用word2vec模型训练正文数据获取文本向量,最后使用训练好的SVM模型完成分类任务。
6)评判结果。
该系统处理普通分类和快速分类两种任务,普通分类就是将文本内容无差别地使用word2vec以获取文本向量,再将该文本向量通过SVM进行分类。如果文本内容比较长,并且待分类文本数量比较多的话,那么处理该任务时间将会比较长,但是有些场景需要高效率,低耗时的处理文本分类问题,对于这种需求普通分类不能达到其处理要求。这就要使用该系统提供的快速分类功能,快速分类根据文本标题内容提取相应的关键字或者相近的关键词,匹配相应的类别队列,以达到快速分类的目的。快速分类功能能够在保证准确度的情况下达到短时间内完成分类的目的,如果分类队列内容全面,且设置得当,快速分类所需时间会是普通分类所需时间的一半以下。
4 实验结果的呈现
针对上文提出的SVM的网页文本分类系统的实现,本实验选用的数据集为搜狗中文实验室的全网中文新闻数据集——“SogouCA”完整版,该数据集有多个网站的近2万篇网页文档数据,测试数据为在凤凰、搜狐等网站爬取的1000篇网页内容。使用多选择分类系统的快速分类和普通分类处理文本数据的分类准确率结果对比为如表3。
其中P代表 Precision,R代表Recall,F1代表F1-Score。
使用多选择分类系统的快速分类和普通分类处理文本数据的分类时间结果对比如表2。

表1 分类准确度结果对比(单位:%)

表2 分类耗时结果对比(单位:Seconds)
5 分类结果分析
针对以上结果,我们可以得出结论:在多选择分类系统中普通分类处理文本数据的时间明显长于快速分类时间,普通分类处理文本数据的准确度优于快速分类,但是快速分类准确度也在可接受范围内。多选择分类系统提供了多选择分类服务,能够满足不同的分类需求,给我们以后不同的需求场景提供了多选择机会。
6 结语
多选择分类系统通过将网页文本的分词,去停用词,通过已经用word2vec训练好的模型将标题或者与标题相近词通过类别队列提供快速分类服务,或者将文本内容向量化通过SVM提供普通分类服务。该系统能够根据网页文本的特点将分类分为快速分类以及普通分类。快速分类根据网页标题关键词以及其相关词到类别队列中查找类别以达到快速分类的目的,这样省去了文本生成向量以及文本添加到SVM分类器计算的步骤,节省了大量时间。该系统针对不同的分类需求能够提供不同的服务,提供了有差别的分类服务,这也是该分类系统的优势。但是该系统依据标题进行快速分类的分类效果还有待提高,一篇文章同属于多个类别的多分类能力也需改善。希望以后能根据标题以和标题的拓展进行更准确、快速的文本分类服务以及添加文章多分类的功能。
