基于C-R神经网络的生成式自动摘要方法*
2020-03-04王玮
王 玮
(军事科学院研究生院 北京 100091)
1 引言
文本摘要也是一个传统与新兴技术并存的研究领域。文本摘要从20世纪50年出现以来,出现了很多经典的方法,比如基于词频统计的方法[1],基于词典词库的TD-IDF方法[2],基于机器学习的统计方法[3]。在不断涌现的新技术中,很多可以用于文本自动摘要,但与人工生成的摘要相比,效果可能总是不尽人意的。但随着深度学习和大数据技术的发展,为实现自动文本摘要的智能化提供了很好的技术基础。当然传统方法结合深度学习和大数据也是研究的重要方向[4]。
文本摘要是指用单个或多个文档中较少的文字,产生可传达原文本主要信息的一段文本。文本自动摘要是一种利用计算机自动生成文本摘要的理论方法和技术[5~7]。自动摘要的出现一方面是为解决海量情报信息过载问题,另一方面原因是人工摘要的成本较高。自动文本摘要(Auto Text Summarization)是NLP中较难的问题,至今依然没有很成熟的技术来解决这个问题,包括单文档和多文档摘要技术,后者较于前者会更加复杂一些。搜索引擎是ATS应用之一,基于查询的自动摘要会帮助用户尽快找到感兴趣的内容。
自动摘要一般两种解决思路。一种是抽取式,就是按照一定权重,从原文中找到关键句子,组合成一篇摘要。抽取式摘要目前已经比较成熟,但是抽取质量及内容流畅度均差强人意;另外一种是生成式,是计算机在理解整篇文章含义的基础上,自动生成的摘要。伴随着深度学习的研究,生成式摘要的质量和流畅度都有很大的提升。因此依靠自然语言处理理论来自动生成文本摘要是近几年来重要研究方向之一。
文献[8]首次将深度学习模型应用于多文本抽取式摘要,提出了一个计算架构,采用RBM受限玻尔兹曼机作为深度学习网络,并用实验进行了验证。文献[9]首次提出了将CNN应用到文本摘要中,利用CNN进行文档编码,用BP反馈网络生成摘要。文献[10]提出了序列到序列的方法,就是利用RNN循环神经网络作为解码器来进行文本摘要,效果提升比较明显。文献[11]中将RNN的注意力机制用到RNN解码器,效果比单纯的RNN好。本文认为,利用深度学习模型来进行文本摘要生成比传统方法效果是有大幅提升的。目前需要考虑地是深度学习模型如何能更好地应用于文本摘要问题,考虑将深度学习模型进行组合运用,是值得探讨的研究方向。
本文对生成式自动摘要方法进行了综述,提出了基于卷积深度神经和循环神经网络的生成式自动摘要方法,对方法的主要思路、评价方法进行了描述,并通过实例对算法进行了验证,与其他自动摘要方法进行了对比,说明了改进方法的先进性。
2 生成式自动摘要方法综述
生成式文本摘要是更接近于人类思考方式的摘要生成方法,具有更强的生成、理解、表征文本的能力。近年深度神经网络方法表现出强大的表征(Representation)能力,生成式自动文本摘要依赖深度神经网络方法获得了令人瞩目的发展。生成式神经网络模型的基本结构是由编码和解码器组成,如下图1所示。
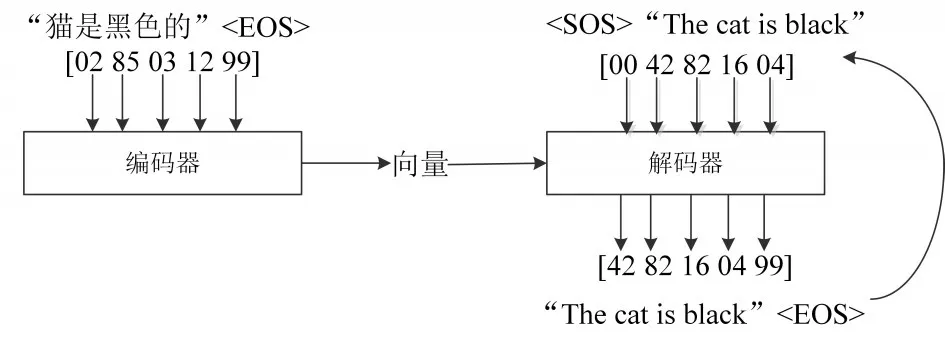
图1 生成式基本模型结构
深度神经网络结构已经可以实现生成式文本摘要。2014年由谷歌大脑(Google Brain)团队提出了Sequence-to-Sequence序列(以下简称Seq2Seq),开始了利用端到端网络来研究NLP的先河。Seq2Seq序列又称为编解码器(Encoder、Decoder)架构,编码器负责将输入文本编码成一个向量,作为原文本的表征,该向量包含了文本的上下文信息。而解码器从该向量提取重要信息,并进行剪辑加工,生成文本摘要,这套架构就是Seq2Seq。该方法被广泛应用于存在输入和输出序列的场景,Seq2Seq架构中的编码器和解码器通常由时间递归神经网络(RNN)或卷积神经网络(CNN)实现。
2.1 基于RNN的生成式结构
“序列到序列”方法在很多文本处理中有很好的效果。从序列角度看,自动摘要为从原始文本序列到摘要文本序列的映射,使用序列到序列建模来处理是可行之法。不同之处在于,摘要长度并不依赖于原文本长度,而且相对于原文摘要必然有信息损失。很多专家已经在这方面取得了很好的研究成果,比如Chopra等使用递归神经网络(RNN)作为解码器,大大提高了摘要效果[10]。
基于RNN模型本身的序列特性,将其用于实现Seq2Seq架构处理文本任务是顺其自然的想法。典型的基于RNN生成式基本模型结构如图2所示。
图中编码器和解码器分别由四层RNN的变种LSTM(长短期记忆网络)组成。图中的向量编码了输入文本信息,解码器获得这个向量依次解码生成目标文本。上述模型也可以自然地用于自动文本摘要任务,这时的输入为原文本(如新闻),输出为摘要(如新闻标题)。
2.2 基于CNN的生成式结构
Seq2Seq同样也可以通过CNN实现。不同于递归神经网络可以直观地应用到时序数据,CNN最初只被用于图像任务。CNN是通过卷积核从图像中提取特征(Features),间隔地对特征进行最大池化(Max Pooling)作用,从而得到不同层次的、由简单到复杂的特征(如线、面、复杂图形模式等),如图3所示。
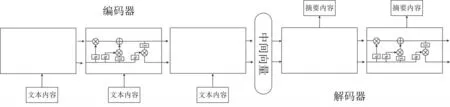
图2 基于RNN的生成式基本模型结构

图3 图像中提取特征示意图
CNN的算法优势是可以提取出层次特征,并可以高效并行地进行卷积运算,根据其特点,可将CNN应用到相关文本任务中,但原生态的文本字符串无法进行计算,需将文本表示为分布式向量(Distributed Representation/Word Embedding)。可以用一个实数矩阵或向量表示一句话或一个词,经过分布式向量表示后,既可以在文本任务中应用CNN。
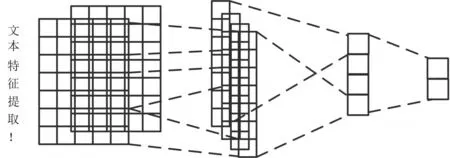
图4 基于CNN的文本特征提取示意图
如图4所示,原来的文本由实数矩阵表示,矩阵可以类比为图像的像素矩阵,卷积神经网络可以像读取图像一样读取文本,学习并提取文本特征。但CNN提取的文本特征,并不能如图像特征那样,有明显的可解释性和可视性。CNN抽取的文本特征可以类比自然语言处理中的分析树(Syntactic Parsing Tree),如图5代表句子的语法层级结构。
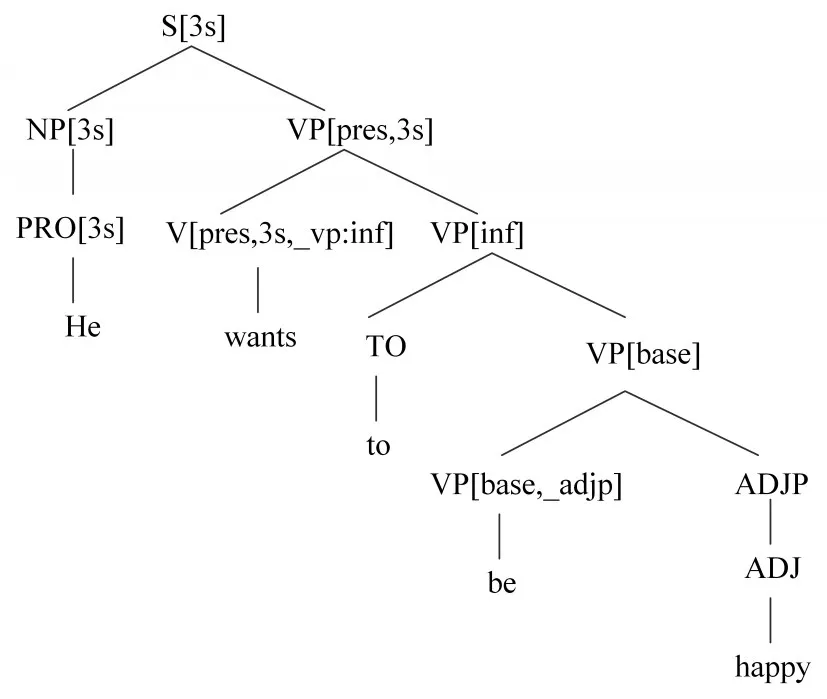
图5 语法层级结构
基于CNN的自动文本摘要模型中的比较著名的是Facebook公司提出的ConvS2S模型[3],由CNN实现编码器和解码器,同时加入了注意力机制,尝试将该模型用于自动文本摘要。实验结果显示,基于CNN的Seq2Seq模型也能在文本摘要任务中达到接近完美的表现。ConvS2S的成功之处不仅在于创新的结构,还在于细致入微的小技巧。在ConvS2S中对参数使用了非常仔细的初始化和规范化(Normalization),稳定了方差和训练过程。这个模型的成功证明了CNN同样能应用到文本任务中,通过层级表征长程依赖(Long-Range Dependency)。同时,由于CNN具有可高度并行化的特点,所以CNN的训练比RNN更高效。比起RNN,CNN的不足是有更多的参数需要调节。
2.3 基于Attention的生成式结构
编码器将原文编码为向量V,而解码器从向量V中提取信息、获取语义、生成文本摘要。但由于“长距离依赖”问题,RNN最后一个时间步输入单词时,会丢失了很多信息,编码生成的语义向量V也丢失了大量信息,导致生成的摘要不够准确。Google团队2017年6月宣布不用CNN和RNN单元,使用自注意力(Self-Attention)和编解码器注意力(Encoder-Decoder Attention),来完全实现端到端任务[12]。由于采用并行计算模式,模型训练和生成速度也有所提升。自注意力模型更加关注句子内部结构,即Word-Pairs的信息。模型单独学习目标端句子内部结构信息,利用编解码器注意力建立源文本和目标文本的对应关系。自注意力在第一层便巧妙地建立了词和整个句子的联系,其思想可用于文本摘要自动生成任务[13]。
3 基于C-R神经网络的生成式自动摘要方法
基于深度学习的自动摘要方法是目前效果较好的方法,也是下一步研究的热点。本文提出一种结合了CNN和RNN神经网络(C-R)的复合模型方法,来完成自动摘要的生成。CNN+RNN编码器负责将输入文本编码成一个中间向量,作为原文本的表征,该向量包含了文本的上下文信息。而RNN解码器从该向量提取重要信息,并进行剪辑加工,生成文本摘要。
3.1 方法思路
摘要模型包括基于CNN+RNN神经网络的编码器和基于RNN的文本生成器。模型分层反映了文档是由词、句、段组合而成的本质,可以有效地对文档的局部和全局信息进行把握,对长句和重要句子的信息损失较小,能够更加全面地保留文档的主旨含义,保证产生的摘要更加人性化[14]。基于C-R神经网络的生成式自动摘要方法模型总体结构图,如图6。
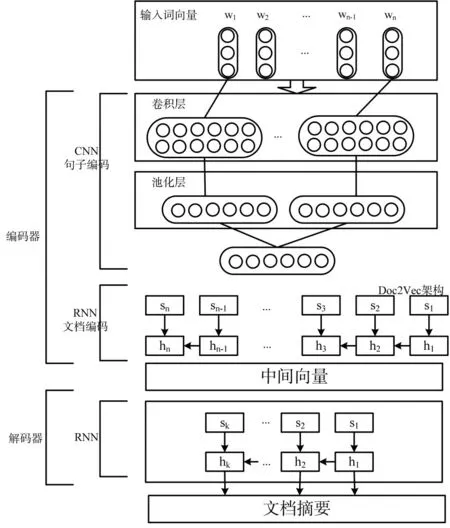
图6 基于C-R神经网络的摘要模型
3.1.1 词向量输入
首先,利用Word Embedding中的CBOW训练模型,生成文本的词向量。CBOW训练模型是一个前馈神经网络模型,共有输入层、映射层和输出层三层结构。先对文本分词后得到词典D,训练模型的初始输入是随机浮点数矩阵,其大小为|D|*d。|D|是词典D中的词语数量,d是词向量的维度。经过大规模数据集的训练,并不断更新词向量矩阵中,预测词的前后文所包含的词语的向量,从而可以获得词典D中各个词的向量表示,而后输入到编码器中。
3.1.2 语句向量编码
每个句子被看做是一个词序列,先通过卷积神经网络(CNN)获取句子的表示向量,用作RNN的输入以获取文档表示。对输入的文本词向量卷积操作之后,可以将邻近词语的特征组合表示出来,这些特征组合表示在进行局部最大池化操作之后,能够比较强地表征词特征的组合会被挑选出来,在进行若干次的卷积和最大池化操作之后,就可以生成原始语句的向量表示,该向量的维度是固定的。
采用CNN网络表示语句编码,设语句S可用词表示为{w1,w2,…,wn},利用每个词 w 的词向量构成n*d(d表示向量维度)的语句矩阵。为了计算便捷,要求导入系统的句子长度要一致,所以对较短的语句,文中采用以添加“占位符”的形式进行补全到最大语句长度,“占位符”是相同维数的全“0”向量。如此反复,随着卷积和最大池化的层数逐渐增多,最终原始语句就可被表示成固定维度向量。当词向量进行卷积操作后,其原来的向量表示数量明显减少,由于语句的长度不一致而给语句学习的表示过程所造成的影响,将会得到有效的改善;通过最大池化操作,词语之间比较差的组合表示可以被删掉,而仅将比较好的组合表示提取出来,进行后续的训练学习,从而提高实验效率。
3.1.3 文档向量编码
文档向量编码的任务,借鉴参考文献[6]提出文档向量表示Doc2Vec框架融合RNN模型实现,在该文档向量表示框架中,每篇文档的每个句子均由唯一的向量表示,通过将RNN将句子向量首尾链接形成文档向量[15]。RNN本身是序列结构,它的隐含层是由结构相似的序列构成,由序列来完成文档的向量表示。
为了预测下一个词语,采用串联结合向量的方法,将词向量和文档向量进行连接操作。词向量和文档向量采用误差梯度下降法进行训练,每次循环,固定长度的上下文可以从文档中抽样出来,通过计算误差梯度不断更新模型参数。如果数据集包含N篇文档,词汇表含有M个词,文档向量为d1维,词向量为d2维,则该模型共有N*d1+M*d2个参数。当N很大时,模型的参数数量也很大,但由于训练中的参数更新比较少,保证了训练过程的高效性。
3.2 摘要评价
对文档摘要的质量进行评估是比较困难的。对于相同的文档,虽然有关于语法正确性、语言流畅性、关键信息完整度等标准,但一定程度上评判还必须依赖人的主观判断。自20世纪90年代末开始,一些会议或组织致力于制定摘要评价标准,比较著名的会议或组织有SUMMAC、DUC(Document Understanding Conference)、TAC(Text Analysis Conference)等,其中DUC的摘要任务被广泛研究,大多数抽取式摘要模型在DUC-2004数据集上进行测试。
摘要评价要基于语法和连贯性来评价摘要的可读性。目前评估文本摘要质量主要有两种方法:人工评价方法和自动评价方法。为了更高效地评估文本摘要,自动评价方法会选定一个或若干指标,基于指标对生成的摘要与参考摘要(人工撰写,被认为是正确摘要)进行自动评价。目前最常用、最受到认可的指标是Lin提出的ROUGE(Re-call-Oriented Understudy for Gisting Evaluation)[16],包括一些衍生的指标,最常用的有ROUGE-n,ROUGE-L,ROUGE-SU。
ROUGE-n:该指标旨在通过比较生成的摘要和参考摘要的N-Grams(连续的n个词)评价摘要的质量。常用的有ROUGE-1,ROUGE-2,ROUGE-3。
ROUGE-L:不同于ROUGE-n,该指标基于最长公共子序列(LCS)评价摘要。如果生成的摘要和参考摘要的LCS越长,那么认为生成的摘要质量越高。该指标的不足之处在于,它要求N-Grams一定是连续的。
ROUGE-SU:该指标综合考虑Uni-Grams(n=1)和Bi-Grams(n=2),允许Bi-Grams的第一个字和第二个字之间插入其他词,比ROUGE-L更灵活。
作为自动评价指标,ROUGE和人工评定的相关度较高,在自动评价摘要中能给出有效的参考。但另一方面,从以上对ROUGE指标的描述可以看出,ROUGE基于字的对应而非语义的对应,生成的摘要在字词上与参考摘要越接近,那么它的ROUGE值将越高。但是,如果字词有区别,即使语义上类似,得到的ROUGE值就会变低。换句话说,如果一篇生成的摘要恰好是在参考摘要的基础上进行同义词替换,改写成字词完全不同的摘要,虽然这仍是一篇质量较高的摘要,但ROUGE值会呈现相反的结论。从这个极端但可能发生的例子可以看出,自动评价方法所需的指标仍然存在一些不足。目前,为了避免上述情况的发生,在Evaluation时,通常会使用几篇摘要作为参考和基准,这有效地增加了ROUGE的可信度,也考虑到了摘要的不唯一性。对自动评价摘要方法的研究和探索也是目前自动文本摘要领域热门的研究方向。
4 实验验证
4.1 数据集处理
本文采用搜狐新闻数据(SogouCS),来自搜狐新闻2012年6月到7月期间国内,国际等多个频道的新闻数据,提供URL和正文信息。
对数据进行预处理很关键,处理质量会直接影响编码器编码阶段输出摘要的质量。要读部分信息进行替换和处理:一是去除特殊字符,如:“「,」,¥,…”;二是去掉如表情符内容:三是替换日期标签为TAG_DATE变量,替换超链接URL为标签TAG_URL,替换全角英文为标签TAG_NAME_EN,替换数字为TAG_NUMBER。

图7 数据集样例
本文设定的输入序列,是新闻的正文,待预测的目标序列是新闻的标题。为了训练的效果正文部分不宜过长,设正文分词个数到最大长度为120个词。标题部分最大分词个数为30,即生成标题(等效为摘要)不超过30个词。
4.2 程序实现
2016年Google开源了TensorFlow中的自动摘要模块Textsum,基于深度学习模型自动生成新闻标题,利用了“Seq2Seq”思想,摘要效果近似于人工。利用TensorFlow的TextSum库,使用Python语言可以实现本文提出的基于C-R神经网络的生成式自动摘要方法。
4.2.1 输入词向量计算
SogouCS数据集的原文内容输入CBOW模型的进行模型训练,用以生成文本词向量。输入模型的文本形式是把每篇分词(用前文研究过的基于Bi-LSTM网络的六词位标注算法的中文分词方法)后的原文以行存储,设定词向量维数为200,模型训练过程中的滑动窗口的大小设置为5,并将词频小于5的词直接过滤掉,最终得到的输入词向量,其部分截图如图8所示。

图8 词向量部分截图
4.2.2 程序实现
部分实现代码如下:
#Encoder:Multi-Layer RNN,Output:encoder_outputs
for layer_i in xrange(hps.enc_layers):
with tf.variable_scope(‘encoder%d’%layer_i),tf.de-vice(
self._next_device()):
cell_fw=tf.nn.rnn_cell.RnnCell(
hps.num_hidden,
initializer=tf.random_uniform_initializer( -0.1,0.1,seed=123),
state_is_tuple=False)
cell_bw=tf.nn.rnn_cell.RnnCell(
hps.num_hidden,
initializer=tf.random_uniform_initializer( -0.1,0.1,seed=113),
state_is_tuple=False)
(emb_encoder_inputs,fw_state,_)=tf.nn.bidirectional_rnn(
cell_fw,cell_bw,emb_encoder_inputs,dtype=tf.float32,
sequence_length=article_lens)
encoder_outputs=emb_encoder_inputs
4.2.3 结果输出

表1 自动生成摘要示例
4.3 结果分析
实验将本文方法与其它摘要生成方法来进行对比实验。
1)基于TF-IDF特征统计的自动文摘方法。该方法通过计算文档中关键词的特征值,将特征值组合计算,得到每句话的权重表示,选取权重高的语句作为文摘句。该方法将每句话用离散特征空间表示,提取了若干关键词,但是忽略了词与词之间的相关性掉,实现起来相对简单。
2)基于LDA模型的自动文摘方法。考虑了文章词语相关性的算法,改模型主题数、特征的选择,将直接影响最终的实验结果,对比分析选取实验效果最好的特征数,并将得到的结果作为比较基线。为了确定最佳主题数,选择了相同的500篇验证集来进行实验以选取最佳主题数,对比分析结果如图9所示。在本实验中,设主题数为5来进行测试。

图9 LDA模型不同主题数的实验对比
从表2中可以看出,对于传统的文摘方法,将词之间的相关性考虑在内的LDA方法实现的文摘效果,要明显高于简单地基于特征统计的TF-IDF方法,而基于深度学习的方法实现的文摘效果又高于传统方法。

表2 不同摘要方法的实验结果对比
基于TF-IDF的统计方法对文本的表示具有局限性,中文中存在一词多义和多词一义现象,如果忽略了文本内容中前后文语境,仅用各自独立的特征来表示文本,得到的文摘效果必然不佳。基于LDA模型的方法克服了统计方法的缺点,通过大规模语料库的统计和分析计算,提取和推断词语的预期语境间的关系,所以获取的摘要质量有一定改进。
而基于C-R网络的生成式自动摘要方法在对句子进行建模时,充分考虑了句子的结构信息,在多层卷积和池化以及序列化的过程中,可确保句子的语义信息和特征保留。C-R网络摘要生成方法将文档和文档中的句子进行语义上的匹配,将句子和文档整体的语义信息考虑在内,会得到较好的实验结果。
总得来说,传统文摘方法实现起来简单,所用模型也很直观,但在获取文摘的过程中,没有将词语的位置及在文本中的次序等语法信息进行充分考虑,在文本语义表达上还存在一定的欠缺,需要人工选择大量的特征,当面对大规模的数据集时会十分费时费力;而基于深度学习模型的自动文摘方法,一方面,它通过对大规模语料库的学习,可以得到词或句子的连续的空间表示,将词语之间的相关性和语法信息考虑在内,在文本的语义表示方面具有很大的优势;另一方面,在学习过程中,所有的特征都是通过对语料库的学习自动获得,不需要人的额外参与,通过对数据集的不断学习来自动获取文章的摘要。
5 结语
本文提出了基于卷积神经网络和循环神经网络(C-R)的生成式自动摘要方法,提出了方法的主要思路和实验所需软硬件环境,对实验结果评测指标的选取做了描述,接着对完成的各实验结果进行对比分析。分析表明基于C-R网络的自动文摘方法能通过大规模数据集的训练,得到文本的语义表示,通过对文档和句子的语义匹配进行打分,将匹配度高的句子输出构成文本的摘要,相较传统的自动文摘方法,获取文本摘要的智能性及质量有了很大提高。
