基于雾计算的智能工厂实时任务调度架构
2020-02-27鲍士兼赵成林许方敏
曾 鹏,鲍士兼,赵成林,许方敏
(1.北京邮电大学 信息与通信工程学院,北京 100876;2.中国国际工程咨询有限公司,北京 100048)
0 引言
随着工业领域向着数字化、智能化和服务化的方向发展[1],智能制造技术已成为工业界高度重视的领域之一。在此背景下,智能工厂正有效地支持着智能制造的实施[2]。
然而,随着智能工厂和物联网的发展,智能工厂中的智能设备与传感器越来越普及。传统的基于云计算的网络架构无法再满足智能工厂应用对时延的需求[3-4]。
雾计算将数据的分析处理扩展到了网络边缘,可以有效地克服云计算由于长传输距离带来的高时延的缺点[5-7]。然而,要想充分利用雾计算中的网络资源、使雾计算中的计算节点有效协作,还需要一个有效的任务调度方案[8-9]。
现有的任务调度方法大多是根据当前雾计算资源的多少,与当前接收到的任务集合进行匹配,通过算法将各个任务分配到合适的计算节点进行处理[10-12]。然而,这些研究都只考虑了某一时刻的任务调度,不太适用于实时的智能工厂生产环境。为此,本文深入调研分析了智能工厂的特点,利用雾计算的优势,设计了一种基于雾计算的智能工厂网络架构,并且基于该架构,提出了一种基于动态优先级的实时任务调度方案。
1 网络架构
基于雾计算的优势以及智能工厂的特点,设计了一个基于雾计算的智能工厂网络架构,如图1所示。整个架构分为3层:基础设施层、雾计算层和云计算层。

图1 基于雾计算的智能工厂网络架构地理分布Fig.1 Smart factory network architecture based on fog computing
智能设备层,主要由机械臂、车床、冲压设备和摄像头等各类现场设备和传感器组成,传感器实时采集设备状态数据,用于异常检测、故障诊断和剩余寿命预测等分析或机械控制等智能工厂应用。根据现场设备所在的车间,传感器通过WiFi、蓝牙或有线链路将采集到的数据发送到相应的雾节点进行处理。
雾计算层,由一个雾管理节点和多个雾节点组成。每个雾节点负责接收和执行所处车间中智能设备生成的任务,并定期将自己的运行状态发送到雾管理节点。而雾管理节点则根据雾节点的运行状态向各个雾节点下达任务调度决策,各雾节点根据决策调度等待队列中的任务。雾计算层由于靠近设备端,可以处理时延敏感的任务。
云计算层,由高性能的服务器集群组成,具有强大的计算和存储能力,负责处理工厂中计算复杂度大、延迟敏感度低以及数据量大的异构数据。
因此,雾计算层负责处理实时的、时延敏感的计算任务,而云计算层负责处理大规模的、非实时的计算任务。由于雾计算层资源相比于云计算层相对匮乏,因此需要有一个高效的任务调度方案对雾计算的资源进行调度。
2 实时任务调度方案
2.1 调度流程
雾计算层的任务调度模型如图2所示。在智能工厂中,每个雾节点接收其对应车间中智能设备的任务请求。任务请求到达雾节点之后,将被放入任务等待队列中等待雾节点执行。

图2 任务调度模型Fig.2 Task scheduling model
然而,智能工厂中的实时任务通常具有不同的优先级。若直接按照固定优先级的调度模型执行任务,会导致低优先级任务不断被高优先级任务阻塞而超时,必然会影响智能工厂的正常生产。考虑这些情况,结合任务的固定优先级以及执行紧迫度,提出了一种基于动态优先级的任务调度模型。在雾计算层中,各个雾节点可以按照任务的动态优先级执行等待队列中的任务。
此外,合理的任务调度对于任何系统来说都非常重要[13-15]。由于每个雾节点具有不同的计算能力,并且每个雾节点的任务到达率不同,一些雾节点将累积大量等待执行的任务,而另外一些雾节点的资源利用相对空闲。针对这种情况,提出了一种定期执行的计算卸载策略,该策略根据每个雾节点的计算能力、存储容量和通信容量,将各个雾节点等待队列中的任务重新分配,可以充分利用雾计算层的网络资源,均衡雾计算层中每个雾节点的负载,从而提高任务完成率、降低任务执行时间。
因此,提出的基于动态优先级的实时任务调度方案的任务调度流程如图3所示。
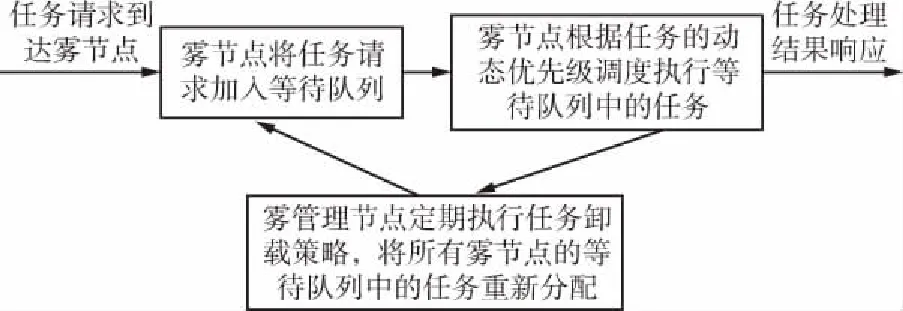
图3 任务调度流程Fig.3 Task scheduling process
2.2 动态优先级
为了解决基于固定优先级的任务调度模型的缺点,应该考虑任务的延迟容忍属性。目前已有许多根据任务的延迟容忍属性决定优先级的调度算法[16-17]。然而,这些算法却忽略了任务本身的优先级。因此,本文基于任务的固定优先级和执行紧急程度,设计了基于动态优先级的任务调度模型,用于等待队列中任务的调度执行。
分别代表任务Tk到达雾节点的时刻及其最大容忍时延。
集合{Fog1,Fog2,Fog3,…,FogN}代表雾计算层中的N个雾节点,并且雾节点Fogn用向量{Cn,Sn,Pn}表示。其中,Cn代表雾节点Fogn的CPU计算频率;Sn代表雾节点Fogn的可用存储容量;Pn代表雾节点Fogn的传输发射功率。
因此,在t时刻,任务Tk在雾节点Fogn中的执行紧迫度可表示为:
(1)

在t时刻,任务Tk在雾节点Fogn中的实时优先级为:
(2)
式中,prmax表示所有任务的最高优先级;p,q代表权重参数,二者用来权衡固定优先级以及任务执行紧迫度的重要程度。
本文考虑的是任务之间是非强占关系。因此,对于雾节点Fogn,每执行完一个任务,会重新计算等待队列中任务的实时优先级Dprk,n,并且选择其中Dprk,n最高的任务执行。
2.3 任务卸载策略
本文用I表示2次任务卸载策略的执行间隔,由于每次卸载时任务规模不同,因此I是动态调整的,可以通过下式得到:
(3)

当第α任务卸载策略执行时,假设雾计算层所有雾节点的等待队列中共有K个任务,可以用集合{T1,T2,T3,…,TK}表示。并且,每个任务所在的雾节点用集合{l1,l2,l3,…,lK}表示,其中lk∈{1,2,…,N}。此时,任务Tk在等待队列中已经等待的时间为:
(4)
式中,tα表示当前任务卸载策略的开始时刻。
当雾管理节点执行完任务卸载策略之后,会得到每个任务的卸载决策。这里使用xk,n表示任务Tk是否被分配到雾节点Fogn,则:
(5)
因此,可以用集合{xk,n}表示此次卸载决策,其中k∈{1,2,…,K},n∈{1,2,…,N}。
在任务卸载过程中,一个任务只能分配给一个雾节点。同时,考虑到雾节点的存储容量限制。那么有:
(6)
(7)
此外,在任务卸载过程中,雾节点之间的任务卸载是需要考虑传输时延的。在此,将任务Tk从雾节点Foglk卸载到雾节点Fogn所需要的传输时延为:
(8)
式中,Translk,n表示从雾节点Foglk卸载到雾节点Fogn的所有任务组成的集合;rlk,n表示雾节点Foglk与雾节点Fogn之间的数据传输速率。由式(9)可得:
(9)
式中,Blk,n为雾节点Foglk与雾节点Fogn之间的信道带宽;hlk,n为信道增益;N0为噪声。
当任务Tk被卸载到对应的雾节点后,还需要经历等待与计算2个过程。这2个过程产生的时延为:
(10)
(11)
式中,HPtasksk,n表示在任务Tk之前执行的任务的集合。
由式(3)~(11)可以得到,任务Tk从生成到执行完成所需的总时延为:
(12)
由于容忍时延的约束,则有:
(13)
并且根据式(12),可以得到所有任务执行完成的时刻为:
(14)
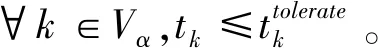
此外,将任务的值定义为完成任务的固定优先级,可以得到本次任务卸载决策获得的总价值为:
(15)
本文的目标是每次的任务卸载策略可以在降低任务完成时延的同时,获得最大的卸载决策价值。任务卸载策略是一个多目标优化问题,在最大限度地减少任务的完成时间的同时,最大化卸载决策完成任务的总价值,该优化问题为:

(16)
s.t.
(17)
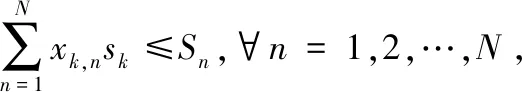
(18)
(19)
在满足式(17)~(19)的条件下,尽量优化式(16)。
3 基于NSGA-II的任务卸载算法
实现提出的实时任务调度方案,必须要解决提出的优化问题。由于提出的优化问题由2个目标函数组成,是一个典型的多目标优化模型,因此本文使用NSGA-II算法[18]来解决问题。


算法1 基于NSGA-II算法的任务卸载算法输入:Fog1,Fog2,Fog3,…,FogN{}T1,T2,T3,…,TK{}l1,l2,l3,…,lK{}输出:xk,n{},k∈1,2,…,K{},n∈1,2,…,N{}1:初始化:设置种群规模M,初始化种群Y1,最大迭代次数maxGen,交叉概率p1和变异概率p2。2:计算当前种群中每个个体的适应度函数值,并执行非支配快速排序和拥挤度排序。3:fort=1:maxGendo4:通过二进制锦标赛法从Yt中选择个体,并执行交叉和变异操作以生成新一代种群Gt。5:通过将新一代种群与上一代种群合并得到组合种群Rt=Yt∪Qt。6: 对Rt进行非支配排序,并通过拥挤度排序以及精英保留策略选择M个个体,形成新一代种群Yt+1。7:end for8:从最终代种群YmaxGen+1选择一个最佳个体,并得到卸载决策。9:returnxk,n{},k∈1,2,…,K{},n∈1,2,…,N{}
4 仿真实验
4.1 仿真场景与参数设置
采用Matlab作为实验平台来评估所提出的任务调度方案的性能。在提出的基于雾计算的智能工厂网络架构下,车间数量为6,每个车间有1台服务器作为雾节点。雾节点的计算能力随机分布在2~4 GHz,可用存储容量随机分布在10~20 GB,雾节点之间的传输速率ri,j∈[20,40]Mbps。
另外,本文考虑智能工厂中有3种优先级任务的情况,任务参数参考文献[19-20]设置,具体参数如表1所示。
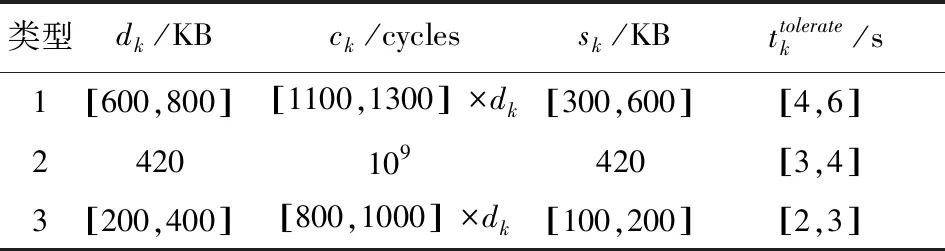
表1 任务参数设置Tab.1 Task parameter settings
到达的任务流遵循泊松分布,3种任务的总到达率为λ,3种任务到达率之比为0.4∶0.25∶0.35,实验模拟20 s的任务产生。在基于NSGA-II算法的任务卸载策略中,变异概率设置为0.1,交叉概率设置为0.9,种群大小为100。
为了验证提出的任务调度方案的性能,建立了几组对比实验方案:
方案1:雾节点之间不进行任务卸载,每个雾节点根据先到先服务的规则执行任务。
方案2:每个雾节点随机将任务卸载到其他雾节点,每个雾节点根据先到先服务的规则执行任务。
方案3:使用提出的任务卸载策略对雾节点进行任务卸载,并且每个雾节点根据先到先服务的规则执行任务。
方案4:使用本文提出的任务卸载策略对雾节点进行任务卸载,并且每个雾节点根据EDF算法[13]调度执行任务。
本文的方案:使用提出的任务卸载策略对雾节点进行任务卸载,并且每个雾节点根据提出的基于动态优先级的任务调度模型执行任务。
4.2 仿真结果分析
图4比较了在不同任务到达率下,5组实验的平均实验性能。仿真结果表明,提出的任务调度方案具有最佳的平均时延性能。这是由于提出的任务卸载策略充分利用了雾计算层的资源。此外,由于使用动态优先级模型调度任务,雾节点可以先执行更高优先级和更紧急的任务,从而减少任务的整体等待延迟。此外,可以看到,当同时使用任务卸载策略和EDF算法(方案4)时,平均时延性能非常差。这是因为雾节点仅在调度任务时考虑了任务的截止时间,导致低计算时延的任务请求到达雾节点之后,由于截止日期还早而被迫等待,因此增加了整体等待延迟。

图4 不同任务调度方案的平均时延Fig.4 Average delay of different task scheduling schemes
图5和图6分别比较了在不同任务到达率下,5组实验完成任务的总价值和完成任务的数量。
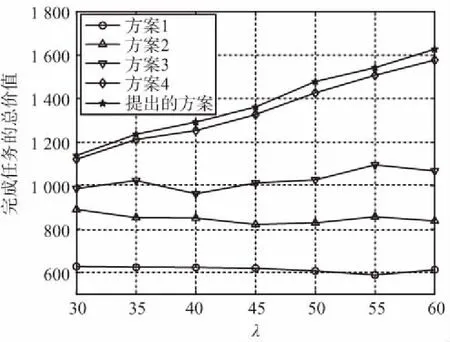
图5 不同任务调度方案完成任务的总价值Fig.5 Total value of tasks completed by different task scheduling schemes

图6 不同任务调度方案完成任务的数量Fig.6 Number of tasks completed by different task scheduling schemes
可以看到,提出的任务卸载策略在完成任务的总价值方面具有最佳性能,并且完成任务数量的性能仅仅略低于方案4。这是因为EDF算法只考虑了任务的截止日期,因此可以完成更多任务。然而,就平均延迟而言,方案4的性能非常差。因此,本文提出的任务调度方案的性能最优。
此外,表2中的数据显示了任务的总到达率为60的情况下,方案4和本文提出的任务调度方案的3种任务的完成数量以及完成率。可以看出,由于方案4只考虑了任务的截止日期,导致大量较高优先级的任务未能执行,不能满足智能工厂的要求。

表2 3种任务的完成数量和完成率Tab.2 Completion quantities and rates of three tasks
图7显示了任务的总到达率为60的情况下,不同优先级权重下3个任务的完成率。可以看出,当权重p较大时,固定优先级越高的任务的完成率越高。这是因为当雾节点执行等待队列的任务时,更倾向于执行具有更高固定优先级的任务。此外,当权重q较大时,系统将更倾向于执行具有更高执行紧急度的任务,因此这种情况下,固定优先级较低的任务的完成率比权重p较大时更高。通过调整权重p,q的大小,可以满足智能工厂在不同场景下的不同要求。
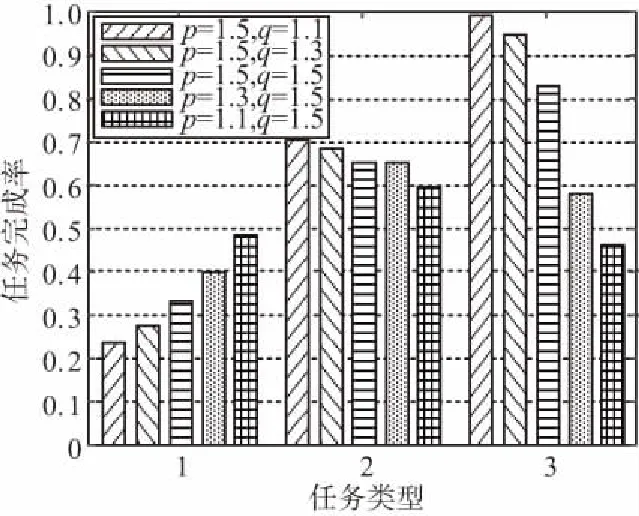
图7 不同优先级权重下各类任务的完成率Fig.7 Completion rates of various tasks under different priority weights
5 结束语
针对于基于云计算的智能工厂网络架构的缺陷,设计了一种基于雾计算的智能工厂网络架构,并在此架构的基础上,提出了一种基于动态优先级的实时任务调度方案。仿真结果证明了提出的网络架构以及任务调度方案可以在雾计算层资源紧张的情况下,有效地降低雾计算层执行任务的平均时延并提高了雾计算层任务执行的价值。
